此前关注这一问题也挺久了,貌似始终没有看到有说服力的答法:只看到国内某个奇特的自媒体宏论说 M1 版 MacBook 的 8GB 就相当于别家电脑的 16GB RAM 这种没给出论据的说法。
毕竟就直觉来看,存储介质一个萝卜一个坑,同一份数据不会因为处理器的指令集不同或者操作系统差异,就会有大小上的区别。而且即便内存延迟、带宽不同,容量大小依然是客观存在:两个瓶子的出水口口径不同,流量自然有差异,但瓶子的容量并不会因为流量差异而成为某个相对值。不过系统性能层面倒的确可能形成差异,比如内存压缩、操作系统、软件对内存的利用效率等。
事实上 Max Tech 也并不是什么专业和客观的媒体,这家 youtuber 此前的“高端”言论也不少。不过这里总结下他们这期的内容,可作为 M1 版 MacBook 内存容量问题的相关参考,虽然也存在问题就是了。而且有一点必须要说,就是大量 Youtuber 和 up 主判断某电脑好不好用,基本就是看看剪片子流畅与否,这种具有偏向性的应用场景并不代表普罗大众。但这期内容仍然具有一定的参考性,期望给各位抛砖引玉吧(还是第一次说别人的东西是抛砖…)。
1.软件优化相关
Max Tech 这部分的观点是说,糟糕的软件优化对于 4K 视频剪辑绝对是悲剧,内存再大也没用。尤其是将 Premiere Pro 和 Final Cut Pro 做比较,即便 Premiere Pro 用在更大的内存、更快的 SSD 硬件平台上,针对相同片源的输出速度上也可能完全比不上 Final Cut Pro,而且可能差距甚大。这就是软件的威力了。
而且此前 Max Tech 制作过一期“视频编辑最佳容量 RAM”的视频,发现对 Premiere Pro 而言,内存容量到一定程度后,对于视频输出的时间就已经没有帮助了。而到了近代,macOS 和 Windows 操作系统层面本身也有编辑视频上的效率差异。
他们还特别提到 1 年前,用 AMD Threadripper (3970X,32 核)+ Nvidia Geforce RTX 2080 Ti + PCIe Gen 4 SSD 搭了一台 PC;然后拿它跟 Mac Pro (2019 款,15000 美元)作了对比。单纯从通用和图形计算之类的性能跑分来看,前者是碾压后者的。但如果用来做视频的话,包括 4K 视频剪辑、HEVC 转码等,Mac Pro 仍然更快(双方都用 Premiere Pro 的情况下)……此处主要是为了说明 macOS 效率明显更好…
Max Tech 对于“日常工作”的定义估计就是剪片子,所以我觉得这部分内容并不具有代表性,更多数据就不给了,大家有兴趣可以去看看。
