其实 Intel 的 10nm 工艺是 2、3 年前就已经有国外媒体和机构介绍过的,一直都想整理出来与各位爱好者分享。不过先前忙,始终没有时间去整理。这次期望抽几个周末来搞定这篇姗姗来迟的文章。我在想,这种文章理论上的确是定位于像我这样的半导体技术爱好者,作为拓展见闻的一种方式存在。
恰巧 Intel 也在 8 月的 Arch Day 2020 举办线上活动——是以闭门的形式。会上的重点内容自然就是 Tiger Lake 处理器(Willow Cove 核心)还有 Xe 图形处理器了。Tiger Lake 的升级重点之一就是 10nm SuperFin 改进版工艺——很多人不知道的是,从 Intel 初代 10nm 工艺问世,到 Ice Lake 应用 10nm+,到这一代 Tiger Lake 已经算是 Intel 的第三代 10nm 技术了,而 10nm SuperFin 大概才是 Intel 真正成熟的 10nm 工艺。
有关 Willow Cove 处理器核心,以及 Xe GPU 的内容,因为本身也都是很庞大的话题,所以未来会单独成文(虽然不知道是何年何月)。另外,在本文写到一半的时候,我发现文章篇幅实在是太长了,所以决定把这篇文章剖成上下两篇来刊,本文是上篇。
这里提醒一下,某些英文单词我在文章里没有翻译成中文,是因为我觉得中文的表达可能欠妥,或者有些词我不知道应该怎么翻译成中文。比如我觉得 gate 译作“栅”其实是挺让人费解的。所以在我看来,某些东西没有必要去尝试理解其中文的表意。比如你知道晶体管的某个部分叫 gate 就可以了,至于这东西究竟算是门、闸还是栅,那都无关紧要。
一个更为典型的例子,在本文中是 Contact Over Active Gate,我觉得译作中文以后将让人非常难以理解。对这个词而言,你有一定的英文基础,并且读到相应位置,应该自然能理解它表达的是什么意思。
这里强调一次,本文的素材主要来自 AnandTech、Wikichip、Semiconductor Engineering,以及 Solid State Technology 和 TechInsights,我对某些内容进行了二次演绎;其中的数据与内容是经过了这些媒体与机构大量努力与研究得到的,这些都不是我的研究成果,我只扮演翻译、注释和学习的角色。个人水平有限,存在理解错误之处,也欢迎各位指正。
Intel 的 10nm 工艺最早其实可以追溯到 Cannon Lake 时代——很多对 Intel 产品不熟的人,应该都不知道 Cannon Lake 的存在——这才是 Intel 首款应用了 10nm 工艺的 CPU 产品。那是 2018 年的事情了——Cannon Lake 芯片最早亮相是在 2017 年的 CES 消费电子展上。但因为工艺不成熟,Cannon Lake 始终未能大规模面世——只在极个别的小众机型上稍稍地露了个面,不仅只有双核心,而且还禁用了集成的 GPU——很大程度表明良率问题大,Cannon Lake 便神不知鬼不觉地成为了历史。
10nm 还算是大规模量产,就要到现在大部分人都知道的 Ice Lake 上了,虽然其实 Ice Lake 也仅是以低压处理器的面貌出现,主频也不及 14nm 那么高。至少表明直到十代酷睿 Ice Lake,Intel 的 10nm 工艺都始终称不上真正成熟。不过探讨 Intel 的 10nm 还是不得不从 Cannon Lake 开始聊。10nm SuperFin 我会放到下篇去谈。
初代 10nm 工艺的晶体管密度
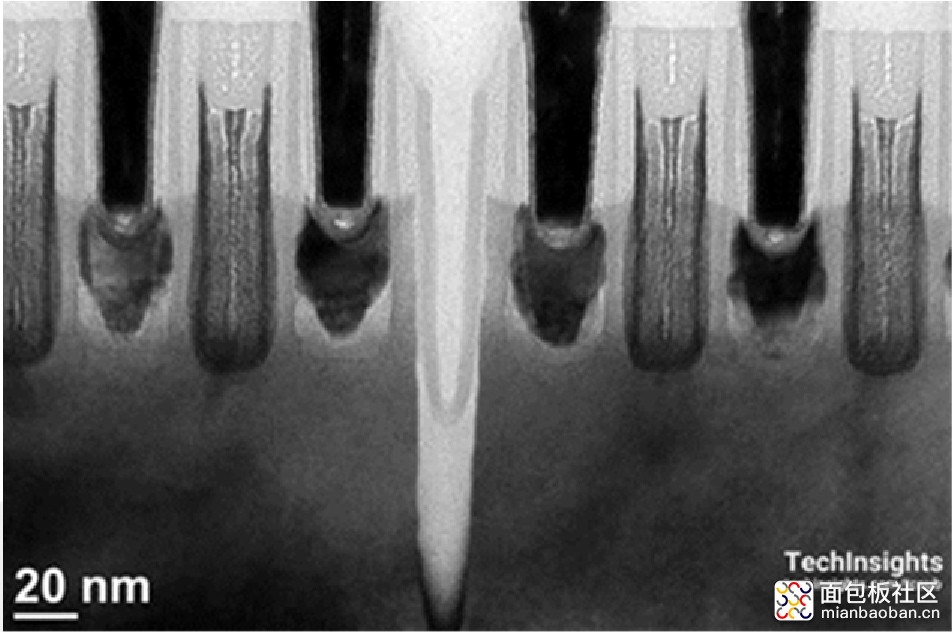
下面这张图就是当初面世的 Cannon Lake 芯片,来自 TechInsights,数字标注则是由 WikiChip 进行的。这是一颗双核处理器,核显部分包含了 40 个 Gen10 执行单元,不过产品面世的时候,核显是禁用的。右边那个是 I/O die,左边主 die 的尺寸是 70.52mm²。
来源:TechInsights[9] & Wikichip[4]
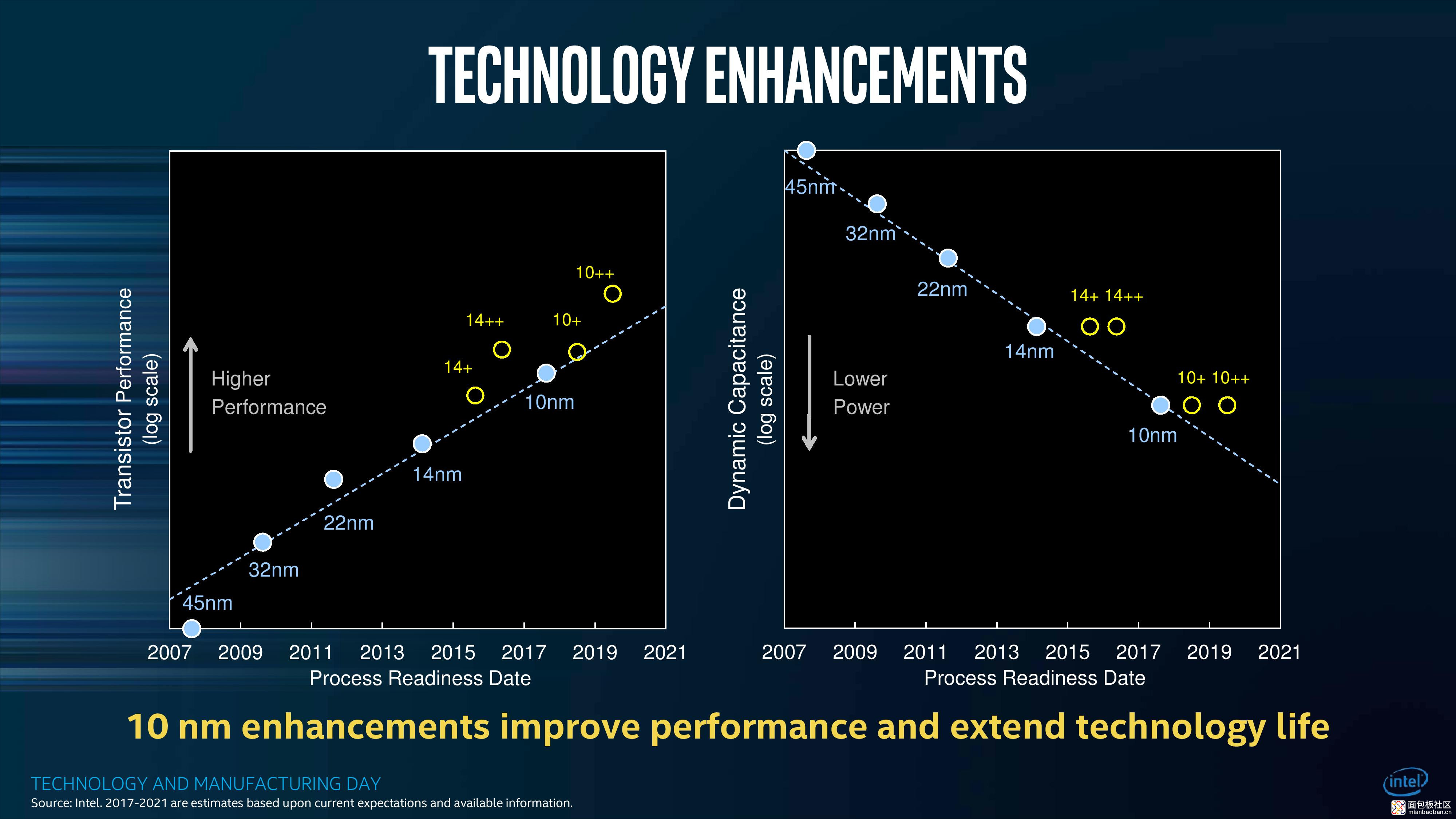
首先来聊下晶体管密度,这好像也是绝大部分爱好者关心的话题。Intel 在 2017 Technology and Manufacturing day 之上呈现的下面这张图——表明其 10nm 工艺相比 14nm,晶体管密度提升 2.7 倍,达到了 100.8 MTr/mm²(百万晶体管每平方毫米)。2.7x 这个倍率其实是比过往任何一次工艺节点迭代都更为激进的——很大程度上也被视为 Intel 未能及时达成 10nm 规模化量产目标的很大一部分原因。
