写在前面:很久没更专栏了,其实近期有太多东西值得去细细谈了,但工作忙始终没时间。这篇文章算是此前一些发布学习内容的总结,也加入了很多新的内容——正好也是跟一跟 vivo X60 发布的热点。虽然整体上算是个“云”评论,而且都是公开的 IP 信息,但对于技术爱好者一定是有价值的,希望爱好手机 SoC 技术的各位同学喜欢。也算是自我学习的一个过程,内容分享给各位。
上个月参加完 Exynos 1080 芯片的发布会,我就提过,Exynos 1080 可能将会是在2021年的甜品级终端产品比较长寿的一颗芯片。就其纸面数字,以及定位特点来看,2021 年中高端定位手机产品,大约也会迎来一次性能飞跃。
所谓的纸面数字,可列举的是三星电子系统 LSI(以下简称三星或三星 SLSI)官方给的数字, Exynos 1080 的 CPU 单核性能提升 50%,多核性能提升 100%(基于 Geekbench 5 测试);GPU 性能提升 130%(基于 Manhattan V.3 测试数据)等。这个提升程度在如今两代同档定位产品的升级间,应该说是相当大的。其“提升”的对比对象是 Exynos 980。有关这颗芯片是否真的达成了这种提升,下文再谈。
需明确的是,Exynos 1080 并不是最顶级旗舰的定位,未来三星应该还会推出一颗 Exynos 2100 芯片(当然也可能是 Exynos 1888……)。但从配置来看,Exynos 1080 在定位上明显高于前代 Exynos 980。理论上,Exynos 1080 的同档竞争对手应该是骁龙 765G 和麒麟 820,甚至和一部分骁龙865的新品有一战之力,当然很快高通还会推更新款的中高端定位 SoC(骁龙 777???)。也因此 Exynos 1080 极有可能拉高 2021 年这块市场的竞争水平。
就在这几天,vivo 正式官宣了 X60 系列将搭载 Exynos 1080。其实 vivo 作为这颗芯片的首发品牌也并不让人意外,毕竟三星 S.LSI 在发布会上就提到了这一点。而且和去年的 Exynos 980 一样,vivo 也参与了 Exynos 1080 的研发,这也是三星在芯片发布会上反复强调的一件事。
与此同时,Exynos 1080 未来甚至可能还会出现在更多的国产手机上,11 月初 BusinessKorea 就报道了三星 SLSI 计划在 2021 年向更多中国智能手机制造商提供 Exynos 芯片的传言。实则从甜品级的配置来看,如果三星/vivo 在设计和制造上实施得宜,则 Exynos 1080 极有可能成为很长寿且受欢迎的一颗中高端手机芯片。
那么本文,我就尝试来剖析 Exynos 1080 这颗芯片本身(包括主要的几个 IP,以及三星 Foundry 的 5nm 工艺),并谈一谈三星和 vivo 之间所谓的“联合”研发,究竟“联合”了些什么。毕竟 vivo 在此作为终端制造商,与上游供应商做联合研发,一方面是其开发实力的体现,另一方面也是差异化竞争的依据——我对此也一直非常好奇。
本文分成 6 大部分,分别是
(1)Exynos 1080 概览;
(2)CPU 部分;
(3)GPU 部分;
(4)NPU、ISP 等其他 IP;
(5)三星与 vivo 合作了什么;
(6)三星 5nm 工艺是什么。
文章篇幅较长,各位同学可以根据自己的喜好,选择性阅读。
Exynos 1080 配置概览
此类常规的媒体发布会,三星透露的技术细节通常都比较少,主要就局限在芯片的配置和特色 IP 上。vivo 方面给出的信息是,针对 Exynos 1080,vivo 从 2019 年 6 月起,提前 18 个月投入超过 50 人的技术专家团队,与三星共同定义配置,包括选用 5nm EUV FinFET 工艺、最新 Cortex-A78 CPU 及 Mali-G78 GPU,制定 RGB scaler(RGB 色彩标准化)、加入 CLAHE 影像算法等。
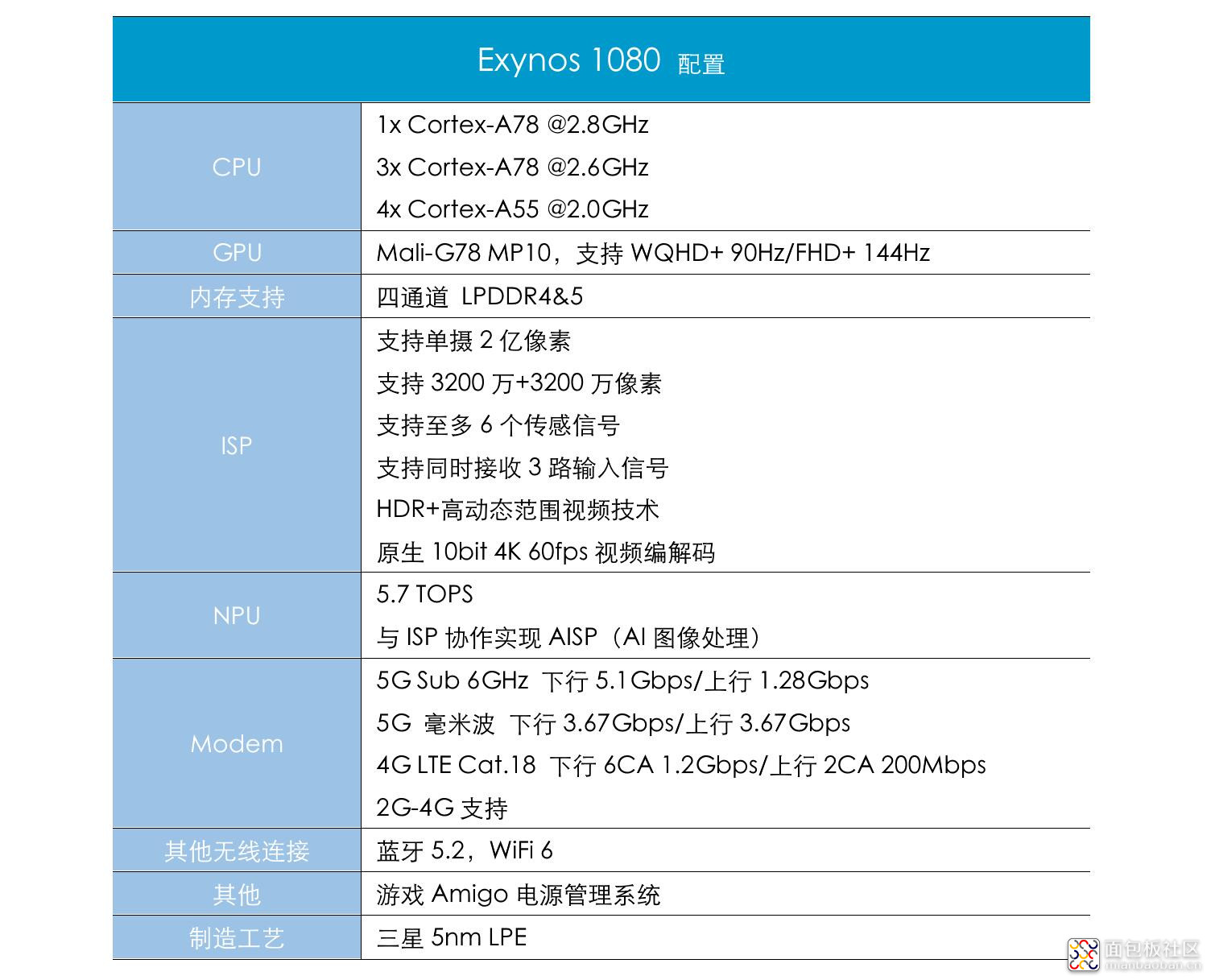
芯片 18 个月的开发周期算是 IC 设计的日常了,有关 vivo 在此间的合作,后面的段落将会展开。首先罗列 Exynos 1080 的配置如下表:
这其中的一些亮点包括,制造方面在选择了三星 Foundry 的 5nm工艺(5LPE),这部分将在后面的段落中详述。实际上,三星 Foundry 自 7nm 开始,就与台积电在工艺路线上有了较大的差异,5nm 也体现了这种差异。(下文将把三星电子系统 LSI 与三星 Foundry 统称为三星,不做区分)
