苹果 PowerPC 时代,我在上高中。那时有件事我印象很深刻。当时我们班有个很懂计算机的人,拿着一本计算机杂志,跟我安利 iMac G4,说你看这个电脑多好看啊,多牛逼啊,比 Windows 电脑不知道好看了多少倍。而且他还跟我强调说,你知道吗?这台电脑的 PowerPC 处理器比你们奔腾处理器快 2 倍。
我当时还是个高中生,根本不知道什么是 PowerPC,我当时就只知道 Intel 的奔腾处理器(还听说过 AMD),听他说完就觉得苹果好牛逼;而且他那么懂电脑,他说快 2 倍,那就应该是 2 倍吧。iMac G4 用的处理器是 IBM 的 PowerPC G4(具体应该是 PowerPC 7445 之类)...
苹果芯片的精准制导
其实“快 2 倍”这个说法,好像也是当年乔布斯在发布会上吹出来的(也可能是当年某本苹果杂志的编辑写出来的)。最早苹果在宣传广告中提到,PowerPC G3 比当时的奔腾 II 要快 2 倍;后续说 G4 比奔腾 III 快很多;G5 比奔腾 4 快很多。差不多就是这样。(我高中时期,时代一脚刚刚跨入到奔腾 4 等灯等灯)
当年乔布斯曾经公开对比过 Mac 和 Windows PC,对比的方式是双方自动执行一组 Photoshop 任务。当时 Mac 以快得多的速度完成工作,碾压奔腾处理器的 Windows PC......当年奔腾正在搞超长流水线,处理器主频不知道飞跃到哪里去了。PowerPC 那会儿走的线路更偏宽核心,频率是低很多的。苹果那一时期还做过一个叫“The Megahertz Myth”的宣传,主要就是教育公众,别迷信时钟频率。
这事儿吧,其实有一定的道理。不过乔布斯的这次对比,PowerPC 的胜出,主要是因为 PowerPC G4 处理器配了个 AltiVec 加速单元,这是个 128bit 的矢量处理单元,可以单周期内执行 4 路单精度浮点数学运算(或者 16way 8bit/8way 16bit 之类),而且还是超标量设计,同时可以执行 2 个矢量操作。Photoshop 就能充分利用这个单元。AltiVec 效率比那会儿的 MMX 扩展指令要高。
就这个角度,也能一定程度解释,为什么现在的 iPad Pro 剪视频那么流畅,但桌面 PC 同等操作下却没那么快。这其实跟处理器设计的思路有很大关系。我觉得这么对比,并不存在什么公平不公平的问题。而且奔腾 4 当年在路子上的确出了比较大的问题。
只不过你不能就此得出一个结论说,PowerPC G4 就比奔腾 III/4 快多少。那现在,我们是不是也可以只对比一下充分利用 AVX512 的特定任务,来让 Intel 和 AMD 比比,后者会不会被 pia 出银河系吗?这是不合理的。
拿某些固定工作单元去比性能的意义,其实没那么大,尤其是对通用性很重要的 CPU 而言。这一例中,且不说究竟有多少程序代码能用上 AltiVec 单元(就像现在很多人质疑 AVX512,说用不到它);应该要比的还是日常消费用户比较频繁的操作,在效率上怎么样。苹果日常就非常善于呈现一些他想让你看到的数字,虽然没在说谎,但也未展示事物全貌。
我觉得,在 CPU 通用计算发展思路,该用的技术基本上都用过一遍以后(比如乱序执行、分支预测、超线程等近代技术),CPU 单线程性能推进本来就遇上了瓶颈。这时候是需要引入专用处理单元的,这也是一个常规思路——典型的像是在 GPU 领域,NVIDIA 为光线追踪引入了专用处理单元,这是提升性能和效率明显收益更高的方案。
苹果面向消费用户,或者目标群体时,一向都十分清楚自己需要针对硬件(或软件)做什么样的强化。所以事实上,苹果自己掌控处理器的设计,对目标群体的确是一件好事——就像它也掌控操作系统和软件一样。比如历史经验告诉我们,大量 Mac 用户用苹果电脑来剪片子,而 Final Cut Pro 在软件优化上的苹果平台加成,就是 Premiere 和 Davinci 都望尘莫及的,不管是视频编辑时的实时渲染、编码预览,还是输出速度。硬件层面为此若进一步做加成,还能再度提升效率。
iPad Pro 实现一些简单视频后期,效率明显比 x86 的 MacBook 更高,即是这一思路的集中体现。不过我也始终觉得,这种思路是有明确目标用户定位的。大部分人,并没有这些需求,如果我压根儿不用 Photoshop,那么像 AltiVec 这样的专用单元只能成为一种资源浪费。至于很多人,把这类思路解读为苹果在芯片设计上的黑科技,那也大可不必;毕竟 Intel 在服务人群的思路上和苹果是大相径庭的;就像高通也不可能面向 Android 阵营极为草率地,推出一颗性能与苹果 Ax SoC 相当的产品一样。
Arm 效率真的高过 x86 吗?
