
FIR滤波器根据输入数据速率的不同可分为串行结构、半并行结构和全并行结构。串行结构的FIR滤波器是将并行数据串行输入,所需的DSP资源较少,但是数据吞吐率较低;而全并行结构的FIR滤波器数据是并行输入,滤波系数的个数就决定了所需DSP资源的个数,资源耗用较多,但是吞吐率可以做到很大。在大多数应用中,如无线数字中频处理,所需数据吞吐率一般都较高,因此采用的是全并行结构的FIR滤波器。
全并行FIR滤波器根据实现结构不同可分为:直接型(Transverse)、转置型(Transpose)和脉动型(Systolic),这一节主要讲解直接型FIR滤波器设计。
(一)直接型
直接型FIR滤波器在上一节中也有介绍,如图1所示,数据x(n)移入并寄存,如果有11个抽头,因此直接型FIR滤波器需要11个乘加模块。
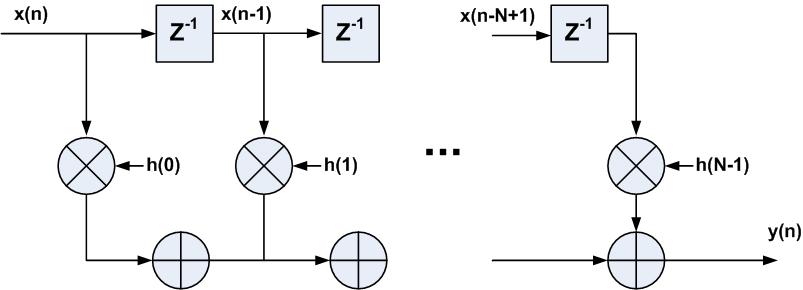
图1
FPGA实现时,直接采用上图中结构,不对中间数据寄存,则关键路径是x(n)h(0)+x(n-1)h(1)…x(n-N+1)h(N-1),以阶数10的FIR滤波器为例,如下为抽头系数:
coe_0 = -1241
coe_1 = -650
coe_2 = 1300
coe_3 = 4739
coe_4 = 8126
coe_5 = 9544
coe_6 = 8126
coe_7 = 4739
coe_8 = 1300
coe_9 = -650
coe_10 = -1241
数据输入时打了一拍,输出时打了一拍。综合后结果如下:
Number of Slice Registers: 2
Number of Slice LUTs: 19
Number of DSP48E1s: 11
