
SRAM使用的是ISSI的61LV5128,8位宽,19条地址线。FPGA内部有一个地址产生计数单元,因此数据读操作时输出管脚的时序起点就是这些地址产生单元。因为希望快速读SRAM,所以状态机代码读SRAM是第一个时钟周期送地址(SRAM的OE#信号始终接地),第二个时钟周期读数据。系统时钟使用的是50MHz(20ns),SRAM的标称读写速度可以达到8ns。感觉上20ns操作一个8ns的SRAM似乎很可行。
<?xml:namespace prefix = v ns = "urn:schemas-microsoft-com:vml" /><?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
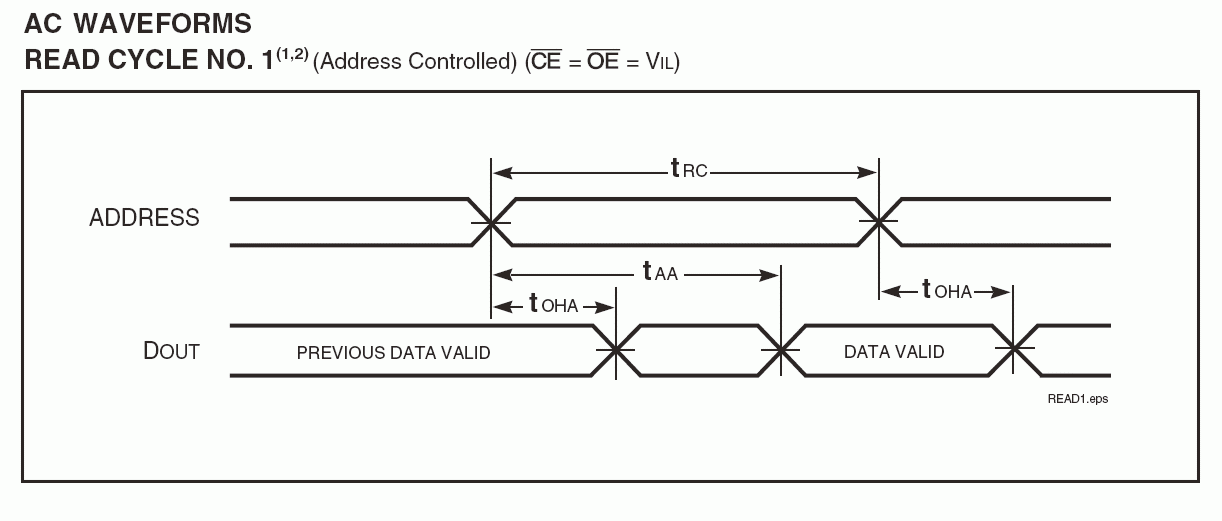
上面SRAM的读时序中,tRC=8ns,也就是说地址稳定后最多等待8ns数据总线上的数据是有效的(上面的说明只是相对于SRAM管脚而言,不考虑其它条件)。那么在地址稳定后的0—8ns之间的数据可能是有效的也可能是无效的我们无从得知(也许不到8ns数据就已经有效了,可以说8ns是一个很保守的读取时间),但是8ns以后一直到数据地址发生变化的tOHA时间内的数据一定是稳定的。
上面罗嗦了一大堆,下面步入正题。我们要计算FPGA和SRAM的数据总线接口上的input delay值,按照公式:Input max/min delay = 外部器件的max/min Tco + 数据的PCB延时 – PCB时钟偏斜。
我们先计算一下地址总线最终稳定在SRAM输入管脚的时间,应该是FPGA内部时钟的launch edge开始到FPGA输出管脚的延时加上地址总线在PCB上从FPGA管脚到SRAM管脚的延时。前者的值为5.546ns—9.315ns(由FPGA时序分析得到,不包括launch edge 的clock network delay),后者的值为0.081ns—0.270ns(由PCB走线长度换算得到)。那么地址总线最终稳定在SRAM输入管脚的时间max=9.585ns,min=5.627ns。
其次,我们可以从SRAM的datasheet查到(也就是上面的时序图的tRC)地址稳定后Tco=8ns数据稳定在SRAM数据总线的输出管脚上。数据总线从SRAM管脚到达FPGA输入管脚的PCB延时为0.085ns—0.220ns。
从上面的一堆数据里,我们需要理出一条思路。首先需要对这个时序进行建模,和FPGA内部的寄存器到寄存器的路径和类似,这个时序模型也是从FPGA内部寄存器(输出管脚)到FPGA内部寄存器(输入管脚),不同的是这个寄存器到寄存器间的路径不仅在FPGA内部,而是先从寄存器的输出端到FPGA的输出管脚,再从PCB走线到外部器件SRAM的输入管脚,然后经过了SRAM内部的Tco时间后,又从SRAM的输出管脚经PCB走线达到FPGA的输入管脚,这个输入管脚还需要有一些逻辑走线后才达到FPGA内部寄存器的输入端。整个模型就是这样,下面看这个输入管脚的Input delay如何取值。大体的这个路径如下图,也可以简单的把两个寄存器之间的路径理解为FPGA内部的一个大的组合逻辑路径。
根据Input delay的定义,加上我们这个模型的特殊性,我个人认为input delay的路径应该是从CLK的launch edge开始一直到FPGA的DATA总线的输入端口。那么所有的路径延时值在前面都给出了。最后计算得到input max delay = 17.765,input min delay = 13.731。
无疑,上面得出的input delay参数都有些偏高了(由于该工程使用器件为Altera MAX ii EPM570,内部资源有限速度也无法做得太高,加之工程的其它控制模块也相对有些复杂,所以这对于该工程在20ns内操作8ns的SRAM带来了一定的挑战。),下面进行时序分析即建立时间和保持时间余量的计算。
建立时间:
Data Arrival Time = Launch Edge + Clock Network Delay + Input Maximum Delay of Pin + Pin-to-Register Delay = 0+3.681ns+17.765ns+ Pin-to-Register Delay = 21.446ns + Pin-to-Register Delay
Data Required Time = Latch Edge + Clock Network Delay to Destination Register - utSU = 20ns + 3.681ns – 0.333ns = 22.348ns
Clock Setup Slack = Time Data Required - Time Data Arrival Time = 22.348ns – (21.446ns + Pin-to-Register Delay) = 0.902ns - Pin-to-Register Delay
若满足时序要求,则:0.902ns - Pin-to-Register Delay > 0 即Pin-to-Register Delay < 0.902ns
保持时间:
Data Arrival Time = Launch Edge + Clock Network Delay +Input Minimum Delay of Pin Pin-to-Register Delay = 0+3.681ns+13.731ns+ Pin-to-Register Delay = 17.412ns+ Pin-to-Register Delay
Data Required Time = Latch Edge + Clock Network Delay to Destination Register + utH = 0+3.681ns+0.221ns = 3.901ns
Clock Hold Slack = Time Data Arrival - Time Data Required Time = 17.412ns+ Pin-to-Register Delay – 3.901ns = 13.511ns + Pin-to-Register Delay
若满足时序要求,则:13.511ns + Pin-to-Register Delay > 0
Pin-to-Register Delay 时间从时序报告里得出在4.711ns—6.105ns范围内。那么建立时间余量显然不满足,建立时间时序违规。而保持时间则不会违规。
虽然这个工程如此这般分析下来,似乎在这个工程条件下用50MHz的速率来读存取时间为8ns的SRAM是不可行的。但是在我初步调试这个工程的时候,没有进行时序约束和时序分析的情况下就进行了板级调试,而且调试的最终结果是正确的,读写SRAM的操作好像没有出现预想之外的问题。这让我很是纳闷,为什么理论上进行静态时序分析不可行的时序最后却通过了板级调试了呢?思考了很久,归纳了以下几种可能性:
1, 首先不排除上文里时序分析的方法有误,很期待各位高手指点;
2, 时序分析的有些太苛刻了,可能有些地方都是想到了最坏的情况(当然这是必要的,有些时序违规不是一天两天能出现的,甚至听说过恩年出现一次的问题,这是最让人郁闷的事,记得我们部门里的机器在实验过程中出现了一点问题立刻大群人马围坐分析,毕竟我们搞的都是~~不是一般的马虎不得的东西呵呵);
3, 有些违规最严重的路径可能是地址的高位,因为我们操作的时候都是递增地址读数据的,高位地址变化周期长,它的时序违规表现的不是那么明显;
4, 还真有那么一次,发现一个从SRAM读出的很小块的显示图片区错误了,不排除是读时序问题造成的;
5, SRAM标称的8ns是最大的等待时间,或许和开篇提到的一样,SRAM实际上数据有效等待时间不需要那么长,也就是上面分析中外部器件的Tco减小了。
这是我能想到的可能的情况,也许还有别的问题,也期待各位提出自己的一些看法。




 /4
/4 






文章评论(0条评论)
登录后参与讨论