
国家兴亡匹夫有责,从神九用到CAN总线讲起(7)学会检验
关于第一种错帧漏检的原因,可疑帧重构方法可以参考我以前的文章:杨福宇,“CAN协议的错帧漏检率改进“,《单片机与嵌入式系统应用》,2011, No.9,p.8-11,详细的英文版见Fuyu YANG, On Residual Error Probability of CAN Protocol, http://www.frogenyozurt.com/wp-content/uploads/2010/06/CAN-Residual-Error-Probabilioty.pdf。
没人会否定细节决定成败这一原理,错帧漏检率就是细节,完全是数值决定的。如果算错了,岂不是搞了冤案吗。这是支持本系列博文观点的基础,所以我将这部分公布在这里,用三篇文章:(7)、(8)、(9)讨论CAN的错帧漏检问题。这里是我最新的版本。第一篇是在原有分析的基础上用的新方法论证,给出了第一种情况下的错帧漏检率。好处是你不用计算机也能手算来核实,可以用一天、甚至更少的时间,证明Bosch的数据是错的;第二篇文章是给出第二种错帧漏检原因下的错帧漏检率,它也不需要你花很多时间读懂它、核算它,给出的错帧漏检率也证明Bosch的数据是错的,因为数值虽小,仅此一项也已超过了Bosch的数据;第三篇是探讨可疑数据流(见后面定义)发生在CRC部分时的情况,计算得到的错帧漏检率也相当大,仅此一项也已超过了Bosch的数据。
这非常专门,感兴趣的人未必很多,很多杂志会因为读者面窄、版面字数限制等而*毙了它。但是你如果想驳倒我在本系列博文中表达的观点,你至少要指出我的计算有错误,所谓谁主张谁举证。
技术的发展也是越来越专门化,就CAN错帧漏检率的事进行研究,全世界也只有数人而已,如果这些人(包括我自己)犯了错,岂不误事?公开之后人人可以复核,便于纠正。特别是我的方法不需要大量机时,复核的条件宽松多了。
有人对专门的议题不太感冒,“我又不是干这一行的”。有些人会认为看起来非常纠结,我需不需要花力气读完它?
不错,每个人精力有限,不过常识性的东西总不会拒绝的。好比你买了台电视机,开不出来,你会查查电源插了没有,插座好不好,入户总保险烧了没有。当别人说这台电视机有问题,你总要先用常识判断一下。现在我说CAN有错帧漏检率高的问题,你最好也判断一下,我这里没有高深的理论,而仅是技巧,一层窗户纸,捅破了就没什么稀奇。如果我说得对,这就成为你的另一种常识,用到别的需要判断的地方。
在以前的文章中我没有给出具体数值的推导过程,这次我采用了更简化的方法,完全手算,证明我的数据是可靠的。
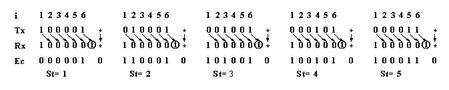
0. CAN规定,发送节点在连续5个相同位后自动添加一个反向的值,接收节点在收到连续5个相同位时就把下一个反向的值删去。
在一个连续5位的窗口中,由于出现传送位错,会只有一边执行填充位规则,见图0。然后收发二边的位流就有了相位移,会造成许多位错。如果第二个传送错使相位移回来,后面的位流就不再受影响。相移造成的多位错是CAN的CRC失效的原因之一。
图0 CAN填充规则可能造成位流的相移
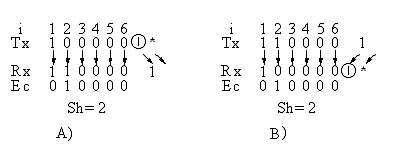
1.可疑数据流的结尾部分存在一个6位的窗口,在这里有一个位错,使填充规则只有一方执行,执行的结果是不再有相位移。图1是发送节点有填充位而接收节点无,图2是发送节点无填充位而接收节点有。
图1 第2个传送错造成填充位误读为信息位的5种漏检错序列尾部形式
图2 第2个传送错造成信息位误读为填充位的5种漏检错序列尾部形式
要知道的是:因为第一个1是用于开始一个5b窗口的“分界符”的作用,处于第2位的0也可能是填充进去的0,所以尾部的形式不止这5种,详见英文稿。其他尾部型式对错帧漏检率的贡献比较小,几乎可忽略不计,所以本文就仅讨论这5种尾部型式。
2.我的创新方法得以成功的基本条件是从误差多项式Ec,t重构出对应的Ut,这里下标t表示尾部。
Ut是一个多项式,由Ut*G可得到Ec。只要有Ut,并在它的基础上添加x的多项式变成U,就可以由U生成Ec,由Ec生成可疑数据流Tx。这样的Tx在特定位置发生位错时就会生成Ec,因为Ec是G的倍数,就会错帧漏检。
所以由Ec求Ut是关键。做CRC检验的除法时将数据字写为D=(dm dm-1…),生成多项式写为G=(gn gn-1…),商写为Q=(qk qk-1 …)。则有:
qk=dm*gn
qk-1=dm-1*gn+dm*gn-1
而求对应的尾部有Ec,t= (e5 e4 e3 e2 e1 e0);Ut= (u5 u4 u3 u2 u1 u0).
