
把大象关冰箱的步骤 --- NAND FLASH控制器磨损管理算法芯片化硬实现
目前,存储领域包括eMMC,SATA SSD ,PCIe SSD等控制器是一个非常热门的领域。通常,由于NAND FLASH易于损坏的特性,因此需要控制器做额外的工作,才能满足商用可靠存储的需要。
存储控制器的所做的额外工作就是均衡磨损、坏块管理、以及逻辑地址到物理地址映射的管理。通常在存储控制器中需要集成CPU运行并运行相应的软件才能完成上述的功能,而随着存储性能的增加,则需要更高性能的CPU或者多核处理器以及高速的处理算法。
本文目的提出一种可以硬实现的均衡磨损,坏块管理,以及逻辑地址映射的算法,(可芯片化)。用于替代处理器的软件(FTL)实现,从总体上较CPU固件实现有较好的功耗比和高速性能的目标。
首先说明: NAND FLASH的管理说明:
1:NAND FLASH 只能按页写,且只能写干净的页。(一个页一旦写过就不能写第二次,除非被擦除)
2:NAND FLASH 能按页读,这个可以读多次。
3:NAND FLASH 只能按块擦。(一个块包含多个页)。
4:NAND FLASH的出错一般出现在写,和擦除时,如果NAND FLSAH的块在写或者擦除时,出错,则就不能再使用,内部内容需读出写入其他的位置。
5:如果NAND FLASH的管理中,如果重新改写同一地址,则原地址内容作废,逻辑映射一个新地址写入(原因见规则1)。
1:基本操作:读,写;
那么如何设计相应的硬实现算法:首先是考虑写操作,每次写都要写一个干净的地址。因此我们假设有一个模块,每次吐出一个新的干净页地址,那么每次写操作时,都申请从此模块申请一个新地址。
写NAND FLASH的步骤:(把大象关冰箱里的步骤)。
0:主机写入一个逻辑地址(LA logic address)中一个page的数据(PD pagedata)。
1:从地址分配器(FIFO)中申请一个干净页地址(PA physical address),然后写到新的页地址中。(这个步骤前少一步,)
2:记录逻辑地址和物理地址的对应关系。(LA->PA)到映射表。这样完成写的流程。
下次读的时候,
0:主机读取一个逻辑地址(LA logic address)。
1:查找映射表,对应的映射表LA->PA,则读取PA的页数据(PD)。返回主机。这样就完成了读的流程。
这样考虑就是想法简单了,上图是正常的写流程。
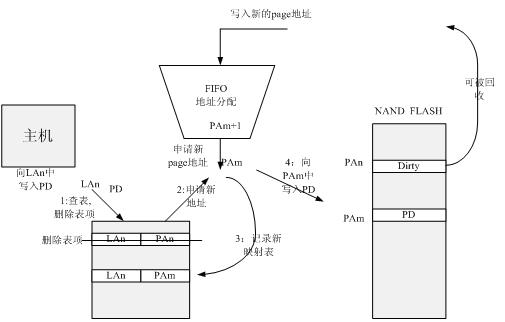
由于写FLASH的步骤,首先要确定原有逻辑地址在映射表里是否存在,映射表相应的表项删除(删除的表项会重新擦除使用,否则很快就会写完)。
写NAND FLASH的步骤:
0:主机写入一个逻辑地址(LA logic address)中一个page的数据(PD pagedata)。
1:查看页地址中是否有相关的逻辑地址表项,如果有,则删除表项,否则直接到下一步。
2:从地址分配器(FIFO)中申请一个干净页地址(PA physical address),
3:记录逻辑地址和物理地址的对应关系。(LA->PA)到映射表。
4:然后写到新的页地址中。
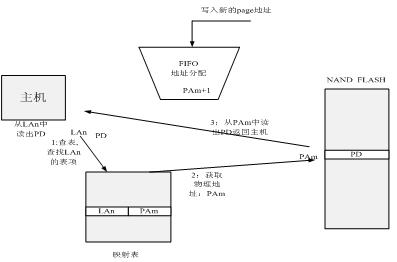
读NAND FLASH的步骤:
0:主机从一个逻辑地址(LA logic address)中一个page的数据(PD pagedata)。
1:在映射标的表项中,查找LAn的表项。
2:查找对应的物理地址(PAm)。
3:从PAm读出PD并返回主机。
