最近在看流水线,先介绍一下流水线技术,主要有以下几个关键意思
1:面积换速度
2:能提高数字系统的工作频率和数据吞吐量
3:以消耗较多的寄存器为代价,在性能上的提升
先介绍一种四级流水线的加法器,
它的特点是每两位bit作为一个流水线阶段进行相加,
这样在输入数据四个时钟周期后得到数据。
需要
1:在每一级暂存输入数据
2:暂存每个阶段的结果
实现代码如下
module Addr_8bit_4l(Clk, Rst, In_a, In_b, Cin, Sum, Cout); //可综合模块——4级流水线8bit全加器,时钟上升沿触发,可同步复位,实现中高速加法运算
input Clk,Rst; //时钟输入端,同步复位端
input [7:0] In_a; //8位二进制输入a端
input [7:0] In_b; //8位二进制输入b端
input Cin; //进位输入端
output [7:0] Sum; //8位和输出端
output Cout; //进位输出端
//--------------------------输入输出端口数据类型定义---------------------------
wire Clk,Rst;
wire [7:0] In_a;
wire [7:0] In_b;
wire Cin;
wire [7:0] Sum;
reg Cout;
//-------------------------------中间变量声明---------------------------------
reg [7:2]a6_Temp,b6_Temp; //高6位输入缓存
reg [7:4]a4_Temp,b4_Temp; //高4位输入缓存
reg [7:6]a2_Temp,b2_Temp; //高2位输入缓存
reg [1:0]Sum2_Temp; //低2位和缓存
reg [3:0]Sum4_Temp; //低4位和缓存
reg [5:0]Sum6_Temp; //低6位和缓存
reg [7:0]Sum_Temp; //总8
reg Cout2_Temp,Cout4_Temp,Cout6_Temp; //低2位、低4位、低6位的进位缓存
//--------------------------------功能块开始----------------------------------
always @ ( posedge Clk) //时钟Clk上升沿触发
if(Rst==1) //如果Rst为高电平——
begin
a2_Temp <= 0; //同步复位
a4_Temp <= 0; //同步复位
a6_Temp <= 0; //同步复位
b2_Temp <= 0; //同步复位
b4_Temp <= 0; //同步复位
b6_Temp <= 0; //同步复位
Sum2_Temp <= 0; //同步复位
Sum4_Temp <= 0; //同步复位
Sum6_Temp <= 0; //同步复位
Sum_Temp <= 0; //同步复位
Cout2_Temp <= 0; //同步复位
Cout4_Temp <= 0; //同步复位
Cout6_Temp <= 0; //同步复位
Cout <= 0; //同步复位
end
else //否则——
begin //流水线开始
//-------------------------------第1级流水线------------------------------
a6_Temp<=In_a[7:2]; //输入In_a高6位存入缓存a6_Tem
b6_Temp<=In_b[7:2]; //输入In_b高6淮嫒缓存b6_Temp
{Cout2_Temp,Sum2_Temp}<=In_a[1:0]+In_b[1:0]+Cin; //输入In_a、In_b低2位接受进位并相加,和存入Sum2_Temp,进位存入Cout2_Temp
//-------------------------------第2级流水线------------------------------
a4_Temp<=a6_Temp[7:4]; //输入In_a高4位存入缓存a4_Temp
b4_Temp<=b6_Temp[7:4]; //输入In_b高4位存入缓存b4_Temp