作为对比,这里可以给出三星和台积电近代工艺的数字。从 Wikichip 的数据来看,台积电的 7nm(N7)工艺晶体管密度在 91.2 MTr/mm²(特指高密度单元;另:N7+ 大约是 N7 的1.2倍),5nm(N5)工艺晶体管密度预计为 171.3 MTr/mm²(应该也是指高密度单元);[10]
三星这边, Wikichip 预计其 7nm(7LPP)工艺晶体管密度 95.08 MTr/mm²(HD高密度单元,且为 54nm gate pitch 版,57PP 版会更稀疏),而 5nm 工艺约在 112.79 MTr/mm²(54PP 版)[11]。不过这些数字可能无法直接比较,一方面在于计算晶体管密度的方法;另一方面在于不同的单元库,即便是同一个厂商的同一代工艺,晶体管密度原本也就是不一样的。下文会进一步提到这一点。
当时 Intel 提出一种新的计算晶体管密度的方法。因为以前更早几代的工艺,标准单元的设计是大致相似的,所以要算密度就会相对比较容易。比较古老的一种计量密度的方法,其实是用 CPP(contacted poly pitch,即 gate pitch,栅间距)去乘以 metal pitch 最小金属间距。
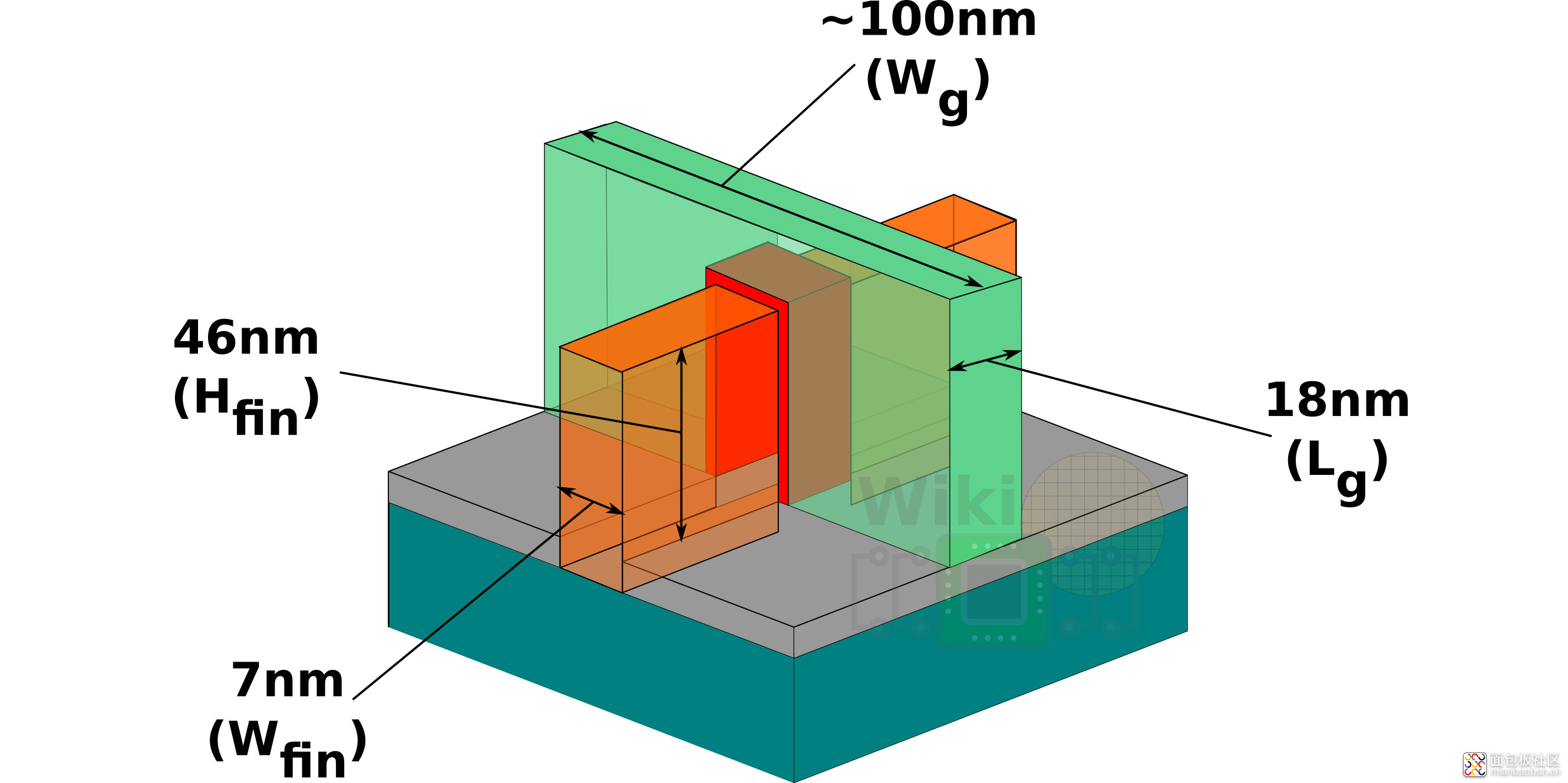
FinFET 晶体管的 fin 与 gate,来源:Lam Research
到了 FinFET 晶体管时期,增加 fin(鳍)高度、减少 fin 之间的间距就能有效增加驱动电流。驱动电流上去之后,就可以减少 fin 的数量——一个单元减少 fin 的数量,也就实现了金属 track 的减少,可以降低动态功耗,与此同时确保性能,甚至还能通过一些优化手法来提升速度。
在金属 track 减少之后,传统计算密度的方法其实就不怎么准确了,因为它其实不能反映单元高度减少这样的实际结构变化。所以后来有方法是 CPP 乘以 MMP(最小金属间距),再乘以 Track 数。有关“单元(cell)”的介绍,在本文的下一个段落——它是几个晶体管组合而成的。
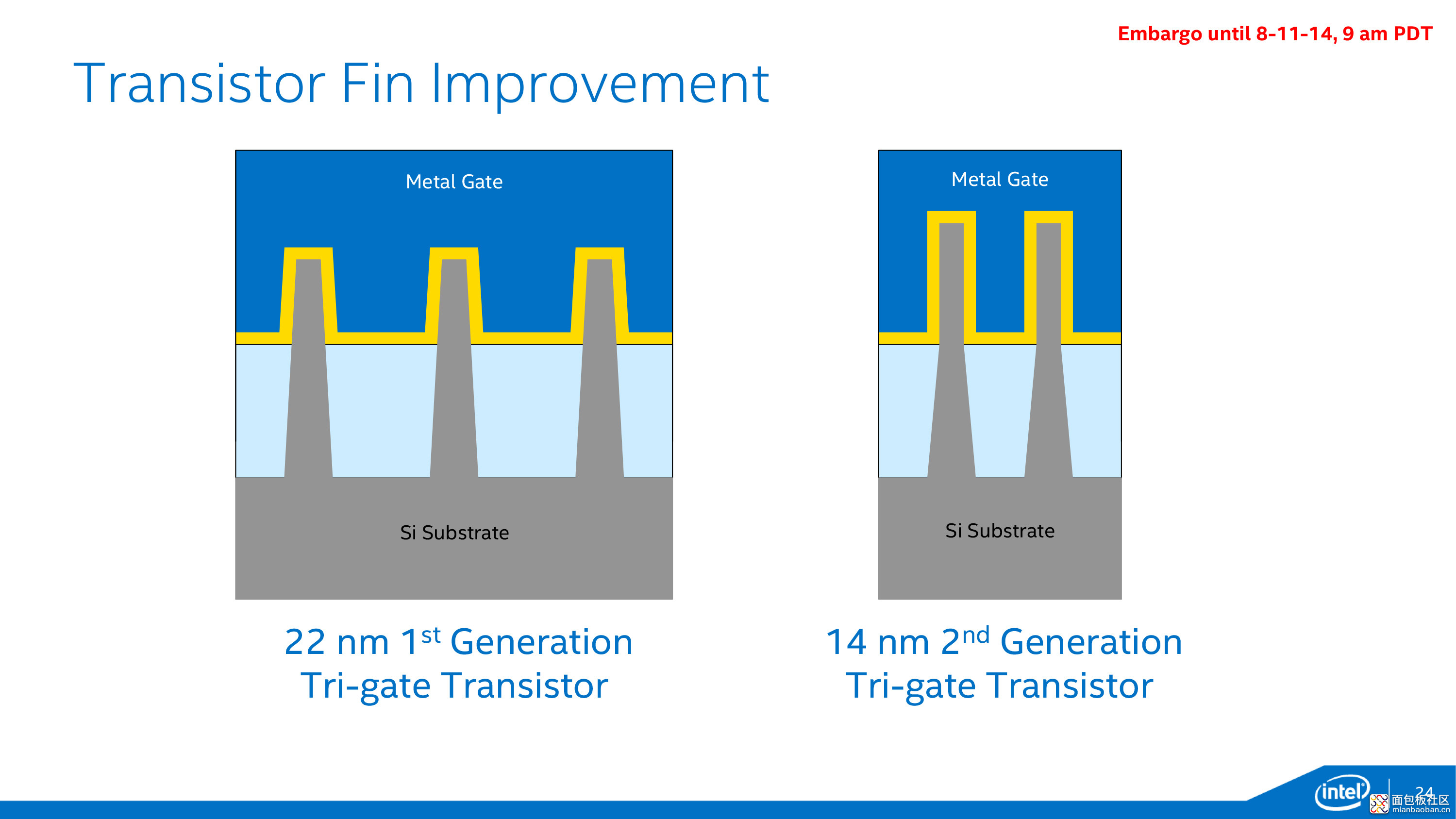
Intel 22nm 工艺,fin 与 gate 交错的晶体管构成的单元(cell)
但更多的结构优化,比如后文会提到的 COAG 技术进一步降低了单元高度,同时采用 dummy gate 来缩减单元的宽度。那么在单元宽度、高度同时降低的情况下,上面这种计算方法就又不准确了。所以当时 Intel 引入新的计算密度的方法是这样的:
这个计算等式中,分母部分的单元面积,就是用单元高度乘以单元宽度。Wikichip 在文章中提到,这种计算方法其实不能算新,以前就有人提出过,只不过现在被 Intel 又翻了出来。Wikichip 认为,这种计算方法一方面考虑到了常规缩放(CPP x MMP),另一方面也考虑到了 track 数量的变化;与此同时上面这个等式还考虑到了影响单元宽度的其他优化方案。[2]
这个等式中出现了两种常见的标准单元:NAND2 门(2-input 与非门),以及比较大的 scan flip-flop 单元(扫描触发器)。与此同时,等式将 60% 的权重给了小型逻辑单元,40% 给了复杂单元。
比如说,NAND2 门是由 4 个晶体管组成的,fin pitch 是 34nm,整个单元的高度是 272nm;gate pitch 是 54nm,则单元宽度为 54 x 3nm;。所以就是 4/[272 x (54 x 3)] = 90.78 MTr/mm²。同理,Scan Flip-Flop 单元的整体密度为 115.74 MTr/mm²。经过加权之后,差不多在 100 MTr/mm² 上下。Intel 的芯片一般包含了更多大型与复杂逻辑单元,所以这个计算方法其实对 Intel 会比较有利。
但实际上,即便是这个公式也并不能真正彻底反映晶体管密度。典型的比如 SRAM 单元,即处理器的 cache 部分,占到了 die 的最大一部分。如果将 SRAM 作为计算晶体管密度的组成部分,则数字会不够靠谱。所以 Intel 此前还表示,除了标晶体管密度之外,还应当标 SRAM 单元尺寸。
与此同时,芯片上还会有所谓的 dead silicon 作为一种热缓冲。所以如今的晶体管数字,更多的应当作为一种参考来看,毕竟晶体管并不是以均匀的方式分布在 die 上的。
Intel 工艺节点密度,数据来自 AnandTech[1]
IEDM 2018 大会上,Intel 针对更早的工艺,又给出了一些不同的晶体管密度数字。应该就是针对老版工艺,重新采用 Intel 提出的这种计算方法。
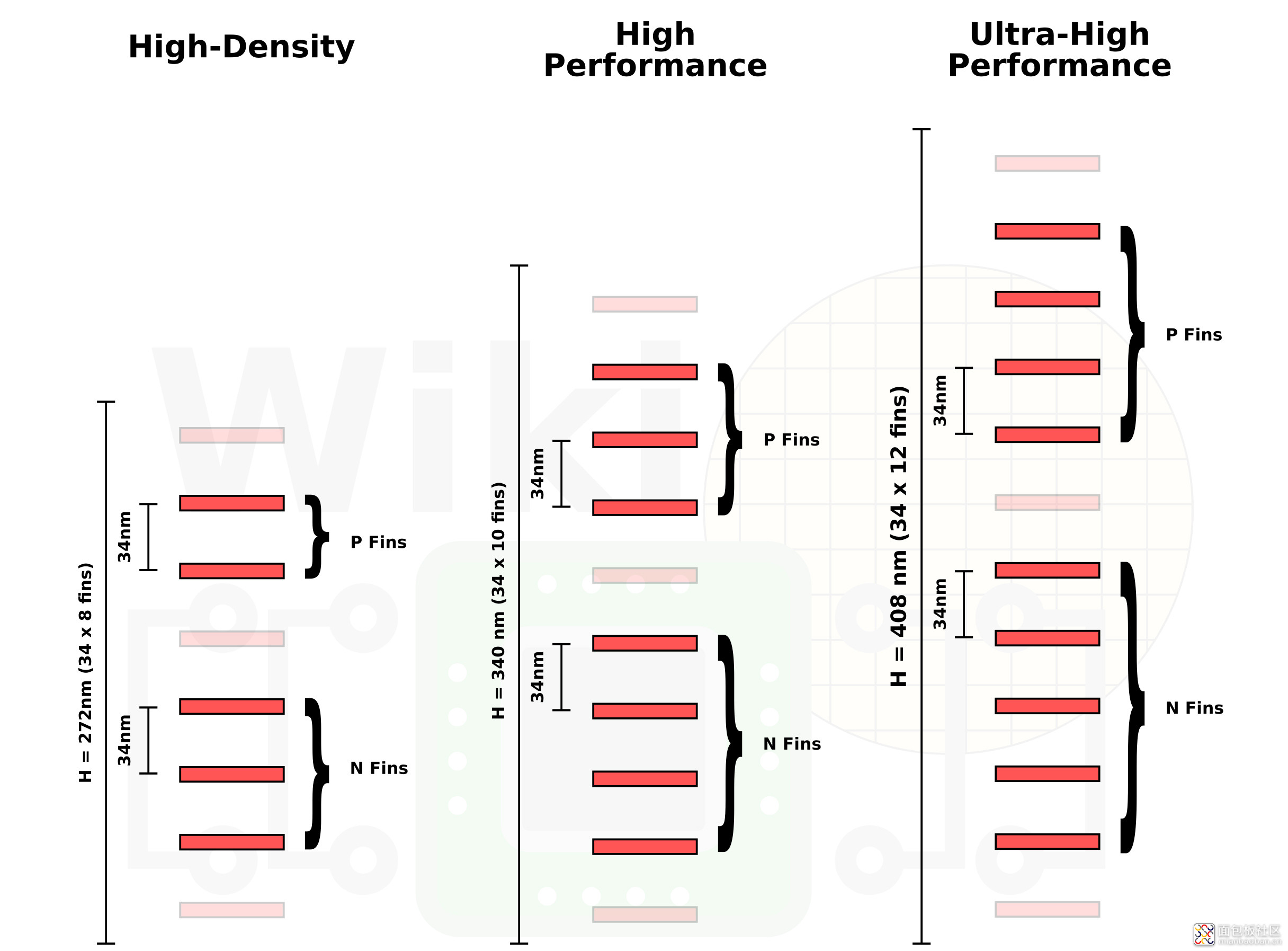
