这篇文章主要是给大家推荐一个视频,提供一个思路——视频在本文末尾,不过看我的这篇文章也够了。这则视频的很多内容,其实是值得商榷的(尤其制作视频的这位 Coreteks 大嘴真的是什么都说得出来)。这个视频的信息量巨大,我觉得非常有意思,所以这里分享给各位。只不过看的时候,注意很多内容别当真。
这则视频的主题是:从 PlayStation 5 游戏机,看索尼和 AMD 改变游戏行业的杀招,以及英伟达的水深火热(我瞎说的)...
Coreteks 这个人我关注已经两周了,他大部分视频都体现了同一个思路,就是将来的处理器都要融合到一起,一切都要融合到一起,CPU、GPU、内存什么乱七八糟的全部都可能放到同一颗芯片上。(而且不是异构那么简单,而是彻底从架构上去颠覆,对这一点我就已经很不同意了,不过这是背景)
不过他在近一年的视频里,都讲对了数字芯片的一个共识。那就是处理器现在性能提不上去了,所以需要依赖各种专用硬件单元(或专用核心、专用处理器)来提升性能和效率——靠 CPU 或者 GPU 的通用单元是不行的,因为通用单元发展到现在已经极限了。所以我们要做专用单元,一个专用单元就只能做一件事情(或某几件事),虽然可能有浪费,但执行这一件事的时候效率奇高啊。
这一点是本身现在就在发生的过程,不管是哪个层面的专用。而且历史上一直就存在的,比如 CPU 的扩展指令集——或 GPU 早年就是一种极为专用的 ASIC 图形处理器——只不过这些年的这个趋势越来越激进。比如 Intel 对于 CPU 在机器学习算力上的执著(其实 Arm 也在搞)...比如英伟达在光线追踪方面 RT 专用核心的执著...比如谷歌为 Pixel 手机开发的专用影像处理核心...比如谷歌用脉动阵列做的 TPU...
对于这种“专用”的理念转变,可能是多层级多方位的...在提升性能以外,它势必造成一定程度的浪费,比如你买 Pixel 手机可能根本就不拍照,那这个专用影像处理器对你而言就多花了钱;比如你买来 Intel 处理器的 PC,就只用来上上网,那显然像 AVX512 这种指令对你来说没有半毛钱用处。这是一定的...但你不能说这种趋势不对。
Coreteks 的这则视频是从 PS5 的整体架构着手的...网上对 PS5 的骂声一大片,主要是觉得其用力的点完全不对,包括对于变频这种设计在游戏主机上的应用感到匪夷所思;包括 SSD 可能带来昂贵的售价,以及算力参数上不及 Xbox...我觉得,这可能表现出,索尼在实现目标过程中,具体实施方案可能做得没有那么理想(或者无法那么理想)...
如果撇开 CPU 不谈(两台游戏机都是 Zen 2,频率略有差别)。GPU 部分,(似)已公开数据显示,PS5 是 36CU(2.25GHz,可变频),标称 10.28 TeraFLOPs 算力;而 Xbox 这边是 52CU(1.825GHz),12 TeraFLOPs。同 GDDR6,Xbox 在其中 10GB 有带宽上的一定优势。Coreteks 认为,这些在最终游戏上,基本不会带来什么大差距。(其实我也这么觉得)
先说个结论,Coreteks 认为,PS5(以及 AMD)将带来的游戏革命,是其他任何平台,包括 PC 都给不了的。下面解释:
1.
Coreteks 认为,Xbox 和 PS5 的主要差别在 I/O 层面(指数据与通信):Xbox 的数据压缩速率在 4.8GB/s,PS5 则为 8-9GB/s——"In my opinion, Sony has won the console war right here."
SSD 与存储子系统的低延迟、高带宽,是 PS5 的主要特性(这原本也算是 RDNA 着眼的,以及 RDNA2 要加强的,虽然我觉得怎么看都是一个普通理念啊喂)...
2.