e0=g0*u0
e1=g1*u0+g0*u1
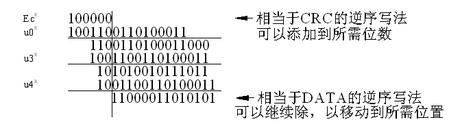
所以存在一种逆序的类似性,可用逆序做除法。以Ec,t= (0 0 0 0 0 1)为例,CAN的G的逆序写法为(1001100110100011),除法过程见图3。由于感兴趣的仅是Ec的最后6位,所以除法只要把该6位除尽就可。这种逆序求法可以由CRC反求出在某位置的数据是什么样的,这种方法将来还要用到。如果你把这张图倒过来看(下面的转到上面,左面的转到右面),就可以看到它就是你平时做CRC除法的过程。所以CRC与DATA之间的关系是相互可以求取的,只是你没有注意而已。
图3 由CRC逆序求DATA的方法
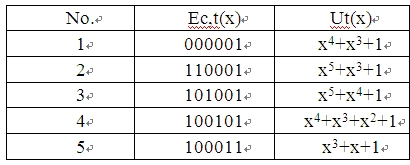
所以只要将Ec,t和G以逆序写法就可以求得Ut的逆序写法。Ut的阶次在5之内,例如对应出错的5个位置有x4+x3+1等(如表1)。
表1
3.可逆数据流的头部也是一个6位的窗口,只有一方执行填充位规则。它的误差多项式与尾部的形式类似(图4)
图4 头部出错形态
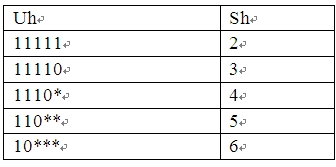
U的头部用多项式来表示如Uh=(uk uk-1 uk-2 uk-3 uk-4),这里只取5项,因为它与G相乘后形成Ec的头部5项,已经足够判断容许的第一个位错发生的位置。因为Ec的第一个1代表第一个位错发生的位置,而第二个1最早发生在可疑Tx的第7位。例如,Uh=(1 1 1 1 1)时,Ec=1000001...,第1个1最早只能在Sh=2。Uh=(1 1 1 1 0)时,Ec=10001...,第2个1最早只能在第7位,所以Sh=3。Uh=(1 1 1 0 *)时,Ec=1001...,第2个1最早只能在第7位,所以Sh=4,此时uk-4的取值已不影响可疑数据流的长度。Uh=(1 1 0 * *)时,Ec=101...,第2个1最早只能在第7位,所以Sh=5,此时uk-3 uk-4的取值已不影响可疑数据流的长度。Uh=(1 0 * * *)时,Ec=11...,第2个1最早只能在第7位,所以Sh=6,此时uk-2uk-3uk-4的取值已不影响可疑数据流的长度。
于是可以汇总为表2。这个关系是核查的基础。
表2
我们知道,Ec的阶次是U的阶次与G的阶次之和,即k+15。Ec的长度是阶次加1,而Ec的最后一位就是可疑数据流的最后一位,所以可疑数据流的长度就是Ec长度加Sh-1,即:
LTx=k+15+Sh (1)
4.由于Ut的系数只到只到x5,就可以从x6开始往上加xk,使Ec不断加长,形成各种漏检实例。
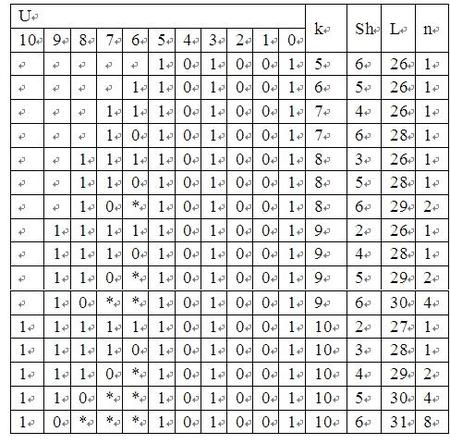
当k=6~10时,它与Ut中的项形成的头部就不是简单可确定的,所以我们用表格列出来,对照表2的Uh-Sh关系,以及(1)式,就可以得到添加xk各种组合后的可疑帧长度,以及对应该长度的组合的数目。