不过 Final Cut Pro 的针对性优化,以及以此为代表的软件生态,的确可以作为某种内存利用率对比参照。对系统比较懂的同学可以谈谈。
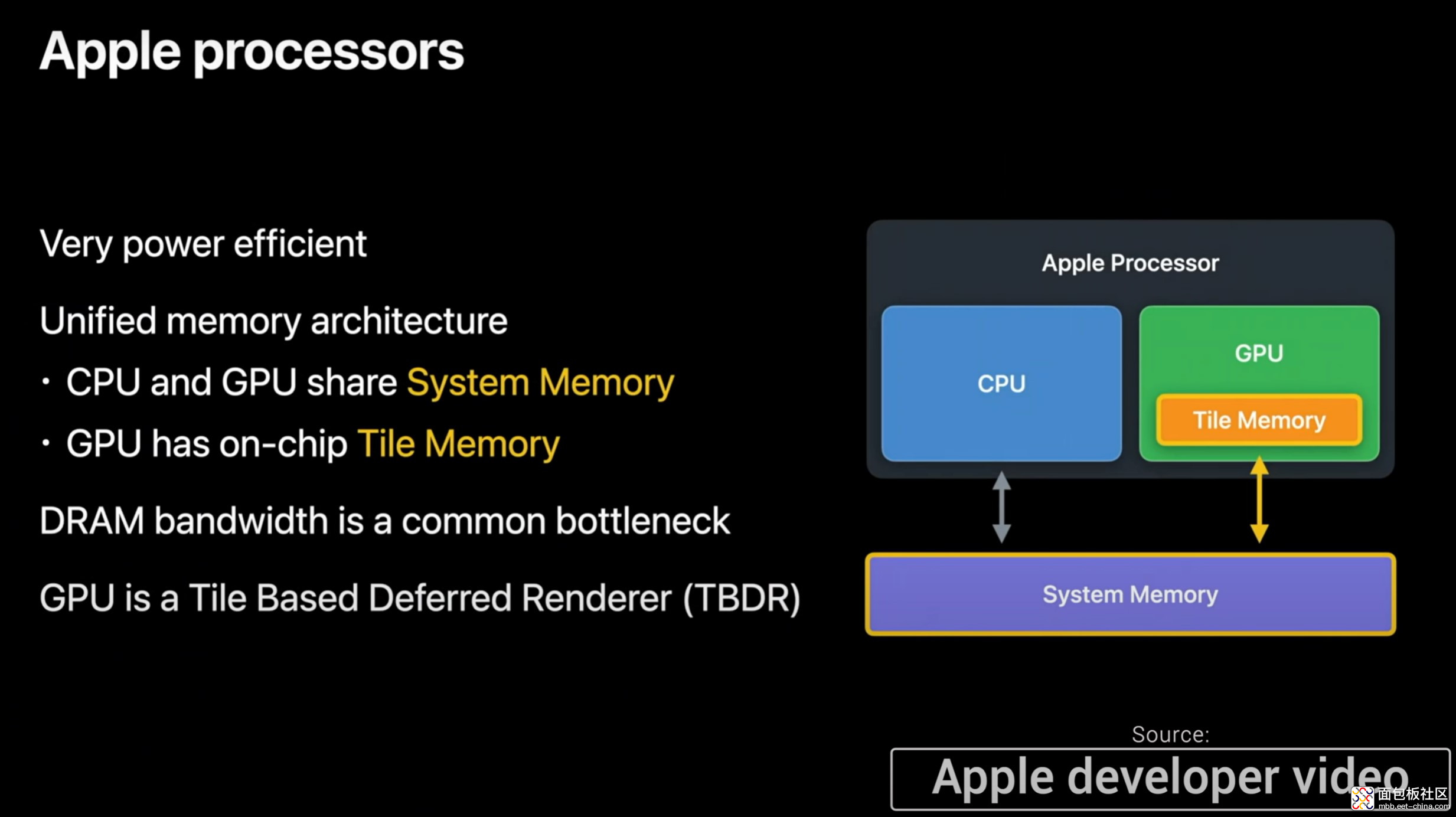
2. Apple Silicon 的内存带宽与延迟优势
M1 平台有个特性叫 UMA,unified memory architecture 统一内存架构。这一点应该也是众所周知的了。M1 这颗芯片把内存直接封装在了计算 die 的旁边。
传统的即便配了核显的处理器(典型的比如 Intel 的酷睿处理器),虽然 GPU 和 CPU 构成同一个 SoC,但 CPU 和 GPU 的内存仍然是两个不同的空间,因为 CPU 和 GPU 对内存的使用方式其实是不同的。两种的数据交换需要在不同空间之间做复制。
而 UMA 针对 CPU、GPU 不再分配专用区域,内存是同时分配给两者的,不需要复制操作。这种提高内存利用率的方法,效率、延迟都提高了。
这可能对内存的延迟、吞吐都提出了更高的要求(因为这两种处理器对内存的需求是不一样的)。至于具体怎么实现的,我不清楚,迟点再去研究一下。
此外,针对 M1 搭配内存延迟和带宽的问题,Max Tech 援引了两个东西。其一是 XDA 上有个用户的发言,如上图所示,具体的各位高人来辨别下真假吧。“They also managed in a cheap platform (mac mini = $700) get 4266MHz memory working with about half the latency of any x86-64 I’ve seen. The mac mini can manage a random cacheline (assuming a relatively TLB friendly pattern) of around 30-33ns.”
“Maybe the usual Intel Core i7/i9 or Ryzen 5000 look rather quaint with their 60ns or higher memory latencies.” Max Tech 的评论则提到“Apple’s Unified Memory is so fast, tasks use less RAM and when RAM needs to be used it can clear out much faster as well.”