当时 Intel 还提到,基于功能要求,10nm 工艺有三种不同类型的逻辑单元库,分别是 HD(高密度,short libraries 短库)、HP(高性能,mid-height libraries 中等高度库)、UHP(超高性能,tall libraries 高库)。越短的单元库,功耗越低,密度越高,不过峰值性能也越低。
芯片设计就是多种单元库的混合,一般来说越短的库对于那些成本更敏感的应用,或者是 I/O 和 uncore 部分来说,是更为适用的。越大的库,当然密度就越低,有更高的驱动电流,对于设计中最关键的路径当然就更为可用。
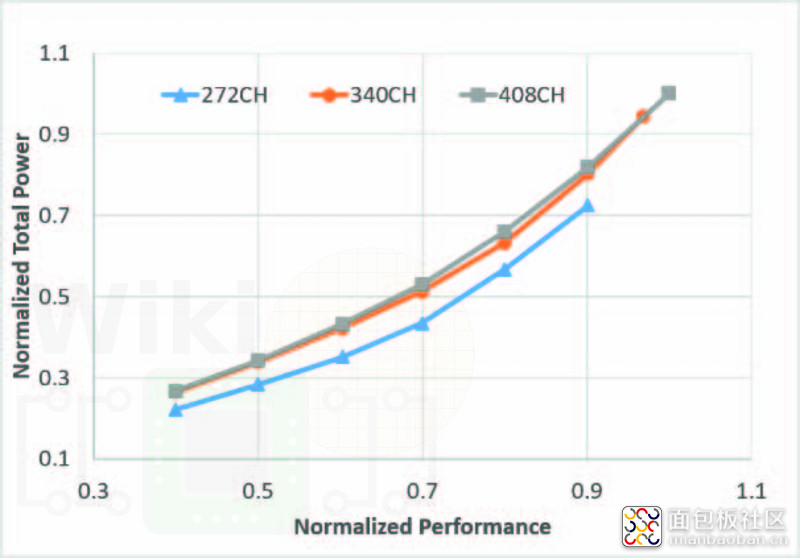
这三种单元库的密度自然也是不同的,Intel 列出的 100.8 MTr/mm²,指的其实是 HD 高密度库(单元高 272nm,8 fins)。其他两种单元库的密度分别为:HP(高性能)单元库密度 80.61 MTr/mm²(单元高 340nm,10 fins);UHP(超高性能)单元库晶体管密度 67.18 MTr/mm²(单元高408nm,12 fins)。
不同单元库在尺寸上的差异,主要是由每个单元的 fin(鳍)数量差异导致的。Fin 数量不同,单元高度就不同;对于更高的性能而言,更多的 fin 就支持更高的驱动电流,即以功耗和面积为代价。下面这张图是 WikiChip 呈现这三种库功耗与性能方面的关系的。
来源:Wikichip[3]
所以,HD 单元主要为那些非性能相关的部分准备,HP 单元应用在绝大部分需要性能的部分,而 UHP 单元针对关键路径。所以最终一颗芯片的密度怎样,其实很大程度取决于不同部分的设计采用何种单元,及其占地面积是多大。
晶体管的变化
一个晶体管,源极(source)到漏极(drain),即是嵌入在氧化物(oxide,蓝色部分)中的 fin(鳍,灰色部分),穿过 gate(栅,绿色部分)。这其中的一个关键参数,就是 fin 高度,fin 宽度,以及 gate 长度。所谓工艺的进化,就是要让这几个参数尽可能变小,与此同时保证速度性能表现。
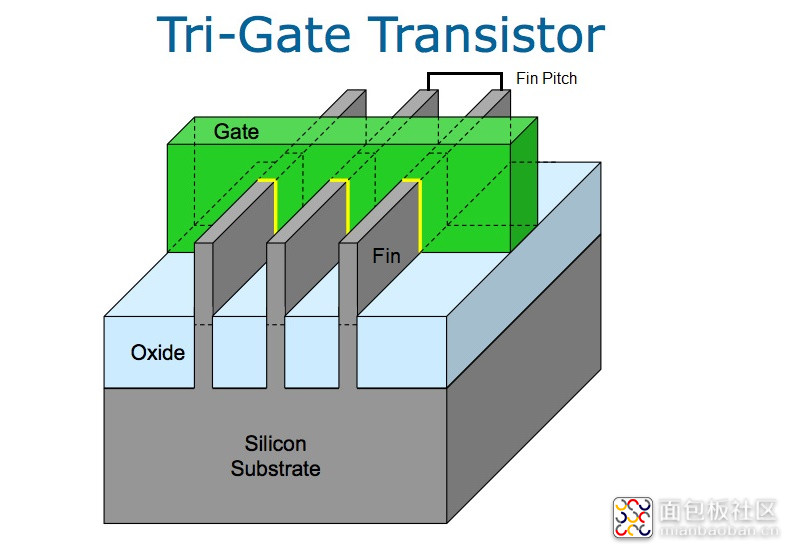
Intel 的 22nm 工艺时期就采用一种所谓的 tri-gate(三栅)晶体管,包含了多个 fin,为实现更好的性能,增加总的驱动电流。
Fin pitch(鳍之间的间距)是衡量工艺先进性的一个重要参数。另外,如果一个 fin 穿过多个 gate,则 gate pitch(栅间距)也需要考虑进来。
Fin 实际上长上图这样,这是一个剖面图——第二张图助于理解。这张图中,Intel 展示了 22nm 到 14nm,fin 高度变高了,fin 宽度缩减,fin pitch 当然也更短了。另外 fin 嵌入到 gate 中的部分也更多了。Fin 与 metal gate 的接触面更大,fin 本身与 fin pitch 更小,那么漏电流就更小,性能也越出色。整体上就是为了增加驱动电流,与此同时处理好寄生电容和栅电容(gate capacitance)的问题。
而在 10nm 工艺上,Intel 对 fin 的设计还是比较激进的(至少相比 14nm),其变化情况如下:
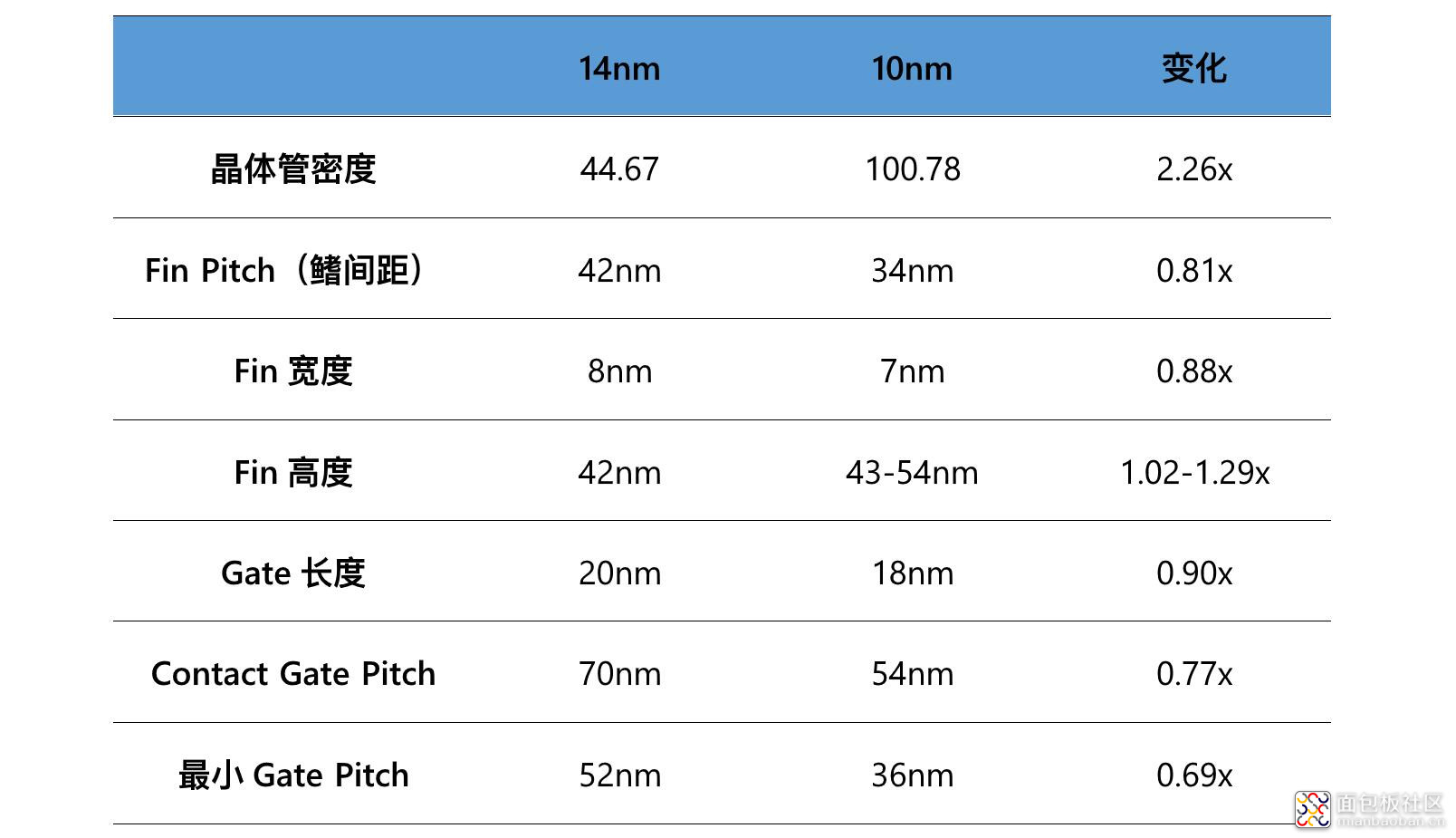
这里的 gate 长度,注意是下图中的 Lg,而不是 Wg
来源:Wikichip[2]
给出各部分参数示意参考,来源:Semiwiki[12]
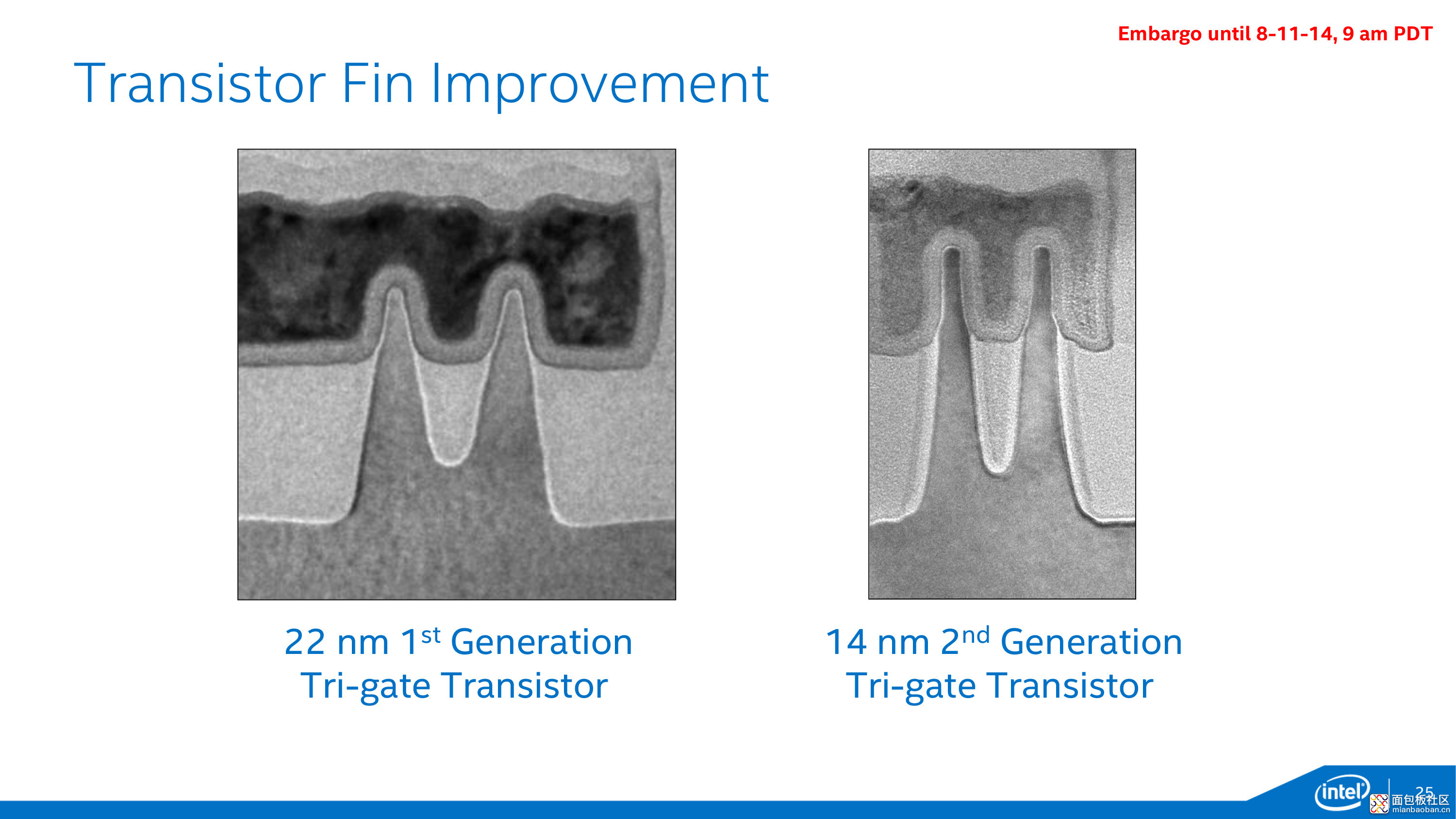
IEDM 2017 大会上,Intel 表示 10nm 工艺的晶体管 fin 高度在 43-54nm(官方数字 46nm),原本上一代工艺是 42nm,fin 与 gate 的接触面更大。Fin 高度可以根据晶体管的需要做调整。Fin 宽度则从 8nm 降至 7nm——看看,在 10nm 工艺下其实是有某个参数在 10nm 以下的。如此一来 gate 的宽度达到了大约 100nm。
Fin pitch 部分,Intel 的 10nm 工艺是从 42nm 缩减至 34nm。Fin pitch 缩减的技术挑战越来越大,此处是应用了 SAQP(Self-Aligned Quad Patterning,自对准四重曝光)技术的。这应该也算是众所周知的了。
Wikichip 针对 SAQP 的简短解释:先有两层牺牲层(sacrificial layers),以 136nm 的间距做第一层曝光。随后对 spacer 层(间隔层)进行沉积和蚀刻,移除第一层牺牲层,蚀刻到第二层牺牲层,就有了 68nm 间距。然后再对第二层间隔层进行沉积和蚀刻,移除第二层牺牲层,在 fin 上蚀刻,移除第二层间隔层,就能获得 1/4 的间距了。总共 4 道额外的工序,包括三次蚀刻,一次沉积。