事实上,英伟达 Turing 架构的主要优势之一,也是低延迟、高带宽。英伟达的 RTX 显卡有两种加速器用于加速光追——这是现在大部分人都知道的了,RT core 和 tensor core;另外针对高带宽,还有两个比较重要的专用单元,一个用于压缩内存中的数据,一个用于解压——以此,数据可以更快地访问到。这一次 PS5 也是类似的增带宽思路...
当代处理器的很大一部分瓶颈就是带宽或者通信,而非单纯的计算部分;计算单元数量并不能反映实际性能。英伟达去年在莱斯大学的一次演讲中提到:
Accelerator Design is Guided by Cost.
Arithmetic is Free (particularly low-precision)
Memory is expensive.
Communication is prohibitively expensive.
这里的"cost"指的主要是芯片功耗上的开销,"free"和"expensive"也是这个意思。即算术是极低开销,存储代价很大,通信代价非常大...
我自己觉得,这的确是现在不少专用处理器(如 GPU、AI 处理器)的一个现状。所以 Graphcore 造的 IPU(一种 AI 处理器),就是在疯狂堆片上 SRAM,大量提升本地存储容量(IPU 二代是 900MB 的片上 SRAM),以及百倍提升带宽。
至于真正到执行单元,低精度的数学运算,真的都不是个事儿:算术的功耗,跟通信的功耗,那就不是一个数量级。(如上图,这个数据可能是有问题的,但各操作间的比例应该是这么回事吧,用以表现从 DRAM 读取 32bit 数据耗费远高于运算的能量)
英伟达首席科学家 William Dally 在 2019 年曾经说过,"Accessing even a small memory array costs way more than doing an operation. And a lot of what we think of memory cost today is really communication cost."
3.
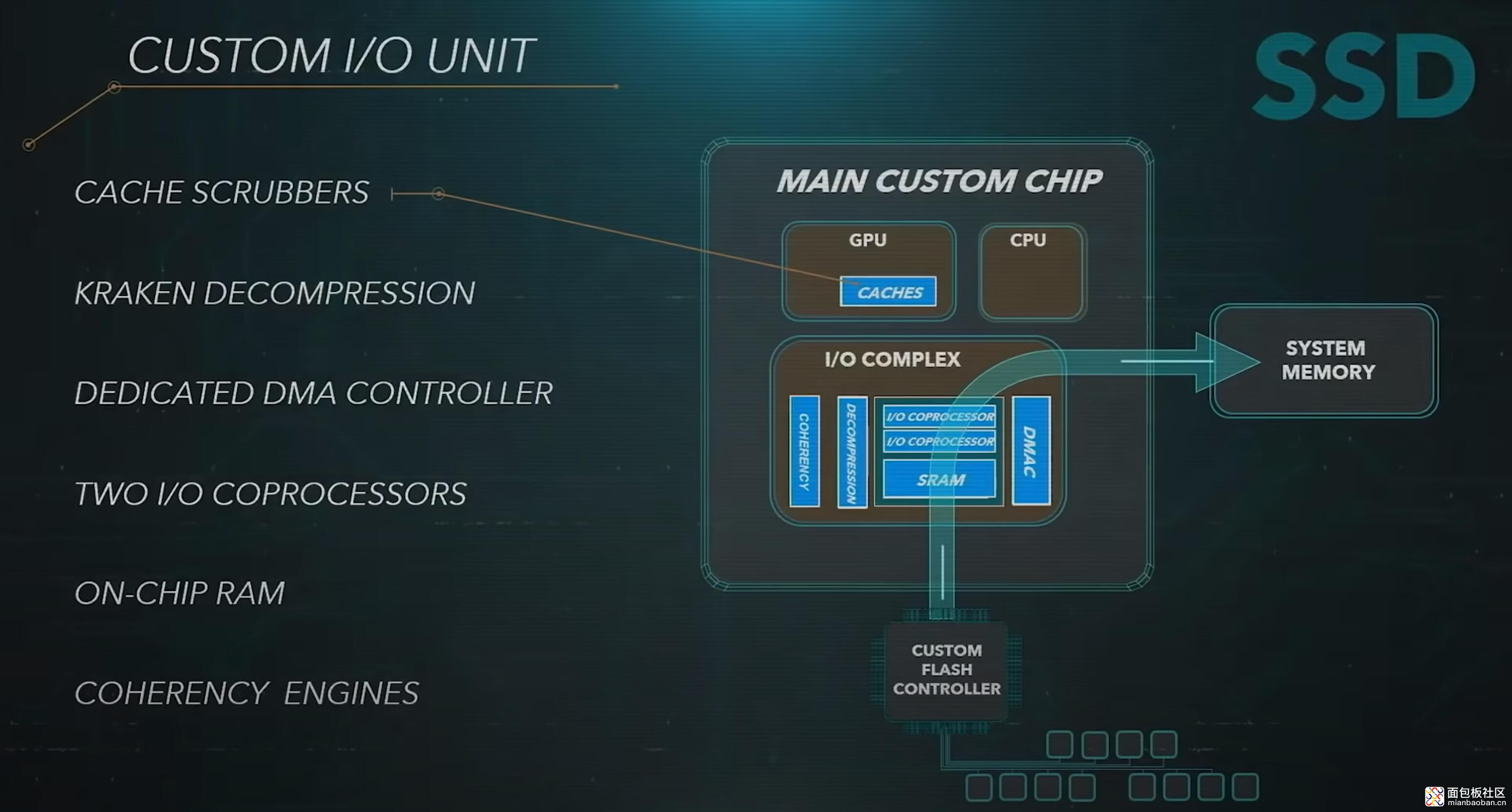
索尼 PS5 践行的就是上述思路,即一方面用专用计算单元,另一方面大幅提升数据传输带宽(虽然如很多知乎大佬所说,在具体实现上可能是很不理想的),包括高速 SSD(下图)。Coreteks 特别提到,PC 平台难以大规模推行这类方案,因为 PC 毕竟是个开放的平台(PC 平台的游戏需要迁就大众,不能像 PS5 那样搞高带宽需求)。