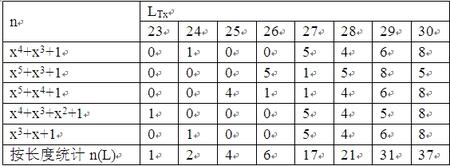
对表1的5种尾部多项式添加结果如表3~表7,我将表4~7移到注1中,以便愿意深究的朋友复核。一般读者只要看出表3表达的意思即可:在Ut上添加高次项是如何改变U头部类别,从而改变可疑数据流长度L及该长度下可能的可疑数据流数目n的。
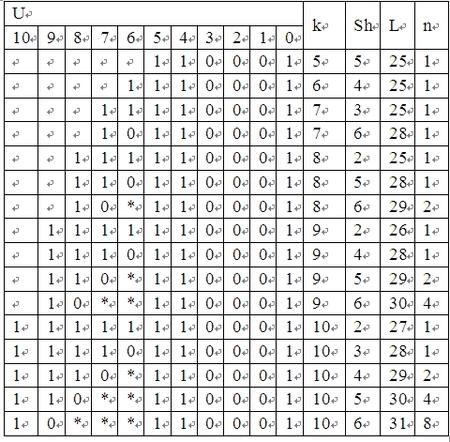
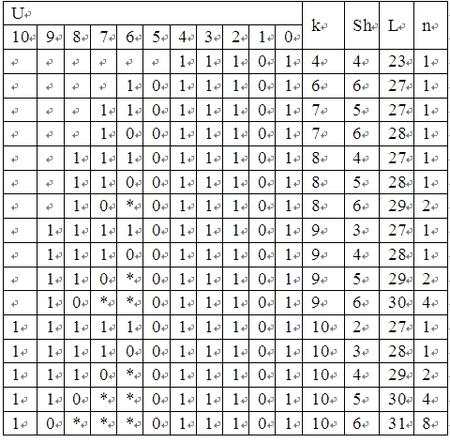
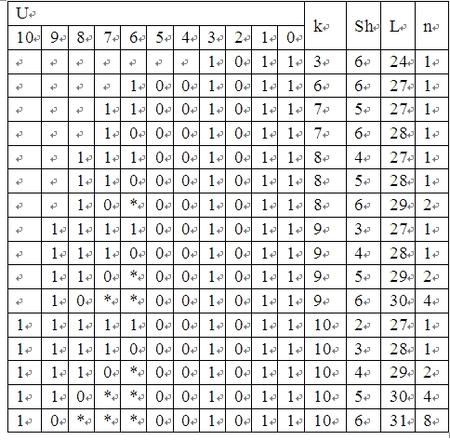
表3 x4+x3+1
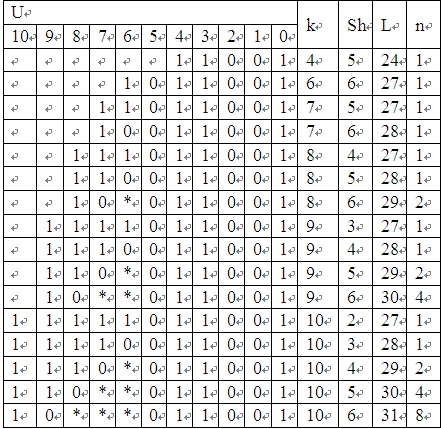
由这些表可汇总出出现各种可疑数据流的次数,并统计总数如表8
表8 在k<=10时各可疑数据流长度出现的总次数
5.有了U就可以构造出完整的Ec,由Ec就可以构造出整个可疑数据流Tx。
例如 U=x6+x4+x3+1,得到Ec=U*G=(1110,1111,0101,1010,0000,01),重构见图5。由Ec可知第一个位错发生在第6位,由Ut=x4+x3+1可知,第二个位错发生在尾部的第一位。在头部的Tx填充位被Rx理解为数据位之后,Rx和Tx就有了相移,所以由Ec7和Rx7就可以决定Tx7=Ec7○+Rx7,然后因为传送中没错,所以Rx8=Tx7,逐位推出,直到第22位,传送中又出第二次错,Rx23=not Tx22,继续无错到第27位,由于Rx方出现填充位删除条件,Tx27被删掉了,Rx与Tx的相移消失,整个可疑数据流就构造完成。
图5 U=x6+x4+x3+1重构出的可疑数据流
这重构出的Tx之所以称为可疑数据流,是因为只有当位错发生在特定位置时(在本例中是第6、22位)才会发生漏检,若不在特定位置,那么产生的Ec就不是生成多项式的倍数,CRC就可以检验出错误,不会漏检。
6.可疑数据流Tx处在数据域内的任一段内(图6)。
如果可疑数据流Tx流的长度为LTx,那么在可疑数据流Tx以外的帧的其余部分取值(除DLC及格式规定部分外)都是可以任选的。对可疑数据流Tx存在的一段,只有一种与Tx有关的具体数据。这样,与特定位置、特定Tx有关的漏检占所有长度为LTx的各种数据的概率为2-LTx。当Tx在数据域内移动时,因Bit flip位置不同,又构成新的漏错实例,这样的移位会有65-LTx种,头部窗口有100000,011111及填充位规则在发送节点或接收节点处执行共四种,所以对特定Tx(与Ect有关)的漏检概率是:
Pun,L=4*(65-LTx)*2-LTx (2)
图6 可疑数据流的位置
7.我们根据(2)式以及表8计算k<=10时的漏检概率为:
Pun,L<29=ΣPun,L*n(L) (L=23~29)
=2-27*(42*26+41*25*2+40*24*4+39*23*6+38*22*17+37*2*21+36*31)