2:擦除:擦除
从上述的机制来看,每次写操作时,都会占用一个PAGE,而假设原有的逻辑地址内部存储数据,则原有的逻辑地址对应的物理地址则被废弃,因此需要将这些物理地址重新擦除后重新使用。(否则FLASH写完一遍后,再也不能再写)。
另一问题,page按页来写,而擦除按照块来擦除,假设每个块有512个page。
按照上述机制,每个块都有512个page放入申请单元中,而这些page写操作时,被依次申请,也就是说,BLOCK中每个page都会被写满,当这些物理page被重新写时,则原有的page变成脏页,可以被擦除。但是前提是512个page的都凑齐。那擦除的情况分为两种,
对于情况1,可以类似数通领域的组片,每个被重复写的逻辑地址,就释放一个物理地址,收齐一个块中所有的物理地址(都被写过后,释放掉),就可以重新擦除后,重新放置在地址分配器中。
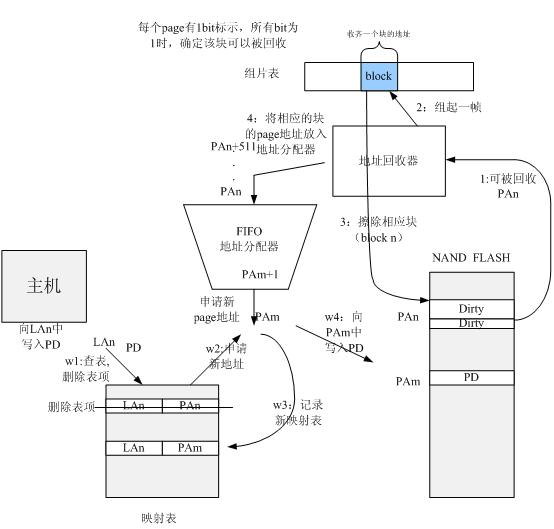
对应情况1来说:其触发条件新的写入page,原有page被回收后,放入地址回收器中:
因此擦除的步骤可以分为:
1:获取被回收的物理地址PAn;
2:回收器检查PAn所在的BLOCK n,所有的page是否收齐(每个块用1bit标示,所有bit收齐为1时,可被回收),如果收齐转入步骤3,否则置PAn已回收的标示。
3:通过NFC(NAND FLASH)擦除相应块。
4:释放地址(PAn … PAn+511)到地址分配器,供新的写请求申请。
对于情况2,其触发条件为,地址分配器中的可分配地址低于水位线(可用的地址少于一定数量)。

对于情况2来说:
1:地址分配器FIFO低于阈值,用于触发地址回收器。
2:地址回收器,查找还剩最少page没有收齐的BLOCK及相应的page(PAx,PAy,PAz)。
3:在映射表中,查找相应的物理地址所对应的逻辑地址;
4:通过地址分配器申请新的物理地址,并填写在原来的映射表中。
5:读取原物理位置的数据PD(X,Y,Z)。
6:将数据写入新的申请的物理地址中。(4,5,6可以串行执行,循环多次,将未收齐的地址读出)。
7:转移完毕后,擦除原来的块(BLOCK)。
8:将擦除后的块地址,写入地址分配器中。
完成后(就多出了接近一个BLOCK的地址空间,供上层应用写入)
3:坏块管理;
NAND FLASH在写或者擦除时,会出错,出错时,需要将此块标记成坏块,以后将不能使用。
因此坏块管理模块,需要记录所需要不能使用的坏块。因此我们讨论坏块出现的两种情况:
1:在擦除时,出错,则此block为坏块,坏块管理单元记录坏块。
2:在写某page出错,首先所在块(block)读出剩余的page,分配新的物理地址,更新映射表,同时对该块进行擦除,如果出错标记为坏块,如果有幸不出错,则可以重新将地址放入地址分配器。
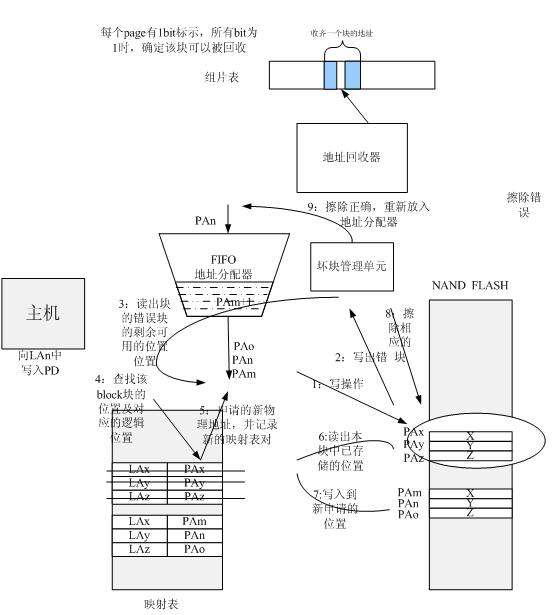
对于情况1来说:操作相对简单;
对于情况2来说:坏块管理单元的操作较为复杂:
1:写操作,触发坏块管理单元工作。
2:写出错。坏块管理单元受到触发,记录当前的物理坏块的位置(M)。
3:同时将地址分配器中M坏块中的剩余地址读出,(禁止再向这些page中写入数据)。读出后,申请新的块中的page,将当前数据写入flash。
一种积极的处理方式如上图所示:
4:查找该block对应剩余物理地址所对应的逻辑地址。
5:申请新的物理地址并记录新的映射表。
6:读出物理块地址所对应的数据。
7:将数据写入新申请的物理地址。
