
概述
项目使用的FPGA目标器件为Cyclone 10 GX系列规模最大一颗料,由于功能升级增加了功能模块更多,发现器件片内RAM不够使用了。为了探索片内RAM使用的利用率问题,从代码RTL级与编译软件的优化选项方面进行了思考。表1是器件手册中给出的C10GX器件片内RAM颗粒,即M20K,可配置模式。
表1:Intel Cyclone 10 GX器件单端口片内存储器配置
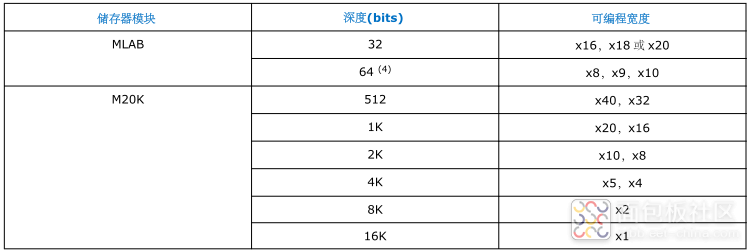
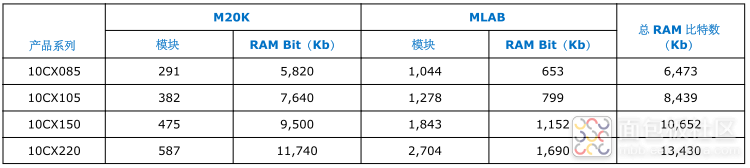
对于MLAB来说,一个MLAB大小是640bit,是由双功能逻辑阵列模块(LAB)配置而成。MLAB是宽而浅型存储阵列的最佳选择,每个MLAB由10个自适应逻辑模块(ALM)组成,在Intel Cyclone 10 GX器件中,这些ALM可配置成10个32x2模块,这样的每个MLAB可实现32x20的简单双端口SRAM模块,Cyclone 10 GX系列器件中片内存储器性能及分布如表2所示。
表2:Intel Cyclone 10 GX器件中片内存储器性能及分布
项目遭遇片内RAM不够问题
升级的项目,在之前逻辑设计的基础上增加了两个模块,理论上存储器消耗要增加一倍。逻辑修改后,工程全编译时,在Fit阶段报错,提示目标器件无法提供足够的RAM来完成布局,如图1所示。

图1:因RAM不足,导致布局失败
Info(170034): Selected device has 587 memory locations of type M20K block. The current design requires 626 memory locations of type M20K block to successfully fit.
Info(170033): Memory usage required for the design in the current device: 107% M20K block memory block locations required
Info(170043): The Fitter setting for Equivalent RAM and MLAB Paused Read Capabilities is currently set to Care. More RAMs may be placed in MLAB locations if a different paused read behavior is allowed.从编译消息列表中摘出上述3条有关出错的消息,第一条提示器件总共587个M20K颗粒,当前设计需要626个来完成布局。第二条给出当前设计完成布局需要消耗器件片内RAM颗粒数量是目标器件能提供的107%。第三条消息提示Fitter的关于“Equivalent RAM and MLAB Paused Read Capabilities”当前设置是“Care”,如果允许更改该设置,则可以将更多的RAM消耗替换为MLAB消耗。
在Quartus的Settings设置中,找到编译器设置页面,并在该页面中找到属于Fitter的Settings高级设置按钮,如图2所示,并点击此按钮进入高级Fitter设置页面。
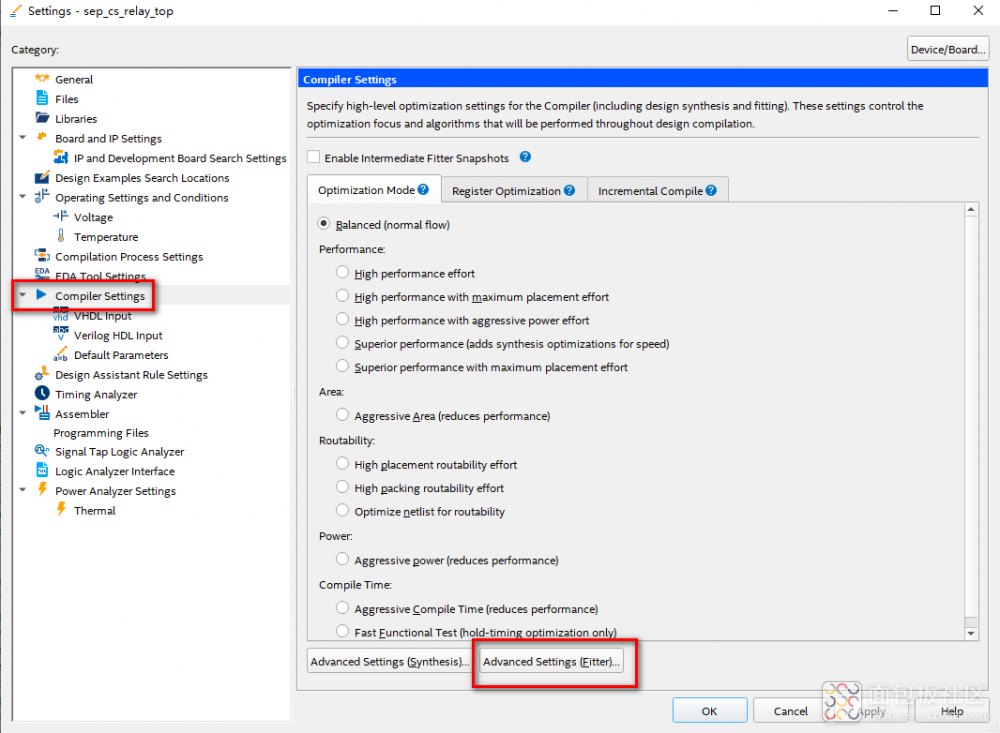
图2:编译器设置页面
如图3所示,为Fitter的高级设置页面,找到“Equivalent RAM and MLAB Paused Read Capabilities”设置选项,可以将默认设置“Care”修改为“Don’t Care”,如此再重新编译后则可以解决上述报错问题,如图4。
如图4所示,虽然经过上述修改解决该报错问题,但是整个RAM消耗已经达到了100%。100%的RAM消耗率,如果设计功能已经达到目标要求,则是可以作为最终设计提交,但是这仅仅这是项目的预先编译评估,所以并不能就此停止。比如,在后期调试时需要添加SignalTap功能的时候,就可能面临无RAM可用的情况。同时,还需要了解上述设置修改对逻辑设计是否产生负面影响进行评估,即需要对该设置进行深入了解,否则不要轻易修改默认设置。
如果需要进一步减小RAM消耗,那么就需要针对当前设计进行深度优化,这是下一节的内容。
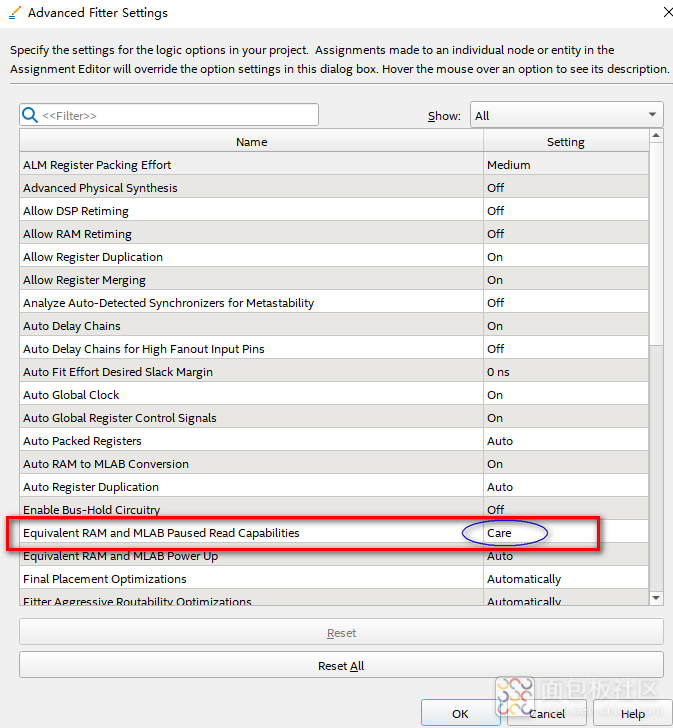
图3:高级Fitter设置页面
片内RAM耗尽后,优化思考
Cyclone 10 GX最大型号器件,总共有587颗片内M20K颗粒,如图4所示,按照图3所示对Fitter高级设置进行修改后,对工程再编译,全编译无报错通过,编译报告提示所有M20K颗粒已经100%耗尽。