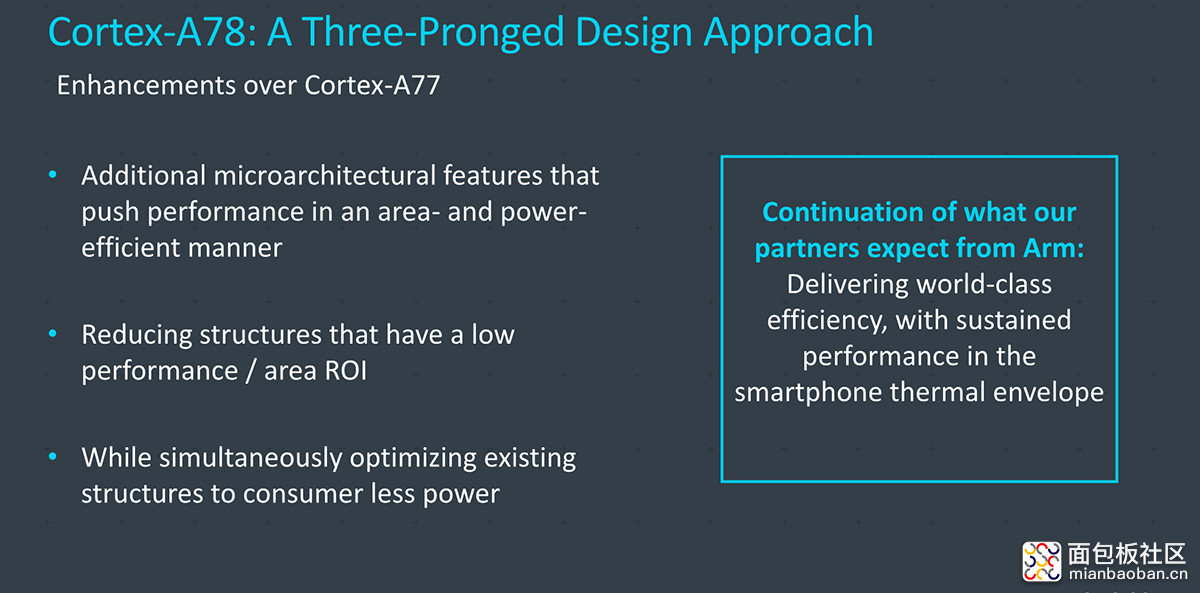
设计 IP 相关的部分,这颗芯片的 CPU 核心为 1+3+4 搭配——这应该是 Exynos 系列芯片首次采用这种搭配方法,这原本就是 DynamIQ 的灵活性体现。且其中的“1+3”都采用 Arm Cortex-A78 大核,其中最大的那颗核心频率最高 2.8GHz——这个频率算不上高,与 Exynos 1080 的定位相符;随 Arm v8.2 指令集一同到来的小核心自然就是 Cortex-A55 了。
GPU 部分也选择了 Arm 最新的 Mali-G78,10 月份海思发布的麒麟 9000 也用上了这个GPU IP。不过由于定位上的差异,Exynos 1080 的 Mali-G78 是 10 核心配置,核心数量规模实则不到麒麟 9000 的一半,频率未知。不过麒麟 9000 为 Mali-G78 MP24 核心的“顶配”,可能本身也并不见得有多合理(尤其在峰值性能下的效率表现上)。
三星在发布会上也提到,Exynos 1080 的“GPU性能相比上代提升 130%,是上代的 2.3 倍之多”(基于 Manhattan V.3 测试数据)。有关这一点下文还将做详述。
有关 Exynos 1080 的 AI 专核,三星官网给出的数据是算力 5.7TOPS——这是在 Exynos 1080 产品定位上,相对甜品级的性能数字;作为参照,定位更高端的 Exynos 990 这个数字是10TOPS,竞品骁龙 765G 的 AI 算力为 5.5TOPS。Exynos SoC 在 AI inference方面的部署似乎一直比较神秘,从此前为数不多的介绍来看,主要是 NPU+DSP 的异构计算。这既不像 Arm 官方的 Ethos NPU;也不像高通那种单纯加强 DSP 的 tensor core,外加各种核心异构计算的 AI Engine;而且从此前 AnandTech 针对 Exynos 990 的测试来看,三星面向 NNAPI 似乎也并未完全开放NPU的算力。
这颗芯片的其他亮点还包括:(1)集成 modem 的 5G 支持,包括 Exynos 980 没有的毫米波的支持,且最高下行速率推升到了 5.1Gbps;(2)全高清+分辨率搭配 144Hz 刷新率的支持,也是为游戏手机做配的体现;(3)AISP,实际上也就是在成像数据的后处理上,除了 ISP 之外,也加入了 AI 专核的干预,以 AI 来进一步提升成像质量——这一点,也是当代手机 SoC 厂商的主旋律。
从明面上能看到 Exynos 1080 相较前代的一个缺失应该是 MFC 编解码能力,失去了对 4K 120fps 的支持。接下来我就尝试针对其中的一些细节,做更深入的“云”剖析。鉴于三星和 vivo 公开的信息有限,我也只能从公开的 IP 资料来谈谈这颗芯片——借此机会,也算是为爱好者们准备开拓视野的内容了。
CPU:着力效率调优的Cortex-A78
10 月份发布的旗舰定位的麒麟 9000 比较遗憾的一点就是未能采用 Arm Cortex-A78 和 Cortex-X1。这让其在对阵 2021 年的中高端芯片时,可能都会有些力不从心——比较典型的就是 Exynos 1080。
Exynos 1080 应该会是首颗将 Cortex-A78 实体化的手机芯片。三星在发布会上提到,基于 Geekbench 5 的测试,Exynos 1080 的 CPU 单核性能与多核性能分别有 50% 和 100% 的提升。
从网上的公开数据来看,基于 Exynos 980(vivo S6 5G)的 Geekbench 5 测试成绩(单核 695,多核 1850)[1],如果抛开系统设计层面的影响不谈,若三星公开的这一成绩属实,则 Exynos 1080 的 CPU 性能是妥妥地超过了骁龙 865 的(与麒麟 9000 基本持平)。隔代的两个定位的芯片之间,做到性能赶超也并不多见。
不过 Exynos 980->1080 的性能跃升多少也在意料之中,一方面是 Exynos 1080 的 CPU 最高频率相比 980 提升了27%,加上大核心 IP 从 Cortex-A77 升级到 A78,以及制造工艺从 8LPP 升级至 5LPE,多重因素促成单核 50% 提升也并不奇怪;至于多核,Exynos 1080 的 A78 核心实际上有 4 个,比前代的 2 个 A77 大核就明显有多核性能上的优势了。