对于制造工艺来说,增加更多的步骤,生产时间就会更久,产量会有损失。最终 Intel 的 10nm 初代工艺的 fin 长下面这样,其中加入了与初代 22nm FinFET 工艺的对比。
虽说看起来好像也没什么,但如此一来,fin 就能以更为密集的方式制造出来了,而且和 gate 之间能有更大的接触面积。这对于驱动电流会有帮助。
Fin 与凹槽(gate 下面的那个灰色区域)的接触区域其实也很重要,其中的接触电阻是需要考虑的问题。Intel 在 10nm 工艺中,将这部分的钨材料换成了钴,据说这种材料能够实现线路电阻 60% 的缩减。
另外,Intel 还围绕源极和漏极外延部分,增加了保形钛层(conformal titanium layer);并且针对 pMOS 外延层增加了一个单硅化镍层,降低接触电阻。Intel 宣称此举可以达成 1.5 倍的接触电阻降低。[7]
晶体管还有一些别的改进,不过综合包括 Wikichip、AnandTech、Semiconductor Engineering 与 Solid State Technology 几家机构的介绍,其中一些我并不是很理解,有兴趣的同学请移步文末给的链接——这里我也稍微给出一些我个人的理解,可能存在错误。Wikichip 在文章中提到说,10nm 节点上,最小的 gate 长度(length)是 18nm,而 gate pitch 为 54nm。这其中是第七代应变硅(strain silicon)外加个 stresser——这个 stresser 我觉得可能是指的应力层,或者某种应激的介质?且 Intel 在此还引入了新的 ILD0(第一介电质层)stresser,贯穿 gate,与 fin 相交处,用以加强 nMOS 晶体管的驱动电流。[2]
与此同时,在 gate pitch 逐渐变小的过程中,gate 与 contact(这里的 contact 应该是与上层 MOL 之间的 contact,不过好像 gate 整个外层都应该有个 spacer 层,所以或许也相关于 gate 与 fin 的 contact)之间的空间变得越来越局促,其中的 spacer 层也就变得更小了。也就是说,contact 与 gate 之间的寄生电容对晶体管性能的影响也越来越大。Intel 的 22nm 工艺就开始采用 low-k(低介电常数)的 spacer,而在 10nm 工艺上,Intel 表示这里的 spacer 有更低的介电常数,相比上一代降低 10% 的电容。[2]
上面所有这些工程方面的努力,带来的自然就是相比 14nm 比较大幅度的提升了。nMOS 驱动电流(IDSAT,工作在饱和区的电流驱动能力)提升 71%,供电电压 0.7V 时驱动电流每微米 1.8mA,Ioff(关断电流)每微米 10nA。nMOS 的 IDLIN(工作在线性电流特性区的电流驱动能力)为每微米 0.475mA,相比 14nm FinFET 晶体管表现有 100% 的提升。
而在 pMOS 这块,0.7V 供电电压驱动电流每微米 1.55mA,每微米 Ioff 则为 10nA,pMOS IDLIN 每微米 0.325mA;相比 14nm 提升 55%。[2]
单元库
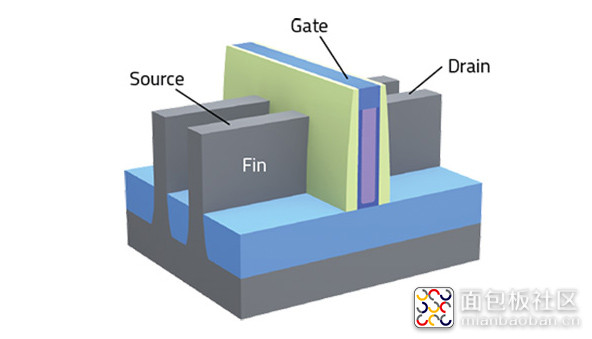
一个单元,实际上就是几个 fin 与 gate 的组合。每个单元都需要在上下端接地和电源。然后单元本身做各种混合搭配。前文就展示过一张 Intel 22nm 工艺的 SEM 图,那张图展示的单元有 6 个 fin 的,也有 2 个 fin 的,另外也有不同长度的 gate。
在每个单元中,有通电流的 active fin,还有作为间隔存在的 inactive fin。Intel 最高密度单元(HD),总共会有 8 个 fin,其中仅有 5 个是 active fin。
来源:Wikichip[3]
这种单元库主要是为成本敏感型应用准备的,这些应用要求较高的密度,或者对性能没有太高要求,典型的比如 I/O。这 8 个 fin,两个 active 'P' fin,两个 active 'N' fin,外加一个可选的 active 'N' fin——针对的是各种有先后顺序的逻辑功能,比如说与非门接或非门。
还有其他类型的单元库,HP(高性能)与 UHP(超高性能),分别有 10 个和 12 个 fin。这两者都有一个额外的 P fin 和一个额外的 N fin,这两者能够帮助提供更大的驱动电流,在一定程度牺牲效率的情况下达到更好的峰值性能。而单元高度,也就是用 fin pitch(fin 之间的间距)去乘以 fin 的数量。
