
内部参考版本
第一章 提高代码技巧实现速度优化
如果代码风格非常随意,那么使用再怎么高级复杂的优化工具有时候也无法达到设计约束要求的性能。逻辑设计业界总结了三大设计原则,即速度面积互换、并行和同步设计原则。本章我们来首先讨论数字设计基本物理特性,即速度。在此基础上,我们重点讨论一些FPGA逻辑设计中在代码阶段可以进行速度优化的方法。
根据逻辑设计的内涵,一般我们定义了三个基本的有关FPGA设计速度方面的概念:吞吐量、延迟和时序。在FPGA数据处理背景下,吞吐量指的是每个时钟周期被处理的数据数量,其通用的单位是比特每秒(bps)。延迟是指输入数据和数据被处理后输出之间的时间,它典型的单位是时间单位或者时钟周期数。时序是指时序单元之间的延时,当我们说一个设计“不符合时序要求”的时候,一般是指关键路径或者说最大路径延时(包括组合逻辑延时、时钟到输出的延时、布线延时、建立时间和时钟偏斜等)大于目标时钟周期,常常这时候我们在时序分析的时候会看到负时序余量(slack),时序的标准单位是时钟周期和频率。
这一章,我们将详细地讨论在代码设计的时候如何实现以下列出的优化:
l 设计的最大吞吐量,即如何最大化设计每秒处理的数据比特数。
l 低延迟结构,即最小化一个模块的输入和输出之间的延时。
l 优化时序来减少关键路径上组合逻辑延时
n 在组合逻辑结构中插入寄存器
n 并行处理结构:将顺序执行操作转化为并行操作
n 转化有优先级解码信号为无优先级逻辑结构
n 寄存器平衡:重新分配流水线寄存器附近的组合逻辑
n 路径重组:将关键路径上的一些操作转移到非关键路径
1.1 高吞吐量优化
一个高吞吐设计主要关心的是数据的速率是否稳定在一个稳定状态,而很少关注任何指定的数据通过设计的传输延迟(latency)。我们可以想象一下制造业里面的生产线,数字设计中的吞吐量是指处理的数据量,好比工业制造业,比如汽车生产线,下线产品的数量,这里我们会想到二者相通的一个概念,即流水线(pipeline)。
一个流水线设计与制造业里的生产线非常相似,即原始资料或者数据从前端进入,通过各阶段的操作和处理,最后产生最终的产品或者最终的数据输出。流水线设计非常完美的地方在于,新数据在之前数据还未处理完成的时候就可以被处理,这和汽车在生产线上被处理的模式非常相似。流水线设计多见于超高性能器件中,且不受各种协议结构的限制,比如CPU指令集、网络协议栈以及加密机制等等都非常适合使用流水线设计。
从算法的角度看来,流水线设计的一个重要的概念是“展开循环”。作为一个例子,我们来考察下面这段代码,这个for循环是典型地从纯软件的角度来实现X的三次方。
XPower=1;
for(i=0;i<3;i++)
XPower =X*XPower;
注意上述我们谈到的“软件”是指那些可以在微处理器中执行的指令集。上面for循环其实实现了一个迭代算法,即相同变量和地址一直被访问直到计数完成。这段代码无法并行执行,因为在微处理器中一次只能执行一个指令(这里我们只谈论单核处理器)。相同的功能也可以使用硬件来实现,我们来看看下面这段Verilog代码,实现了跟上述软件一样的算法(这里我们没有考虑输出归一化处理):
module power3(
output [7:0] XPower,
output finished,
input [7:0] X,
input clk,start);//start信号宽度只有一个时钟周期
reg [7:0] ncount;
reg [7:0] XPower;
assign finished = (ncount == 0);
always@(posedge clk)
if (start) begin
XPower <=X;
ncount <= 2;
end
else if(!finished) begin
ncount <= ncount-1;
XPower <= XPower*X;
end
endmodule
上面这个例子,在计数结束之前使用了相同的寄存器和计数资源,如图1-1所示。
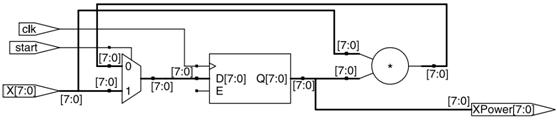
图1-1:迭代的实现
如图1-1所示,这种类型迭代的实现,在前一次计数未完成之前是不会开始新的计数,所以这种迭代机制与之前我们看到的纯软件实现的迭代算法非常相似。唯一的区别在于,硬件实现上述迭代需要一个控制信号(图1-1中的start)来作为握手信号,用于指示计数的开始和结束。另外,还需要一个额外的模块来控制传输新数据到迭代模块以及接收迭代模块输出结果,上述硬件实现的迭代算法的性能为:
l 吞吐量=8/3或者2.7bits/时钟周期
l 延迟=三个时钟周期
l 时序=有一个乘法器延时的关键路径
作为比较,我们对上述硬件实现方法进行改造,下面的代码是利用流水线方法来实现的同样的迭代算法:
module power3(
output reg [7:0] XPower,
input clk,
input [7:0] X
);
reg [7:0] XPower1,XPower2;
reg [7:0] X1,X2;
always@(posedge clk) begin
//第一级流水
X1<=X;
XPower1<=X;
//第二级流水
X2<=X1;
XPower2<=XPower1*X1;
//第三级流水
XPower<=XPower2*X2;
end
endmodule
在上面的实现代码中,我们看到X被同时赋给两级流水中的寄存器,这两级流水都使用独立的资源来实现相应的乘法操作。需要注意的是,当X在第二级流水中被用于计算最终的三次方时,X的下一个值可以被赋给第一级流水,如图1-2所示。
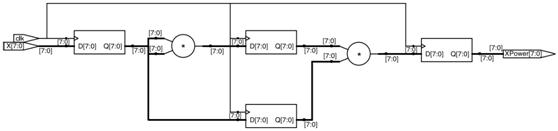
图1-2:利用流水线实现迭代算法
如图1-2所示,最终的X3的计算和下一个X值的首次计算同时发生,这种设计的性能,如下所示:
l 吞吐量=8/1,或者8bits/时钟周期
l 延迟=三个时钟周期
l 时序=一个乘法器延时的关键路径
可以看到吞吐量获得了三部的提升,通常,一个算法需要n次迭代循环,该循环被展开后并使用流水线实现的话,吞吐量都能获得n倍提升。比较图1-1和1-2我们发现这里并没有增加额外的延迟,也没有消极的时序影响,关键路径还是只有一个乘法器。
类似这样的迭代循环的展开带来的后果就是增加了面积。我们看到图1-1实现的迭代只需要一个寄存器和一个乘法以及一些没有展现的控制逻辑,而使用流水线实现的迭代则需要独立的寄存器来寄存X和XPower,同时每一级流水都需要一个独立的乘法器。后面的章节我们再来讨论针对面积的优化。


 /2
/2 






用户1645455 2013-11-29 22:37
用户439399 2013-11-26 08:38