所以我才说,感觉 Exynos 1080 在定位上相比 Exynos 980 是明显拔高了的——或者说三星和 vivo 有将中高端定位手机 SoC 提升竞争水平的决心。所以 2021 年高通和联发科这些竞争对手预备推的同档产品,会采用什么样的配置会显得十分关键。
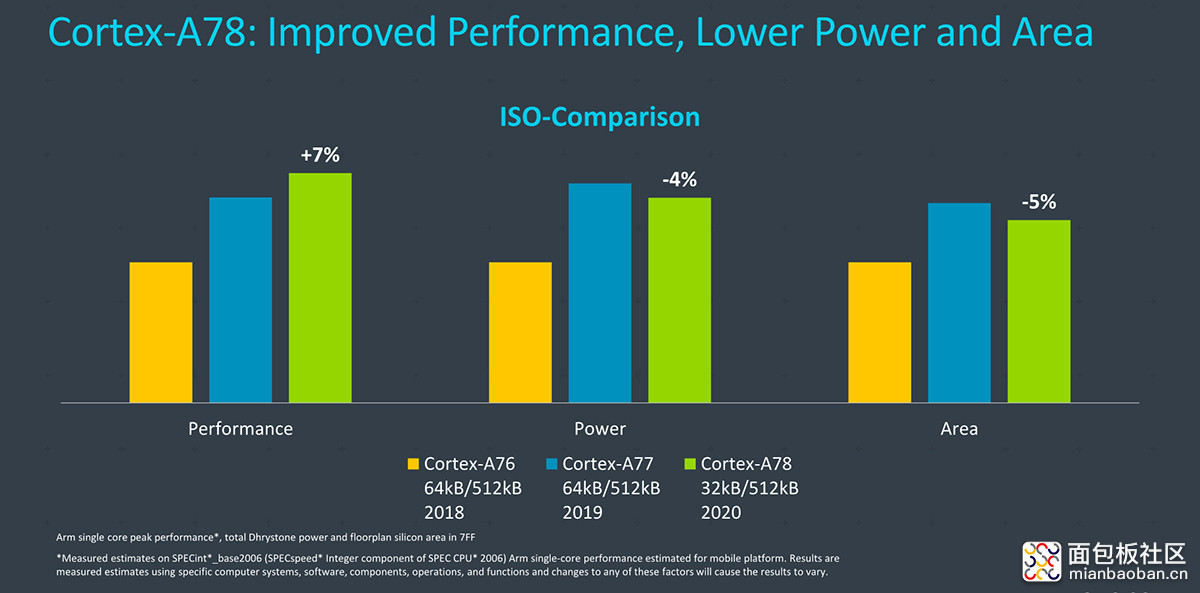
微架构 Cortex-A78 是 Austin 家族的第三代产品。事实上,A78 相比 A77 的 IPC 提升应该算是比较普通的水平。Arm 此前发布这代 IP 时提到,单核心在 1W 功耗下,A78(3.0GHz,N5 工艺)会比 A77(2.6GHz,N7 工艺)提升 20% 的性能。若以相同性能为前提,则 A78(2.1GHz,N5 工艺)功耗是 A77(2.3GHz,N7 工艺)的一半。
这组对比的变量实在是有点多了,而且 Arm 是以台积电 N5 和 N7 工艺作为参照的。实际上,如果以相同制造工艺为前提,且核心配置相同的情况下,A78 相比 A77 大约有 7% 的性能提升,另外有 4% 的功耗红利和 5% 的占 die 面积红利。那么结合 Exynos 1080 相比前代 27% 的频率提升,Exynos 1080 收获来自三星 5LPE 工艺的性能红利似乎相当可观——这一点也完全合理,毕竟此处对比的是 8LPP 和 5LPE。
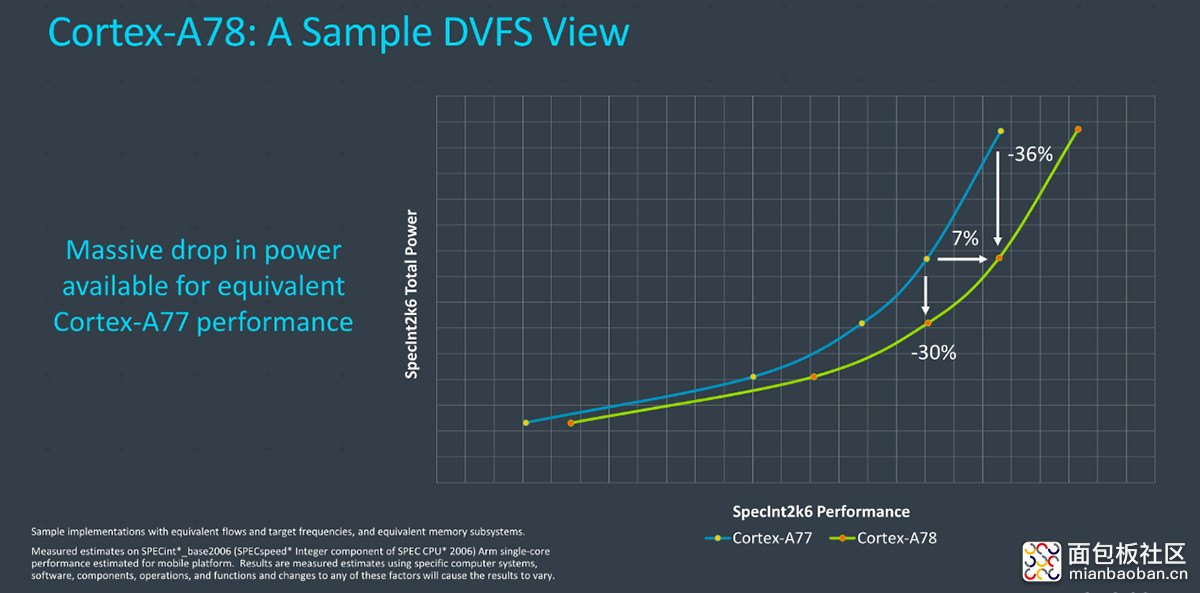
在功耗方面,Arm的数字是,在 A77 与 A78 达到相同性能(A77 的峰值性能)水平下,A78 功耗可降低至多 36%;同功耗水平下,A78 的性能优势在全区间内最多是 7% 左右。不过 Exynos 1080 比 980 提频了这么多,其实际的峰值功耗和效率水平还是待实测的。
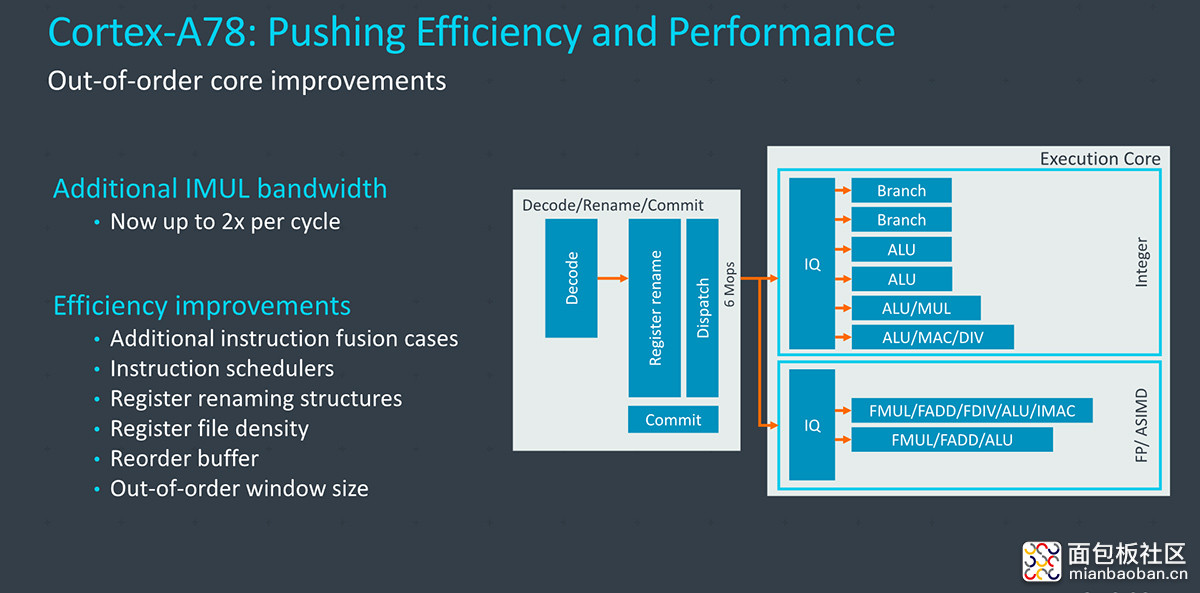
这里再简单谈一谈 Cortex-A78 微架构本身的一些调整。A76 和 A77 实则已经在核心的宽度、OoO 能力和频率方面做了提升。A78 属于典型的优化型 IP;相比 A77 主要是面积、功耗及效率上的改进。前端、执行及存储系统都有对应的结构和尺寸缩减,主要是针对原本设计中,收益并不高的结构做缩减(典型的比如 L1I 指令缓存开始提供 32KB 的选择,也就是 IC 设计厂商可以将其做得更小——前面提到的性能、功耗对比都是基于 32KB 的 L1I),做到效率上的优化。
A78 前端最大的变化是分支预测器,除了精度提升外,能够处理至多每周期 2 个分支,也就提升了吞吐,能够更好地从错误预测中恢复。而且去年的 A77 后端多出第二个分支执行单元,A78 则在前端做了平衡。分支预测器部分结构做了精简,提升面积和功耗方面的表现。
执行核心的发射队列(Issue Queue)其实是有比较大的变化的,只不过 Arm 此前并未详述变化细节,只提到此间变化能够带来功耗效率方面的提升。寄存器重命名结构和寄存器堆也做了优化,部分有尺寸上的缩减,寄存器堆在相同的芯片面积内可以容纳更多的数据,这对整体结构的面积缩减也就有帮助。ROB(re-order buffer,乱序执行的重排序缓冲)尺寸不变,但效率和指令密度也都有了提升。
每周期 Mop(Macro-ops)的 dispatch 似有拓宽。执行单元部分,唯一较大的变化是,A78 在一条简单 ALU 管线中,增加了第二个整数乘法单元,每周期的整数乘法吞吐就获得了提升。执行单元其余部分变化比较小。
存储子系统部分,多加一个 load AGU(地址生成单元),load 带宽提升 50%。Load/store 队列到 L1D 数据缓存的带宽翻倍至每周期 32 bytes,核心到 L2 缓存的读写带宽也翻倍;prefetcher(预取器)在存储面积、精度和时机表现上都有加强;还有前文提到的L1I 指令缓存现可选更小的 32KB;L2 TLB(translation lookaside buffer)缩减至 1024 pages,算是典型的效率优化。
其实就这些微架构调优来看,这一代 Arm CPU 核的性能重任应该的确是落在了 X1 身上的。不过也因此,Exynos 1080 CPU 部分的效率预计会不错。
GPU:130% 性能提升?