来源:Wikichip[3]
值得一提的是,图中虚化了的 fin,在设计中通常也是存在的,在设计中作为 dummy fin 存在。
衡量密度的一个方法,前文就提到是将 gate pitch(栅之间的间距,或者叫 CPP, contact poly pitch)去乘以 fin pitch(MMP, minimum metal pitch 最小金属间距)。这个参数会比 10nm、7nm 这种用于市场宣传的节点数字,更能够表达工艺先进性,虽然如前文提到的,这也已经不足以描述现如今的晶体管密度了。
其实单纯用这种方式去衡量密度的话,实际上台积电的 7nm 和三星的 7nm 都比 Intel 的 10nm 略微更密一些。这应该也是 Intel 期望重新定义晶体管密度计算方法的原因。不过这种算法的确没有考虑到不同高度单元库的差异。另外,单元库的大小其实也的确并非唯一需要考虑的问题。
来源:AnandTech[1]
值得一提的是,Intel 10nm 工艺的 SRAM 单元缩减至 0.6 倍。高性能单元(Pull-Up:Pass-Gate:Pull-Down 晶体管比例为 1:1:1)从原先的 0.0499μm² 缩减至 0.0312μm²;而高性能单元面积缩减至 0.0441μm²。Wikichip 有做一张点阵图,展示每一代节点 SRAM 单元尺寸的历史变迁,整体上还是摩尔定律的大趋势,不过的确在这两代有了显著的速度放缓(而且实际就年份来看,那就更是速度上的放缓了)。[2]
提升密度的 Hyperscaling
Intel 在 10nm 工艺介绍时提出了一个新的营销词汇叫 hyperscaling,大致上就是指大肆增加晶体管密度的方案。除了晶体管本身各长宽高、间距之类的缩减外,还包括了两个比较重要的方案,分别是 dummy gate 和 COAG。
dummy gate
在单元库之间,会有几个 dummy gate,主要用于间隔。Intel 的 14nm 设计中,每个单元的两端都会有 dummy gate,也就是说两个相邻的单元之间,就会有两个 dummy gate。而 Intel 的 10nm 工艺,两个相邻的单元则可以共享一个 dummy gate。
这一点对密度提升一定是有好处的,如上图所示,Intel 宣称能有 20% 的空间节约。从 Intel 在前两年 ISSCC 展示的图片来看,这部分可能并不是真正的 gate,而是个蚀刻比较深的凹槽间隔。早前 TechInsights 就发现三星在 10nm 工艺中也曾经采用这种方法来隔离单元。
三星 10nm 工艺中的 dummy gate,来源:TechInsights via Solid State Technology[7]
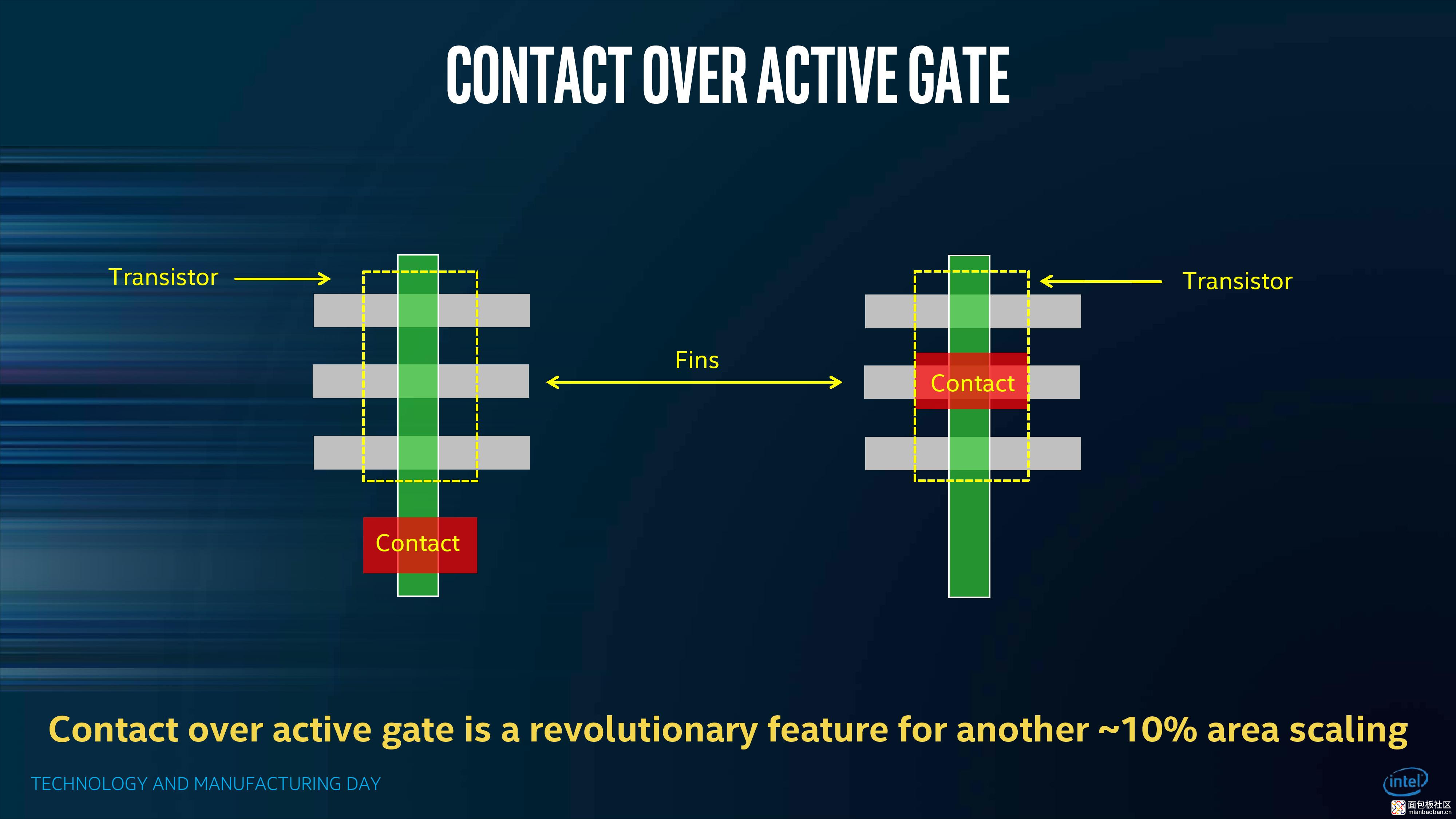
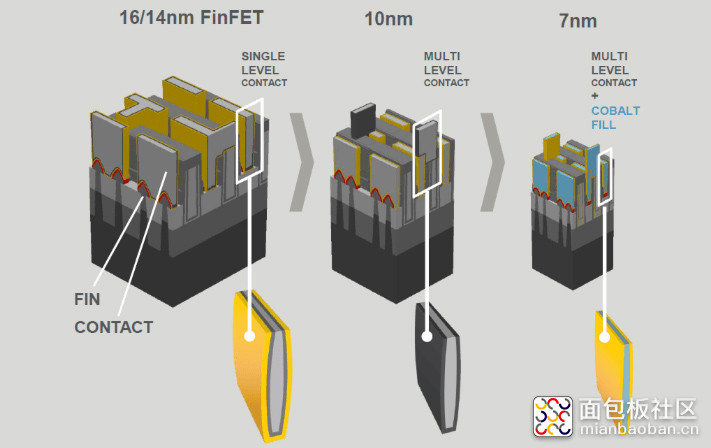
COAG(Contact Over Active Gate)
在一个晶体管内,gate contact(栅接触点)是源极(source)到漏极(drain)电流的控制点;gate contact 就连接上层的 via 导孔了。一般来说,gate contact 会伸到单元之外的地方(虽然 gate contact 也是在上方)。
这是需要额外空间的。Intel 10nm 采用了一种名为 COAG 的方法,把 gate contact 直接放到晶体管"active"区域的上方。
这种改变还是颇为复杂的。有报道说 COAG 是 Intel 10nm 工艺中比较冒进的一部分,而且虽然 Intel 的确做到了,但可靠性不及预期。
这种工艺包括,针对 diffusion contact(源极/漏极触点)与 gate contact,要采用自对准触点工艺流程。实际上,Intel 已经在 22nm 节点上采用了自对准 diffusion contact,所以这次的工艺也算是个扩展。具体是怎么做的,这里就不具体写了,有兴趣的同学可以去看 Solid State Technology 和 Wikichip 的文章[2][7]。
这部分就给制造过程增加了多个步骤。在面积方面能带来大约 10% 的收益。
AnandTech 早前与 Intel 的采访可知,Cannon Lake 之上的 COAG 设计可能仅应用于低功耗/低性能设计,或者高性能/超高功耗设计——而没有更偏中等的设计。[1]
所以总的来说,基于上述 CPP 与 MMP 的调整,以及 dummy gate、COAG 的这些设计,Intel 表示初代 10nm 工艺相比 14nm 达到了 0.37x。
钴材料的应用
