
有些逻辑结构比较庞大,所以可以将其拆分成多个更小的结构,然后这些小的逻辑结构可以并行处理,由此可以提供整个逻辑结构的处理速度。
这里还是以之前的三次方来举例,如果输入为8bit,那么我们可以把8bit乘法拆分为两个并行的4bit乘法,代码如下所示:
|
以下是代码片段: module power3d(
output[7:0]XPower,
input[7:0]X,
input clk);
reg[7:0]XPower1;
//partial product registers
reg[3:0]XPower2_ppAA,XPower2_ppAB,XPower2_ppBB;
reg[3:0]XPower3_ppAA,XPower3_ppAB,XPower3_ppBB;
reg[7:0]X1,X2;
wire[7:0]XPower2;
//nibbles for partial products (A is MS nibble,B is LS nibble)
wire[3:0]XPower1_A=XPower1[7:4];
wire[3:0]XPower1_B=XPower1[3:0];
wire[3:0]X1_A=X1[7:4];
wire[3:0]X1_B=X1[3:0];
wire[3:0]XPower2_A=XPower2[7:4];
wire[3:0]XPower2_B=XPower2[3:0];
wire[3:0]X2_A=X2[7:4];
wire[3:0]X2_B=X2[3:0];
//assemble partial products
assign XPower2=(XPower2_ppAA<<8)+(2*XPower2_ppAB<<4)+XPower2_ppBB;
assign XPower=(XPower3_ppAA<<8)+(2*XPower3_ppAB<<4)+XPower3_ppBB;
always@(posedge clk)begin
//Pipeline stage1
X1<=X;
XPower1<=X;
//Pipeline stage2
X2<=X1;
//create partial products
XPower2_ppAA<=XPower1_A*X1_A;
XPower2_ppAB<=XPower1_A*X1_B;
XPower2_ppBB<=XPower1_B*X1_B;
//Pipeline stage3
//create partial products
XPower3_ppAA<=XPower2_A*X2_A;
XPower3_ppAB<=XPower2_A*X2_B;
XPower3_ppBB<=XPower2_B*X2_B;
end
endmodule
|
将以上代码在Quartus II中编译,编译结果如图1所示:
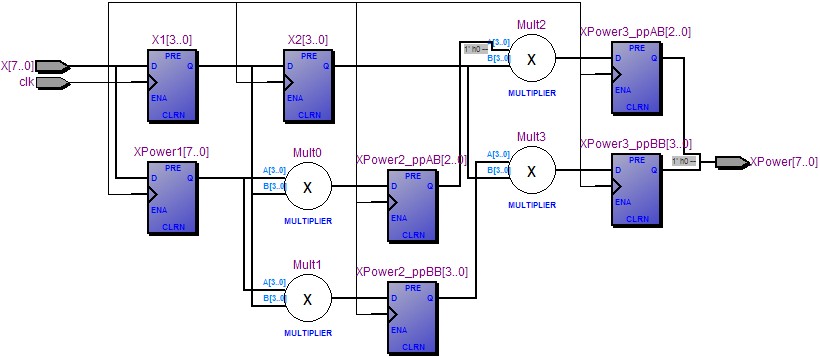
图1:被拆分的乘法
这是一个比较简单的实例,理论上8bit乘法要比4bit乘法运算时间更长,所以含有8bit乘法的路径应该要比4bit路径延时更大,当然实际应用中可拆分的算法也许更复杂,优化效果会更加明显。



 /5
/5 







文章评论(0条评论)
登录后参与讨论