关键路径中数据路径延时报告如图2所示,数据路径延时包括乘法器延时Tdspcko PCOUT AREG MULT (3.001ns)+ 10个级联加法器延时Tdspdo PCIN PCOUT(1.219),数据路径延时总共15.017ns,因此fmax最大不过66.273MHz。可以发现综合器自动将乘法器和加法器在DSP48E1中实现。

图2
加法树实现:
直接型FIR滤波器的一般实现方法关键路径中有较多级的加法器,所有加法器延时累加后导致关键路径延时较大,对整个FIR滤波器的性能造成了很大影响。为了解决加法器延时累加的问题,可采用加法树结构,如图3所示为采用了加法数的直接型FIR滤波器结构,这种层次化的树型结构,使加法器逻辑由级联结构转化成并行结构,这样整个路径的延时减小。
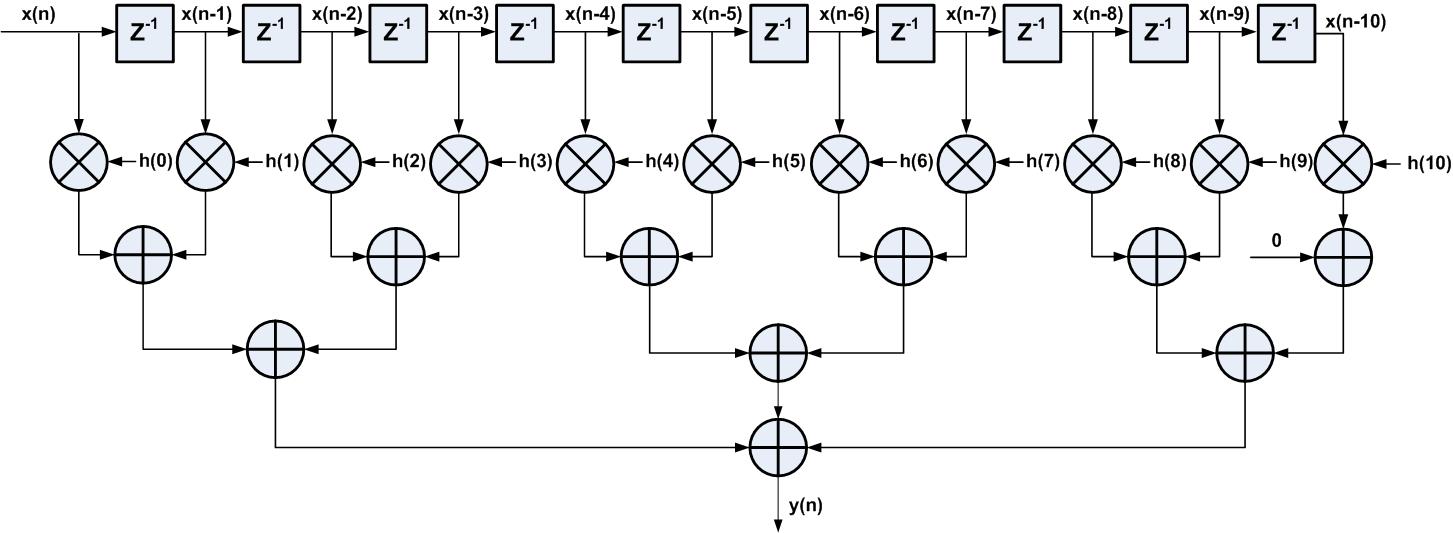
图3
流水线实现:
虽然直接型FIR滤波器采用加法树结构后优化了关键路径,但是时序还是不够理想,因为关键路径上至少有一个乘法器和一个加法器的延时,如果想竟可能的优化时序,可以分隔乘法器和加法器逻辑,中间加一级寄存器,即采用流水线实现。
那如何有效地分割逻辑呢?可以在图3中加法树结构的基础上分割,在原先的关键路径上,乘法器延时3.001ns,加法器延时1.219ns,因此可以将逻辑分割成如下三级:
第1级:乘法器
第2级:2级加法器
第3级:3个数累加即2级加法器
如图4所示为流水线实现的FIR滤波器,逻辑分割后的关键路径是乘法器那一级,理论分析得到的延时只有3.001ns,如果时钟约束到250MHz可满足时序要求。
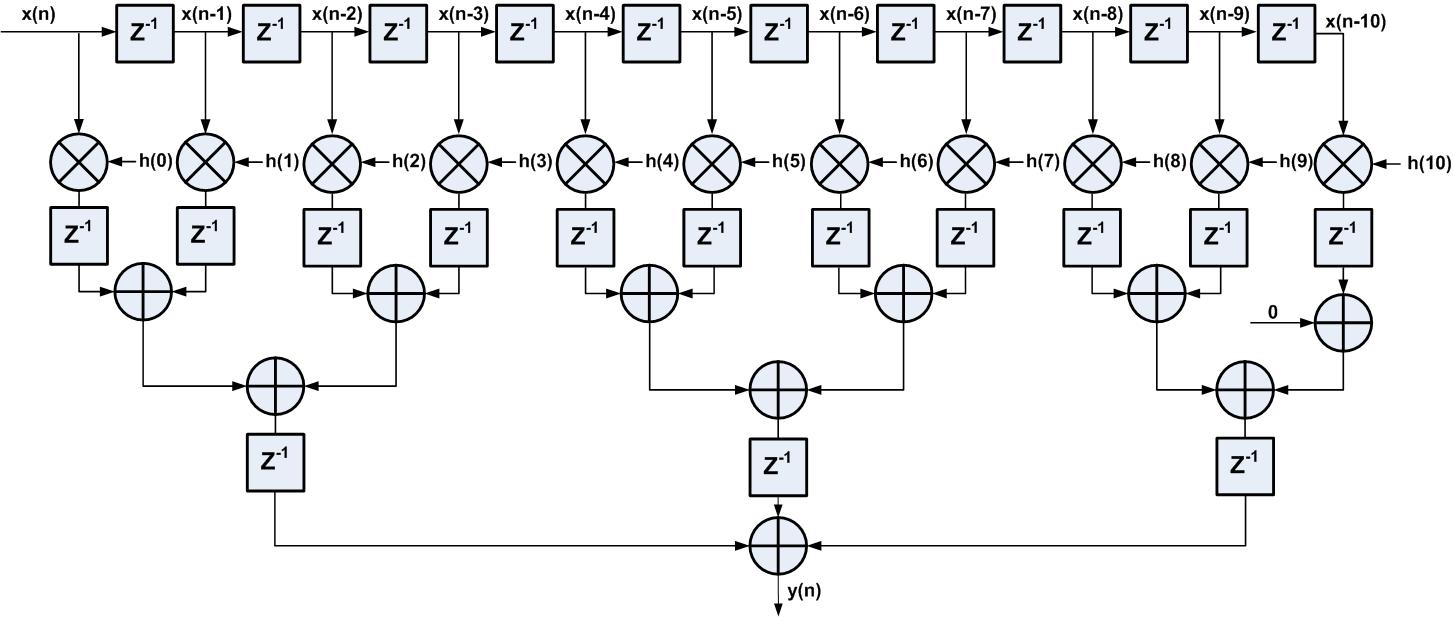
图4
实际得到综合结果如下:
Number of Slice Registers: 105