随着工艺节点推进,上层的 interconnect 层,导线也在变小。导线变小的另一个问题是:当电子穿过更小截面积的导线时,会导致电阻的增加。这两者之间的关系是成反比:
导线的电阻 = 电阻率 x(长度/截面积)
理想情况下,截面积变小,那么就需要用更低导电率的金属。另一方面,更大的驱动电流,本身会带来电迁移之类的连锁效应。
所以 Intel 针对更低层的金属层,也就是最细的导线换用了钴。钴的电阻率实际上是高于铜的,将近 4 倍差异。那么为什么还要换成钴呢?铜原本作为一种常规材料,主要在:电阻率低、缩放性好。
20 多年前的 IEDM 1997 大会上,IBM 宣布计划在制造过程中融入铜 BEOL 技术。于是 1998 年的 180nm 工艺中,IBM 就将铝互联换成了铜互联——主要是因为其低很多的电阻率、更高的可扩展性以及更高的电流密度能力性能。
铜的电阻率是低于铝、钨、钴这些材料的。而铜在当代被替换,主要问题在电迁移(Electromigration)。电迁移,发生在金属结构中高速电子撞击金属原子时,金属原子产生定向扩散,导体某些部位产生空洞或晶须。通常这不是什么大问题,但在电流增加、截面积减小后,更多电子的存在可能会成为一个问题。越多原子偏移位置,导线电阻就越高,直到完全断连。电迁移更多发生在金属的晶粒边界,以及平均自由程(mean free path)比较长的时候(平均自由程是指电子在两次连续碰撞之间,可能通过的各段路线长度的平均值)。
在具体实施中,针对电迁移问题,其实工程师们还是做了比较多的努力的。包括增加扩散阻隔层(diffusion barrier)以及衬垫(liner)。
(貌似在 20nm 工艺时期,liner 就已经采用钴材料,更早以前是钽;早前曾有建议 liner 用钌的,但工艺上有难度。另外 TechInsights 的报告中说,在 Cannon Lake 处理器的更底层检测到了钌[9]:Intel 并没有透露这方面的信息。美国应用材料先前在演讲中也提到过钌,IBM、三星、GloblFoundries 此前也探讨过 7nm 以下工艺应用钌和钴的可行性。Wikichip 猜测,M2/M3/M4 金属层可能用到了钌[4])
来源:Wikichip[2]
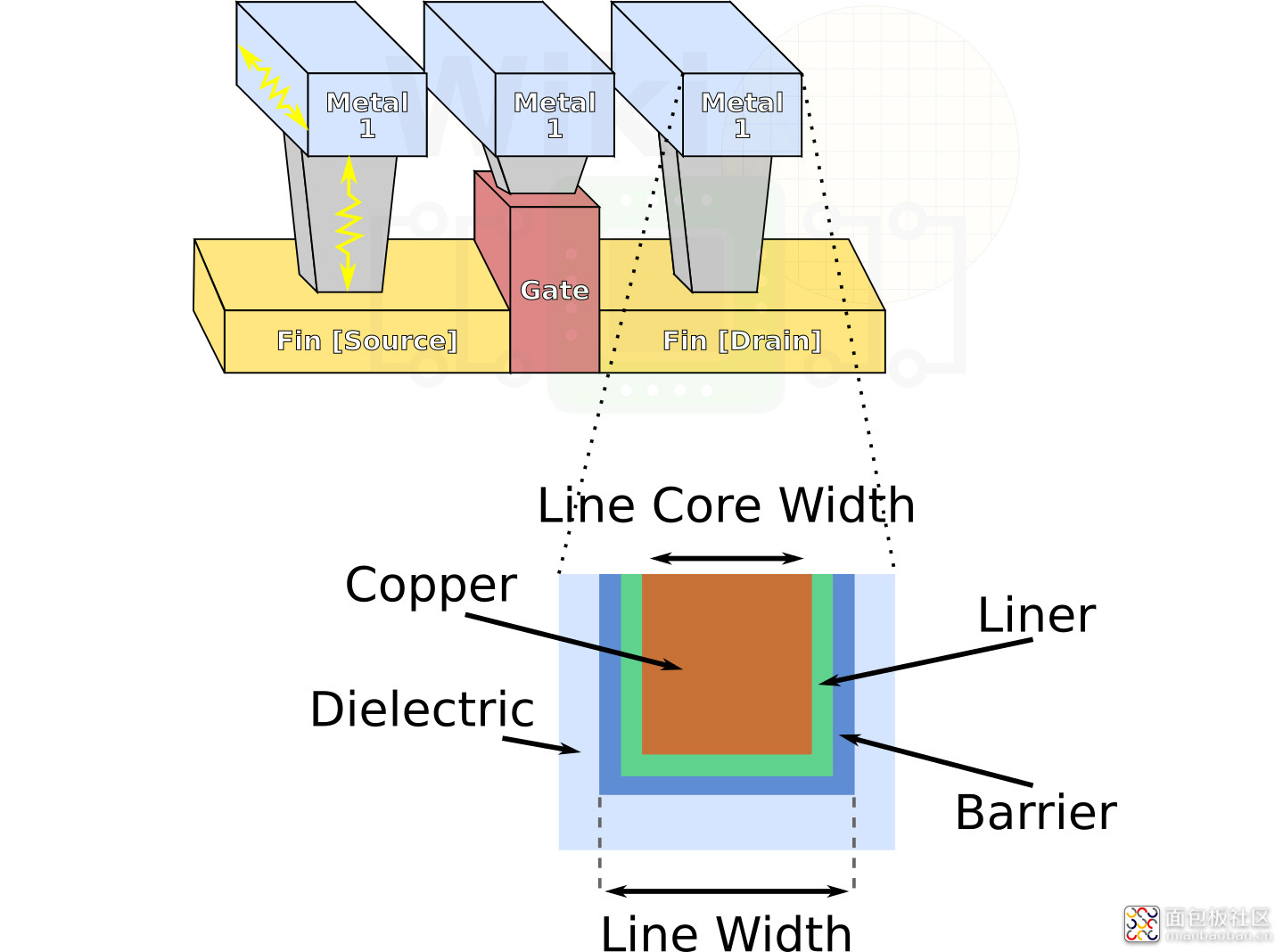
阻隔层的材料可能是硅/钽氮化物。阻隔层用于阻止金属扩散到电介质;衬垫则可理解为将扩展阻隔层和铜“粘合”起来。
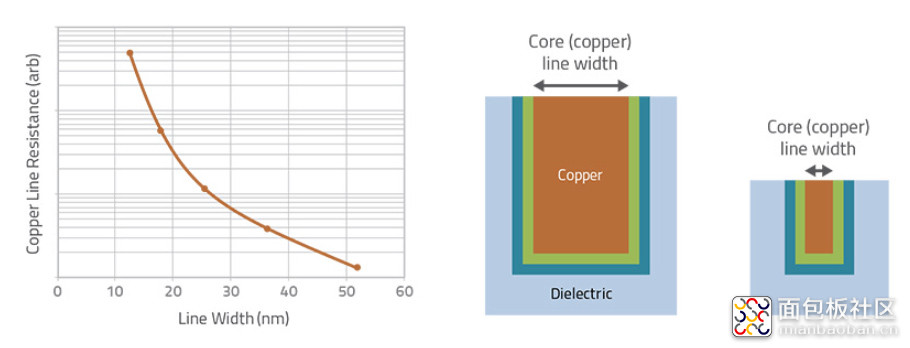
当铜线宽度确定后,其中一部分是需要被 barrier 与 liner 占据的,也就是说实际铜的截面更小。随着导线的进一步缩小,高电阻率的 liner 和 barrier 基本保持不变(因为要令其厚度变低非常难),则铜的截面积就要变得更更小,而 barrier 层则逐渐占据 interconnect 越来越大的部分,甚至极大影响导线的电阻率。那么铜线在传递信号时,就成为当代处理器的一大瓶颈。
来源:Lam Research via Semiconductor Engineering[6]
Lam Research 先前呈现的数据如上图,线宽越小,铜线电阻也就随之飙升。
于是钴成为多方面比铜更能胜任的材料。虽然钴的电阻率高 4 倍,但钴的特性决定了阻隔层仅需 1nm(这一点应该是美国应用材料的某种专利技术)。这样一来导线更大一部分可以被钴本身占据。如此,钴导线可以在宽度上做得更小。同时平均自由程也更短,从 40nm 降到少于 10nm,那么电迁移的问题就比较小了。Semiconductor Engineering 报道中,美国应用材料提到:“当(线宽)小于电子平均自由程的时候,材料界面和晶粒边界就会发生很大的(电子)扩散,导致电阻增加。”[6]在 10-15nm 这个线宽区间内,钴自然就有着更低的电阻。
(补充说明:能够把阻隔层做薄,其实与工艺流程也有关。后文还会提到,某些部分的钨材料也会替换成钴。对于钨而言,其最初材料其实是六氟化钨,剥离氟元素是在沉积工艺阶段进行的——为了阻止氟污染 work-function metal 金属,就需要较厚的一层 TiN 氮化钛阻隔层;而美国应用材料在钴填充的工艺流程上有一些专利,可以让阻隔层做得非常薄,所以钴成为一个很好的选择。)
来源:Lam Research via Semiconductor Engineering[6]
不过钴并不会应用到所有金属互联层:当导线宽度足够宽的时候,传统的铜有着更低的电阻率,显然是更合适的方案。Intel 的 10nm 金属堆栈有 13 层,比 14nm 多了一层,比 22nm 多了两层。
对于 M0、M1 这样底层的金属层才会用到钴。Intel 宣称层到层电阻,钴能够达成 2 倍的降低;而在层内部,在电迁移问题上,钴有着 5-10 倍的提升。
