
在现代系统中,内存限制往往对性能造成重大影响。采用 AI 技术的汽车应用对于可靠性提出了极高要求,内存限制无疑是其面临的一大挑战。一方面,系统必须快速检测并报告潜在的碰撞或其他可靠性问题。所有纠正措施均受到物理条件的限制,必须提前采取适当措施,避免出现问题。
AI 与内存
另一方面,系统采用 AI 技术帮助确定发生碰撞的几率。AI 技术的内存占用率极高,严重消耗高分辨率彩色视频影像并基于这些影像运行神经网络算法。然而,AI 可以形成组织结构(例如特征图为常量或输出图为常量),相关计算过程需要将大量数据保留在内存中。转入 DRAM 的速度将非常缓慢并且极为耗电。AI 在很大程度上依赖高效缓存,从而最大程度地减少片外需求。
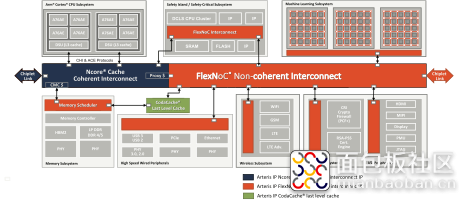
鉴于现代加速器的复杂性,我们可以仿照处理器,在加速器的多个层级插入缓存。最后一级位于片外内存控制器和 SoC 其余部分之间,称为“末级缓存”。该缓存面临的特殊挑战是,除了供 AI 加速器使用之外,它也是CPU 集群、GPU 以及 SoC 中其他任何功能共享的末级缓存。何谓“高效缓存”可能取决于具体应用,因此末级缓存必须非常灵活,甚至需要在运行过程中支持灵活配置。
CodaCache IP
为了满足这一需求,Arteris IP 的 CodaCache IP 应运而生。首先,每个实例均可存储高达 8 MB 的数据。Tag 和数据以 Bank 的形式组织到一起,支持 AI 运算常用的并行访问模式。内存最多可以划分为 16 个 Way,允许每个独立的应用程序使用各自的缓存子集工作,不会被其他应用程序强制逐出。重要的是,这只对逐出产生影响。为了保持内存模型的完整性,所有应用程序均可在缓存地址中读取或写入。
对于 AI 应用,这种 Partitioning 和 eviction 至关重要(在权重为常量的架构中处理权重正是典型例证)。这种模式可保证这些权重在被 evict 之前尽可能长时间驻留在缓存中。
用户有时需要额外使用非结构化 ScratchPad 存储器,在运行时或启动时通过配置CodaCache来实现,譬如用来存储递归神经网络的反馈状态数据等内容。
AXI 连接性和可靠性
尽管 CodaCache 的功能已经是我们部分 NoC 产品的固有功能,但我们仍然根据一般性需求首先打造了这款产品,无论设计团队是否使用我们的 NoC。这款 IP 直接连接符合 AXI 协议要求的片上互连和内存控制器接口,并可通过 APB 端口进行配置。
对于汽车市场而言,最重要的是,这类高速缓存 IP 的设计符合 ISO 26262 标准,可作为 SEooC (Safety Element out of Context) 使用。内存使用 ECC 技术,AMBA 接口使用奇偶校验保护或其他保护方案,同时根据标准要求使用 FMEDA (Failure Mode Effects and Diagnostic Analysis) 对整个内存块进行了分析。它附带安全手册,可帮助集成人员开发并验证其产品的安全合规性。
安全合规性是对这款 IP 的最新补充,汽车行业公司对此的积极关注,恰恰印证了降低 ADAS 与自动驾驶系统的功耗和系统延迟乃是大势所趋。CodaCache 末级缓存正是满足上述要求的关键。
如需了解有关 CodaCache 的详细信息,敬请点击此处。
(https://www.arteris.com/zh-cn/download-technical-paper-codacache-helping-to-break-the-memory-wall)
作者: ArterisIP, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-3893295.html
版权声明:本文为博主原创,未经本人允许,禁止转载!



 /5
/5 






pidaneng 2020-9-11 08:45