
在本篇文章中,我们将展示两种可在FPGA上实现的COTS IEC 62439-3交换机IP核的延迟的比较。第一种是混合使用直通交换和存储-转发交换架构,第二种则是仅基于存储-转发交换技术。
可靠的以太网技术——HSR&PRP
如今,可靠的以太网网络正在获得许多工业自动化应用的认可。这种演变的一个有力证据是国际电工委员会采用了基于高可靠性无缝冗余 (HSR)以太网的协议和用于变电站自动化的并行冗余协议 (PRP) (IEC 62439-3 第 5 和 4 条)。这两种协议都提供零切换延迟时间,在故障情况下不丢失帧,并被当作在第 2 层进行网络监督的强大手段。

图:HSR单播流量环配置示例
HSR帧与传统的以太网基础设施不兼容,而PRP则允许通过两个传统的以太网网络发送重复帧。因此,PRP 的应用领域更为广泛,尽管它并不是专门为“实时”以太网环境设计的。
“实时”意味着在信号发生后的可预测时间内对其进行响应。例如,现代数字控制回路需要低于 10µs的反应时间。最新的基于以太网的控制协议如 EtherCAT或 Sercos III等往往基于硬件来实现可预测的同步行为和极低的延迟时间。
HSR旨在满足为Process Bus设置的严格通信要求。HSR 将每个间隔层中的智能电子设备 (IED) 互连。
PRP适用于Station和Inter-Bay Buses。由于该协议的灵活性,它可以连接许多异构设备。
为了保持通信中的冗余,PRP 和 HSR 网络之间的互连是使用冗余网关执行的。每个 HSR 链路使用两个网关设备连接到每个 PRP LAN。因此,避免了潜在的“单点故障”问题。

图:通过HSR和PRP的变电站网络通信
直通与存储-转发
直通和存储转发 L2 交换机都基于数据包的目标 MAC 地址做出转发决策。它们之间的主要区别是:
—存储转发交换机在收到整个数据包后做出决定。
—直通交换机在分析目标MAC地址后做出转发决定,该地址位于帧的第一部分。
在存储转发交换机中,延迟时间包括接收整个帧所需的时间。因此,与直通交换相比,延迟时间更长。
转发延迟时间
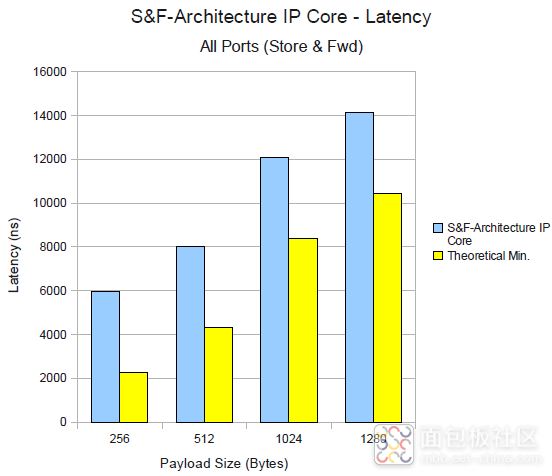
在 Xilinx FPGA 上的虹科HSR-PRP IP 内核中实现这两种方法(一种混合直通和存储转发,另一种是纯存储转发),结果如下:
|
|
|
|
混合直通和存储转发延迟 |
存储转发延迟 |
因此,可以说虹科HSR-PRP IP核实现了专为 PRP 和 HSR 协议设计的交换架构。理论上的最小延迟时间是通过考虑以太网帧的强制字段来计算的,这意味着必须对这些字段进行分析以做出交换决策。在这种情况下,在直通中,时间与帧长度无关,因此它将是恒定的。在纯存储转发方法的情况下,在开始重传之前需要存储整个帧,因此延迟取决于帧长度。可以看出,它比优化的直通交换架构大一个数量级。
结论
分析表明,将直通与存储转发方法相结合的定制架构在任何情况下都能提供最佳的延迟时间。
FPGA在这些新协议中的作用至关重要。一方面,它们允许低延迟、灵活和可扩展的解决方案来满足这些标准中设定的严格要求。另一方面,当工业制造商结合新协议和特定协议为市场提供设备时,FPGA能够减少上市时间和风险。
作者: 虹科工业智能互联, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-3988237.html
版权声明:本文为博主原创,未经本人允许,禁止转载!




 /4
/4 







虹科工业通讯 2022-5-18 16:39
James严 2022-5-14 16:39