
MDIO和I2C,除了前者是推挽后者是开漏之外,它们在信号策略上也有很大的区别。
I2C在空闲状态下为持续的高电平,当主机或者设备要发送数据的时候,才会拉低时钟线和数据线。
MDIO是不管有没有数据要发送,反正不停的给出时钟和扫描PHY地址,有效操作可以随时插入这个过程。
以下内容以可编程逻辑器件为基础,说明round-robin arbitration的原理。
(下文中提到的mask概念,是构建conserving轮叫调度的部分,它会使得主机跳过其中某些从机,只扫描需要的从机;而AM335x的MDIO寄存器的mask概念,是中断屏蔽的意思,对AM335x而言,它的MDIO始终在扫描所有的设备,用户没有办法跳过其中某个地址,要停止polling的唯一办法,是禁止整个MDIO功能。)
首先了解一下神马是round-robin arbitration:
==================================================
http://rtlery.com/articles/round-robin-arbitration
Round Robin Arbitration
Round-robin arbitration is a scheduling scheme which gives to each requestor its share of using a common resource for a limit time or data elements. The basic algorithm implies that once a requestor has been serves he would "go around" to the end of the line and be the last to be served again. The simplest form of round robin arbiter is based on assignment of a fixed time slot per requestor; this can be implemented using a circular counter.
Alternatively, the weighted round robin arbiter is defined to allow a specific number X of data elements per each requester, in which cas X data elements from each requestor would be processed before moving to the next one. Round robin arbiters are typically used for arbitration for shared resources, load balancing, queuing systems, and resource allocation. Any application requiring a minimal fairness where none of the requestors is suffering from starvation is a valid application for a round robin arbiter.
What Is A Round Robin Arbiter?
An arbiter is a logical element serving to select the order of access to a shared resource. An arbiter would typically employ a scheduling algorithm to decide which one on several requestors would be serviced. The round robin arbitration, in its basic form, is a simple time slice scheduling, allowing each memory or a limited processing resource in a circular order. For more complicated applications of round robin arbitration, such as packet switching, using a fixed time slice for each requestor is inefficient as the processing time of each data element, impacts the fairness of the arbitration. Therefore, there are several flavors of round robin arbitration, each suited for a different application.
Work Conserving Round Robin Arbitration
Weighted Round Robin Arbiter
首先了解一下怎么设计round-robin arbitration:
==================================================
http://rtlery.com/articles/how-design-round-robin-arbiter
How To Design A Round Robin Arbiter
First we need to start with a clear definition of what we actually want the arbiter to do. The round robin arbiter design requirement can be summed up in a list:
1. One cycle calculation, so the arbiter can grant different requestors in each cycle.
2. Wraparound functionality, meaning that the arbiter does not loose cycles at the end of each round when moving from a grant to the last active requestor, back to the first one.
3. Work conserving functionality, so no cycles are lost on requestors that are inactive.
Implementation
The figure shows a design that covers all those points, given it is implemented using the right logic:
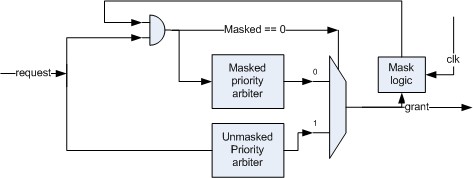
The wrap around functionality, results from the two priority arbiters. Once the masked request vector has no active requests, the mux will cause the grant to be generated from the non-masked priority, which will naturally start at the first requestor. The two priority arbiters implement simple find-first-set priority encoding, returning the first bit which is set in their respective input vectors.
The following figure illustrates the wrap around process for a case where the request vector is stable during the whole time with 3 request bits set. The figure shows a process occurring over 3 cycles and then wraps around back to the first requestor.
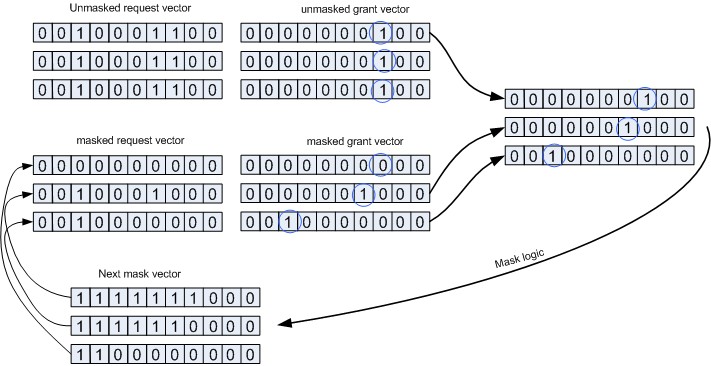
In the first cycle, the masked grant vector is all 0, so the mux selects the unmasked grant and therefore grants the first request (bit #2). The mask logic calculates the mask for the next cycle, by masking all requestors below the selected one as well as the selected requestor itself, so bits 0-2 are masked and all the rest are enable.
(第一个周期,masked grant vector全为0,因此mux会选择unmasked grant vector,对应的是bit #2。之后mask logic会计算下一个周期的mask值,它会掩蔽所有低于刚刚被选择的请求,以及被选择的请求本身,因此bit 0-2会被掩蔽,而其他的则被使能。==> 执行bit2)
At the second cycle, the masked request vector which is the result of an AND between the first cycle "Next mask vector" and the request vector is not all 0, so the resulting grant is bit #3 which is the lowest bit set in the "masked request vector".
(第二个周期,masked request vector的值是第一个周期的next mask vector和request vector相与的结果,也就是1111111000B & 0010001100B = 0010001000B。因此masked grant vector取此值的最低有效位,为0000001000B。==> 执行bit3)
Following the same principle, at the third cycle, the selected grant is bit #7, and the Next mask vector has only bit 8 and 9 bit.
