
在第一章有关速度优化中,原文作者给出了一个三次方的实例,原作者是以Xilinx器件以及Synplify综合工具为例。这里笔者用Quartus运行,我们来看看第一个例子,即原始3次方递归代码:
|
以下是3次方原始迭代代码片段: module power3a( output [7:0] XPower, output finished, input[7:0] X, input clk,start);//the duration of start is a single clock reg[7:0] ncount; reg[7:0] XPower;
assign finished=(ncount==0);
always@(posedge clk) if (start) begin XPower<=X; ncount<=2; end else if (!finished) begin ncount<=ncount-1; XPower<=XPower*X; end endmodule |
上述代码是拷贝自原书,但是在QuartusII中编译是会报错的,在QII中认为端口列表里如果需要定义端口,那么就必须完整定义,否则就只能简单列出端口,然后在module体中再详细定义。如果要在端口列表里定义,那么上述代码执行修改XPower的定义为:
output reg[7:0] XPower
即可,并且要删除module体中的“reg[7:0] XPower”语句;或者是端口列表里不要加“7:0]”而只是在module体里定义。这也许是Synplify和QII的差别吧,没有用Synplify验证,或者应该是老版本与新版本的差异。或许是原书的一个小bug,因为在后面优化后的power3实例中XPower的定义是正确的。
图1是Quartus编译后的网表视图,对比原书差不多:
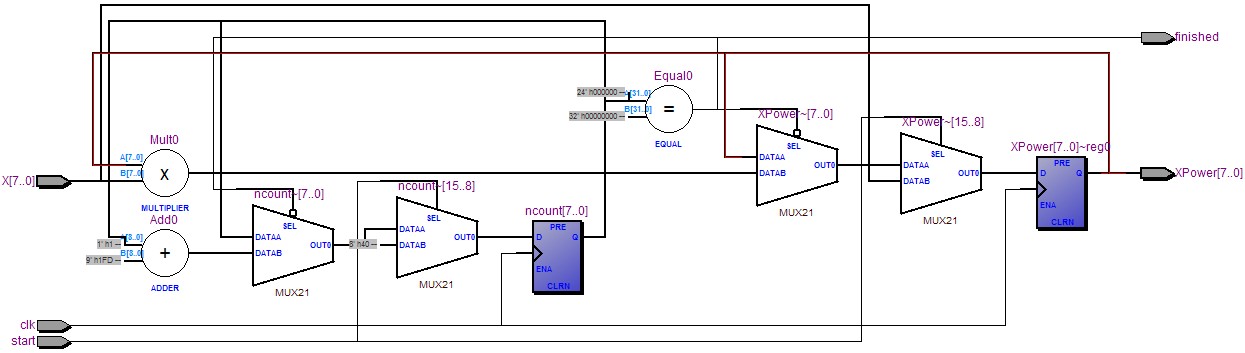
图1:三次方迭代原始网表视图
接下来我们来,原书对于上述迭代进行吞吐量优化后的代码:
|
以下是3次方原始代码进行吞吐量优化后的代码片段: module power3b( output reg[7:0]XPower, input clk, input[7:0]X ); reg[7:0]XPower1,XPower2; reg[7:0]X1,X2;
always@(posedge clk)begin //Pipeline stage1 X1<=X; XPower1<=X; //Pipeline stage2 X2<=X1; XPower2<=XPower1*X1; //Pipeline stage3 XPower<=XPower2*X2; end endmodule |
图2是优化后使用QuartusII进行编译后的结果:
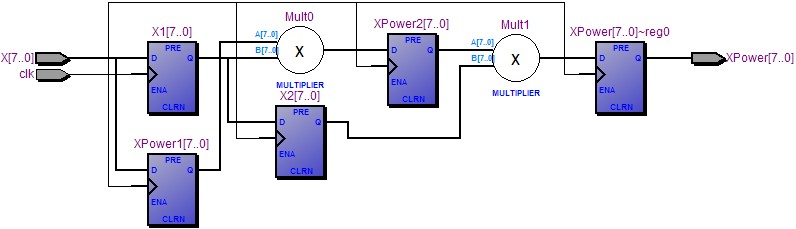
图2:吞吐量优化后的网表视图
可以看到,这种代码级优化的结果一般都与综合工具没有太大相关性。






 /2
/2 






文章评论(0条评论)
登录后参与讨论