三星在发布会上提到,Exynos 1080 的图形算力较前代提升 130%,也就是前代的 2.3 倍。这个数字初听还是挺恐怖的——半导体行业很少存在隔代产品这种幅度的性能提升。不过 Exynos 980 的图形计算基础实际上也的确不算高,具体为 Mali-G76 MP5,即 5 核心的 G76。G76 属于 Bifrost 架构的末代产品,G77 换用了 Valhall 新架构。
而 Mali-G78 属于 Valhall 的二代产品,从 Arm 公布的结构调整来看也属于小改款。不过 Exynos 1080 的 GPU 配置为 Mali-G78 MP10,即核心数量相比前代翻了一倍。加上架构迭代,以及新工艺加持,130% 的图形算力提升似乎也的确不算什么。
Arm Mali 阵营曾在 G76 时代掀起过一阵效率追上隔壁 Adreno 的宣传热潮。Mali G76 实际上也的确在性能和效率(特指能效,而非面积效率)方面,表现出即将与 Adreno 640 齐头并进的意思。不过高通在 Adreno 650 身上小小发挥了一把,而 Mali G77 在具体实施上似乎并没有一款真正具有代表性的芯片产品,所以 Adreno 仍然还是那个 Adreno。
个人倒是觉得,从麒麟 9000 采用 Arm 推荐的满载 24 核心 Mali-G78 实际表现来看,Mali GPU 的确能够在性能上通过堆料来达成与 Adreno 的同等水平,但峰值性能下的效率却差了一大截。所以缩小规模,找性能与功耗的甜蜜点,才是 Mali 这两代产品真正比较合理的选择。Exynos 1080 的 Mali-G78 MP10 也因此应该不会在效率方面有崩坏的情况发生;不过其图形性能预计也就是中高端定位水准。而且这种配置,应该也是为 Exynos 2100 预留空间。
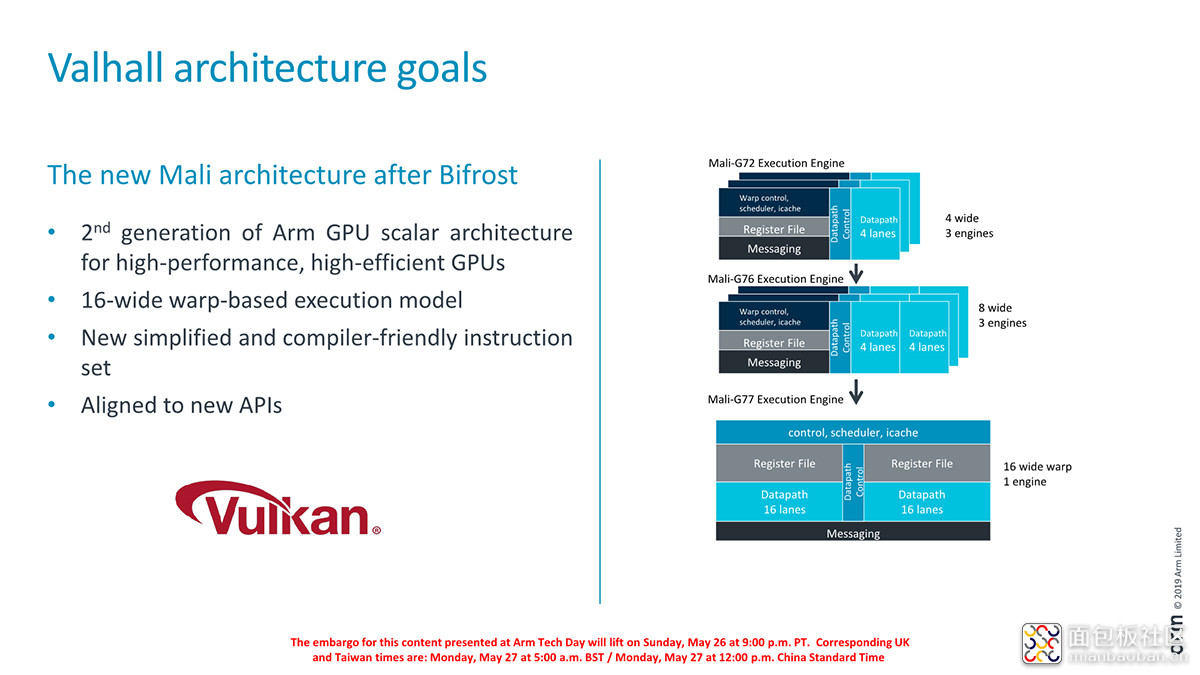
Valhall 架构初代的 Mali-G77 相比前代,在相同性能与工艺的前提下,有 30% 的能效与密度提升。除了 ISA 本身的变化让指令对 compiler 更友好,也更适用于 Vulkan 这样的 API,在架构层面,它相比 Bifrost 有几个比较大的变化,其一是拓宽到 16-wide warp 执行——虽然这个宽度还是和苹果、高通、Imagination 这类走宽核心、少核心路线的 GPU 不能比,但自 Bifrost 的 G71 开始就已经是数次成倍拓宽了。
Arm 一直以来都在走这种窄核心、小 warp size、多核心的路线,应该主要是为了减少 ALU 的闲置时间,获得更高的 ALU 利用率。不过当代图形负载在计算方面正变得越来越复杂,很容易实现多个线程的并发,并利用好更宽的 warp size。(而且这也很大程度上,是 Mali GPU 占 die 面积明显较大的原因)
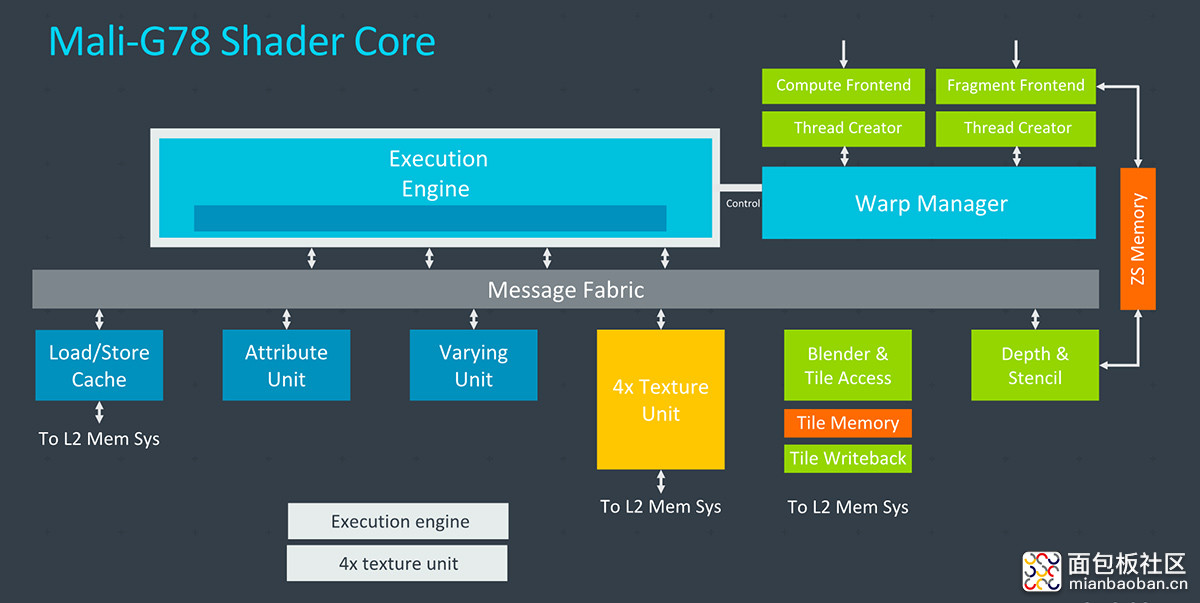
在具体的执行引擎方面,早前的 Bifrost 核心采用 3 个执行引擎的设计,每个都有独立的数据路径控制逻辑、独立的 scheduler 和指令缓存、寄存器堆以及 messaging blocks。Valhall 把几个小的执行引擎合并成一个单独的更大的模块,采用共享的控制逻辑。不过 ALU 管线在此仍然分成了两大块,每个都有单独的 16-wide FMA(融合乘加)单元和相应的执行引擎。
除了执行引擎,shader 核心中的另一个变化是 TMU(纹理贴图单元)吞吐翻番(每周期过滤 4 个纹素,渲染输出 2 个像素)。由于篇幅关系,本文不再介绍 Valhall 架构的更多变化,这里还是回到 Mali G78 本身,相比前代 G77 的一些改进。
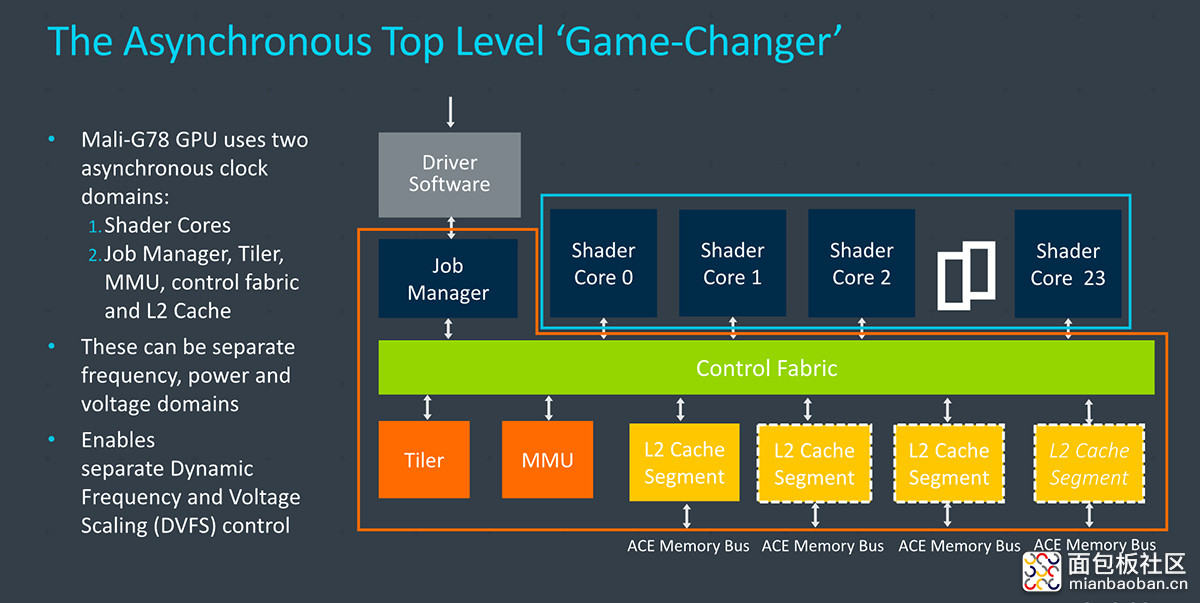
如前文所述,G78 是 Valhall 架构的第二代产品,属于针对 G77 的改款。其执行核心部分和 G77 相比变化不大。最大的变化应该在于,原本整个 GPU 的全局频域(frequency domain)变为两层结构,shader 核心本身是个单独的频域,顶层的各种共享 GPU 模块为一个频域。这样一来 GPU 内部可以有不同步的时钟域,shader 核心可以跑在不同的频率下。
这不失为一种节能和提高效率的方案。以前要在屏幕上显示更多数量的多边形时,只能全面推高 GPU 的运行频率。当代的游戏作品普遍是几何处理工作偏重的,将 tiler 和几何引擎运行频率解耦,能够解决吞吐不平衡的问题。不过这么做需要增加额外的电压域实施,增加了系统成本。另外,这个分层频域设计应该也是可选的,不知三星和 vivo 是否为 Exynos 1080 增加了这个设计。
除此之外,G78 的 FMA 引擎有变化,主要是 FP32 与 FP16 路径做了隔离;tiler 吞吐提升;shader 核心缓存更好的复用和关联性追踪,核心就能更智能地处理缓存数据,避免不必要的数据移动,最终减少带宽需求和功耗。
其中的很多方案普遍是以额外的面积,来换取能效。
最后,针对 Mali-G78,Arm 官方给出的最高 shader 核心数配置是 24 个,听起来还真的是比较疯狂——要知道 Adreno 才 2-3 个核心。因为其实前面几代产品,Arm 似有将核心持续拓宽、做大的意思,以提升每核性能。比如 G77 一个核心其实差不多就相当于两个 G76 核心的规模。Mali-G78 的这种配置变化看起来还真是有些令人摸不着头脑。
Arm 此前宣称,在同工艺前提下,Mali-G78 的性能密度提升 15%(即同面积下,较前代有 15% 的性能提升;或者相同性能下,缩减 15% 的面积),能效提升 10%。在 GPU 实施规模有成倍差距的情况下,Exynos 1080 的图形算力比 980 提升 130% 也就很合理了。
这个 130% 的提升数据,三星此前在发布会上标注时提到基于“Manhattan V.3”测试,那就默认是 3.0 离屏渲染测试好了。此前有记录的 Exynos 980(vivo S6)的 Manhattan 3.0 离屏渲染测试得分大约在 51fps 的水平上[1]。提升 130% 也就是 117fps,这个成绩是优于骁龙 855 的 Adreno 640 和 Kirin 990 的 Mali-G76 MP16 的(也能够看出 Valhall 架构本身的提升),也远高于骁龙 765G。
当然这只是一个项目的对比,Manhattan 是更偏 ALU 计算的负载测试。不过这个成绩,对于应付市面上现有的绝大部分 3D 游戏应该是不成问题的——当然前提是手机的系统设计也需要合理,以及我暂时还不知道 Mali-G78 在这种规模的实施方案中,持续性能是否可坚挺。如此,FHD+ @144Hz 的支持也才有意义。