自从苹果宣布 Mac 要开始用 Apple Silicon,就一大堆媒体说了,看那个 iPad Pro 牛逼坏了——A12Z,一个功耗那么一点点的处理器,性能那么彪悍了,要是苹果给它提个主频、核心数,那岂不是立马把 Intel/AMD 之流轰出地球了吗?
有关这一点,早前的文章《
MacBook要采用Arm处理器,难度有多大?》我也用一个段落提到过,即 A12/A13 这些芯片的能效比,似乎还挺美好的。但实际上,如果苹果给这些芯片暴力提频,提到桌面处理器的程度,则其功耗和能效也会立马崩边——因为频率提升,越往后,给功耗带来的压力就会显著更大,而不是平缓变化的。当然我觉得这种描述略有些片面了。
我们还可以来看看 Cortex-X1 的设计——就是前不久 Arm 发布的一个微架构 IP。这个微架构被 Arm 设计出来的初衷,很大程度上就是面向高性能的。而且需要注意的是,它是以一定程度牺牲功耗和能效,来提升性能的——这跟 Cortex A78 的设计就很不一样。Cortex A78 是纯面向移动平台的那种传统核心,就是必须在 PPA 上做权衡,面积、性能、功耗都必须考虑在内,做到针对手机这类设备尽可能的最优解。

另外,其实我也挺想说,CPU 层面增加一些扩展指令集的能力,包括上面这张图列出了机器学习性能提升,也表明:现在很多人认定,x86 CPU 增加 AVX512 这样的支持没有必要,是在浪费芯片尺寸和功耗(Linus Torvalds 为代表),而应该完全让专用处理器(比如 NPU、GPU)去处理这些事——这类想法可能是十分片面的