Number of Slice LUTs: 124
Number of DSP48E1s: 11
Minimum period: 3.037ns{1} (Maximum frequency: 329.272MHz)
fmax能达到329.272MHz,延时基本与预期的差不多,FIR滤波器能达到这样的性能基本能满足大多数应用了。
线性相位FIR滤波器:
FIR滤波器有一特征:线性相位,直接表现在抽头系数上,抽头系数为偶对称或者奇对称,在这节实例中,系数是偶对称的,即h(0)=h(10),h(1)=h(9),h(2)=h(8),h(3)=h(7),h(4)=h(6),直接型FIR结构优化后如图5所示,输入数据在与系数相乘之前,因系数对称,可以先将相同系数对应的数据进行预加操作,然后再与系数相乘,如此做法的好处是是乘法器资源减少了近一半,此例中DSP资源由原先需要11个到现在只需6个。而且,在Xilinx FPGA中的DSP48E1资源专门为线性相位FIR滤波器应用提供了预加pre-adder结构,即预加和乘法都可以在1个DSP48E1中完成,这样大大缩短了数据路径的延时,有利于时序收敛。
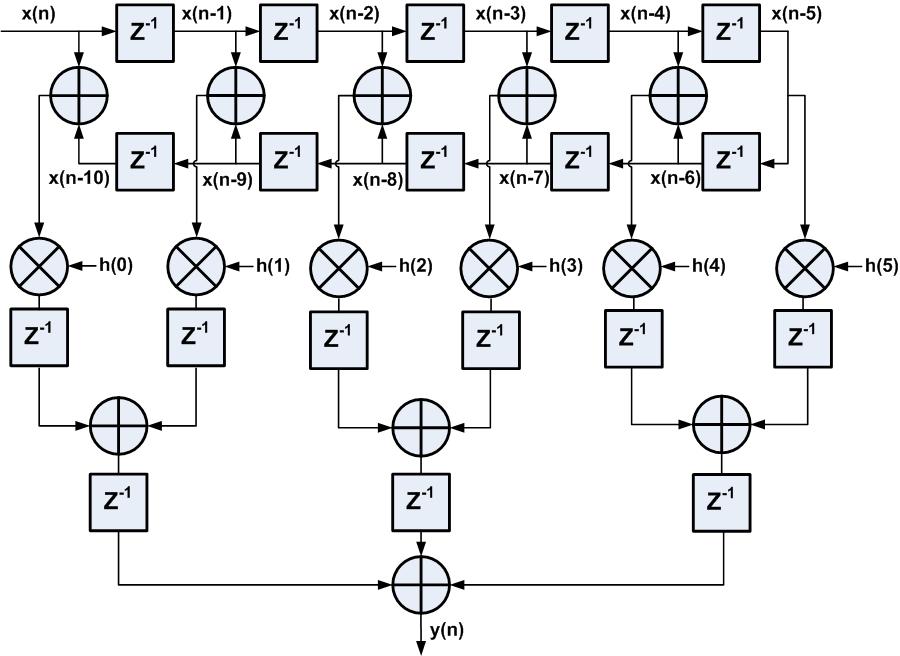
图5
实际得到综合结果如下:
Number of Slice Registers: 184
Number of Slice LUTs: 173
Number of DSP48E1s: 6
Minimum period: 2.854ns{1} (Maximum frequency: 350.385MHz)