所以实际上,基于 Exynos 1080 在 CPU 和 GPU 方面的提升,我才觉得 2021 年的中高端手机市场竞争可能会更激烈。而 Exynos 1080 的实际定位,可能更偏高端(次旗舰),可能不会下放到“那么”中端的市场。
在 Exynos 1080 的图形计算方面,最后一点值得一提的是 Amigo 电源管理方案。此前三星SLSI 在发布会上提到,这是一种面向游戏的节电解决方案,能够实时监控各流程电源消耗情况,优化游戏过程中的总功耗,令电源效率提升 10%。
此方案所处层级未知——如果这是更偏系统层级的解决方案,那么这项技术可能就是 vivo 和三星共同合作完成的。比如像此前知名的 GPU Turbo 那样,在应用和 GPU 驱动之间有个监听层,来监听渲染调用——令其作为神经网络模型的 input,针对特定游戏、特定设备就有了优化过的 DVFS 设定;不过这也可能是更简单的 reactive DVFS 控制。
NPU、ISP 等其他 IP
当代手机主 SoC,在 CPU 和 GPU 之外的其他专用处理器或者 IP 其实也正变得越来越重要。无奈的是,其发展并不像 CPU/GPU IP 那样有如此悠久和成熟的历史,所以其内部细节对我们这些普通人而言,也就没那么公开了。比如说三星的 AI 解决方案,是 NPU 和 DSP 共同完成的。还有包括 5G modem 在内,它们更像是一个个黑匣子。
事实上,从很多测试来看,Exynos SoC 的 Mali GPU 也是面向 NNAPI 可见的。三星在自家 AI inference 专属SDK的开发上是比较晚的,我从三星开发者官网看到目前针对 NPU,三星有专门的 Neural SDK[2]。这个 SDK 现在支持 Caffe 和 TensorFlow 框架。
从描述上来看,它实际上也能同时利用各种计算引擎,包括 CPU、GPU,和 NPU 与 DSP。所以就有些难以理解,Exynos 系列所标的 AI 算力,究竟是谁的算力;我暂时也没有研究过三星对于 Android NNAPI 的支持情况。
三星自己列举的一些 Neural SDK 用例包括了 AI 相册、实时自拍对焦、拍摄建议、人像、场景优化等——这都属于计算摄影(Computational Photography)组成部分。从版本更新情况来看,该 SDK 的开发是有待持续完善的。不过就现阶段 AI 在手机设备上的应用场景来说,AI 专核对于用户的价值究竟有多大,可能仍需要打个问号。沉浸式 VR/XR、智能语音助理识别当然是比较典型的应用,另一个比较重要的想必就是计算摄影了。
谈到计算摄影,三星作为第一方,以及与 vivo 的合作下,推了一个 AISP 的概念。我的理解是这个词就是指 AI+ISP。
vivo 的资料提到了 vivo 美国圣地亚哥、深圳、上海、杭州、东莞等地的专家团队与三星专家团队积极沟通,在第一代 Exynos 980 合作的基础之上,通过一年半的时间迭代和升级,在 Exynos 1080 之上导入了全新 ISP 架构(AISP)与 NPU 的接入点,使得 AI 在影像拍照和视频上的使用更加便捷和实时,并进一步升级了智能自动白平衡、自动曝光、降噪等功能。
事实上在 Android 阵营内,谷歌在 PVC(Pixel Visual Core)介入成像 post processing 的过程还是有标杆作用的,谷歌 AI Blog 也列出了不少如何利用机器学习来参与 3A(自动白平衡、自动曝光、自动对焦),以及降噪、防抖,甚至是 HDR 画面实时预览的过程——我的知乎专栏也翻译过其中的部分文章。不过谷歌不具备将一个专用单元集成到主 SoC 的能力,所以 Pixel 设备利用 PVC 进行 AI 摄影的芯片间通讯延迟应该还是有点久的。
三星在发布会上提到 Exynos 1080 通过 NPU,可以做拍摄物体与风景的检测,优化白平衡和曝光。其实用简单的话来概括,以自动白平衡为例,夜间自动白平衡难度较大——通过机器学习的方式,在模型训练过程里,尽可能去喂大量夜间照片的白平衡调整策略,作为输出就能让 NPU 去做 inference 了。不过我不清楚,在整个流程里,ISP 和 NPU 是如何协作的,每个阶段又如何分配。
聊完 NPU,再来谈谈 ISP。Exynos 1080 的 ISP 纸面参数是单路最高 2 亿像素支持,最多可接收 6 路传感器信号,同时可接收 3 路输入信号;视频原生 10bit 色深拍摄,4K 60fps 支持。其下还有一些细节值得一提,比如说 TNR(Temporal Noise Reduction)硬件级时域降噪模块,在 RAW 域上进行降噪处理,提升录制视频的效果。
“vivo 影像专家团队针对视频拍摄中的运动和夜拍等场景,在分析了全系列用户的使用情况和反馈之后,针对夜景和运动视频中的鬼影、噪声、动态范围等极易影响视频效果的维度,在新一代 ISP 的基础之上做出了硬件级的升级和优化,极大提高了视频的成片率。”
也就是说 vivo 是参与了 TNR 降噪模块的优化的。TNR 降噪其实本身并没有什么新奇的,它是相对 Spatial Noise Reduction 而言的,TNR 是对照多帧,基于某些噪声在画面中分布的随机性来降噪的过程——很多视频后期软件中都有类似的功能。手机产品历史上,iPhone 4s 就宣传过摄像头的 TNR,只是可能当年并未达到“硬件级”,算力和算法也都差着辈儿。
AI 降噪的功能示意
当然这其中涉及到复杂的算法,当其层级位于芯片 ISP 之时,效率应该就会高很多了。所以 Exynos 1080 也因此将硬件 TNR 替代超级夜景算法中的降噪处理部分,实现夜景录像同时的 HDR 功能,也就是实时的夜间降噪和 HDR。另外,针对这一点,vivo 作为更高抽象层级的市场参与者,为 TNR 提供支持,的确也是更到位的做法。
另外,在系统层面,vivo 重构了相机框架代码,压缩软件调度时间;针对运动抓拍场景,可以很大程度规避运动拖影、模糊、延迟等问题。所以不同层级参与者的共同协作,对于终端设备拍摄体验优化,应当还是多有好处的。
SoC 之上的其他大型 IP,另值得一提的是 5G modem 相比前代加入了对毫米波的支持,以及最高下行速率提至 5.1Gbps;无线通讯支持主流的蓝牙 5.2 和 WiFi 6;存储控制器对 LPDDR5 做出支持,带宽在 51.2GB/s——这就是旗舰级的配置了,猜测应该是四通道 16bit,3200 MHz 的水平。
vivo 究竟和三星合作了什么?