(第三个周期,masked request vector的值是第二个周期的next mask vector和request vector想与的结果,也就是1111110000B & 0010001100B = 0010000000B。因此masked grant vector取此值的最低有效位,为0010000000B。==> 执行bit7)
At the forth cycle, the AND of the request vector and the mask vector result in an all 0 masked request vector so the arbiter uses the unmasked grant vector, returning to grant the first active requestor which is bit #2. The result is a clean wrap around.
(第四个周期,masked request vector = 1100000000B & 0010001100B = 0000000000B,因此调度器将使用unmasked grant vector。==> 执行bit2)
The find-first-set priority logic, makes the arbiter "work conserving" meaning that no cycles are lost between consecutive grants.
(find-first-set的优先逻辑,使调度器工作在conserving模式下。)
The more challenging part of the design is to meet the single cycle timing requirement. As shown above, the logical solution is clear, all you need to do is update the mask according to the latest selected grant and you will get the next grant in the following cycle.
As the demonstrated arbiter has combinational path from input to output, it is clear that minimizing this path through the priority arbiters would result in better overall timing, also for the internal path coming from the mask register.
(* 额,其实没怎么看懂。。。这个学FPGA的来看是不是很简单。。。)
(* state machine是神马?完全没概念。。。)
补充:
这是使用phy_id = 4观察到的寄存器的值:
maria: ----> 40070106
maria: ----> 410000ff
maria: ----> 10
maria: ----> 0
maria: ----> 0
maria: ----> 0
maria: ----> 1
maria: ----> 0
maria: ----> 0
maria: ----> 0
maria: ----> 20043100
maria: ----> 0
maria: ----> 0
maria: ----> 0
根据上面的值来理解AM335x的MDIO寄存器描述:
====================
MDIO Version Register (MDIOVER)
MODID = 0x4007,这是Identified type of peripheral.
REVMAJ = 0x01,这是Management interface module major revision value.
REVMIN = 0x06,这是Management interface module minor revision value.
====================
MDIO Control Register (MDIOCONTROL)
IDLE = 0,说明它在正常工作状态,推挽输出,而不是高阻态;
ENABLE = 1,使能MDIO功能;
HIGHEST_USE_CHANNEL = 1,用户可访问通道最高为1;
PREAMBER = 0,使用标准的Preamble;
FAULT = 0,Fault indicator,因此FAULTENB未使能,所以它无意义;
FAULTENB = 0,不使能错误检测;
INTTESTENB = 0,不使能Interrupt test;
CLKDIV = 0xff,时钟分频为0xff,示波器上观察周期为2us,占空比50%,MDIO的时钟可以设置为不超过最高频率的任意值,它通过边沿检测,并非异步。
====================
PHY Acknowledge Status Register (MDIOALIVE)
ALIVE = 0x10,MDIO alive,用户操作和polling操作都会使它更新。
为了验证AR8031引脚初始状态对它的影响,进行如下操作:
1. 将MII1的RXD0、RXD1引脚配置为GPIO,输出1、1,此时MDUIALIVE=0x80;
2. 将MII1的RXD0、RXD1引脚配置为GPIO,输出0、1,此时MDIOALIVE=0x40;
3. 将MII1的RXD0、RXD1引脚配置为GPIO,输出1、0,此时MDUIALIVE=0x20;
4. 将MII1的RXD0、RXD1引脚配置为GPIO,输出0、0,此时MDUIALIVE=0x10;
第4种情况和AR8031默认使用下拉电阻的值都是0x10。
(* 可能是轮叫调度造成了ALIVE的左移?I am not sure.这个留到以后再深入看。目前根据ALIVE的值,修改对应的phy_id即可。)
====================
PHY Link Status Register (MDIOLINK)
LINK = 0,表示还没有Link上。
====================
MDIO Link Status Change Interrupt Register (MDIOLINKRAW)
LINKINTRAW = 0,没有发生Link的改变。
====================
MDIO Link Status Change Interrupt Register (Masked Value) (MDIOLINKINTMASKED)
LINKINTMASKED = 0,MDIOUSERPHYSELn指示的PHY没有发生Link的改变。
====================
MDIO User Command Complete Interrupt Register (Raw Value) (MDIOUSERINTRAW)
USERINTRAW = 1,MDIOUSERACCESS0的用户指令完成;
====================
MDIO User Command Complete Interrupt Register (Masked Value) (MDIOUSERINTMASKED)
USERINTMASKED = 0;
====================
MDIO User Command Complete Interrupt Mask Set Register (MDIOUSERINTMASKSET)
USERINTMASKSET = 0;
====================
MDIO User Command Complete Interrupt Mask Clear Register (MDIOUSERINTMASKCLR)
USERINTMASKCLEAR = 0,
====================
MDIO User Access Register 0 (MDIOUSERACCESS0)
GO = 0,说明读操作完成,此位自动清零;
WRITE = 0,说明不是写操作,而是读操作;
ACK = 1,说明PHY设备应答了;
REGADR = 0,说明读取的是PHY设备的地址为0的寄存器值;
PHYADR = 0x04,说明PHY的地址为4,对应MDIOALIVE的值0x10 = (1 << 4);
DATA = 0x3100,说明PHY返回的数据为0x3100;
====================
MDIO User PHY Select Register 0 (MDIOUSERPHYSEL0)
LINKSEL = 0,为1则监控MLINK引脚,为0则监控MDIO状态机;
LINKINTENB = 0,没有使能LINK改变中断;
PHYADDRMON = 0,不检测任何PHY设备;



 /5
/5 







文章评论(0条评论)
登录后参与讨论