
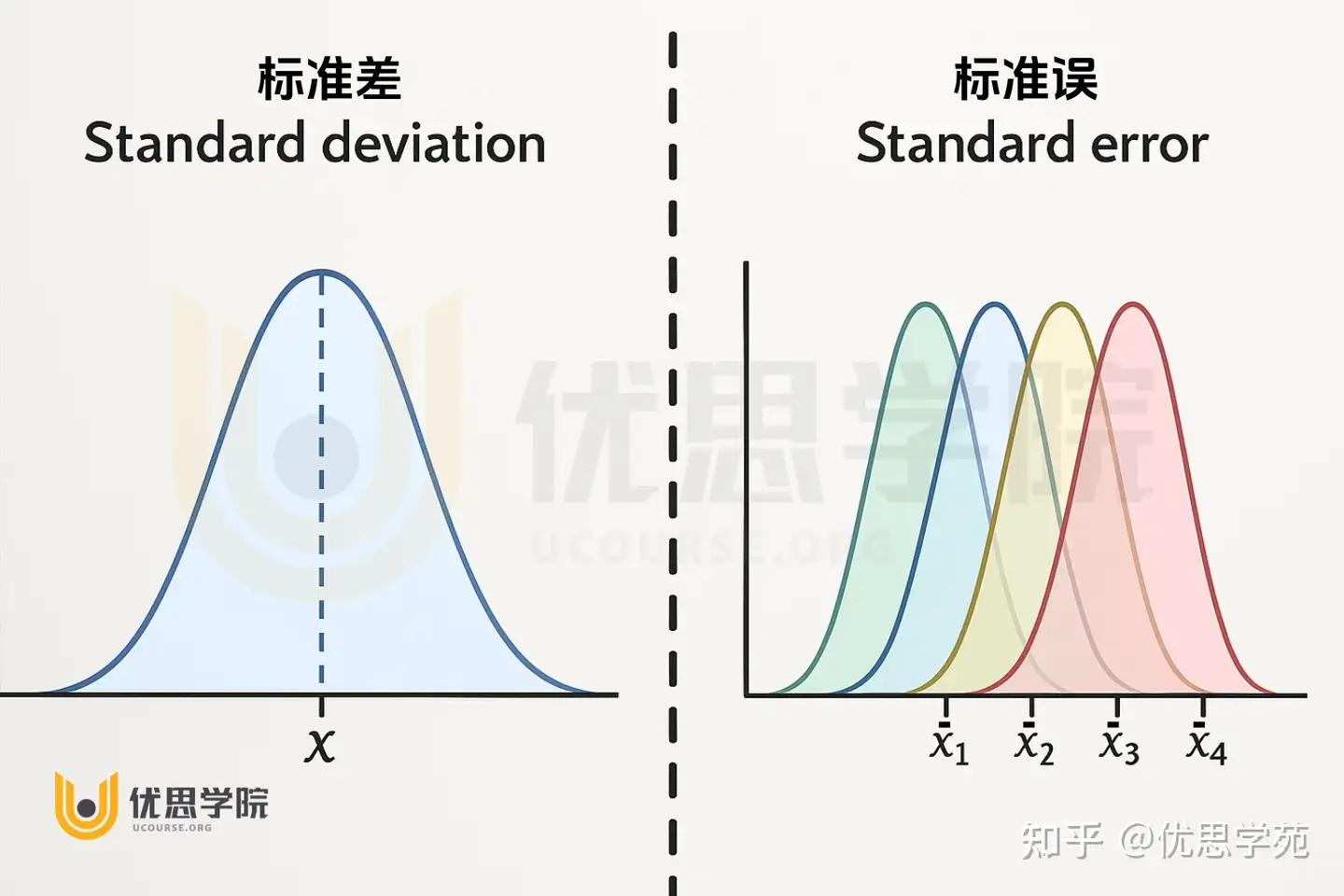
置信区间反映的是“样本均值”这个统计量的不确定性,因此使用的是标准误(standard error),而不是直接用样本标准差(standard deviation)。标准误体现的是均值的波动程度,而样本标准差体现的是个体数据的波动程度,两者并非一回事,就如下图所显示的一样。
下面优思学院会一步一步解释清楚:
很多同学对“标准差”和“标准误”这两个概念傻傻分不清楚,但其实差别明显:
简单来说:
两者衡量对象本质不同,因此不能混用。
我们回到置信区间的本质来看:
是推测总体参数的范围,比如推测总体均值。这里用到的是“样本均值”这个统计量,而非单个样本数据本身。
由于样本均值每次抽样都会变化,每次抽样得到的均值都会和真实的总体均值存在一定偏差。这种偏差的波动程度,就是用“标准误”来描述的。
举个生动点的例子:
因此,置信区间本质上是以样本均值为中心,向外延伸一定范围,来推测总体均值在哪个区间内。
这个向外延伸的范围就必须用标准误来决定,而不是直接用标准差。
很多同学在做题时发现,给定的是一个样本,样本也是正态分布啊,为啥不用样本自己的标准差呢?
原因是:
即便你只抽了一个样本,这个样本虽然也近似正态分布,但它的标准差描述的是数据之间的差异,而不是“样本均值”与“总体均值”之间的差异。
再形象一点:
做题时题目一般给你一个样本,常常还会给出总体标准差σ,或者让你用样本标准差s来估计σ(如果σ未知的话)。
题目里出现的:
无论哪种情况,都必须是 σ/√n 或 s/√n,而不是 σ或s本身。
这和你只拿到一个样本,并不冲突。因为哪怕你只抽了一个样本,你做推断的基础仍然是“样本均值”这个统计量的波动程度,本质不会改变。
标准误体现的是样本均值这个统计量的波动,而标准差体现的是个体数据的波动,两者衡量的是完全不同的东西。
置信区间关注的核心是推断总体参数(例如均值)落在哪个区间,因此用到标准误,而非样本本身的标准差。
理解了这一点,统计推断中关于标准差和标准误的问题也就迎刃而解啦!

作者: 优思学院, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-4102203.html
版权声明:本文为博主原创,未经本人允许,禁止转载!



 /1
/1 







文章评论(0条评论)
登录后参与讨论