有关 vivo 与三星联合开发 Exynos 1080 的问题,其实前文已经列举了不少。vivo 这些年都有与上游厂商做“联合开发”的传统,比如说当年与汇顶合作,推屏下指纹解决方案。而与三星SLSI 的合作,则在上代 Exynos 980 就开始了。
去年的沟通会上,vivo 提到 Exynos 980 的原型机就是 vivo X30——这是作为其他品牌 Exynos 980 手机的母版存在的。当时 vivo 派驻了数百人团队,参与 Exynos 980 芯片开发周期,其中包括了对 5G modem,及系统级 RF 系统相关的功能特性的补充,似乎在偏射频前端部分,vivo 给了很多投入。
今年我也从 vivo 那边看到了一些官方资料。就大方向来看,除了本文开头提到提前 18 个月就投入超过 50 人的技术专家团队,参与 Exynos 1080 的配置定义,vivo 很大程度上是将终端产品使用场景,及终端用户需求,带到 Exynos 1080 的研发过程里。
“在为期一年的前期技术沟通中,vivo 与三星通过每周的技术周会来严格审查芯片中的各个模块和技术细节(CPU/GPU/Modem/ISP/NPU/DSP/PMIC/射频/连接/音频/视频编码/外围设备/安全/传感器中枢/低功耗/系统/内存等),形成超过 10000 项技术点检规格。
“在联合研发期间,vivo 投入总计超过 1400 名技术工程师,包括技术规格专家 50+ 人、电子开发工程师 150+ 人、软件工程师 600+ 人、影像工程师 100+ 人、品质测试工程师 500+ 人等轮流驻厂和派遣团队,共计解决软件层面问题 13000+ 个,硬件层面问题 1000+ 个。”
其中的细节问题,其实前文已经列举了一些具体的参与内容:包括了前期配置定义、 IP 及工艺选择等、AISP 架构的推动、ISP 之上 TNR 硬件降噪模块的优化……;在 SoC 之上系统层级(可能包括了外围、板级、操作系统、中间件、上层应用等)的参与典型如重构相机框架代码,规避拍摄中的运动拖影、模糊等问题……
这里再列举几个系统层级的优化:
1. 5G无线通讯的功耗优化:“将 CP-engine(modem 加速器)和多传输模式架构及功率进行调整优化”,提升数据传输效能;另提升系统快速唤醒和休眠效率,使得“搭载 Exynos 1080 的终端与 vivo X3 相比可降低至少 20% 的功耗”。
2. 基于游戏场景,提升游戏体验:通过第三方应用算力需求的调研,针对不同的应用,来分配算力,如用户唤起应用时调用大算力,应用和游戏运行过程则均衡算力,应用保持后台运行则确保低功耗——这应当算是系统层级的调度策略优化了。
3. 动态帧率自适应:在 Exynos 平台上导入动态帧率自适应,适应内容刷新速度,包括游戏内容帧率匹配。
我所获取的这些资讯,可能仍然没有那么具体,或许我将来有机会时还可与 vivo 的工程师再做深入探讨,在不涉及商业机密的基础上,去理出一些更细节和对爱好者们有价值的资料。
可总结的是,Android 阵营比较少见从 IC 设计到终端设备生产全包的企业,这很容易造成需求与生产的脱节,而且中间层变多也会降低效率。vivo 的主要身份是终端设备制造商,和用户是更靠近的,所以也更懂得用户需求。以需求为出发点,与三星 SLSI 合作,参与最初的设计,加上自己在系统层级上的优化,其实是落实最终手机体验更好的方法。
这也是 vivo“OS+芯片”软硬件生态持续布局,以及构建自身差异化优势的一个体现。
三星的 5nm 工艺
文章篇幅有些过长了,最后一部分就给感兴趣的同学做选读吧。而且这部分内容的阅读可能需要一些相关晶体管制造的基础知识,和前面我们探讨的微架构抽象又有较大差别。而且制造属于三星 Foundry 的业务范畴。推荐在阅读这部分之前,首先阅读我的另外两篇文章:
需要有个基本概念是,像 7nm、5nm 这样的工艺节点数字,实则并不代表微观层面晶体管的任何一个长宽高或者某个具体的参数(如果硬要说的话,应该就只有 fin 宽度和节点数字比较靠近了)。所以 5nm 并不是晶体管的某个部分比 7nm 缩减了 2nm。而且不同晶圆厂对工艺节点的命名有自己的规则,比如说三星的 5nm 工艺与台积电的 5nm 工艺可能就有很大差异。
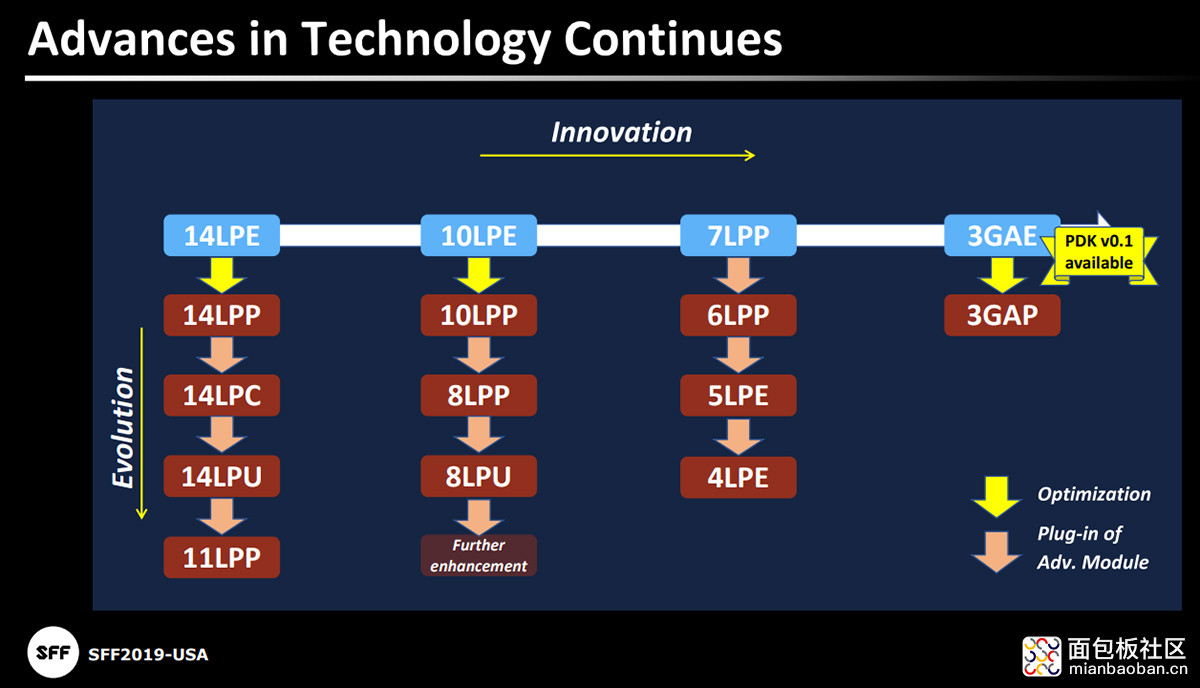