PS5 本身用了一些专用处理器,专门针对主机,以及游戏负载,某些技术未来也是不会进入 PC 领域的。比如说这次很多人在谈的 DMA 控制器,12 个通道——也是知乎上很多人认为索尼错误决策的一部分,因为这部分可能极大增加成本(上图)。显然 Coreteks 认为,这是加速“通信”与带宽的重要组成部分。
(注:Coreteks 似乎是当年 PS3 的 CELL 处理器的支持者,所以上述表达也不难理解吧。我近期有打算写一篇当年 CELL 处理器的文章...)
PS5 专用压缩单元 Kraken,也包含在 SoC 里面,也是专用单元且提升内存带宽的一部分(Xbox 实际上也有,而且 RDNA2 和 Turing 什么的其实都有)。
4.
下图给出了 PS5 完整的 I/O 思路,而且随着时代的推进,越来越多的专用单元会加入进来。(就像苹果的 A 系列 SoC 那样,加入越来越多的专用处理器,分别解决专门的问题——Coreteks 的表达是,A13 Bionic 有超过 40 个专用加速器;在客观数字上我没去了解过,不过其实这一点原本就是趋势)
这张图左下角出现了一个 Coherency Engines(一致性引擎),也算是 PS5 游戏机的 I/O 群体中的另一个重要的专用处理器(或者加速器)了,专门负责跨 CPU 与 GPU 的存储一致性(memory coherency)——这也是 AMD 下一代 APU 的一个重要特性。
Jim Keller 曾经说过这样一段话:
"What Graphics need is a really high bandwidth memory system. In the past graphics had its own memory system, and for the CPU and GPU to talk to each other you'd use PCIexpress."
"With HSA, we made a memory architecture where CPU and GPU share the memory. So graphics sees memory, CPU sees memory and we can pass pointers between them, we have a common address space."
