
PCI总线是计算机的I/O总线,在90年代时替代了ISA总线,成为计算机中的局部总线一直使用至今。PCI总线在发展的过程中,不断自我革新,满足时代的需求。在短短10多年间,PCI总线历经了PCI、PCI-X以及PCI-E的演变历程。传统PCI总线具有32位数据宽度,33MHz的时钟频率,能够支持设备的即插即用、自动识别与配置。与ISA总线相比,不仅在性能上提升了一大截,而且在资源管理上也有质的变化。更为重要的是,ISA总线本质上是处理器总线的延伸,而PCI总线是与处理器总线无关的总线标准,不受制于处理器的类别,数据的传输需要通过桥设备进行转发。因此,ISA总线通常称为第一代I/O总线,而PCI是第二代I/O总线标准,这是一种技术发展的跨越。随着时代的发展,传统PCI总线的性能得到了挑战,越来越不能满足外设的需求。最为典型的是图像传输受到了PCI性能瓶颈的影响,因此,几年前的显卡设备都脱离PCI总线,单立门户形成了一个新的总线标准AGP,这显然是对PCI总线性能的一种否定。技术在不断发展,对高速传输需求的IO设备越来越多,Gbps网络、光纤通道都对传统PCI的性能提出了质疑,传统PCI总线已经不能满足此类应用的需求了。所以,在1999年提出了PCI-X协议规范,该总线具有64位总线宽度,最高能够达到133MHz的时钟频率,在性能上较PCI总线有了一个大的跨越。但是,PCI-X总线仍然是一种并行总线,其存在并行传输过程中的数据相位问题,因此,当PCI-X频率达到一定程度之后,总线带载能力就变的相当差。在133MHz总线频率时,PCI-X总线只能带一个PCI设备。PCI总线的发展遇到了并行总线的技术瓶颈,因此,PCI总线需要做总线结构的根本性变革。历史的车轮进入21世纪之后提出了PCI-Express总线,其将并行总线演变成了点对点的串行总线,在性能可扩展性方面跨入了一个新的台阶。所以,PCI-Express总线也可以称之为计算机的第三代I/O总线。
<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
PCI-X总线经常应用于服务器设备上,其不仅仅对传统PCI总线的数据宽度和总线频率进行了升级,更为重要的是对传统PCI总线协议进行了改进,提高了总线效率。下面对PCI-X总线的主要改进点进行探讨。
PCI-X总线最高能够达到133MHz的时钟频率,其得益于PCI-X总线采用了寄存器-寄存器的信号传输方式,而传统PCI总线对信号的接收与译码放在了一个时钟周期内,这种方法也称为即时协议。即时协议的优点在于一定程度上减少时钟脉冲个数;缺点在于难于提高时钟频率(译码电路会存在时间延迟)。PCI-X总线首先对信号进行锁存,在下一个时钟在对信号进行译码,这样的处理可以提高时钟频率。这种处理的方法本质上就是组合逻辑电路拆分的思想。这种拆分在一定程度上需要更多的时钟周期,由于在正常总线数据传输过程中不存在电路拆分,只有在总线事务起始阶段才有这样的需求,因此,PCI-X的这种改进不仅可以大大提高时钟频率,而且大大缩短了总线事务的处理时间,所以,PCI-X总线的时钟频率最高可以达到133MHz。
对于传统PCI总线操作,如果目标设备不能立即完成请求,那么目标设备会向请求设备发送retry信号,推迟总线事务,请求设备会在一定时候再次访问目标设备完成请求。这样的处理浪费了总线效率。仔细体会一下,推迟总线事务模型本质上是一种查询式的处理模型,这种模型在请求设备能力高于目标设备时,性能变的很差,其会影响到总线上其他设备的事务。针对该问题PCI-X总线对其进行了改进,提出了总线事务分割的概念。也就是当目标设备不能立即完成请求时,发送分割响应给请求设备。请求设备会释放总线,当目标设备完成请求后,会主动启动一次PCI的总线事务,将请求设备所需数据主动传输给请求设备,从而完成请求事务。总线事务分割模型本质上是一种中断式的处理模型,减少了总线事务占用总线的带宽,提高了总线效率。
PCI-X另一个非常重大的创举是引入了MSI机制。传统PCI总线采用的是共享中断模型,当PCI中断发生之后,中断服务程序会扫描总线上的所有设备,查看具体是哪个设备发生了中断,从而调用具体的中断服务程序(在Linux中通过链表维护了共享中断的所有服务程序)。这种中断模型大大浪费了服务程序的时间,特别当PCI设备达到一定程度之后,将会导致中断服务时间过程,发生中断丢失等问题。这种中断处理机制是一种“被动查询”的模型,而MSI则是一种“主动通知”的模型。当PCI设备发生中断事务之后,设备会主动的将中断向量号发送到指定的存储空间,然后触发CPU中断。处理器会根据指定存储空间的中断向量号调用具体的中断服务程序,不存在任何查询过程。为了实现MSI机制,PCI-X需要扩展PCI的配置空间,并且在设备枚举过程中需要为每个PCI设备分配MSI的中断向量号存储地址以及向量号。
综上所述,PCI-X总线在PCI的物理层和逻辑层都做了较大程度的改进,增加了总线宽度,提升了时钟频率,优化了总线效率。由此我们也可以看出,一个发展很完善的标准都会存在某些应用上的缺陷,需要不断的优化和改进,更何况一个普通的系统?系统设计永远是一个由简入繁的过程,一步到位的设计可望而不可及。
PCI-E对原有系统进行了结构层面的革新,下图是采用PCI-E总线架构的计算机体系结构。
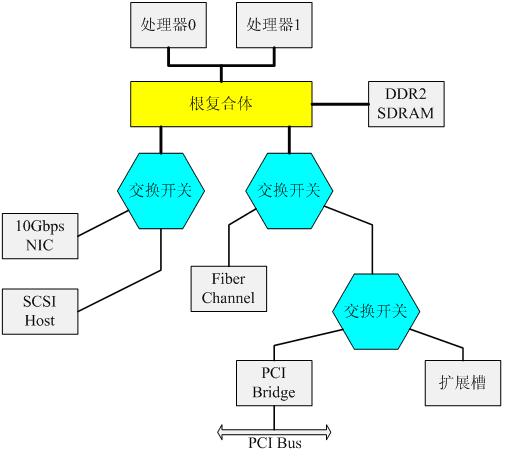
从图中可以看出,根复合体是PCI-E总线的root,其通过FSB总线与处理器进行互联,并且集成内存控制器,可以看成是传统系统的北桥(MCH)。交换开关与根复合体进行连接(在实现过程中交换开关可以集成到南桥,北桥与南桥通过DMI总线进行连接),交换开关可以扩展多个PCI-E端口,其可以抽象成多个传统的PCI桥,逻辑框图如下所示:

PCI-E交换开关进行事务包的路由转发,其内部可以抽象成一条虚拟的PCI Bus,在一条PCI Bus上连接多个PCI Bridge,每个PCI Bridge对应一个PCI-E端口。因此,在PCI扫描软件枚举设备时,同样会枚举交换开关内部的PCI Bus,为其分配总线号。
PCI-E总线是一种分层架构的协议规范,其主要分成如下三层:
1、 PCI-E事务层,处理PCI事务方面的工作,例如请求构造、路由等。PCI-E事务层定义了规范的协议头,在协议头中标识了请求的类型(IO读写、存储器读写或者配置读写)、请求地址、事务属性、请求ID等内容。PCI-E封装的报文称之为TLP,交换开关会根据报文头中的地址或者ID进行路由。在配置过程中,需要采用ID(总线号、设备号以及功能号等信息)进行路由,在正常数据通信过程中采用地址信息进行路由。在系统初始化过程中,每个交换开关的配置空间中都会初始化一份它所管理的地址空间范围,地址路由就是根据type1配置空间的地址信息进行的。PCI-E事务报文TLP生成之后会递交给链路层进行发送。
2、 PCI-E链路层,处理PCI链路方面的管理工作,例如链路传送应答和部分流控。链路层采用数据重传和应答机制处理收发报文,在发送TLP时,首先采用链路头对数据报文进行再次封装,然后将链路数据交给物理层进行发送。发送之后启动超时处理机制,在规定的时间内没有收到对方链路层的ACK应答包,那么认为此次链路传输失效,需要进行数据重传。如果接收到有效应答,那么发送链路层会清除发送缓存中的数据报文;反之,发送链路会重传数据报文。
3、 PCI-E物理层。该层处理数据编解码、链路训练、时钟管理以及串行、解串等方面的工作。PCI-E物理层采用2.5Gbps(5Gbps,10Gbps)、低压差分(800~1200mV)的数据传输方式,为了平衡各频点的能量,在物理层数据发送时采用伪随机码进行数据位乱序;为了达到DC平衡以及时钟信号恢复,将数据位乱序之后的报文进行8b/10b编码;为了解决符号内干扰问题,需要采用预加重(减重)技术处理发送的数据位,进行时域补偿;为了简化设计,接收设备与发送设备之间采用AC耦合的方式。一个PCI-E端口可能含有多个PCI-Lane(PCI通道),一般通道数为X1、X2、X4、X8、X12、X16、X32,对于多通道的PCI-E端口需要进行发送数据字节的剥离,这种思想类似于存储领域的RAID0技术,即一个报文可以通过多个通道同时传输,提高了通信带宽。在多通道(lane)聚合传输的过程中需要注意通道间的时序差异,这种差异需要在链路训练的过程中进行补偿。在系统复位之后,首先需要进行通信链路训练,训练之后收发双发的时钟可以同步,并且发送方会经常发送PLP空闲报文,保证双方始终信号同步。链路训练以及电源管理都是PCI-E物理层的重要组成部分。
(这两天阅读了PCI Express原理及体系结构一书,有些感想,做了一些读书笔记。全文未完待续。。。)



 /3
/3 







tengjingshu_112148725 2009-4-7 09:17