事实上,自芯片制造厂步入 7nm 时代之后,三星 Foundry 就与台积电/Intel 有了较大的路线演进差异。比如说三星在 10nm 工艺之后,就立刻为 7nm 节点选择了某几层的 EUV(极紫外光)。台积电至少前两代 7nm 工艺(N7/N7P)都仍在用 193nm 波长的浸入式 lithography;Intel 同代 10nm 也是如此。
所以在完整节点迭代上,三星 7nm 工艺的起步迈得略大了一点。而三星此后对 6nm、5nm、4nm 的定义,都属其 7LPP 工艺的同代演进,就类似于三星 10nm 与 8nm 工艺的关系那样,如下图。
三星 Foundry 目前的策略都是完整迭代时,走大步子。比如说下一代 3GAE,晶体管结构要改用 GAAFET(Gate-All-Around FET),包括纳米线的 GAAFET,和纳米片的 MBCFET(Multi-Bridge Channel FET)。而在台积电的规划路径上,3nm 仍然采用 FinFET。当然这是后话了。所以目前两者的路线演进,已经出现了较大的分歧。
三星在发布会上提到,其 5nm 工艺(5LPE)令芯片面积降低 35%,功耗效率提升 20%,性能表现提升 10%。
Wikichip 的数据是,三星 5LPE 的 UHD 单元库密度 126.89 MTr/mm²(百万晶体管每平方毫米),相比 7LPP 提升 1.3 倍[3]。不过个人觉得,Wikichip 目前预估的这些数字很难做跨不同晶圆厂的晶体管密度对比。这在我先前的文章中也提过,晶体管密度计算方法有差别,而且晶体管在芯片上也不是均匀分布的,所以不同厂商的晶体管密度数字并不应该做直接对比。
有关三星的 5LPE 工艺这里就简单地谈一谈,其实在常规晶体管尺寸方面,5LPE 相比 7LPP 是几乎没有变化的,包括 fin pitch、gate pitch,以及各层金属间距等。所以对于 IC 设计企业而言,7LPP 到 5LPE 的设计 IP 就能极大程度复用。
那么 1.3 倍的提升是怎么做到的呢?就三星此前在 Arm TechCon 2018/2019 的介绍来看,重点当然就是从单元(cell)着手了。
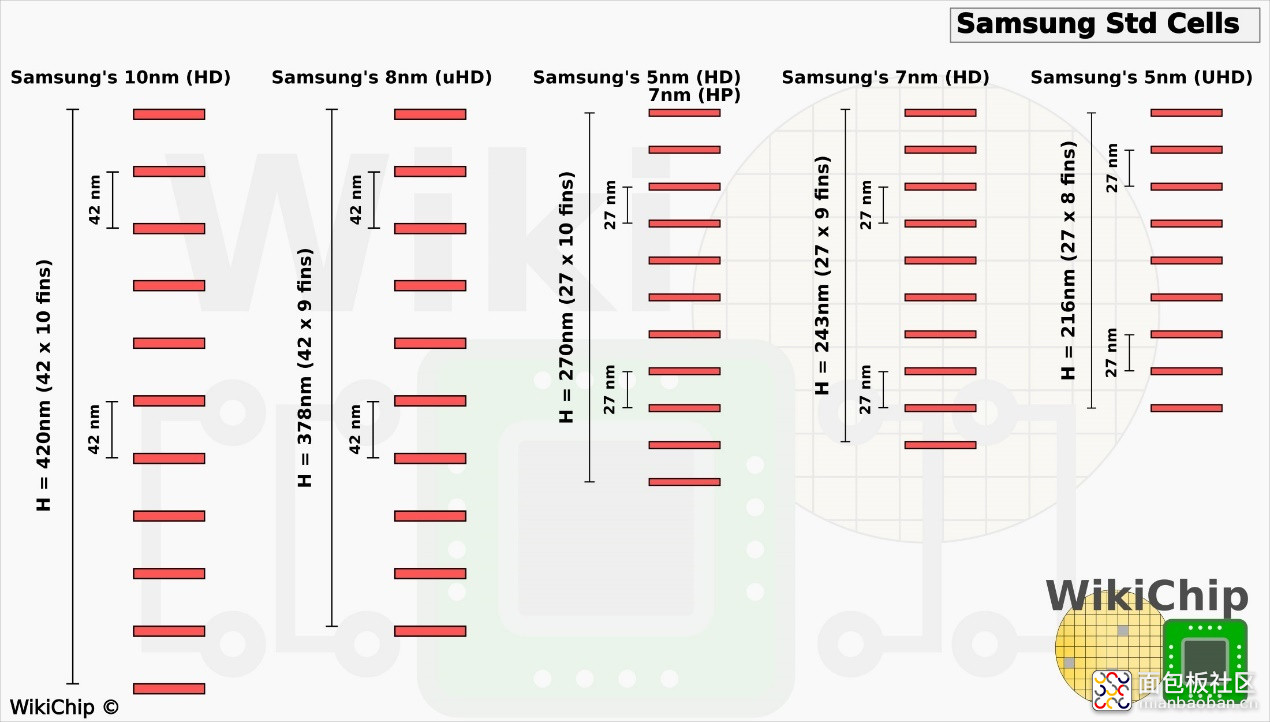
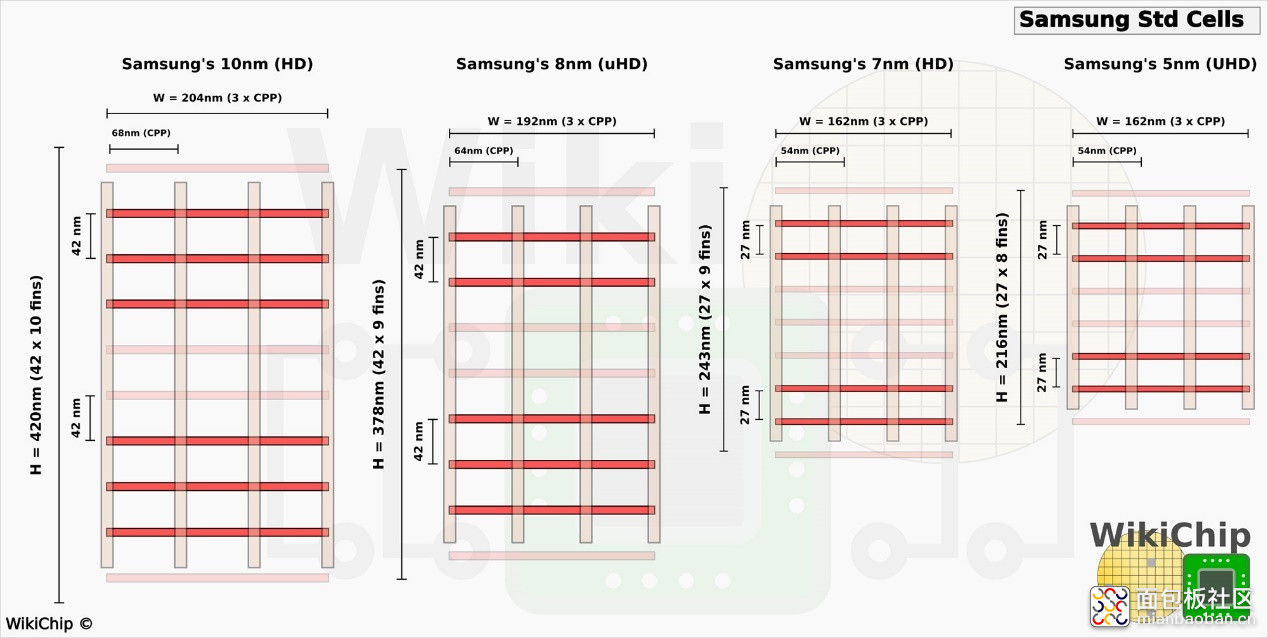
5LPE 引入了一种新型的 6T UHD 单元库。来看下 Wikichip 画的 5LPE 新增 UHD 单元高度的缩减,相较 7nm(HD 高密度单元)的变化。以及更早的 10nm(高密度单元)、8nm(超高密度单元)在 fin 间距和单元高度上的变化:
来源:Wikichip[3]
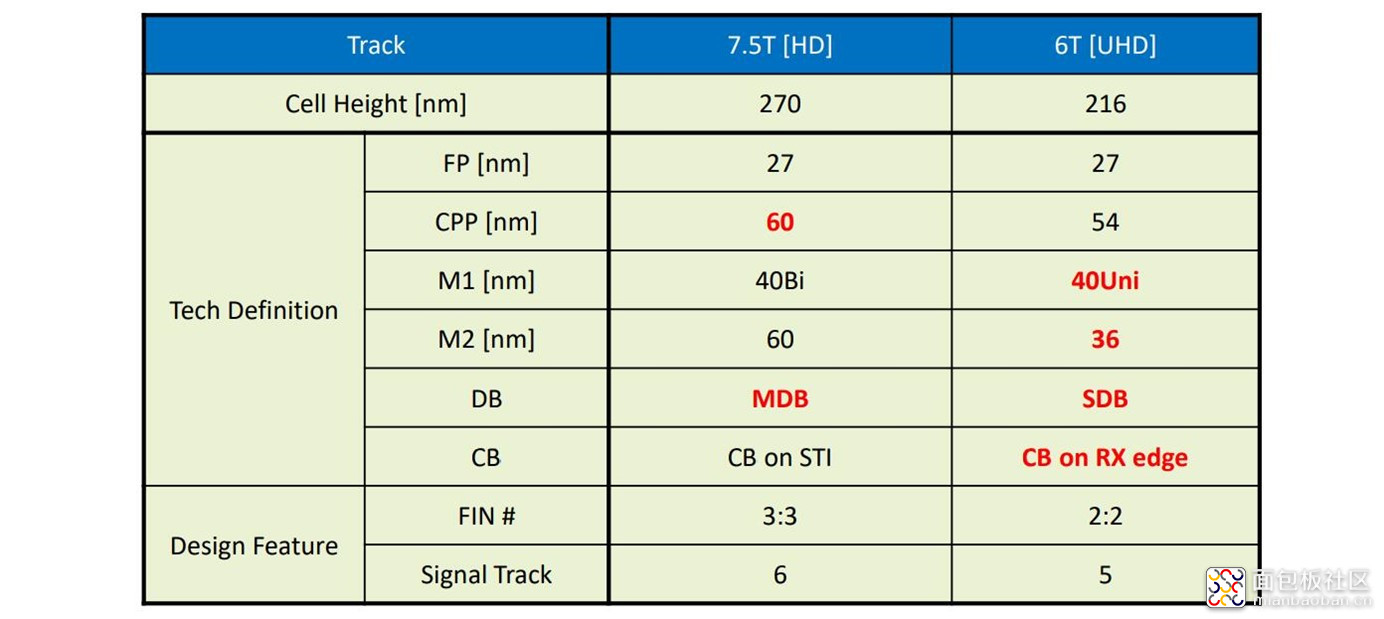
加上 gate 以后就变这样了:
来源:Wikichip[3]
不难发现,三星的 8nm 和 7nm HD 高密度单元相比前代都减掉了一个 fin,减 fin 自然是为了实现面积的缩减、密度的提升。当然在更具体的晶体管改进上,实则 7LPP 的每个 fin 都实现了更高的驱动电流,即更高的性能——这样减 fin 才可行。5LPE 的 UHD 超高密度单元库相比 7LPP 再去掉了 1 个 fin,这样单元高度就变小了。晶体管本身,有包括 low-k spacer 间隔、DC 等方面的加强,要不然性能就得下滑严重了。
当然,这样的 UHD 单元库并不会应用在高性能需求的关键路径部分,这样的话,更大的7.5T HD 单元仍然是必要选择。所以我们才说,所谓的“晶体管密度”实则与芯片设计是息息相关的。6T UHD 与 7.5T HD 单元的主要参数如下:
来源:Arm TechCon 2019[4]
5LPE 相比 7LPP 的实际提升是:对于 7.5T HD 高密度单元库而言,性能提升了11%(同功耗下,速度提升 11%;同性能下,功耗降低约 20%);而 6T UHD 超高密度单元库则实现了大约 33% 的密度提升。[4]
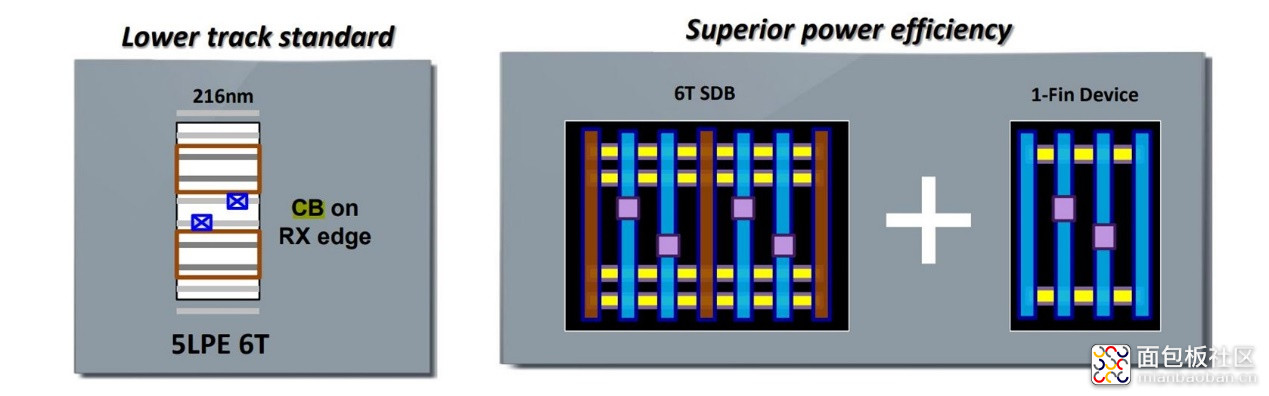
