
几十年来,闪存一直是嵌入式系统的一个重要课题。与其他存储技术相比,它允许大幅改进电子设备的大小和鲁棒性。闪存存储的其他优势包括缺少移动部件和降低功耗。然而,闪存的挑战并没有在消费类电子产品中广为宣传。其中包括有限的耐用性和更高的软件复杂性。

图 1:从U盘驱动器和 SD 卡到 SSD 和集成电路,闪存是我们日常生活的一部分。
如图 1 所示,闪存在我们的日常生活中无处不在,从专门用于存储数据的设备(如U盘驱动器、SD 卡和 SSD)到内部使用闪存的其他消费类电子产品(如智能手机、Wi-Fi 调制解调器和智能灯灯泡。
一个标志性的反例是2001年发布的iPod的第一款产品。它使用旋转的硬盘来提供高存储容量(当时是 5 或 10 GB)。然而,一项研究发现,使用硬盘的产品的故障率大于20%,而配备闪存的型号的故障率则低于10%。由于它们包含敏感的移动部件,旋转的磁盘不能很好地处理机械冲击。这对配备磁性存储的便携式设备的故障率起着关键影响。

图2:2001年发布的原版iPod是具有磁性存储的移动设备的罕见例子。
当涉及到嵌入式系统时,闪存是非易失性存储器的首选。在嵌入式 Linux 系统中,在模块 (SoM) 和单板计算机 (SBC) 上使用集成电路 (IC) 是一种常见做法,因为它们通常比一些型号的 SD 卡更耐数据磨损。当环境振动是决定性因素时,它们也更加坚固。使用集成闪存的模块案例包括来自 Toradex 的 Apalis 和 Colibri 系列。在图 3 中,您可以看到 Colibri iMX8X 模块的放大视图,该模块配备了 Micron 的 eMMC:

图 3:Colibri iMX8X 配备了来自 Micron 的 eMMC 闪存。
本文的目标是概述如何通过利用开源和专有软件来测量和估计 eMMC 磨损,从而设计更可靠的嵌入式系统。其动机是例如对 IoT 网关和数据记录器的需求不断增加,以及出于更高的可靠性或间歇性连接原因将冗余数据保留在本地的需求。为了介绍实际的实施细节,配备 Micron eMMC 的 Toradex 模块将被用于介绍如何实现磨损监控和寿命估计解决方案,即闪存分析工具。
本文还包括宽泛的技术概述和一些实现细节。您可能对该信息并不陌生,因此如果您已经具备必要的知识或您认为合适,请随时跳过部分。
技术概述
在进一步讨论之前,值得注意的是,闪存是一个如此广泛的话题,即使一篇专门讨论其工作原理的文章也无法提供足够全面的概述。以下段落仅作为背景,以更好地了解如何估计 eMMC 磨损。
虽然本文仅介绍了理解磨损估计的要点,但互联网上提供了有关闪存存储的丰富文献。例如,Toradex 在其开发者网站上拥有博客、网络研讨会录像和一系列文章。维基百科关于闪存的文章也有超过一百个对其他资源的引用。
NOR 和 NAND
闪存是一个宽泛的术语,有几种技术组合共同构成具有特定特性的最终闪存产品。闪存存储分可初步分为两种类型:NOR 和 NAND。这些以该技术在晶体管级别如何运行来存储位而命名,类似于 NOR 和 NAND 逻辑门。
虽然 NOR 具有更简单的操作原理和更高的可靠性,但它通常需要更高的引脚数量,并且与 NAND 相比,其单位硅面积的存储密度较低,这会影响其尺寸和成本。由于这些原因,NOR 通常只用于特定应用,即使对于工业级、高度可靠的嵌入式系统也是如此。您可以在 Micron 的 NOR /NAND 闪存指南(PDF)了解更多此话题的信息。您可以在图 4 中看到 NOR和 NAND 技术在存储密度和容量方面的摘要,该摘要取自本段中提到的指南:
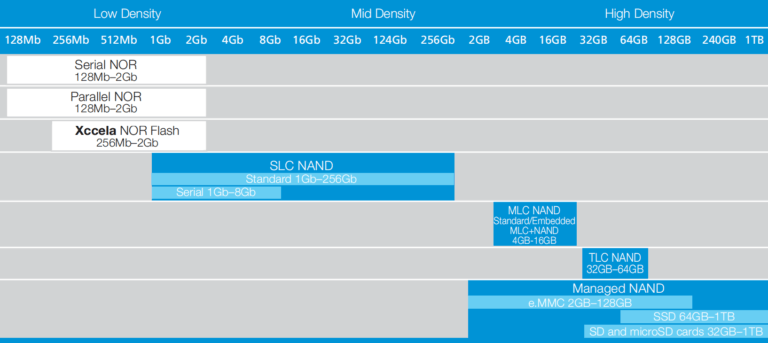
图 4:按密度和容量划分的 NOR 和 NAND 产品。(来源:Micron NOR/NAND闪存指南)
如您所见,Micron eMMC 是 MLC 和 TLC 范围内的专用 NAND 设备,我们将对此进行更详细的讨论。由于 Toradex 模块使用 4GB 到 16GB 范围内的 eMMC,我们可以推断它们使用 MLC 设备。本文稍后将对此进行介绍。
NAND 结构
原始的 NAND 闪存设备可以分为三个不同的部分。
单元格 Cell:最小的单位。该单元以位级别存储数据,并且不能由控制 NAND 存储的设备直接寻址。
页 Page:可用于读取和编程操作的最小单位组。编程操作由从值 1 到值 0 的"翻转"位构成。页面大小在几千字节范围内,例如,4 KB。
块 Block:可用于擦除操作的最小页组合。在定义中,如 Linux MTD 堆栈,块也称为擦除块。擦除操作包括恢复值为 0 的位到值 1。块大小在几兆字节范围内,例如,4 MB。擦除操作比在页上执行的编程或读取操作慢得多。
从上面的要点中最重要的信息是,块磨损,因为它们会被擦除。因此,我们最感兴趣的是块擦除计数。也就是说,每个块被擦除的次数。