但 Cortex-X1 的指导思路就不是这样。Arm 给的一些数据是这样的:相比 A77 在相同频率下,X1 的峰值性能提升 30%。具体应用中,X1 的提升理论上还会更大,因为频率肯定比 A77 要高。不过 Arm 基本没提功耗和面积的事情。AnandTech 预计,X1 的核心大约会比 A78 大出 50%,包括 L1 L2 cache 部分;功耗估计也要多出这么多。
AnandTech 认为,在实际实施方案里,这个数字可能会更大,X1 的功耗可能会达到 A77/A78 的两倍;能效(energy efficiency)会比 A78 差大概 23% 左右。不过讲真的,这根本没什么大不了。Arm 现在大部队都期望去攻占 PC 平板市场,X1 也符合这种设定。
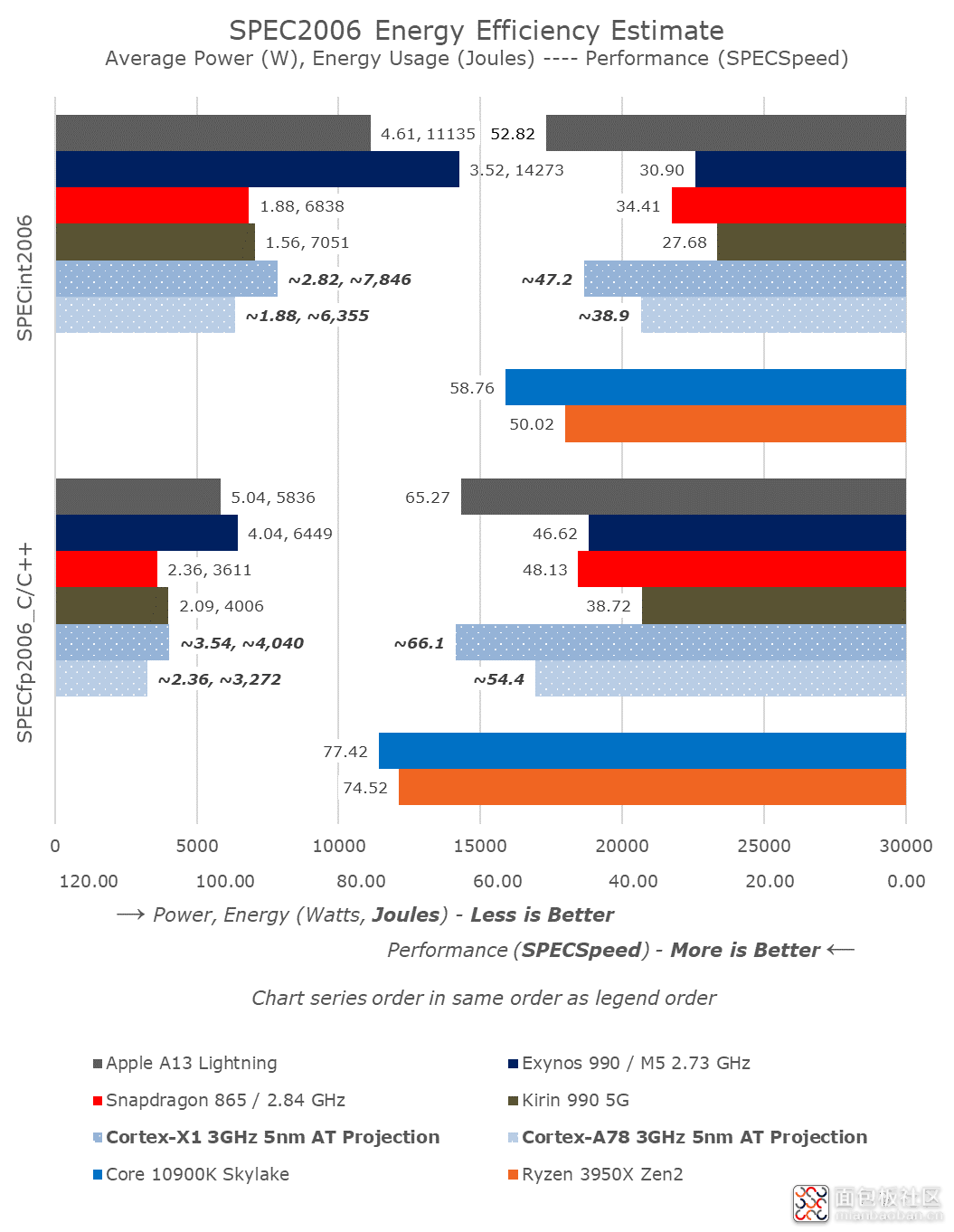
AnandTech(Andrei Frumusanu 博士)假想的一张图,可以表示 Cortex-X1 3GHz 5nm AT Projection(蓝色点状条)的能耗与绝对性能情况。这张图的左边柱状条表示的是 SPEC2006 测试全程消耗的能量(单位:焦耳),柱状条右边有两个数字,一个是平均功耗(单位:瓦特),另一个就是柱状条长度表示的能量(单位:焦耳)。右边柱状条则表示绝对性能,即跑分数字。
但这至少表明了 Arm 并没有什么黑科技,像很多人想象的那样,跟 Intel x86 比起来效率高到天上去——上面这些数据还是在台积电的 5nm 工艺不要出什么大纰漏的情况下;Arm 要做高性能,牺牲效率和功耗也是必须的,这事情真不像很多人想的那么简单,苹果做个高性能处理器就等比放大下 A 系列处理器就可以的。
之前我写 Mac 要用 Arm 处理器有多难的时候就提到过了,性能提升和功耗提升,这不是线性的关系。把 A12Z 提到 3GHz 频率,你看它功耗会崩到哪里去...