Sum4_Temp[1:0]<=Sum2_Temp; //全加和低2位寄存
{Cout4_Temp,Sum4_Temp[3:2]}<=a6_Temp[3:2]+b6_Temp[3:2]+Cout2_Temp; //输入In_a[3:2]In_b[3:2]接受第3级的进位Cout2_Temp并相加
//-------------------------------第3级流水线------------------------------
a2_Temp<=a4_Temp[7:6]; //输入In_a高2位存入缓存a2_Temp
b2_Temp<=b4_Temp[7:6]; //输入In_b高2位存入缓存b2_Temp
Sum6_Temp[3:0]<=Sum4_Temp; //全加和低4位寄存
{Cout6_Temp,Sum6_Temp[5:4]}<=a4_Temp[5:4]+b4_Temp[5:4]+Cout4_Temp; //输入In_a[5:4]、In_b[5:4]接受第3级的进位Cout4_Temp并相加
//-------------------------------第4级流水线------------------------------
Sum_Temp[5:0]<=Sum6_Temp; //全加和低6位寄存
{Cout,Sum_Temp[7:6]}<=a2_Temp+b2_Temp+Cout6_Temp; //输入In_a、In_b高2位接受第3级的进位Cout6_Temp并相加,全加进位输出到端口Cout
end //流水线结束
assign Sum = Sum_Temp[7:0]; //全加和输出到端品Sum
endmodule
仿真测试波形:
每个时钟流水地处理两个bit,顺序从低到高处理完8bit。
第二种树形流水线加法器
这种方法的特点是按树形每级排列加法器结构,加法并行地从树叶开始,一直到树根结束,8bit加法器每次两位相加,共有三级流水线。
实现代码如下:
module Addr_8bit_2(Clk, Rst, In_a, In_b, Cin, Sum, Cout);
input Clk,Rst;
input [7:0] In_a;
input [7:0] In_b;
input Cin;
output [7:0] Sum;
output Cout;
reg [1:0] T_a1;
reg T_a1_cout1;
// reg [1:0] T_a2;
reg [1:0] T_a3;
reg T_a2_cout1;
//reg [1:0] T_a4;
reg [3:0] S_a1;
reg S_a1_cout1;
reg [4:0] S_a2;
reg [7:0]X_a;
reg X_cout;
reg [7:2] a72,b72;
always@(posedge Clk)
begin
///////////////////////////one
{T_a1_cout1,T_a1}<=In_a[1:0]+In_b[1:0]+Cin;
{T_a2_cout1,T_a3}<=In_a[5:4]+In_b[5:4];
a72<=In_a[7:2];
b72<=In_b[7:2];
//////////////////////////two
S_a1[1:0]<=T_a1;
S_a2[1:0]<=T_a3;
{S_a1_cout1,S_a1[3:2]}<=a72[3:2]+b72[3:2]+T_a1_cout1;
S_a2[4:2]<=a72[7:6]+b72[7:6]+T_a2_cout1;
/////////////////////////three
X_a[3:0]<=S_a1;
{X_cout,X_a[7:4]}<=S_a2+S_a1_cout1;
end
assign Cout=X_cout;
assign Sum=X_a;
endmodule
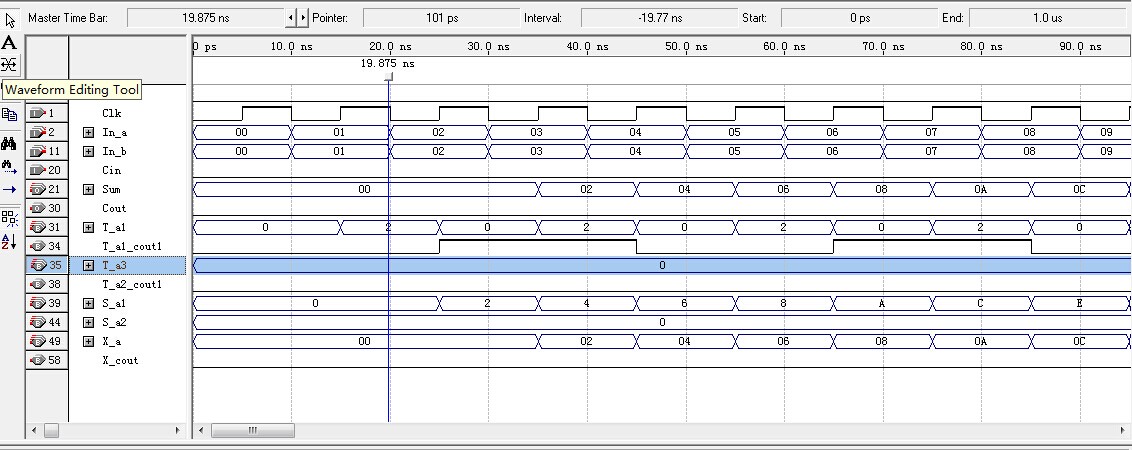
仿真波形:
总结:这两种方法,一种是串行的流水线形式,一种是并行的流水线形式,仅供参考。






 /4
/4 






用户377235 2015-10-12 21:18