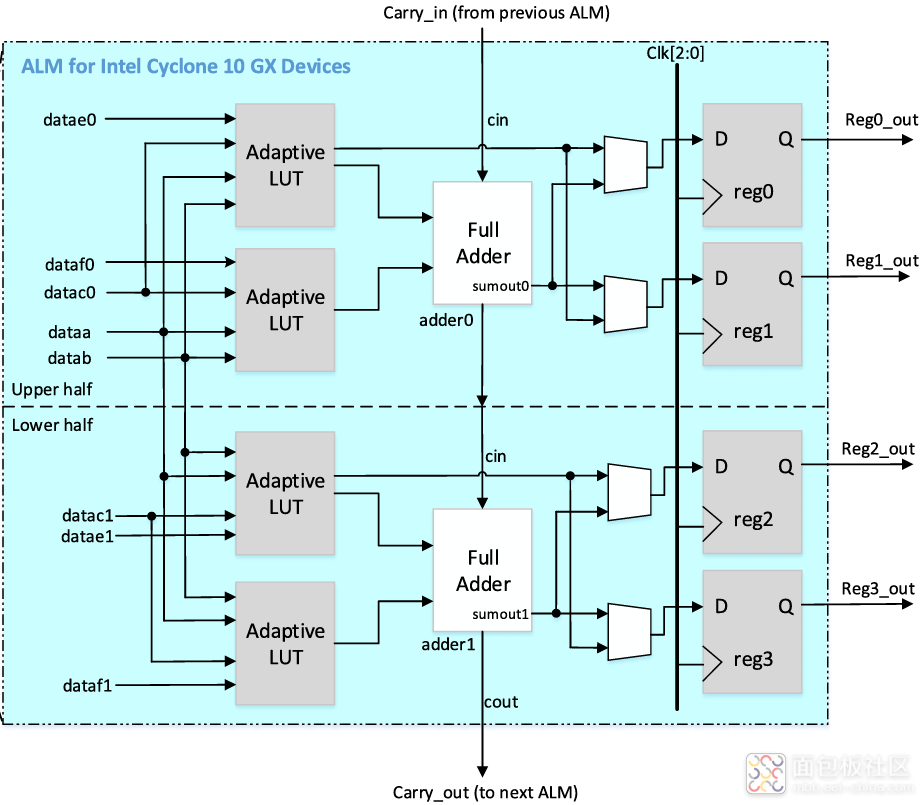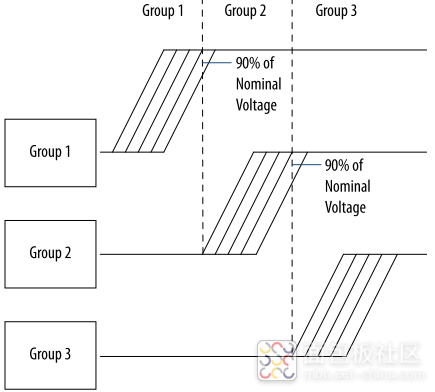
概述 Intel 要求用户为其10代FPGA器件使用特定的上电和掉电顺序,这就要求用户在进行FPGA硬件设计的时候必须选择恰当的FPGA供电方案,并合理控制完整的供电上电顺序。经过在Cyclone 10 GX测试板上实际验证,统一上电确实会导致FPGA无法正常工作,具体表现为JTAG接口无法探测或识别到目标器件。 上电顺序要求 Cyclone 10 GX,Arria 10以及Stratix 10系列器件所有的电源轨被划分成了三个组合,三组电源轨要求依次上电,如图1所示,为三组电源轨上电顺序示意图。 图1:Cyclone 10 GX器件上电顺序示意图 三组电源轨具体划分如表1所示,而在具体设计的时候,有些电源轨电平相同,此时相同电平的电源轨当电流合适的情况下,在进行合理隔离后可以进行合并。具体情况可以参考 。 表1:Cyclone 10 GX供电电压轨分组划分 Group1 VCC,VCCP,VCCERAM,VCCR_GXB,VCCT_GXB Group2 VCCPT,VCCH_GXB,VCCA_PLL Group3 VCCPGM,VCCIO 在分组2中所有电源轨开始爬升之前,分组1中的所有电源轨可以任何顺序爬升到其标称电平的90%水平。 在分组1中所有电压轨以任何顺序爬升到其标称电平的90%后,分组中所有电压轨才可以任何顺序开始爬升。 同样,分组3中的电压轨,也只有等到分组2中所有电压轨均爬升到其标称电压水平的90%之后,才可以任何顺序开始爬升。 之前提到,当分组之中或不同分组之中电压轨标称电平一直时,在合理隔离情况下可以共享供电模块,后面再详细介绍。 需要注意的是,确保新合并的电压轨不会导致未通电的GPIO或收发器引脚获得“驱动”。 所有电压轨都必须单调爬升,且上述上电顺序控制,必须满足标准或快速POR延迟时间要求。也即,整个爬升时间必须控制在最小的POR延迟时间之内。POR延迟时间指标如表2所示。 表2:POR延迟时间指标 Cyclone 10 GX器件电压轨供电共享指导原则 查参考 给出了两种共享供电模块例子,这里就第一个例子进行讨论,详细信息可以查看 。如表3所示,为Cyclone 10 GX器件电压轨共享分组方案之一。 表3:Cyclone 10 GX器件电压轨共享方案 电源 引脚名称 分组 压值(V) 供电公差 电压源 模块共享 备注 VCC 1 0.9 ±30mV 开关电源 可共享 VCCP VCCERAM VCCR_GXBL 2 0.95 ±30mV 开关电源 可共享 为获得更好性能,将VCCR_GXB与VCCT_GXB隔离 VCCT_GXBL VCCBAT 3 待定 ±5% 开关电源 均为1.8V可共享 这四个均为1.8V时,可以使用同一电源模块供电 VCCPT 1.8 VCCIO 待定 VCCPGM VCCH_GXBL 1.8 隔离 可共享,但需要进行正确隔离 VCCA_PLL 参考 AN 692: Power Sequencing Consideration for Intel Cyclone 10 GX, Intel Arria 10, and Intel Stratix 10 Devvices. Intel Cyclone 10 GX Device Family Pin Connection Guidelines

 标签: GX
标签: GX