简单翻译,就是图形计算,需要高带宽的存储系统,以前图形计算有专门的内存系统,CPU 与 GPU 对话用 PCIexpress...而“我们搞了个存储架构,让 CPU 和 GPU 共享存储,两者都能看到内存,我们就能在两者间传递 pointer 了,我们有共同的地址空间。”这是 2014 年 Jim Keller 还在 AMD 构建 Zen 的时候说的。其中提到的 HSA,也就是 heterogeneous system architecture,异构系统架构...HSA 应该是一套规格,让不同的处理器部分做融合的...
HSA 规格的首个践行者就是 PS3 的那个“传奇”CELL 处理器,苏妈(Lisa Su)还在 IBM 的时候,也是这规格的重要缔造者。所以 Coreteks 认为,AMD 现在的思路其实和苏妈早年在 IBM 和 Freescale 嵌入式系统和异构计算方面的经历,是有很大关系的。
这种异构融合的思路,则是未来几年 PC 发展首先在游戏机上的一种尝试(虽然我个人真心觉得,难道现在的笔记本和手机处理器不就是这样吗?)——Coreteks 表达比较重要的一点,应该就是一颗芯片解决多种问题...这样一来,PS5 也可以不用过于 bulky(已公布的索尼 PS5 算是 bulky 吗?)...因为索尼在设计上还比较有追求,同时还要控制发热之类的问题。
其实我看 Coreteks 的很多视频,并没有搞清楚他是支持类似 AMD 这样 chiplet 异构的方案,还是颠覆架构去做 monolithic 单 die 方案,因为他似乎对于富士通 A64FX 超算处理器是非常赞赏的;或者他可能最在意的是“通信”部分的高效。
5.
甚至可以认为(coreteks 认为的),AMD 未来的 CPU 很可能会越来越轻 CU 数量,而偏重于频率以及固定功能单元(也就是专用加速单元)...
6.
那么以上这种思路,在游戏机上带来的体验,为什么是将来 PC 给不了呢?
(1)前面我们说到了高带宽的这种诉求,不过知乎上蛮多人提到索尼有“带宽过剩,算力不行”的传统。存储子系统的这种提升,对于开发者而言意味着什么呢?
去年网上出现过一个开发者 demo,用以"showing instantaneous asset streaming",如果没有前文提到的存储一致性(memory coherency)支持,以及超快的 SSD,还有数据解压专用加速器,则完全不可能做到 demo 中演示的样子(具体为什么,我不清楚,各位可以去找一下这个 demo)。这些,正是前面这么多内容提到的 PS5 所专注的方向。
这个 demo“可以实现无缝的开放战争游戏体验,游戏中不会有加载等待画面;画面角色移动速度,甚至可以用来创造一些新的游戏类型,包括开放世界环境的竞速游戏——而且游戏内容元素的数量级可以远超过去的那些游戏;还有过去我们没看到过的游戏类型——比如可能是'画面频繁缩放'的游戏,比如可能是从银河系大画面,极速放大到某个星球,甚至再快速放大到分子级别的画面——在任何一个画面级别,都会有非常牛逼的细节”。
这一点,PC 平台就几乎不大可能实现,起码 PC 平台的 SSD 大部分都不会做到 PS5 的程度。
(2)AMD 去年在 Computex 上做过一个 demo 演示(现在是 3DMarks PCIe 特性测试场景之一),对比的是 Intel Core i9-9900K + 英伟达 RTX 2080 Ti,以及自家的 AMD Ryzen 7 3800X + AMD Radeon RX 5700 Series,如下图。当时的这个演示其实引起了比较大的争议,因为这个演示本质上偏向于高带宽测试,而大家普遍觉得,没有哪个游戏会需要这种场景。
这次 Computex 展会上,AMD 还特别提到了和索尼之间的合作,以及期望革新未来 10 年的游戏。这可能就是索尼游戏主机所真正着力的方向,和未来游戏将要出现的画面——PS5 的带宽也就真正有了用武之地。
PC 享受不到这些游戏,原因同上,毕竟绝大部分 PC 都不会在架构上像 PS5 那样做。
(3)还有一个 demo,是原本要在 PS4 上发布的一个游戏《觉醒计划(Project Awakening)》,现在放出了一个预告片。预告中的画面可能是即时演算的,比 PS4 游戏画面要好多了。Coreteks 认为,这可能是索尼早前提到的加入了光线追踪效果的一个游戏。
番外.