图 5:原始 NAND 闪存的总体示意图。
NAND SLC 和 MLC
单元格作为最小单位,用于存储每一个位。每个单元实际存储的位数取决于它在读取操作期间可以保持和区分的电平阈值。闪存有多种设计,用于指示存储单元可以存储的位数。
SLC:单级单元,每个单元存储 1 位
Pslc:SLC 模式的 MLC 操作,每个单元存储 1 位
MLC:多级单元,每个单元存储 2 位
TLC:三级单元,每个单元存储 3 位
QLC:四级单元,每个单元存储 4 位
表 1 总结的密度和成本与可靠性和使用寿命之间存在权衡。

表1:NAND单元技术比较
图 6 有助于展示 SLC 和 MLC 如何存储位:
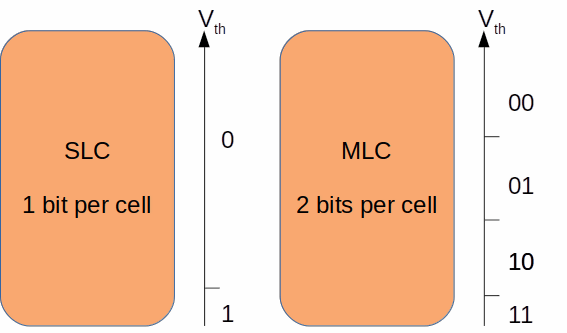
图 6:SLC 和 MLC 电压阈值
pSLC("伪SLC")提高了 MLC 设备的操作速度和使用寿命,但代价是将其容量减少一半。寿命与真正的 SLC 无法相比拟,但它大大增加了。伪 SLC 不应与快速模式混淆,后者使 MLC 设备更快,但不会延长其使用寿命:
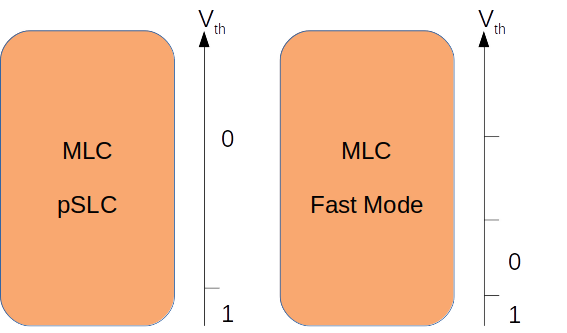
图 7:伪 SLC 和快速模式
了解块是否配置为 MLC 或 pSLC 对于确定设备的使用寿命非常重要,因为我们会随着时间的推移统计坏块计数。
对于使用 MLC 技术的 eMMC,根据硅的线宽,块一般可以承受 3000 到 10000 次擦除周期。与 MLC 相比,pSLC 的生存期提高操作2倍。因此,pSLC 比快速模式或提高配置(即使用容量翻倍的闪存使其使用寿命延长两倍)更可取。在制造商的公开文档中很难找到擦除周期计数和线宽值,因此对设备本身进行基准测试可能是一种解决方案。
ECC
我们简要地回顾了块磨损并变无法继续使用。这时当它们正常的时候,并不是一切都是完美的。位可能被随机翻转,损坏存储的数据。这是 ECC 或纠错代码算法介入以更正翻转的位。
随着时间的推移,块中有位翻转的概率会增加。当它变得太大时,块被标记为无法使用。可能在一开始就有坏块,存储设备会从工厂发货时就标记一些坏块。制造商通常包括备用模块来替换这些坏块,从而使它们不会立即影响可用的存储容量。
写入放大
简单地讲,写入放大就是将数据从一个块复制到另一个块,无论是为了更新数据、磨损均衡或任何其他原因。
磨损均衡和垃圾回收
如果始终使用相同的物理页和块,如更新文件,则这些块将过早磨损。在最坏的情况下,如果 NAND 控制器没有为坏块重新分配,则系统甚至可能在闪存寿命终止 (EOL) 之前停止工作。
为了防止这种情况发生,磨损均衡算法可确保块始终被均匀使用。为此,它会移动数据。有两种类型的磨损均衡算法。
动态:仅移动动态数据,即随时间更新的数据。静态数据保存在最初写入的块中。此算法更简单,但不使用存储设备的全部容量。当只有一小部分闪存保存静态数据时,最好使用它。
静态:此算法有目的地移动静态数据,均匀地磨损闪存的所有块。这是一种更复杂的算法,但它通过使用所有可用的闪存延长了存储设备的使用寿命。
垃圾回收是在出于任何原因复制数据时将块标记为"脏"的过程,而不是简单地直接清除它们。脏块仅在以后某个时间点擦除,例如系统空闲时,但早于当系统将再次需要这些块的的时间。请记住,擦除块是一种缓慢的操作,因此在某些情况下,适当的垃圾回收可以提高性能
图 8 展示了原始 NAND 管理算法如何被视为控制器将物理擦除块( PEB )映射到逻辑擦除块(LEB),并将特定的 NAND 操作抽象为简单的读取和写入操作:

图 8:原始 NAND 操作通过控制器抽象。
当原始 NAND 芯片连接到系统,试图实现"透明"控制器以简单地将 NAND 编程、读取和擦除操作转换到类似 HDD 的读写操作时,它严重影响了闪存的性能和使用寿命。这就是为什么 Linux MTD 子系统几乎总是被基于原始 NAND 特性的文件系统使用,并且可能在这之间还有一层,如UBI 和 UBIFS 就是一个例子,而不是文件系统直接访问块设备。
如果您想了解有关磨损均衡的更多信息,请查看 Micron 的 TN-29-42:NAND 闪存设备中的磨损均衡处理技术 (PDF) 和维基百科上的"磨损均衡"文章(以及其参考资料,包括一些LWN.net文章)。有关垃圾回收,请阅读 Micron 的 TN-2960:单级单元 NAND 闪存中的垃圾回收 (PDF)。
要详细了解原始 NAND 设备和应用程序之间抽象层的完整实现,请完整阅读MTD、UBI 和 UBIFS 文档。当然,为了了解实现的细节,您也可以看看Linux内核源代码。
尽管原始 NAND 操作非常复杂,为了创建磨损估计模型,我们必须在一定程度上了解这些操作,抽象这种复杂性的简单方法是购买具有集成控制器的 NAND 设备,也称为托管型NAND。就集成电路而言,常用类型包括嵌入式 USB、eMMC 和 UFS。在这里,我们将重点讨论eMMC。
eMMC 闪存分析
工业级嵌入式系统中最常用的大容量闪存技术之一是 eMMC(嵌入式多媒体卡),它由原始 NAND(通常是 MLC 或 TLC)及其附带的 NAND 控制器组成。它从底层操作系统中抽象了大部分管理软件堆栈。eMMC 标准由 JEDEC 维护,在注册后可免费使用。本文撰写时发布的最新标准是嵌入式多媒体卡电气特性标准 5.1(注册后下载 PDF)。
由于控制器提供了高质量的抽象层(前提是它来自可靠的制造商)因此,只要采取一些预防措施,就可以安全地使用能够处理块设备操作的文件系统。在 Toradex 嵌入式 Linux BSP 中,对于具有 eMMC 闪存的计算机模块,我们默认使用 EXT4 文件系统。图 9 总结了原始 NAND 和托管型 NAND 在控制器方面的差异:

图 9:原始 NAND 和 eMMC 控制器
在本文的示例中,我们分析了具有 1024 个块的 4GB MLC eMMC,在实际情况中,它可以时 Micron的MTFC4GAJCN-1M-WT,这在 Apalis iMX6Q 1GB 最新版本的模块上使用。我们还假设平均块寿命为 3000 次擦除周期,这只是一个根据我们实际经验的猜测。它不是从上述器件的数据表中得到的。
使用 eMMC 的挑战在于收集有关控制器实施和模块生命周期的详细信息,这些细节可能公开提供,也可能不公开。此外,人们可能更喜欢选择提供良好专有健康报告的制造商。eMMC 标准为此保留一些寄存器,但是否使用它们则是可选的。为案例研究选择的 eMMC 具有详细的健康报告,有关该报告的详细信息可从 Micron 的 TN-FC-32:e.MMC 设备运行状况报告获取,该报告可在 Micron 网站的 eMMC 软件部分注册后获得。在 Micron 网站的这一部分中,您还可以找到本文稍后将使用的 emmcparm 工具,以及非常有帮助的 TN-FC-25:了解 eMMC 的 Linux 驱动程序支持。
命令和寄存器
eMMC 标准通过包含电源、CMD、DAT0-7 和 CLK 信号的总线定义了操作。
CMD 是一个串行通道,不同的 CMD 值表示不同的操作。将命令从主机发送到卡后,将通过同一串行行从卡向主机回复应答。相关数据可通过 DAT 信号线获取问。为了更好的说明,图 10 中提供了多块读取操作的图示。幸运的是,我们将使用的所有工具已经实现并抽象成为了 eMMC 通信。
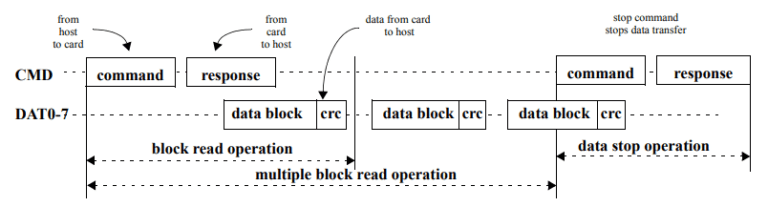
图 10:多块读取操作。(资料来源:JEDEC标准号84-B51,第5.3.1节,第9页)
eMMC 标准还定义了具有不同信息集的寄存器,这些信息又可通过特定的 CMD 命令进行访问。表 2 显示了 eMMC 寄存器:

表2:e.MMC寄存器(资料来源:JEDEC标准号84-B51,第5.3章,第8页)
Extended Device Specific Data(以前称为Extended Card Specific Data)是提供运行状况报告的位置。它包含:
供应商专有运行状况报告,32 字节长
设备寿命估计类型 A,以 10% 的增量提供运行状况
在我们的eMMC 上指的是SLC块
设备寿命估计类型 B,以 10% 的增量提供运行状况
在我们的eMMC 上指的是MLC块
EOL 预警信息,按平均预留块来反映设备寿命
返回正常值、警告值(消耗的预留块的 80%)和紧急值(消耗的保留块的 90%)
一个相关的问题:如果这些信息是现成的,为什么不只使用JEDEC标准的数据?
原因之一是健康报告仅从JEDEC标准第5.0版中引入。
另一个是值的低分辨率(10% 增量),这对写入少量数据的测试应用程序不利。需要很长的运行时间才能获得任何有用的信息。
此外,提供独立于特定技术(如既能可以时 SD 卡,也可以是采用 MTD的原始闪存)的闪存磨损估计工具更加灵活。
Micron 专有运行报告
对于本主题,我们(几乎)不在 JEDEC 标准的讨论范围之内。我们需要了解的唯一信息是如何访问此数据。我们只需要知道,我们必须使用一般的命令,即GEN_CMD或CMD56,作为入口门,从器件中获取这些数据。eMMC 规范中特定应用命令部分包含更多详细信息。
我们接下来需要的信息是供应商实现的运行状况报告。在我们的例子中,它包含在 Micron 的 TN-FC-32: e.MMC 设备运行状况报告中,可在 e.MMC 软件区域中找到。
可获取下面的数据:
坏块计数器和信息:工厂坏块计数、运行时坏块计数和剩余块计数。这还提供有关每个块上关于失效页地址和是否在擦除或者编程中失效。
块擦除计数器:所有块的最小、最大和平均块擦除计数,以及每个块擦除计数。
块配置:每个块的物理地址,以及它是 SLC 还是 MLC。
要访问其中每个参数,必须由 CMD56 发出特定的参数。
关于在计算机模块在生命期内 eMMC 支持的说明
计算机模块制造商通常有长期供货策略,因为他们的客户可以从中受益,如工业和医疗用户。例如,Toradex 保证超过 10 年的供货。
通常,单个器件的生命周期比整个计算机模块的生命周期短。因此,新版本硬件会随着时间的推移发布,并与产品更改通知 (PCN) 进行说明。这是使用计算机模块的主要优势之一 ,它抽象了重新设计的复杂性。
另一方面,您可能会想出一个不符合最新标准的 eMMC 的硬件。这是另一种实际方案,您希望有一个磨损估计解决方案以某种方式脱离特定的技术或标准。
闪存运行状况
在任何给定时间点的闪存运行状况可以理解为已耗尽的容量百分比。为了简单起见,我们将假设在早期阶段没有块磨损,磨损水平是最佳和静态的,并且没有写入放大,即理想的场景。
总使用量可以从擦除总数或可写入设备的数据总量中获得:

或者
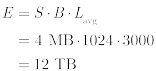
这里:
E 表示总使用量,以擦除周期数(顶部)或字节数(底部)表示
B 表示块的数量
Lavg 表示块的平均块寿命,以块擦除计数表示
S 块的大小,以字节表示
根据定义,擦除周期的总数更准确,因为块磨损由块擦除引起。因此,前一种方法往往优于后者。
在上面的示例中,一旦将 1536000 次擦除均匀地分布的块上执行,或者将大约 6 TB 的数据写入设备,则其生存期已达到其生存期的 50%。
在 Linux 上监视闪存运行状况
要Linux 中监视前几节中讨论的闪存运行状况参数,需要从 eMMC 设备中提取有意义的信息的软件。可达到此目的的开源工具是 mmc-utils。它实现了大量 eMMC 协议,包括从Extended Card-Specific Data (EXT_CSD) 寄存器读取数据,并以人们可读格式显示数据。它包括 JEDEC eMMC 5.0 标准中定义的器件寿命。让我们通过运行不带任何参数的软件来简要了解一下它,其打印了帮助信息:
root@colibri-imx6:~# mmc
Usage:
mmc extcsd read
Print extcsd data from
mmc extcsd dump
Print raw extcsd data from
上面的输出侧重于 extcsd 操作。如果我们执行 extcsd 读取命令,我们可以获取一系列信息,包括 JEDEC 运行状况。让我们看看输出的开头或第一行:
root@colibri-imx6-05097264:/app# mmc extcsd read /dev/mmcblk1
=============================================
Extended CSD rev 1.7 (MMC 5.0)
=============================================
这证实了我们有一个符合 JEDEC 5.0 标准的 eMMC。然后,我们可以筛选输出以获取 JEDEC 定义的运行状况:
root@colibri-imx6:~# mmc extcsd read /dev/mmcblk1 | grep LIFE
Device life time estimation type B [DEVICE_LIFE_TIME_EST_TYP_B: 0x01]
Device life time estimation type A [DEVICE_LIFE_TIME_EST_TYP_A: 0x01]
eMMC Life Time Estimation A [EXT_CSD_DEVICE_LIFE_TIME_EST_TYP_A]: 0x01
eMMC Life Time Estimation B [EXT_CSD_DEVICE_LIFE_TIME_EST_TYP_B]: 0x01
root@colibri-imx6-05097264:~# mmc extcsd read /dev/mmcblk1 | grep EOL
Pre EOL information [PRE_EOL_INFO: 0x01]
eMMC Pre EOL information [EXT_CSD_PRE_EOL_INFO]: 0x01
在上面的示例中,我们看到运行状况估计设备寿命在 0% 到 10% 之间,并且具有正常的 EOL前的状态。因此,它是一个新的设备。如果我们尝试获取供应商的专有运行状况报告,我们发现它无法通过最新 mmc-utils 获得。甚至稍早的 ChroiumOS 也只显示零:
root@colibri-imx6:~# mmc-cos extcsd read /dev/mmcblk1 | grep -i health
Vendor proprietary health report:
[VENDOR_PROPRIETARY_HEALTH_REPORT[301]]: 0x00
[VENDOR_PROPRIETARY_HEALTH_REPORT[300]]: 0x00
[VENDOR_PROPRIETARY_HEALTH_REPORT[299]]: 0x00
然而,人们总是可以编写一些补丁来尝试扩展该工具的功能。一个可用作测试的示例可能类似于如下代码所示。请注意,为了简洁起见,此代码未完整显示,例如省略验证功能:
/ Retrieve the erase count for each block
// A two-step approach is needed (read number of tables and then read tables)
int do_block_erase_info(int nargs, char **argv)
{
ret = CMD56_data_in(fd, cmd56_how_many_tables, data_in);
