
在《时序优化一例(一)》中采用修改代码的方法优化了一实例,通过加入一级流水线寄存器分割组合逻辑达到该路径时序收敛,但是重新check一下timing发现还有时序不满足,而且还是除法器IP核的时序未收敛,对于这官方提供的IP核那就没办法通过修改代码进行优化了。查了些资料,发现还可以通过物理综合优化,在没有使能物理综合前,QuartusII软件只进行逻辑综合,逻辑综合中的时序仅限于综合后的门级电路或者器件内部的逻辑单元的时延信息,并没有包含布线时延信息,也就是说Synthesis与fitter并没有交互操作;而物理综合则在综合时考虑具体的布线时延信息,使获得不错的综合结果。
QuartusII提供了几个选项,可以通过Settings->Compilation Processing Settings->Physical Synthesis Optimization打开,如图1所示。
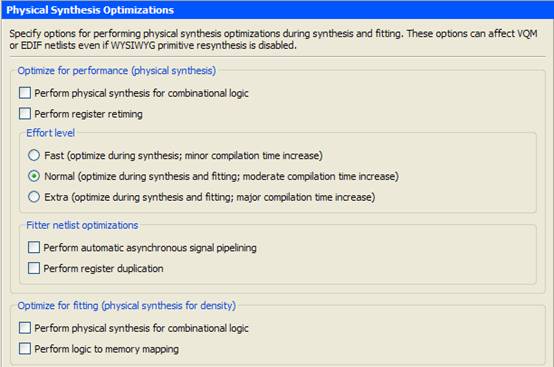
图1
其中主要分为两部分:
1. Optimize for Performance:主要用于优化性能
2. Optimize for fitting:主要用于优化fitter
与时序相关的就是第1部分(Optimize for Performance)了,翻阅了官方手册,找到了对应各选项的解释。
Perform physical synthesis for combinational logic:通过交换LEs中LUT port来减少关键路径的逻辑层数目,同时还会通过复制LUT解决扇出过大的问题,此选项只影响combinational logic,并不对register进行优化;
Perform register retiming:关于register retiming的概念,主要是为了解决关键路径逻辑过长的问题,通过在combinational logic中移动register,利用宽松路径的余量来补偿关键路径进行优化;
Perform automatic asynchronous signal pipeline:该选项是在fitter时自动加入针对异步clear或load信号的流水线级来优化性能,特别是在recovery和removal slack未达到时序要求时可以使能这一选项;
Perform register duplication:自动复制register优化高扇出的问题。

图2
针对设计,通过查看关键路径,如图2所示,发现逻辑级数达到33,这与第一个选项:Perform physical synthesis for combinational logic所能解决的问题比较匹配,使能第一个选项,看一下优化结果:
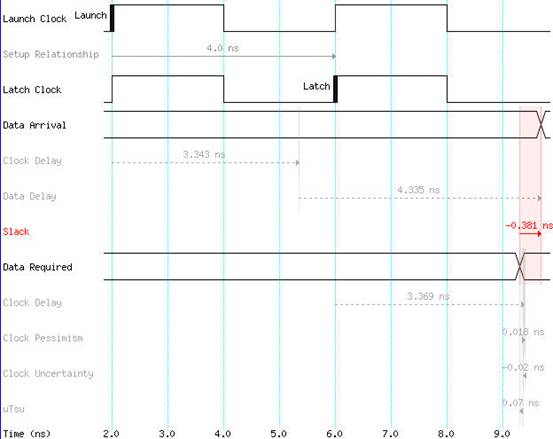
图3 优化前
如图3所示为优化前的时序波形图,时序未收敛,关键路径上Data Delay过大,达到4.335ns。
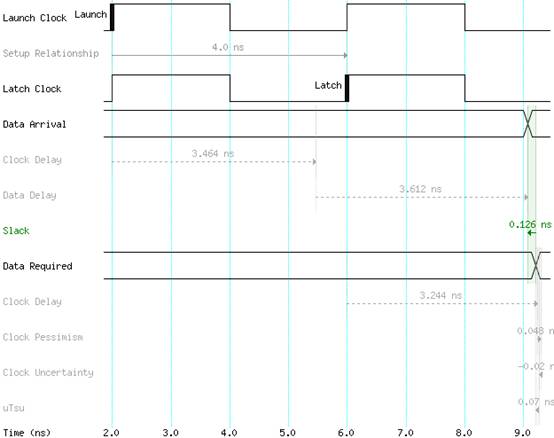
图4 优化后
如图4所示为经过优化后原先关键路径的时序波形图,发现该路径已达到收敛,Data Path的时延仅3.464ns,留给建立时间0.126ns的余量。因此选项:Perform physical synthesis for combinational logic确实达到了优化的目的,下面来查看一下软件是如何自动优化的:

图5 优化后
如图5所示优化后的Technology Map图,发现逻辑级数还是很多,查看TimeQuest Timing Analyzer中的统计,logic lever还是有32级,相比于优化前仅少了1级,估计这1级也不是使路径时序收敛的关键,还需继续深入探究。
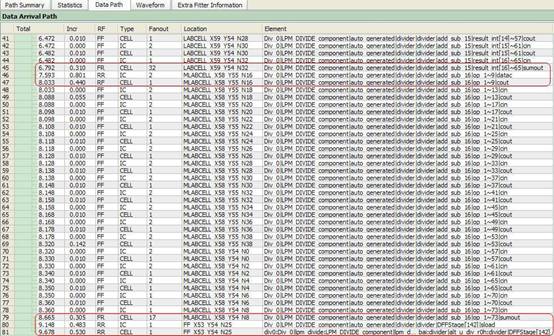
图6 优化前Data Path
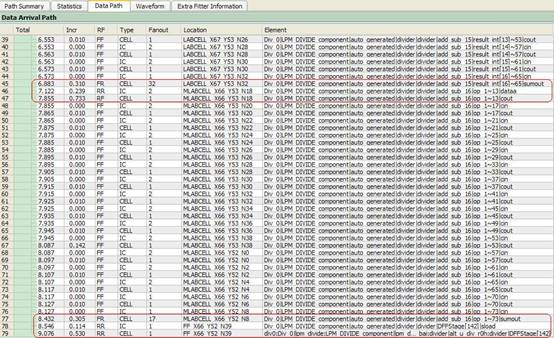
图7 优化后Data Path
如图6、7所示,通过比较优化前和优化后的Data Path,根据上面分析,优化前Data Path总时延为4.335ns,而优化后仅为3.464ns,相差0.841ns,这足够使路径达到时序收敛。仔细比较优化前后的Data Path,发现共有两处差别:
1. 在逻辑中少了1级,原先连接这级逻辑的路径时延发生了变化
![]()
(a)优化前
![]()
(b)优化后
图8
通过图8中优化前后的对比,优化后少了Div_0|LPM_DIVIDE_component|auto_generat
ed|divider|divider|add_sub_16|op_1~9|这一级,减少了布线延时,时延方面从0.310+0.801+0.440+0.000+0.055=1.606ns减少到0.310+0.239+0.733=1.282ns,
![]()
(a)优化前
![]()
(b)优化后
图9
2. 如图9所示为第二处差别,此处具有相同的路径,节点的扇出也相同,就是时延发生了变化,节点Div_0|LPM_DIVIDE_component|auto_generated|divider|divider|add_sub
_16|op_1~73|sumout到节点Div_0|LPM_DIVIDE_component|auto_generated|divider|divi
der|DFFStage[142]|sload的时延从0.483ns减少到了0.114ns,这就很奇怪啊,查看Technology Map肯定看不出什么区别了,因为它们路径两端的节点是相同的,那只能通过Chip Planner查看底层是如何布线的了。
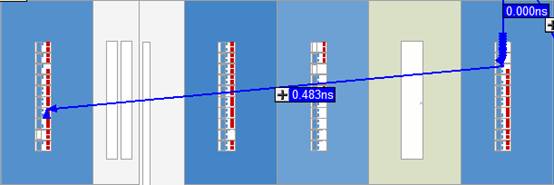
(a)优化前
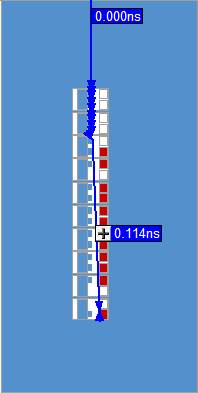
(b)优化后
图10
通过对比图10中(a)和(b),发现优化前这一小段路径横跨了好几个LAB,导致时延比较大,而优化后该段路径在一个LAB就内部消化了,软件自动对关键路径的布线进行了优化。

图11
经过以上优化和分析,原先的关键路径时序收敛了,那整个设计的时序是否收敛了呢?那就重新check一下timing吧,很遗憾,还是不满足,如图11所示,不过庆幸的是setup slack提高了些,到-0.240ns了,不然这优化算是白费了。
总结:此次优化是通过软件自动进行的,通过查找问题使能了对应选项,这种针对性的优化效果还是很明显的。在我尝试其它选项进行优化后发现几乎没有什么效果,甚至使问题更加恶化了,因此采用软件自动优化时不能太盲目,认为将所有优化选项都使能就是最佳的,必须根据设计本身的问题采取针对性的优化方案。
革命尚未结束,咱还需继续努力!


 /5
/5 



用户408415 2011-10-12 09:22
Hoki 2011-10-11 13:54
用户408415 2011-10-11 12:43