从微软演示的 Xbox Series X《战争机器 5》来看,4K 60fps 效果基本和 RTX2080 Super + R7 3700X 差不多。但算一下一台游戏机多少钱,而后者光一个英伟达的显卡就多少钱,两者加起来 1040 美元...英伟达这种策略怎么还没有翻车?
Coreteks 认为,未来的 APU 可以扫清中低端市场的那些独立 GPU,至于那些硬核玩家,普遍都会转向游戏主机,因为如前文所述,未来很多游戏将是 PC 根本应付不了的,根源在专用处理单元以及带宽差异上。
Coreteks 另外认定,英伟达在这个战局中显得非常被动(说起来英伟达收购 Arm 的话,按照 Coreteks 的说法,做架构变更岂不是可以改变战局?)。Coreteks 为英伟达提了三个建议,其一是“使用硬件加速降低渲染精度”,其二“加强数据本地性·”,其三“加强视觉真实度”。
这部分 Coreteks 其实谈的还是挺悬的,比如第一部分,用硬件加速来降低渲染精度(以节约功耗),而光追也可以用这种方案去做,增加某种类型的硬件,考虑将 FP32 转为 Int8(??有这种操作吗?)...
VRS(variable rate shading)就是在精度方面的一项举措,游戏画面背景可以以明显更低的精度去渲染,前景则用高精度渲染,人眼看起来,整体画面其实也没太大差别。还有 advanced culling(前些年有个针对 Turing 架构 Mesh Shaders 的 demo 演示,就提到过这种 advanced bulling)——coreteks 认为会有专用单元来加速这项技术,如果有 3 个固定单元来渲染画面中,不同远近的对象,则针对主要注意力的部分做高精度渲染,而某些部分则完全可以用低精度去搞,又完全不会影响到游戏体验(当然估计会对跑分有影响)。
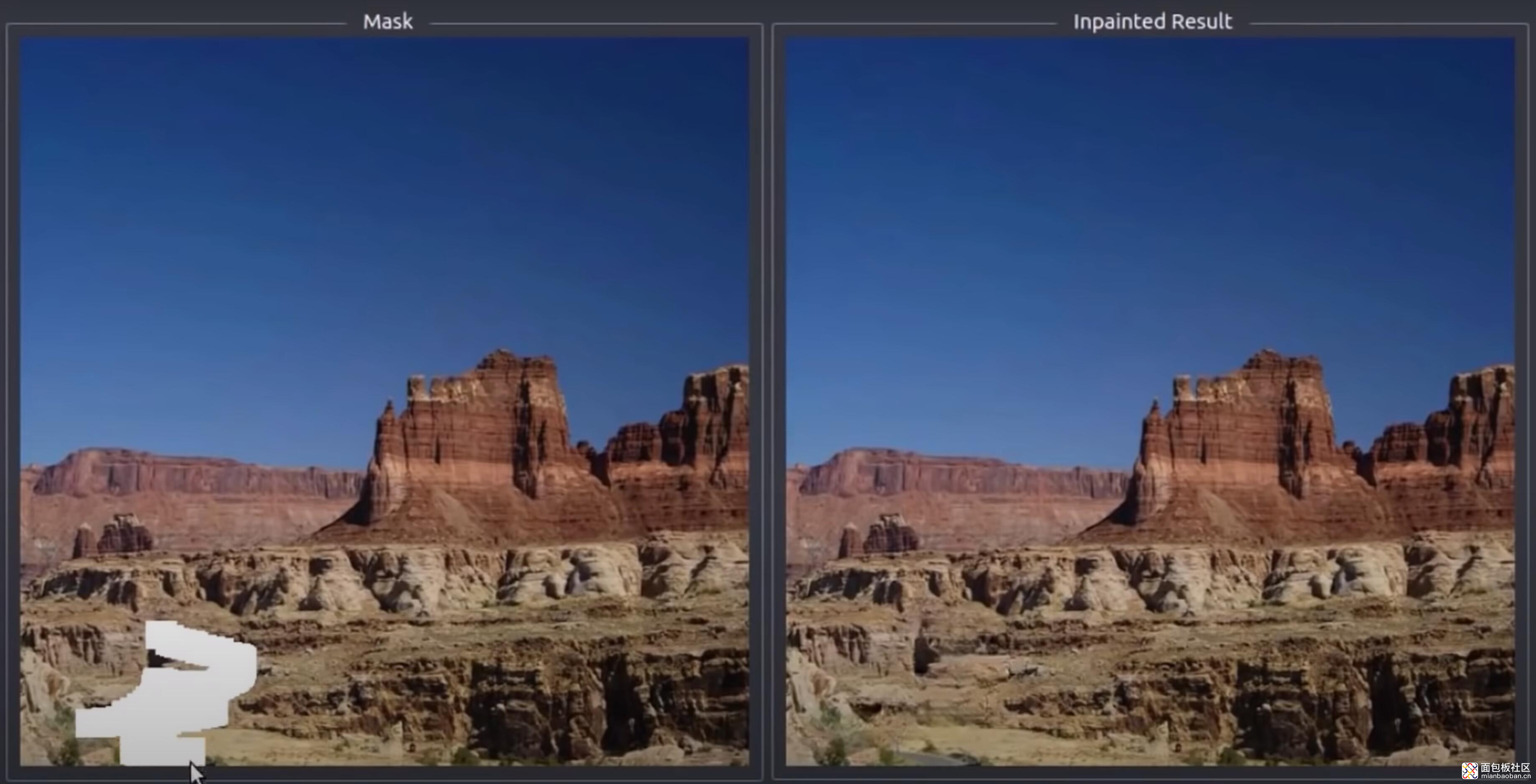