所以针对以上段落的总结是:苹果给 Mac 上自家芯片自然是好事——这里的“好”,体现在苹果收拢自家生态,Mac 迭代节奏也能完全掌握在自己手里;更重要的是,面向目标群体(比如做设计的、vlogger、搞摄影的等等)实现硬件层面更高效的支持,因为苹果可以更具针对性地去做硬件和芯片,Mac 设备的体验也因此可以更好。这也是苹果一直以来,对生态掌控力的固有经验——iPhone 即是这个思路下的产物。之所以等到现在,Mac 才使用 Apple Silicon,也是因为苹果现有的技术储备已经足够。
但这并不意味着,其芯片技术领先到了哪里去,更不表示 Arm 现如今在桌面市场比 x86 平台已经表现出了多大的技术优势。
番外:苹果需要做几颗处理器?
苹果用自家处理器,另一个我觉得挺现实的问题是,Mac 产品线有那么多不同的产品,比如 MacBook Air/Pro、iMac、Mac Pro 之类。如果要全线用自家芯片,那是不是要做一堆不同型号的处理器出来?
好吧,就算苹果能通过芯片体质的 binning 来自己划分个 A14-a,A14-b,A14-c 几个档位的 SoC 出来(比如针对较弱体质的就屏蔽掉两个核心之类的,或者用更低的频率,用在低端产品线上,那这样还节约了设计成本,桌面 CPU 本来也是这么搞的嘛)。问题是,Mac 一年的销量才多少(而且还要划分不同设备类型的不同芯片)?
之前的文章《
摩尔定律失效,FPGA迎来黄金时代?》曾经提到,用尖端工艺去设计和制造芯片,所需耗费的成本不菲——这个成本并不是哪个行业都耗得起的,就算是汽车产品,其出货量也走不起最尖端工艺的量(汽车销量爆款能达到百万就很不错了)。iPhone 之所以能用自己的芯片,而且性能炸裂,一个很大的原因是 iPhone 的年销量非常高。所以苹果能走得起最先进制程工艺,比如现在的 7nm 制程。iPad 本质上是沾了 iPhone 的光,设计成本和制造成本都可以有效控制。
Mac 年销量才多少?开一个 5nm 的产线要多少钱?如果走不起量,就不可能用得起最先进的制程。去年 Mac 全产品线的销量是 1800 万台左右;iPhone 预期是在 1.9 亿部上下。这个就有 10 倍出货量差距。
如果给 Mac 重新设计高性能处理器,这里面的设计成本负担其实也非常高,尤其是配合每年的最先进制程——每年还要迭代,苹果又不是专门做芯片的,没有客户摊薄成本(这一点和 Intel、高通这些厂商就显著不同);生产成本已经说了,走不走得起这个量,我觉得有兴趣的同学可以算一下(苹果肯定也算过这笔账了,或者苹果有某种高端的解决方案,衰 O_o)。
当然苹果也可以不去刻意设计高性能处理器,比如跟 iPad 用一样的处理器,或者也就改个款,或者可能有什么黑科技,规模化放大设计(有了解芯片设计的朋友跟我说,有这样的可行性)...那我觉得这样的话,至少就现在来看,苹果的 A 系列芯片起码在通用性上,日常操作在 Intel 面前真没什么特别的效率、性能优势(虽然 Intel 现如今正在渡过自己非常难堪的一段时间)。
另外,在 GPU 方面——看很多分析文章提到,未来苹果极有可能完全采用自家集成在 SoC 内部的 GPU,放弃 AMD 家的独立 GPU 设计——这一点从苹果现在的开发者文档能看出些端倪,AMD、NVIDIA 统统被苹果归到旧款 Mac 设备行列了,这也符合苹果一贯以来的尿性;毕竟苹果的 Metal API 也搞这么久了。如果是这样的话,Radeon GPU 还真是做了这么长时间的嫁衣——可见老黄不愿意支持苹果 Metal API 的决策是正确的...(逃
这篇文章谈的比较散了,真像 Intel 的软文——实际上,我的确不希望 Intel 在 PC 市场没落。
最后,庆贺下我最近获得面包板明星博主称号...我会努力学习的...下篇文章可以写写历史上的 PowerPC,从 PS3 那颗著名的 CELL 处理器(PowerPC 970)入手...









 /5
/5 







pidaneng 2020-9-4 01:44
开发工匠 2020-7-31 11:44