printf("Block erase count\n");
printf("Block\tErase\n");
for(table_idx = 0; table_idx < how_many_tables; table_idx++){
ret = CMD56_data_in(fd, (table_idx * 256) + cmd56_retrieve_base, data_in);
for(physical_block = 0; physical_block < 128; physical_block++){
printf("%d\t%d\n",
(256*data_in[0+2*physical_block]) + data_in[1+2*physical_block],
(256*data_in[256+2*physical_block]) + data_in[257+2*physical_block]);
}
}
}
然后,我们可以用这个应用程序,从 Micron 的闪存中检索以下数据:
int do_bad_block_count(int nargs, char **argv);
int do_bad_block_info(int nargs, char **argv);
int do_block_erase_count(int nargs, char **argv);
int do_block_erase_info(int nargs, char **argv);
int do_block_addr_type_info(int nargs, char **argv);
另一种选择是使用供应商的特定工具,如 Micron 的 emmcparm,该工具不仅提供 JEDEC 的综合寿命报告,而且还提供上面列出的和在实际使用中举例说明的更详细的参数。
在撰写本文时(2019 年 8 月),emmcparm 自 2016 年 5 月 27 日发布版本 2.6.0 以来到2019 年 6 月 5 日发布的 4.4.0 版本期间有不定期的更新。该工具具有多种功能,其中运行状况为一个:
root@colibri-imx6:~# emmcparm_arm
--spare_block
--bad_block
--erase_count
--sect_count
I/O 跟踪
I/O 跟踪可以是一个有用的指示器,表明闪存在迅速耗尽,也可以是一个调试指示器,用于显示哪些应用程序正在写入过多的数据。I/O 跟踪为不依赖于 JEDEC 标准或 eMMC 供应商运行状况报告的磨损估计模型提供输入数据。因此,它是实现一种灵活的工具的想法,可以扩展到所有各类使用原始 NAND 作为存储的技术。
实现可靠的 I/O 跟踪机制的第一步是掌握一些关于 Linux I/O 堆栈工作原理的基本知识。在非常高的层面上,通常在应用程序开发期间发生的情况是编写一些用户空间代码,并执行文件操作。
操作的完成方式可能因您使用的库和语言而异,但在某些时候,会从用户空间过渡到内核空间。此时库的函数会对内核进行系统调用。除了使用经过良好测试的成熟库(如 C 标准库),您也可以自行进行系统调用,但代价是需要实现抽象,并容易出错。
然后,Linux 内核通过通常称为 I/O 堆栈或存储堆栈来处理该 I/O。作为最后一步,它通过低级设备驱动程序将数据发送到设备,在使用 eMMC 的情况下,该驱动程序必须符合 JEDEC 标准。图 11 在尽可能的最高层面上,标识了原始 NAND 和 eMMC 设备的堆栈
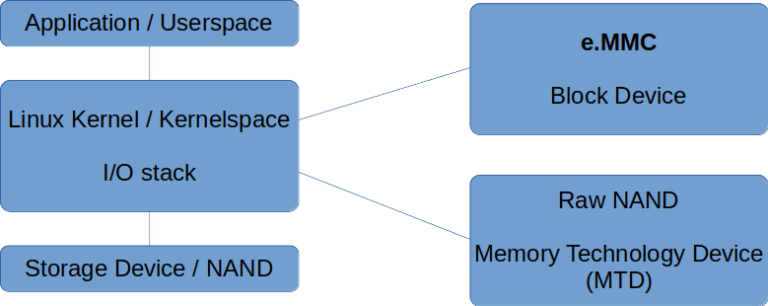
图 11:eMMC 和原始 NAND 的 I/O 堆栈
我们可以从上到下浏览内核堆栈:
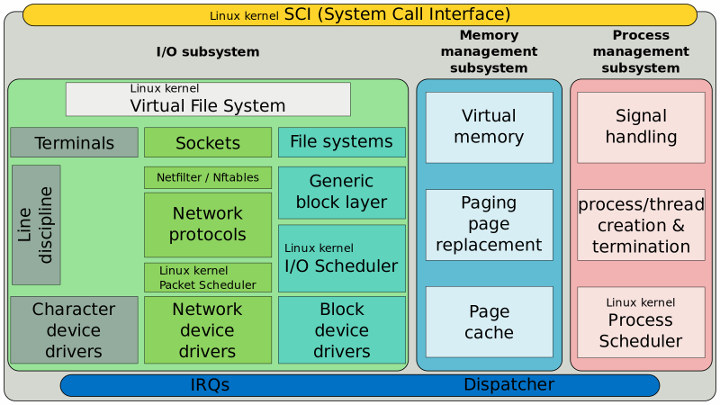
图12:Linux内核结构的简化概述。(来源:维基百科)
virtual file system是用户空间 API 的抽象层。
file system本身实现特定结构来定义与文件相关的概念。
generic block layer,通常包括文献中的 I/O scheduler,是堆栈中处理所有块 I/O (BIO) 的地方,此抽象文件系统的块设备等。
I/O scheduler获取 I/O 请求的队列,并根据特定算法将它们发送到块设备驱动程序。它尝试最大化块 I/O 性能,scheduler的选择计可能会影响闪存的延迟、吞吐量和使用。
人们最初可能认为,观察随时间而写入闪存的次数,以获得写入速率,是能够可以从用户空间完成,并且这就足够了。然而,这种方法最大的问题是,它不能获得精确的测量。
如图 13 所示,Linux 内核是一个复杂的系统,它通过其堆栈实现缓存层,以防止不需要的磁盘访问。这是一个顾虑,因为磁盘操作总是很慢;即使闪存的出现,并且其有更快的操作速度,现在也需要延长存储设备的生命周期,这些缓存和队列对此有所帮助:

图 13:缓存、缓冲区、队列和同步。
Linux 内核实现了一个称为页缓存的缓存,该缓存位于高层 VFS 和低层文件系统之间。它是内核最受欢迎的缓存系统。它使数据可供用户空间应用程序可靠使用,而无需通过文件系统。
进一步深入 I/O 堆栈,由于 I/O 合并,优化存储硬件,以及通常以吞吐量为目标的 I/O 队列的使用,可能会产生缓存副作用。作为合并 I/O 的示例,有一种回写机制,该机制将数据保留到必需写为止,从而防止碎片化以及使用零碎数页或块。这些机制也使得很难跟踪特定进程实际上写到闪存的数量。
作为数据同步的附带说明,对于嵌入式系统应用(尤其是没有备用电源)可能至关重要,并且可能会影响闪存寿命。因此,要注意只有在绝对必要才保存数据,即使在意外断电的情况下。用户按机器触摸屏面板上的"保存"按键就是此类应用的一个示例。
测量 I/O 写入
从我们对所有实际到达闪存的写入进行监视和核算的角度来看,问题变得更加明确:
在 Linux 堆栈的哪些位置,我们保证能够测量实际到达闪存的写入量
我们如何测量这一点?(我们可以使用哪些工具?)
不同于运行状况测量(可用于收集数据的工具数量有限),可用于 Linux 内核堆栈观察的工具是非常丰富的。图 14 显示了这方面的一个示例,取自Brendan Gregg的博客。Brendan Gregg 是 Linux 性能监控领域知识最渊博的一个人。
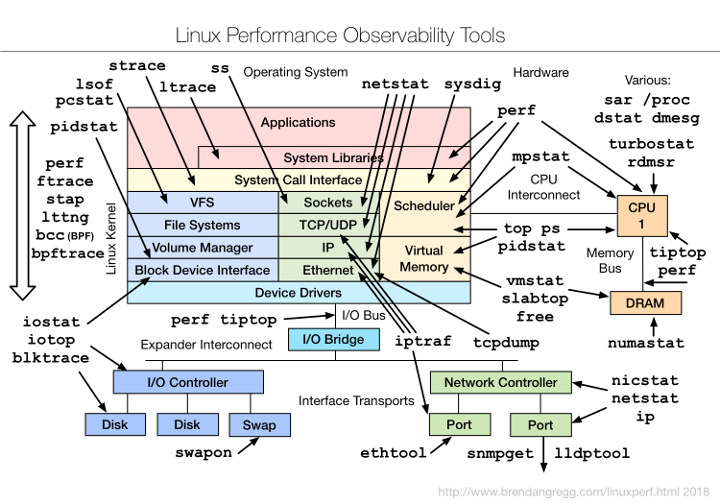
图 14:Linux 性能观察性工具。(来源:Brendan Greg)
在我的研究过程中,我使用了iotop来跟踪用户空间操作,和blktrace/blkparse来准确跟踪块级I/O和实际到达闪存的内容。由于我不是内核黑客,这个主题仍有很大的研究空间,所以我不会以任何方式暗示这些是最适合或最优化的工具。例如,perf 跟踪和 eBPF 也在我的待办事项列表中。有一篇关于Linux块I/O跟踪的有趣文章,以及互联网上的许多其他资源,包括Linux内核文档本身。
在块级别跟踪 I/O 的重要意义在于准确性,因为这是确保写入操作实际到达闪存的唯一途径,而不是从缓存中刷新或由内核中的后续文件系统操作合并。这一点很重要,因为真正需要统计的是块写入的次数(实际上是擦除),而不仅仅是应用程序尝试写入的实际数据量。
让我们在实践中简要地了解一下如何使用 iotop 和 blktrace。
iotop 有一些选项可以很方便地帮助完成此任务,并且很容易收集和分析时间戳、写入计数以及负责这些写入的进程:
root@colibri-imx6:~# iotop –help
Options:
-o, --only only show processes or threads actually doing I/O
-b, --batch non-interactive mode
-a, --accumulated show accumulated I/O instead of bandwidth
-k, --kilobytes use kilobytes instead of a human friendly unit
-t, --time add a timestamp on each line (implies –batch)
-q, --quiet suppress some lines of header (implies --batch)
你可以参考下面的示例:
root@colibri-imx6:~# dd if=/dev/urandom bs=4k count=100000 | pv -L 25k > testfile
root@colibri-imx6:~# iotop --only --batch --accumulated --kilobytes --time –quiet
TIME TID PRIO USER DISK READ DISK WRITE SWAPIN IO COMMAND
2019-08-02 03:11:19 50 be/4 root 0.00 K 24.00 K -0.00 % -0.00 % pv -L 25k
2019-08-02 03:11:20 50 be/4 root 0.00 K 52.00 K -0.00 % -0.00 % pv -L 25k
2019-08-02 03:11:21 50 be/4 root 0.00 K 80.00 K -0.00 % -0.00 % pv -L 25k
2019-08-02 03:11:22 50 be/4 root 0.00 K 104.00 K -0.00 % -0.00 % pv -L 25k
2019-08-02 03:11:23 50 be/4 root 0.00 K 128.00 K -0.00 % -0.00 % pv -L 25k
当使用blktrace时,事情变得有点复杂。文档是开始查阅的好地方。在没有过滤的情况下,以实时模式下运行,它可以呈现大量的输出:
root@colibri-imx6:~# blktrace -o - /dev/mmcblk1 | blkparse -i -
179,0 0 26 0.000114661 304 A WS 4509800 + 8 <- (179,2) 4468840
179,0 0 27 0.000117328 304 Q WS 4509800 + 8 [jbd2/mmcblk1p2-]
179,0 0 28 0.000119661 304 M WS 4509800 + 8 [jbd2/mmcblk1p2-]
179,0 0 29 0.000127328 304 U N [jbd2/mmcblk1p2-] 1
179,0 0 30 0.000131661 304 I WS 4509736 + 72 [jbd2/mmcblk1p2-]
179,0 0 31 0.008860277 279 D WS 4509736 + 72 [kworker/0:3H]
179,0 0 32 0.012586780 279 C WS 4509736 + 72 [0]
幸运的是,在 blktrace 和 blkparse 中实现了诸多筛选器来简化任务。表 3 列出了它们,并简要说明:

表 3:过滤掩码(来源:blktrace 手册)
为了跟踪最后一刻用户空间PID信息和在闪存上发出的确认写入操作,我们将会使用write过滤器。在 blkparse 端,进一步筛选选择以下跟踪操作,这些跟踪操作从 blkparse 文档中引用:
C - 完成:上一个发出的请求已完成。输出将详细说明该请求的扇区和大小,以及请求的成败。
I - 插入:请求正在被发送到 io 调度器,从而添加到内部列队并稍后由驱动完成。此时请求已完全形成。
寿命估算
通过记录 I/O 跟踪和闪存运行状况,可以确定两个相关性:
随时间推移的闪存运行状况
在写入率方面的闪存运行状况
请注意,这两种相关性都会随时间而发生,因此通过在单独的存储介质上实现本地 DB(或相同的介质,但考虑其对闪存磨损的影响)并运行系统足够长的时间,可以收集足够的数据估计上述相关性,然后计算寿命。
以擦除次数测量的总使用量:
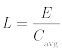
以字节或者多个字节测量的总使用量:

这里:
L 是秒为单位的寿命
E 是以擦除次数(顶部)或字节(底部)表示的总使用量
Cavg 是平均所有块擦除计数;即块擦除总数除以每秒擦除的块
Wavg 是调整后的平均写入速率(以每秒字节为单位)
请注意,在第二个公式中,调整后的平均写入速率是运行闪存运行状态后的写入速率,包括相关的写入也统计在内。因此,在实践中,这考虑到诸如写入放大和系统写入等因素,这些在应用程序角度进行监视或估计理论值时不会被考虑的。
关于磨损估计的备注
温度会影响闪存寿命。您必须考虑使用 pSLC 模式(如果可用)、使用静态与动态磨损均衡、存在的坏块、设备接近 EOL 时会发生什么情况以及存在备用块等可能性。
记得通过文献来寻找与您的设计模型相关的注意事项和其他的方面。
闪存分析工具
Toradex 实验室目前正在开发闪存分析工具,旨在您的设备上抽象估算 eMMC 设备上磨损的所有复杂性。在本文中,我们一直在介绍此任务的原则、注意事项、案例和复杂性。现在,可能很清楚为什么这是一个复杂的任务,应用程序开发人员可能宁愿选择避免。

图 15:闪存分析工具
如上图 15 所示,该工具旨在成为全面的辅助工具,而不仅仅是一个寿命估计工具。它被设计利用 Torizon 平台的 Docker 容器运行并作为模块化解决方案,您可以在核心模块的 BSP 上选择要使用的内容。
由于当前预测模型是使用线性回归方法实现的,因此,该工具的路线图包括对解决方案的深入研究,以创建具有更高准确性的新模型,支持更多用例。我们能够预见到基于 AI 和大数据的解决方案的可能性。

上面展示了 UI 的外观,我邀请您率先测试下,并告诉我们您对此的看法。
总结
估计闪存寿命可以像从闪存运行状况中给出的块大小公式计算一样简单,也可以像开发工具并生成在数秒内估计设备寿命所需的模型一样复杂。您可以根据产品的使用场景来选择投入多少精力,或仅选择图 16 中概述的重要元素。无论如何,这是宝贵的信息。
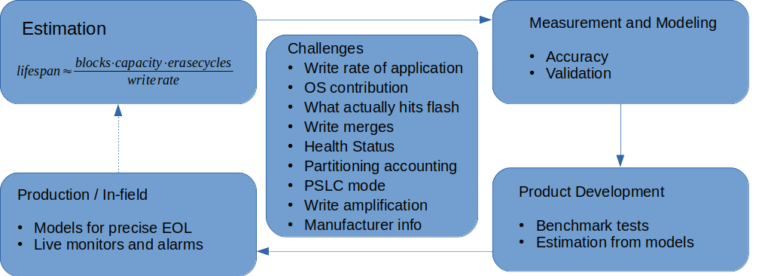
图 16:估计和预测原始 NAND 寿命。
与更简单的计算相比,复杂的方法提供了一些好处。除了更精确的结果外,您还可以将您工具某个版本部署到生产中,以获得更精确的生命周期数据。这还为您提供了监控功能和触发警报的能力,从而进行更具预测性的维护。最后,一系列底层和高层面的工具,包括 Micron 的 emmcparm、mmc-utils 和 Toradex 闪存分析工具,都可以让您轻松创建可靠的解决方案。我希望您在阅读这个博客文章时有一个愉快的经历。




 /3
/3 






curton 2019-9-18 21:56