另外,英伟达还有一个强项,就是 AI 部分,也可以用来降低精度。早前英伟达曾经放出过,把画面中缺失的部分给自动补上的技术,靠的就是 AI(下图)。这种技术或许就可以应用到游戏中去,用以渲染游戏画面中一些无关紧要的对象。
前面提到第二点,“加强数据本地化”,其实就没什么要多说的了。现在的专用芯片制造商,恨不得把片内存储堆到可以把一大堆模型放下的程度,这主要还是个成本的问题。
第三点,“加强视觉真实度”。Coreteks 针对这一点有特别提到,英伟达现在应该再引入一项类似实时光线追踪这样的技术点,但要足够吸引人,实现对竞争对手的绝对技术领先——比如 AMD GPU 的游戏机也实现不了,那就真的炸裂了。可能还是跟 AI 机器学习相关的技术——毕竟这是英伟达投入了很多年、花了很多钱的优势项。
英伟达今年的 GTC2020 有演示在网上放出来,部分内容其实跟游戏关系并没有那么大,但也是图形计算相关的。好像是迪士尼的一个什么电视节目场景,采用虚幻引擎去录制——或者说是一个 AR 现实增强实现,生成虚拟的背景,前景还是拍摄的真人,类似于实时特效,而且随时都可以切换!好像完全看不出破绽,完全高保真,让人觉得,主持人或者演员就是在现场。类似这样的技术,也就可以拍死 AMD 企图构建的上面提到的世界了。
好了,以上大部分内容都出自 Coreteks,有兴趣的去看看这个视频吧,我觉得我基本上已经把他要说的东西传达到位了。这则视频的意淫成分颇多(而且 Coreteks 的绝大部分视频都是在意淫)。如果有事实错误,也欢迎各位指出。事实上,即便存在非常多相当夸张的想法,但我总体上觉得,数字芯片往“专用”化发展,以及企图解决数据与通信问题的方向,可能都是值得思考借鉴的。仅供各位娱乐。
推荐阅读:




















 /4
/4 







FPFA兔兔爸 2020-8-8 15:19
禁止 中国接触并获得 PS技术
到今天,OS5还是对中国禁止销售吧?