注释:步骤4,5,6,7可以顺序执行,循环多次,取决于该block的已用的page的个数;
8:等搬完毕后,重新擦除该块(M);
9:如果擦除成功,则将地址重新放入分配池,否则该块丢弃。
另一种消极的方法:
在步骤3后,只需要记录当前块位置,将M坏块中的剩余地址读出后,放入地址回收器,等待该块剩余位置被重新写时,则该page被废弃,由地址分配器收齐所有地址后再进行擦除。
剩余步骤从8开始,直接擦除该块,擦除错误,直接废弃该块,擦除成功可重新放入地址分配器。
4:均衡磨损;
均衡磨损是NAND FLASH的基本功能,通过将可用的地址放入先入先出的地址分配器中,能够保证均衡磨损的效果。
如何将磨损程度最小的可用块,放入地址分配器(FIFO),是本节讨论的要点?
这个问题转化为:设计均衡磨损管理模块,其功能将磨损程度最小的块,首先放入地址分分配器。
均衡管理模块需要将统计所有块的磨损次数,然后找到最小磨损的块。对于需要分配地址时,如果涉及到查找最小磨损块,则可能会影响写的效率。因此,涉及一个链表,将块的磨损次数按照次数的多少进行排序,如果磨损次数相同,则按照地址的大小排序。如此一来,则可以保证,则需要快速申请有效地址时,则可以按照链表的顺序,迅速将可用块地址放入地址分配器。

因此:对于均衡磨损来所,涉及到链表的生成和链表的读取;
那什么时候均衡管理模块将数据放入地址分配器中?
这样,根据上述的算法,就可以使所有的块,均衡的磨损,保证所有块被擦除的次数一致。
5:总结一下;
回应开头,本文的目标是设计一种可以硬件(硬件描述语言)实现的NAND FLASH的均衡磨损的算法。替代CPU+软件的方式实现在当前较热门的存储控制器中。
(1),所有的操作,都需要触发条件(读,写,擦除,坏块管理,均衡磨损),其他时间可以模块可以休眠,因此功耗容易控制;预计比CPU有更好的能耗比(也跟实现相关)。
(2)硬件实现不取决于CPU的能力,特别是对于PCIe的NAND FLASH控制器来说,可以达到非常高的处理能力,瓶颈在NAND的读写擦除速率。
(3)缺点:设计中需要多个表项的管理。
分别是1:映射表,管理逻辑page地址和物理page地址的对应关系。
2:地址回收器中,block内page的回收表;(每个page需要1bit表示)。
3:均衡管理模块中的链表,存储所有块的磨损次数以及链表信息。
这些表项与NAND的大小有关系(是8G/16G/32G?),这些表项是按比例增加的,因此NAND,这些表项需要大块的RAM存储。
其次映射表的查找,同时需要设计CAM模块及操作,来加速表的查找。
如果在PCIe的控制器中,可以放在外部DRAM中,掉电检测时,存储在NAND中,加电时再将数据读出。如果没有外部DRAM,则就需要将映射表一部分放入NAND中,另一部分放入片内SRAM中,同时也会占用较多的SRAM。 同时需要不断的取出及存入NAND中(这个设计同时保证可靠性就是一个挑战)。
(4):总结,此种算法应该适合应用于高速的NAND控制器中,替代高性能多核CPU来实现FTL。具有较高的能耗比与可行性。
用户1632137 2016-6-3 14:32
用户435905 2016-4-21 20:25
潜龙思瑞 2016-2-14 13:53
hotriver_276559161 2016-1-26 08:46
用户1012893 2016-1-11 09:07
用户468979 2015-12-14 10:22
用户377235 2015-11-24 17:46
用户377235 2015-2-26 11:27