
位宽比较大的加法器,直接相加,肯定不是一个明智的做法。流水线加法器,
还是42bit加法器
module top(clk,rst_n,data1,data2,data3);
input [41:0] data1;
input [41:0]data2;
input clk,rst_n;
output reg [42:0] data3;
reg [41:0] a,b;
always@(posedge clk or negedge rst_n)
if(!rst_n)
begin a<=42'd0;b<=42'd0; end
else begin a<=data1;b<=data2; end
wire c1,c2,c3;
wire [14:0] out1,out2,out3;
// 一级流水
add U1(
.cin(1'b0),
.clock(clk),
.dataa(a[14:0]),
.datab(b[14:0]),
.cout(c1),
.result(out1));
// 二级流水
add U2(
.cin(c1),
.clock(clk),
.dataa(a[29:15]),
.datab(b[29:15]),
.cout(c2),
.result(out2));
// 三级流水
add U3(
.cin(c2),
.clock(clk),
.dataa(a[41:30]),
.datab(b[41:30]),
.cout(c3),
.result(out3));
always@(posedge clk or negedge rst_n)
if(!rst_n)
begin data3<=33'd0; end
else data3<={out3[12:0],out2,out1} ;
endmodule
RTL视图
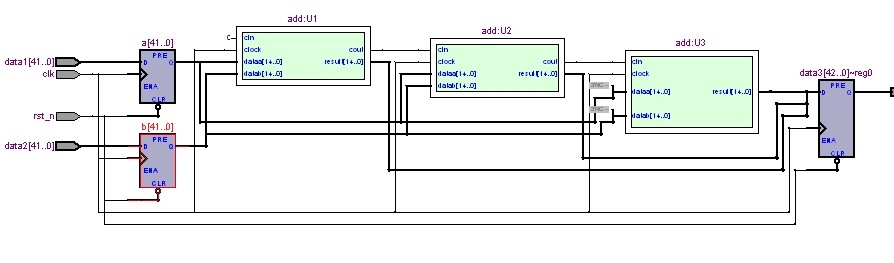
每一级加法器内部都有寄存器输出,用Technology Map Viewer 看U1,如下(部分)
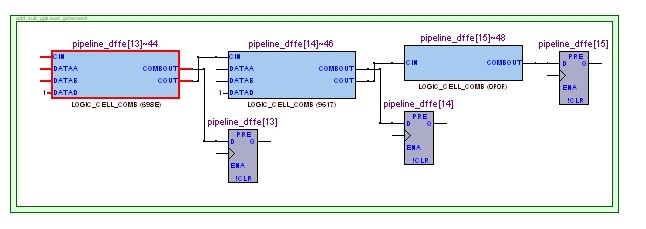
不会出现b[0]到data[41]那样,经过40多个组合逻辑LUT全加器,每一级流水是15bit全加器,所以,最大的路径延时,是从U1的进位端 c1(pipeline_diffe[15]) 到 U2的进位端 c2(pipeline_diffe[15]) ,或者从b[0]到 out1[14](pipeline_diffe[14]) 等等,总之最多经过15个全加器组合逻辑 !
但是,上边的流水线形式,结果不能一个时钟周期输出,3级流水线,需要3个时钟输出结果!
最大Fmax

把上边的流水线程序改动一下,输入数据缓存几个节拍,可以实现1个时钟输出一个结果
module top(clk,rst_n,data1,data2,data3);
input clk,rst_n;
input [41:0] data1;
input [41:0]data2;
output reg [42:0] data3;
// 第一拍 作为第一级流水数据源
reg [41:0] a,b;
always@(posedge clk or negedge rst_n)
if(!rst_n)
begin a<=42'd0;b<=42'd0; end
else begin a<=data1;b<=data2; end
// 第二拍 作为第二级流水数据源
reg [41:0] a2,b2;
always@(posedge clk or negedge rst_n)
if(!rst_n)
begin a2<=42'd0;b2<=42'd0; end
else begin a2<=a;b2<=b; end
// 第三拍 作为第三级流水数据源
reg [41:0] a3,b3;
always@(posedge clk or negedge rst_n)
if(!rst_n)
begin a3<=42'd0;b3<=42'd0; end
else begin a3<=a2;b3<=b2; end
wire c1,c2,c3;
wire [14:0] out1,out2,out3;
// 第一级流水,低15位相加
add U1(
.cin(1'b0),
.clock(clk),
.dataa(a[14:0]),
.datab(b[14:0]),
.cout(c1),
.result(out1));
// 第二级流水,中15位和低15位的进位 相加
add U2(
.cin(c1),
.clock(clk),
.dataa(a2[29:15]),
.datab(b2[29:15]),
.cout(c2),
.result(out2));
// 第三级流水,高15位和中15位的进位 相加
add U3(
.cin(c2),
.clock(clk),
.dataa(a3[41:30]),
.datab(b3[41:30]),
.cout(c3),
.result(out3));
always@(posedge clk or negedge rst_n)
if(!rst_n)
begin data3<=33'd0; end
else data3<={out3[12:0],out2,out1} ;
endmodule
还有没有其他的方法???加菲在《玩转 IP core》讲座中提到了一种“先运算再选择”的方法,第一步算出所有可能的运算结果,即预先算出进位是“0”和“1”的结果;第二步根据进位进行选择,得到最终结果。这样相对于,原来的逐次进位的,信号的建立时间可以减少。但是,系统单元的面积也会急剧增加。
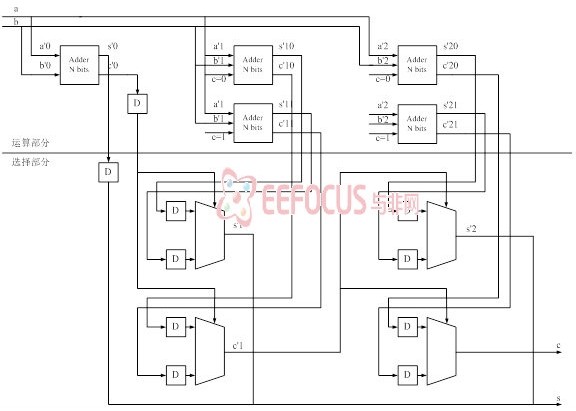
话说,上篇博客开篇 提到的问题还没解决 ,下篇续。。。。。
pengchengcheng082_593158939 2014-7-28 22:04
用户230340 2014-7-14 11:21
pengchengcheng082_593158939 2014-5-27 08:15
用户1737382 2014-5-26 16:04
pengchengcheng082_593158939 2014-5-7 20:01
用户1737382 2014-5-7 09:26