
由于半导体工艺的局限,CMOS的源漏极之间的漏电流越来越大,随着频率的提升,功耗呈E指数的势态增长,因此,硅工艺很难再有突破。面对这样的局面,Intel等CPU厂商只能走多核的道路,多核已是市场的主流。
在目前的计算机架构中,往往采用多个多核CPU构建SMP或者NUMA系统,那么这种多核系统会引入什么样的性能问题呢?在此,略分析一二。
如下图所示,CPU是系统的执行单元,Thread和Memory是资源,Interrupt是外部或者内部的异步事件。传统单核系统时,由于只存在一个CPU,因此,操作系统对Thread、Interrupt和Memory采用简单的分配方式。但是,多核系统需要慎重考虑这些问题,甚至在编写程序的时候都需要考虑多核资源竞争问题,否则会影响到系统运行效率。
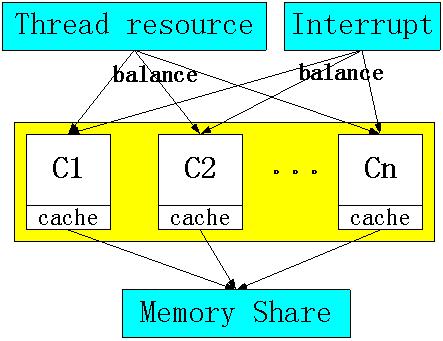
在此,多核面临的问题可以归纳成如下三个方面:
1, 线程分配问题。其实目前的Linux都支持多核的线程分配问题,其问题的关键在于CPU之间的负载均衡,操作系统需要保证每个CPU都处于均衡的工作状态。为了提高效率,需要降低CPU之间的相关性,因此,需要合理划分线程,这一点需要程序开放人员考虑。
2, 中断处理问题。中断是CPU的异步事件,当一个中断到来时,哪个CPU进行响应成了一个问题。目前的Linux还不能对中断平衡做出较好处理(这个功能目前正在开发)。中断处理的不平衡对IO性能影响很大。例如,只有C1处理器对网卡中断进行处理,那么,当网络事件很多时,C1必将被网络中断吞没,如果网络数据处理线程也被分配到了C1处理器,那么整个系统的IO性能将会很低很低。因此,对于IO密集型应用而言,中断的多CPU平衡急需解决。
3, 内存共享问题。每个CPU核都有自己的Cache,因此,对共享数据的访问将会破坏Cache所带来的数据局部性优势。CPU在访问共享资源的时候,每次都会刷新自己的Cache,因此,访问共享数据将会带来系统性能的损失。如果,一个程序开发人员不注意,将一些计数器变量作为全局变量使用,而且这些变量将会被高频率访问,那么,系统将会带来比较可观的性能损失。对于共享内存的优化,我觉得一方面可以提高编译器的性能,主动地为程序开发人员优化共享内存资源;另一方面,需要开发人员自己设计更好的算法,避免内存共享。其实,对于共享内存的一个优化思路是全局内存局部化。对于计算密集型应用,我觉得共享内存问题需要慎重。
CPU多核化可以提升系统性能,但是,增加了很多优化的空间,使得计算机系统变得更加复杂。




 /4
/4 






文章评论(0条评论)
登录后参与讨论