另一份援引的数据来自 AnandTech,这个是 AnandTech
很早之前做的 M1 的内存延迟测试。M1 的内存总位宽是 128bit,8 x16bit 通道,LPDDR4X 4266,峰值带宽 68.25GB/s。
带宽部分相关的应用实测,Max Tech 用的是 Lightroom Classic 做 4200 万像素照片输出速度可以秒杀 2020 款 5K iMac,包括 16GB RAM 版。
AnandTech 另外也提到每颗 Firestorm 大核心读取内存带宽就能大约达到 58GB/s,写入则有 33-36GB/s。“最重要的是,取决于是标量还是矢量指令,内存复制带宽大约为 60-62GB/s。单颗 Firestorm 核心能够几乎完整地利用内存控制器,这一点非常惊人,我们以前也从未见过这样的设计。”
(参考 AnandTech
针对 Tiger Lake-U 做存储性能测试时提到的,More importantly, memory copies between cache lines and memory read-writes within a cache line have respectively improved from 14.8GB/s and 28GB/s to 20GB/s and 34.5GB/s. 仅供参考,对比对象各位可以点开链接去看。这份数据是 Tiger Lake-U 的,好像 Tiger Lake-H45 是另一回事……)
上面这张图,据说是 64GB 版的 16 寸 MacBook Pro,和 8GB 版的 M1 MacBook Air,在 Lightroom Classic 上的输出性能比较。感觉这个数据还是挺有趣。不过仍需考虑今年酷睿处理器 Tiger Lake 其实在内存带宽上相比前代还是有变化。
而上图中的 16 寸 MacBook Pro 用的处理器是第九代酷睿 Coffee Lake,算是比较老的架构了。具体的各位自己去调查吧,总体应该都不及 M1。另这份对比中的变量过多,不只是内存容量的问题了。
3. GPU 工作方式
另外 Max Tech 特别提到了苹果 GPU 的 TBR 特性。前两周正好
写过一篇文章谈桌面和移动 GPU 的。一般我们说桌面 GPU 常见 IMR(立即渲染),而移动端 GPU 对功耗和带宽都更敏感,所以无法像桌面 GPU 那样大手大脚做内存的存取操作,所以普遍在用 TBR(基于 Tile 的渲染)结构,也叫分块渲染。就是把画面分成一个 tile 一个 tile 地做渲染,GPU 如果能再配上片上 cache 可以存在 tile 数据,那么就能进一步减少内存的存取操作。
其实苹果 GPU 在架构上延续了 Imagination 的设计。所以论立即-延后这件事,苹果的 GPU 都普遍在用相比 Arm、高通之类更延后的 TBDR(tile-based deferred rendering)结构。有兴趣的可以去看看 Imagination 的 blog 对 TBDR 的解释。从介绍来看,M1 上的 GPU 也是这么搞的。这也属于常规嘛。
这种设计实现的应该是图形计算节约系统带宽。说起来感觉好像有一定的道理?(不过基于 tile 的渲染方式,可能在桌面平台也很早就存在了)不过针对这一部分,Max Tech 又拿 M1 和 Intel 十一代酷睿比视频转码输出,真的也是够了!?又不是比编解码器,数据这里就不给了。
后面 Max Tech 也再度提到了,苹果教育开发者如何降低内存和带宽利用的开发方法。不过上面这张 ppt 的出处我没找到,貌似是图形开发?提及 4K 帧 FP32 image 处理,令其实现带宽上 62% 的缩减,以及 270MB 的 buffer 节省。貌似与统一内存架构也有关系?有兴趣的同学可以去找找这张图出自苹果的哪个开发者视频,看看具体是怎么说的。
4. SSD 交换和其他
当然另一个要提的肯定是采用高速 SSD 来做物理内存不够时的 SWAP 交换。据说丐版的 MacBook Air 一样用了比较顶尖的 SSD(和以前不同?),确保 SSD 读写上的高速,即便从交换页载入也有比较快的速度(据说…)。
有关 SSD 损耗率的问题,这一点我之前看过蛮多视频,基本上是一个在 MacBook 生命周期内不值得用户去多虑的参数,之前应该是被人炒过了。另外未来要应用 PCIe Gen4 的 SSD,还能实现速度的进一步跃升,“所以 64GB RAM 就更没必要了”,而且传言中 M1X 要配的高性能 Mac 可能不会有 64GB RAM 版本。
还有一些,包括 Max Tech 对比了,如果做视频输出,则 32GB 和 64GB 版的 Intel 处理器同款 Mac 在视频输出速度上相差无几。这个对比其实也偏科了,不过可能对很多日常轻量级办公的用户有参考价值。
以上数据均为内容转述,加了一点不成熟的点评和背景内容补充,有兴趣的同学欢迎去看原视频。也欢迎各位喷,主要就 Apple Silicon 配合内存容量的问题,发表更多的见解。
我自己感觉,缺一个控制变量的测试,可以考虑 Intel Tiger Lake 平台,以及 M1 两者,尽量保持相同的其他配置,来看看更多对存储容量相对敏感的测试,比如多开网页,看双方在内存交换前分别打开了多少网页之类的;而不要光比媒体输出这种单一场景。
而且实际上,YouTube 上有一些从事严肃工业化摄影/摄像工作的工作流,可以比较明显地发现 M1 的短板。不过毕竟 M1 只是个低压处理器,这种程度做对比也没什么意义就是了。











 /5
/5 






curton 2021-7-25 06:04
yzw92 2021-7-23 06:31