展开一下 6T UHD 单元的一些特性。这种单元包括采用 SDB(single diffusion break)、36nm 的 M2 间距,CB on RX edge(RX是指单元的活跃区域,CB属于额外的本地互联层,在单元内横向布局,将接触层的触点连接到多晶硅本地互联——位于第一层金属层之下,也就是MOL互联;所以CB on RX edge也就是CB互联层用到单元活跃区域边缘)。
除了 6T UHD 以外,5LPE 还引入了一种低漏电的 1-fin device(1个p fin,1个n fin),能够提供至多 20% 的功耗节约。见下图:
所谓的 SDB,三星在更早的工艺节点中就引入过,只不过 7LPP 节点没有选择 SDB。Intel 将 SDB 称作共享 dummy gate。这是指,一般每个单元的两端都会有 dummy gate,而 SDB 或者说共享 dummy gate,就是让两个单元共享一个 dummy gate,以实现尺寸的缩减。上图的 6T SDB 棕色那几条就是 single dummy gate 了。
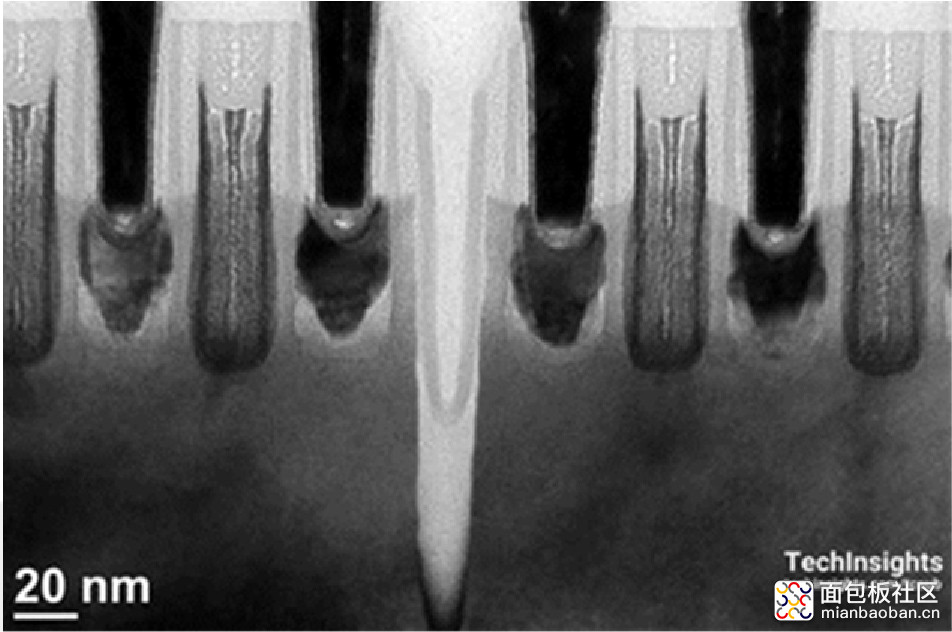
值得一提的是,从 TechInsights 的拆解来看,这里的 dummy gate 实际上并不是真正的 gate,而是个蚀刻足够深的凹槽,如下图[5]:
三星 10nm 工艺中的 dummy gate,来源:TechInsights via Solid State Technology[5]
7.5T UHD 单元之间并未采用 SDB,而是 MDB,混合间隔的 dummy gate:pMOS 为 SDB,nMOS 则是 DDB(double dummy gate),性能自然更好。
最后总结一下,其实前面差不多都已经说完了。一方面是期望,这样的文章能够为半导体技术爱好者开拓视野,理解如今的手机 SoC 从大方向上来看是怎么回事,以及 2021 年的手机 SoC 会是什么样。这在本文第三部分 GPU 介绍的结尾处已经有了小节,即 Exynos 1080 可能会推升中高端定位手机产品的竞争水平;以及这是一颗甜品级,且可能获得较长寿命的手机 SoC。
另一方面,则在 vivo 与三星 SLSI 的联合研发层面,vivo 更多以终端用户的需求为出发点,让 Exynos 芯片在设计之初就更考虑用户体验层面的问题。所以在消费电子爱好者关注 vivo X60 这款手机时,也不要忘记观察,其中的 Exynos 1080 带来了多少细节方面的体验提升,比如夜间拍照降噪与同时 HDR 是否明显有了更快的速度。
参考来源
[1]vivo S6评测体验:5G自拍求对手 - 快科技
https://news.mydrivers.com/1/683/683229_all.htm
[2]Samsung Neural SDK - Samsung Developers
https://developer.samsung.com/neural/overview.html
[3]Samsung 5 nm and 4 nm Update - Wikichip Fuse
https://fuse.wikichip.org/news/2823/samsung-5-nm-and-4-nm-update/
[4]High-Performance 5LPE Implementation Next-Generation Arm “Hercules” CPU. Kevin K. Yee (Samsung), Fakhruddin Ali Bohra (Arm), Edson Gomersall (Cadence). Arm TechCon 2019
[5]IEDM 2017: Intel’s 10nm Platform Process - Solid State Technology
https://sst.semiconductor-digest.com/chipworks_real_chips_blog/2017/12/18/iedm-2017-intels-10nm-platform-process/







 /5
/5 



我的果果超可爱 2020-12-31 13:10
DavidArmstrong 2020-12-17 11:08
火引冰薪 2020-12-17 09:35
yzw92 2020-12-17 06:24