
快照技术是计算机技术中的传统技术,常应用于数据的快速备份。在快照实现技术中,最常用的快照算法有COW写时拷贝算法和ROW写时映射算法。COW算法适合在写少读多的情况下应用;ROW算法适合在写多读少的情况下应用。这里主要分析一下COW算法实现过程中的bitmap语义。
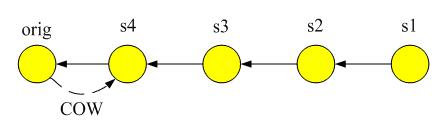
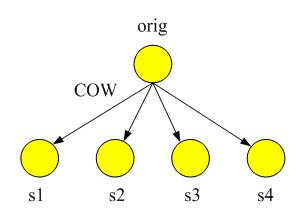
在实现COW快照过程中需要用一个bitmap来表示快照设备之间的增量信息。对于链式快照而言,假设创建一个快照点s4,那么源设备会将记录的bitmap信息交给s4,然后将源设备的bitmap清空。这样在写源设备的时候,系统会检查写操作所在的chunk是否在历史的某个时刻被写过,如果已经被写过,那么将orig设备上所对应chunk拷贝到快照点s4,并且将新的数据写入orig,然后再修改orig设备的bitmap对应chunk的位信息。这个过程就是快照的写时拷贝过程。对于草型快照而言,数据将向多个快照点进行COW,效率相对于链式快照低。从这个过程可以看出,orig设备上的bitmap信息记录的是最近一个快照点之后的增量数据信息。在未来的某个时刻,如果再创建一个快照点,那么orig上的bitmap信息将转移给新创建的快照设备,这样这个bitmap信息就描述了目前最近快照点到未来快照点之间的增量数据。这些增量数据的老数据都位于最近快照设备之上,因此,在链式快照的读写算法中,需要通过读前驱设备的bitmap信息来定位数据是否位于被访问的快照设备上。草型快照具有同样的原理,其bitmap信息在创建快照的时候从orig转移给新快照,然后orig上的bitmap清空。由于草型快照设备之间具有很强的独立性,无法反映快照设备之间的增量信息,所以通过这个增量数据的bitmap信息,可以方便的获取草型快照之间的增量信息。
下面补充一下链式快照的读过程:假设读快照设备s2时间点的信息,那么首先读取s3时间的bitmap信息,如果读取chunk的位信息为1,那么说明s2上的数据有效,直接从s2设备上读取信息。如果位信息无效,那么依次往前遍历,定位bitmap位有效的下一个快照设备。这就是COW快照设备的读过程。草型快照的读过程和这个不一样,具体代码可以参考Linux中的snapshot代码。
从上述分析可以看出,COW的bitmap语义为快照点之间的增量信息,通过这个增量信息,链式快照可以遍历得到快照点上的数据,草型快照可以得到快照点之间的增量信息。感兴趣的朋友可以阅读Linux中的snapshot相关代码,本文只是对阅读代码过程中遇到的bitmap语义进行分析说明。



 /1
/1 







文章评论(0条评论)
登录后参与讨论