实际上,在 7nm 节点阶段没有将铜替换成钴的制造厂,应该还是因为其电阻率本身就比较高的关系——而且他们有各自针对铜的优化方案。Semiconductor Engineering 此前报道说,IBM 先前就表示,对钴互联的评估发现,电阻仍然不理想[5]。Wikichip 则在报道中说,IBM/Globalfoundires 曾提出采用 TaN/Ru 阻隔层或者是 tCoSFB(Through-Cobalt Self Forming Barrier),可以做到最薄的阻隔层,令铜导线在电阻方面,可优于钴和钌[3]。
未来钴的使用可能会越来越往 interconnect 的上层走,或者如 TechInsights 所说,钌可能会占据一席之地[9]。
来源:美国应用材料 via Semiconductor Engineering[6]
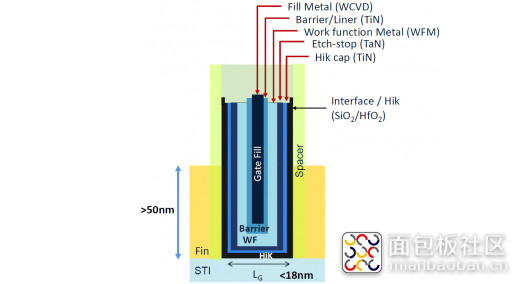
除此之外,钴的应用不仅限于 interconnect 走线部分。从 22nm 开始,除了晶体管和 interconnect 之外,中间还多了个 MOL(middle-of-line)层,是把晶体管与 interconnect 连接起来的部分(如上图)。MOL 主体上包含了上层级和下层级。上层都是一些小的 contact 触点——这些 contact 本身是带空隙的 3D 结构。空隙原本是用钨做填充的(tungsten plug),钨为 interconnect 和晶体管起到了电连接的作用。
随着节点推进,这部分钨以及结构内的材料尺寸也在变小。这会导致接触电阻(contact resistance)问题。所以在 MOL 层,能够最大化导体容量就成为目标了。针对这个问题,美国应用材料曾经开发过一种金属有机化合物钨薄层(metal-organic tungsten film),这层薄层是用来替代阻隔层(和 nucleation layer),这样也就增加了钨的整体量,降低接触电阻。
前面提到 MOL 层还有个下层级,下层有单独的 contact,连接到晶体管之上的接合点(好像包含了前文提到的 gate contact)。这个 contact 内部主要也是钨。在体积缩减的过程里,会产生“肖特基势垒(Schottky barrier)”,也就是电阻增加。解决方案就是把钨换成钴。不过在具体填充工艺上,对制造成本实际上也是有影响的。
这里就不深入了,有关这部分其实我查了挺多资料的,某些看不懂。钴对钨的替换问题,除了前文提到的两个,有一些部分我并不是很确定,可能还包括了 gate 本身的填充——这个问题会更为复杂,从 Wikichip 文章的表达来看,Intel 10nm 的 gate 仍然用了钨。
关于 gate 部分的材料替换,来源:美国应用材料 via Electronic Engineering Journal[8]
不过总的来说,无论是用钴替换 interconnect 的铜,还是替换 MOL 层 contact 核心部分的钨,或者替换 fin 与凹槽接触区域的钨(Wikichip 还在文章中提到,Intel 在贯穿 M2-M5 的披覆层(cladding layer)也用了钴),其本质都是在工艺节点逐渐变小,整个集成电路各部分都变小的过程中,铜、钨这些材料,因为某些原因体积变得过小(可能与各种蚀刻、沉积的工艺流程相关,包括阻隔层太厚,挤占了铜、钨这些材料本身的空间),因此电阻增大。
因此将这些材料换成钴,钴能够以更大的体积存在于整个芯片上,对各部分接触电阻、这电阻那电阻的缩减都有价值。虽然像前文提到的那样,可能铜的解决方案本身还是有深挖掘的价值。
供电的变化
就标准单元(Std Cell)的设计,供电通常是由 EDA 工具去搞定的,这肯定是比手动布置要快多了。但在晶体管密度提升的情况下,Intel 就需要和 EDA 工具提供商合作,将电力输送应用到 block 级别,以及不同的单元排列。这其中要应用不少优化方案。
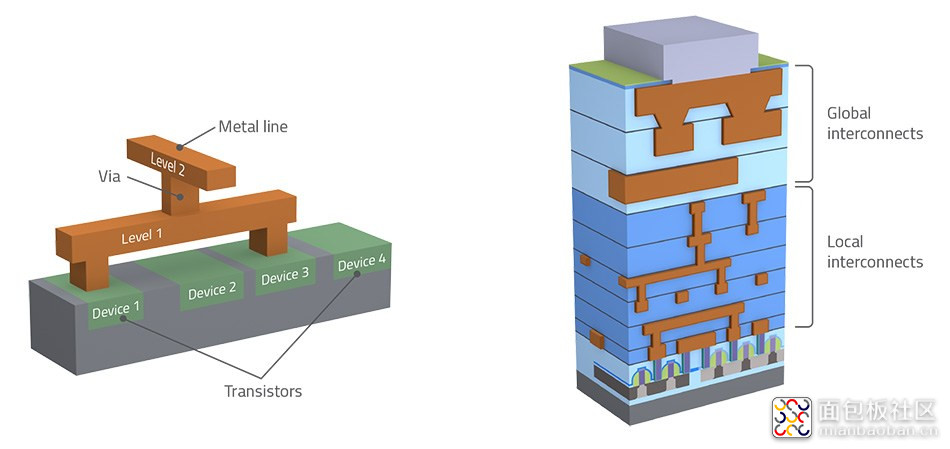
一枚常规的芯片,前文就提到了,用于传送数据和电力的叫 interconnect 互联层或者金属层。这些金属层就被称作 metallization stack,并且构成了 BEOL(back-end of line)的一部分,这些是可以独立于晶体管设计之外的。
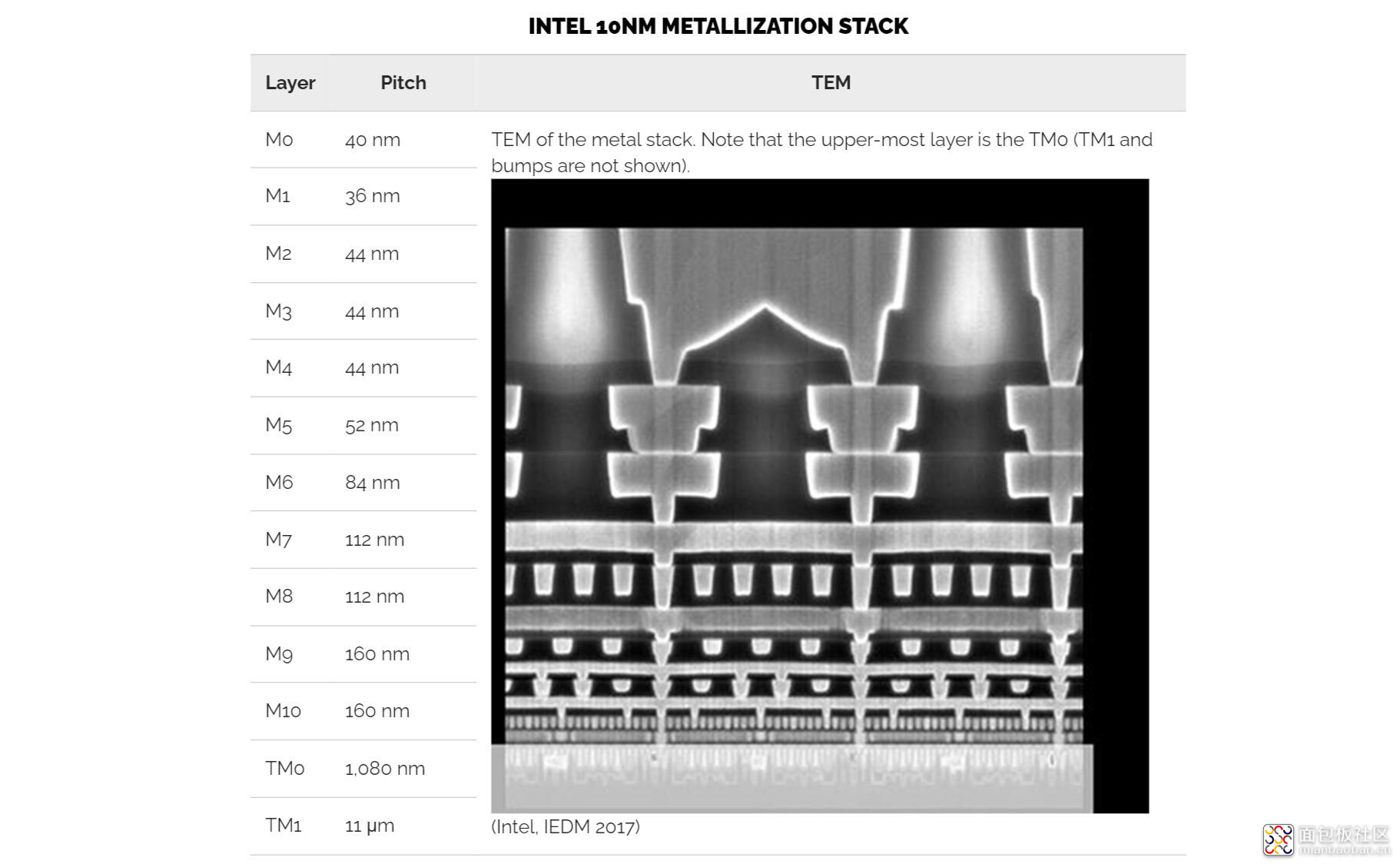
Intel 的 10nm 金属堆栈有 13 层,比 14nm 多了一层,比 22nm 多了两层。Intel 的金属堆叠官方设计规格如下:
最底下的两个金属层用到了四重曝光;M2-M5,以及 gate,则采用双重曝光即可,来源:Wikichip[2]
其中钴(Cobalt)材料,用 Wikichip 的话来说,是一种 barrier-less 的导体。它不需要用到像铜那么厚的 barrier 阻隔层——这一点在前文其实已经提到过了。
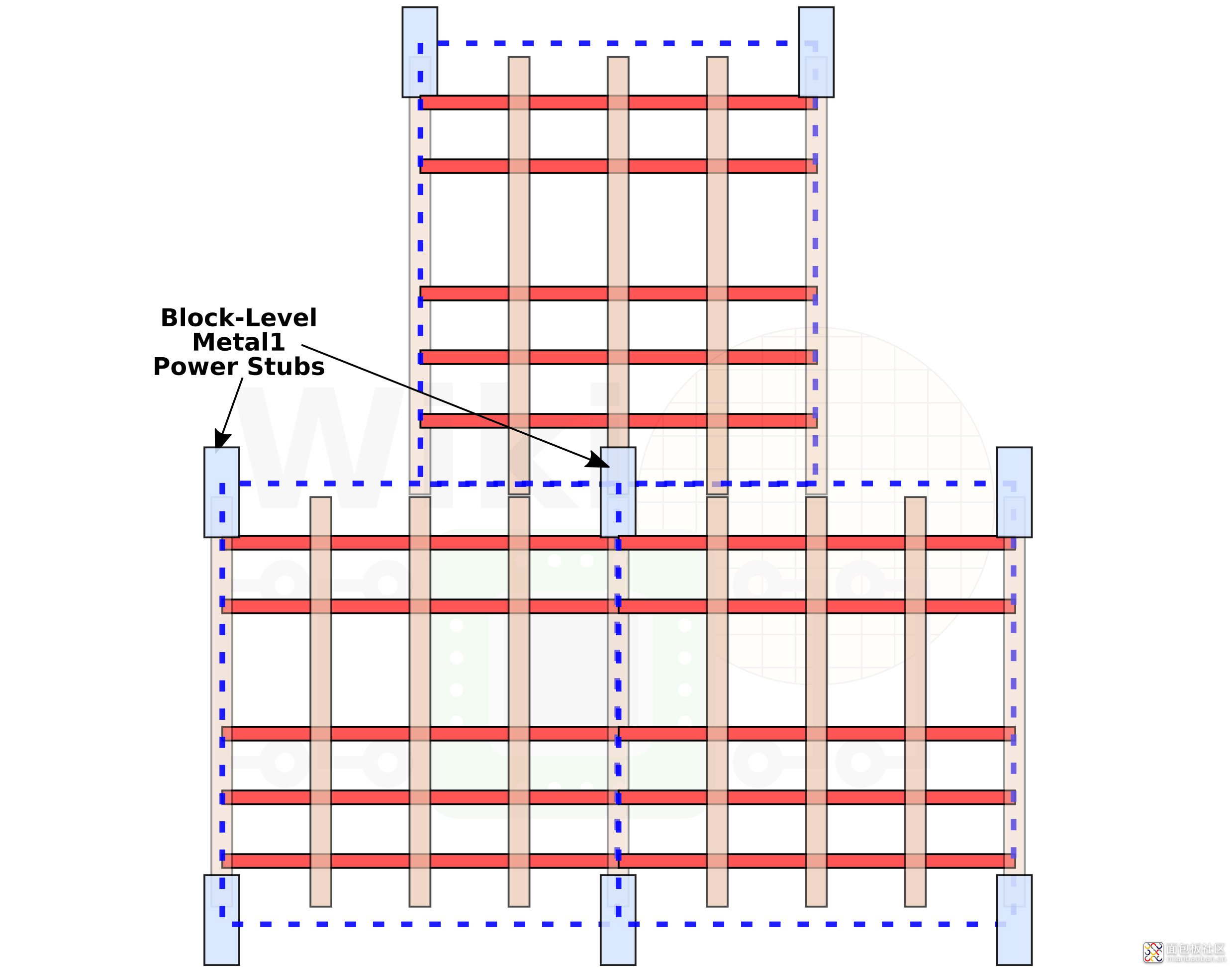
在每一层布局金属线,与打造 fin 和沟槽什么的还是不一样的。以正确的方式接合这些金属电线在设计上自然也很重要。每个单元的电桩(power stub)通常在角落位置,通过 Metal 1 层,把单元连接到 Metal 2 层。所以电桩原本是与单元处在同一个级别的,也就是所谓的 cell level 。Intel 对此作了变动,通过分辨共同的单元组,将其放到最佳位置,也就把电桩从 cell level 上升到了 block level。
来源:Wikichip[3]
通过手动布线来完成这个方案当然是可以的,但那就太浪费时间了。Intel 在这个问题上选择了与 EDA 工具制造商合作,开发所谓“block aware”的自动化,所以这个过程就能完全在工具中完成了。这个方案也能够让 Metal 1 层变得更稀疏一些,也能够提升单元层级的密度。
要实现这种方案,单元的 gate pitch 和 Metal 1 layer pitch 就需要相应地对齐。从上面的那张表来看,gate pitch(CPP)是 54nm,M1 pitch 仅 36nm,这两者是不相等的。不过这两者是 3:2 的比例。虽然仍然可能存在对不齐的情况,但这是发生在 block level 层级的。EDA 工具就需要解决这样的问题,通常是通过增加间隔的方式,但这样也会相应的降低密度。
Intel 的解决方案是针对整个单元库,产出两种格式,一种是未对齐触点的单元,还有一种是对齐了触点的单元。如果 EDA 工具能够理解这两种不同单元的存在,就能根据不同的位置来安排单元库,也就能够尽可能降低对密度的影响了。所以在这个过程里,“alignment aware”(具有对齐意识)这一特性就显得很重要。Intel 宣称这套方案能够达成 5-10% 的密度提升。
这种方案预期在 Intel 所有的产品上都会有所应用。这部分 Wikichip 还有更详细的介绍,可参见参考来源[3]。
在 Intel 最初的预期中,10nm 和 10nm+ 工艺晶体管性能会弱于 14nm++。Cannon Lake 就是初代 10nm 工艺了,而理论上 Ice Lake 应用的就是 10nm+ 工艺——基本也符合预期。十代酷睿处理器产品的两个系列,还在应用 14nm 的 Comet Lake,和已经应用了 10nm 的 Ice Lake,显然是前者性能更好(虽然在低压处理器上,Ice Lake 配备了图形性能明显更好的核显)。
前不久 Intel 刚刚发布的 Tiger Lake 应用的实际上就是 10nm++ 工艺,不过 Intel 已经将其更名为 10nm SuperFin 了。从 Tiger Lake 已经发布 CPU 产品的最高主频来看,10nm SuperFin 实际上在性能上也的确达到了预期,所以 Tiger Lake-U 的频率已经明显比 Ice Lake 高,且全面超越了 Comet Lake。可以认为 10nm SuperFin 是 Intel 真正成熟的 10nm 工艺。
不过这部分我们就放到下篇去说吧,感觉这篇文章的长度有点过长了——突然又觉得,就当代成熟的10nm来看,下篇大概才更有价值吧,这个上篇就算是个历史回顾了。下篇如果有可能的话,我会尝试针对 Intel 的 10nm SuperFin 工艺与台积电、三星的 7nm 乃至 5nm 工艺,在某些维度上做比较。不过鉴于 9 月非常忙碌,所以下篇产出的时间未定。
再次说明,本文的主体资料来自 AnandTech、Wikichip、Semiconductor Engineering,以及 Solid State Technology 和 TechInsights,参考文章链接在文末。这些资料,浓缩了诸多专家、编辑的心血,我在这里只扮演翻译、学习,并且部分注释的角色。
个人不参与生产,对国外这些文献的理解,也是基于此前自己的积累。其中有一些知识盲区,所以文章难免存在错误。贻笑大方之处还请各位见谅和指正。
参考来源:















DrouSherry 2020-11-25 18:04
xuewen_ran 2020-9-11 11:01
pidaneng 2020-9-11 08:42
欧阳洋葱 2020-9-9 12:21
用户3905076 2020-9-9 10:47
intel001 2020-9-8 10:33