图4:M20K颗粒耗尽统计报告信息
如果查看Fitter给出的各个M20K颗粒使用详尽信息,可以发现,各个颗粒容量的使用率不尽相同,有些颗粒甚至使用了不到1%,如图5所示,这些颗粒有12个。
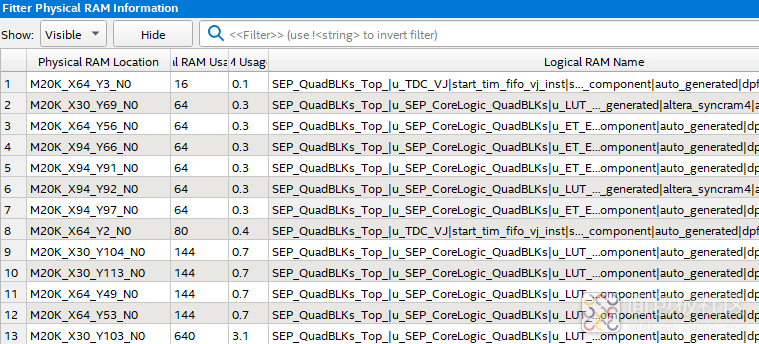
图5:Cyclone 10 GX系列最大器件中M20K颗粒使用情况信息
上述不到1%利用率的M20K颗粒很大可能是为了与其它颗粒“凑整”过程中被消耗的,一旦被占据,该M20K颗粒空余空间就无法开放给其它逻辑使用了。如此大大降低了RAM颗粒的利用率,在进行逻辑设计的初始阶段就应该核算RAM、FIFO或ROM的大小与实际片内RAM颗粒的尺寸来进行规划,提高资源的利用效率。
举个简单的例子说明RAM被“奢侈”利用,AD9633分解为8个LVDS接收器通道,解串后得到了48-bit的并行数据,这时创建了一个FIFO来缓冲该数字转换数据,所以FIFO的位宽48-bit,深度选择为8。所以一个FIFO实际消耗384-bit的RAM,但是经过编译,该FIFO必须要使用2个M20K颗粒(共40960-bit)来实现,RAM利用率不到1%。是不是很奢侈,很浪费?!
这个FIFO的读写时钟不一样,所以属于异步FIFO,修改图3所示的高级设置选项也无法将FIFO转换为MLAB来实现。在例化FIFO的时候倒是可以强制指定使用MLAB来实现它。
参考
作者: coyoo, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-1010859.html
版权声明:本文为博主原创,未经本人允许,禁止转载!


 /5
/5 







文章评论(0条评论)
登录后参与讨论