fmax能达到350.385MHz,由于采用了加法树结构,避免了加法器级联延时,并且分了3级流水线实现。关键路径数据延时报告如图6所示,路径是从DSP48E1输出端到dout_d,但是光从代码中看DSP48E1端到dout_d中间应该还有一级加法器的寄存,原来这个加法器采用了DSP48E1中的累加器实现了。
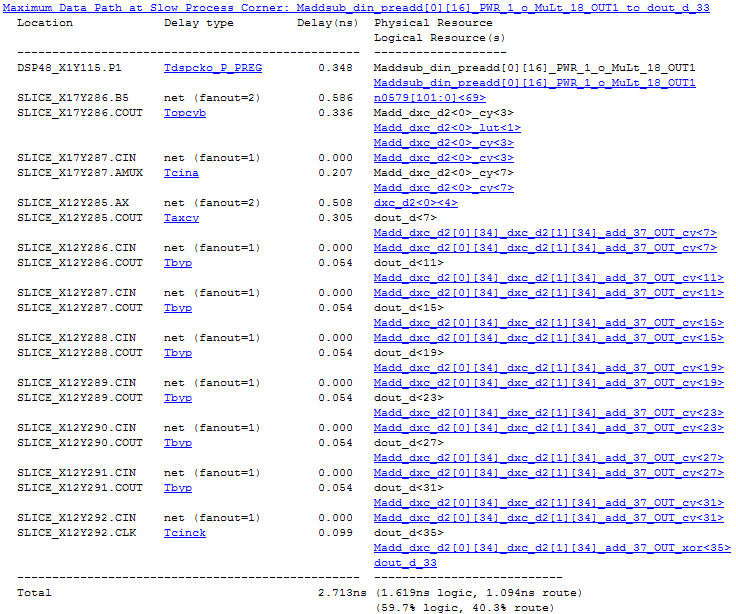
图6
相关代码:
直接型: fir_transverse.v
流水线: fir_transverse_pip.v
线性: fir_transverse_lin.v
用户407763 2015-1-30 13:49
用户327751 2013-8-14 17:16
用户428810 2013-3-22 21:46
用户201521 2013-3-7 23:44
Hoki 2012-6-15 12:49
您好,关于滤波器系数,通过FDATool生成后是小数形式的,但是在FPGA中处理必须用整数形式,因此需要进行位扩展,如扩展成16-bit,则需要将系数乘以2的15次方,并且经过四舍五入之后得到整数形式的滤波器系数;程序中的dout_c表示舍入位,在得到dout时,因为需要从36-bit取其有效的高16-bit,程序中并没有直接进行截位,而是经过了舍入处理,舍入的算法在《DSP in FPGA:数字表示》中有说明:“定义舍入之前全精度数为M位,舍入后的数为N位,其中N<M,当全精度数为无符号数或者数为正的有符号数时,如果舍入相邻位(多余位数中的最高位) 中最高位为1,则舍入时必须进1,反之不进位;当全精度数为负的有符号数时,舍入相邻位为1且舍入相邻位后面还有一位为1,则舍入时需进1,反之不进位。”
用户1670344 2012-6-15 11:51
用户320098 2012-5-18 17:29