
学习时序也有一段时间了,一直也没分享什么学习笔记。这次以时序优化为例,检验一下这阶段的学习成果。
关于时序方面的东西也看了、学了很多,就是练得很少,在平常自己的设计中很难找到非常针对的设计来练习,只能在今后的学习中慢慢发掘了。最近在整一个设计,在要求的指标下时序是满足的,但是为了拿它练手,故意将它的时钟约束提高一倍:
create_clock -name {sysclk} -period 4.000 -waveform { 2.000 4.000 } [get_ports {clk}]

图1
约束到250M了,发现建立时间不满足,如图1所示为10条违规路径,可以发现主要都是From Node:DC_Off模块到To Node:estimator模块的路径,在此设计中不涉及input、output的分析,因此时序模型主要是针对reg-to-reg,一般此情况下的时序违规主要是data_path中的组合逻辑过长或者高扇出导致的。下面通过TimeQuest Timing Analyzer分析一下:
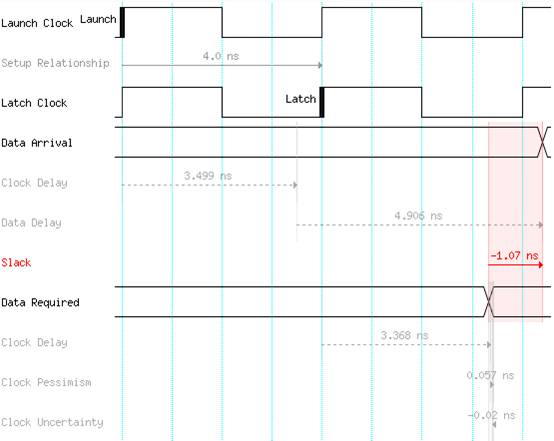
图2
时序波形图如图2所示,建立时间余量是通过Data Required Time减去Data Arrival Time得到的,由于Data Path的时延过大,有4.906ns,导致setup slack为负。
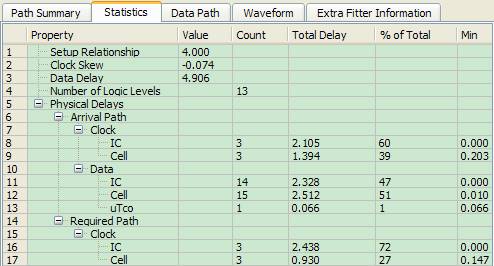
图3
由图3可以发现时序违规的关键路径上的Logic Levels达到13,这主要是在代码中逻辑过于复杂和多层的if…else… 、case导致的。通过Locate Path到Technology Map Viewer可以清晰得查看关键路径上的逻辑,如图4所示,与开始的分析相符,主要是DC_Off模块和estimator模块之间的路径,其中包含大量的加法器逻辑,导致时延过大。

图4(看不清可另存查看)
一般解决关键路径过长问题达到时序收敛的方法,针对逻辑复杂的问题可以加入流水线级分割逻辑;而针对多层的if…else… 、case则需要优化代码避免不必要的优先级编码,这需要的工作量稍大,在验证阶段一般的程序猿也没心思去仔细得抠代码了,因此相比于此方法,加入pipeline还是性价比高的解决办法。在此设计中,修改代码,在DC_Off模块和estimator模块间加入了一级流水线寄存器,如图5所示。

图5
可以发现图5路径中的逻辑是图4路径中逻辑的一部分,加入流水线级后逻辑果然被分割了,然后看一下该路径时序波形图,如图6所示,通过逻辑分割后这条路径Data Path的时延减小到了2.887ns,已达到时序收敛了。
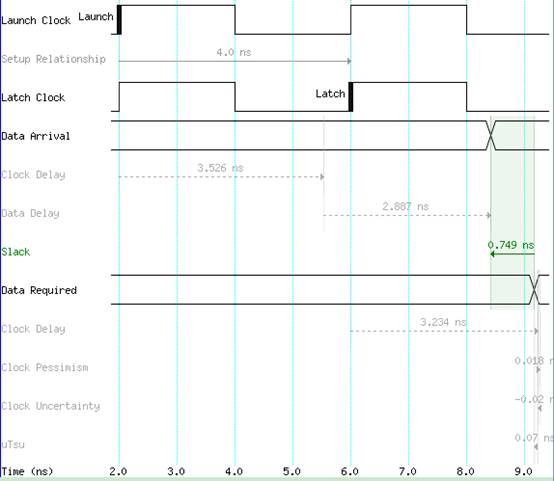
图6
解决了原先的关键路径,再次check一下timing,发现还是没有收敛,如图7所示,setup slack还是负的,不过-0.381还是比原先的-1.070提高不少了,但是关键路径不是原先那条了,而是主要集中在Div模块内部。

图7
Div模块只是例化了一个除法器IP核,难道官方提供的IP核有问题,翻阅了一下除法器的手册,找到了它的性能指标,如图8所示,在我的设计中Device Family为Stratix IV,Input Data Width为32,Output Delay为16,估计fmax达到250M还真是够呛啊。
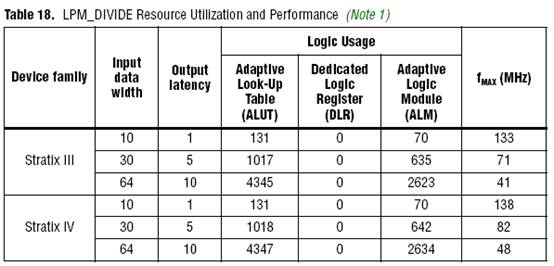
图8
在这个例子中,现阶段时序虽还未收敛,但是还是优化了不少。从中自己也收获不少,学会了通过TimeQuest Timing Analyzer分析,并且进行有针对性的优化,不会再像以前那样遇到时序问题时那么盲目,不知从何下手。下一阶段,再试试用其它方法优化这个设计,不达到时序收敛誓不罢休!




 /4
/4 






文章评论(0条评论)
登录后参与讨论