=2-27*(2688+2624+2560+1872+2584+1554+1116)
=2-27*14998=1.11*10-4
表8中LTx=30的项的贡献在后面计算,以避免重复。
8.对于k>10到容许的最大值时的漏检率贡献以LTx作主线来计算,因为k>10之后Ut的差别已无影响,而Uh的形式起主要作用。这里仍然要用(1)式:
LTx=k+15+Sh。
当LTx固定时,不同的Uh=(uk uk-1 uk-2 uk-3 uk-4)就决定不同的Sh,也就决定了k。由表2知道:
Uh=11111时Sh=2,k=LTx-17,由k-5到k=6共k-10项可以任意选,用LTx代替k即LTx-27项可以任意选,所以属于这一类的有n1=2(LTx-27)种组合。
Uh=11110时Sh=3,k=LTx-18,由k-5到k=6共k-10项可以任意选,即LTx-28项可以任意选,所以属于这一类的有n2=2(LTx-28)种组合。
Uh=1110*时Sh=4,k=LTx-19,由k-4到k=6共k-9项可以任意选,即LTx-28项可以任意选,所以属于这一类的有n3=2(LTx-28)种组合。
Uh=110**时Sh=5,k=LTx-20,由k-3到k=6共k-8项可以任意选,即LTx-28项可以任意选,所以属于这一类的有n4=2(LTx-28)种组合。
Uh=10***时Sh=6,k=LTx-21,由k-2到k=6共k-7项可以任意选,即LTx-28项可以任意选,所以属于这一类的有n5=2(LTx-28)种组合。
所以对特定的LTx有nL=n1+n2+n3+n4+n5=3*2(LTx-27) (3)
种组合。
每种LTx的漏检概率还要考虑它在64位数据域内的可移动数目65-LTx、对应LTx长度有一个漏检帧所占的比率2-LTx、5种Ut形式和4种头部形式,于是:
Pun,L=5*4*(65-LTx)*3*2(LTx-27)*2-LTx=15*(65-LTx)*2-25
最长的LTx=64,考虑求和直到LTx=30(上节对小于30的已求过了),则有Pun,L=64~30=15*(1+2+...+35)*2-25
=15*630*2-25=2.81*10-4
于是所有不同长度的可疑数据流造成的漏检概率总和是:Pun,L=1.11*10-4+2.81*10-4=3.92*10-4
9.位错发生在对LTx特定位置的概率:
上述分析是针对位错发生在非填充位时的,所以仅考虑8字节数据的全部帧长就可以了,可算出帧长为107位,二个错分散在107位中的总的组合数是107*106/2=5671种,所以位错发生在特定位置的概率是Pposition=1.76*10-4。
由此得到Pun=Pun,L*Pposition=3.92*10-4*1.76*10-4=6.89*10-8。
这个数据并不是漏检的全部(见后面的文章),但是它已经比Bosch声称的4.7*10-11大了1000倍。
注1:
表4 x5+x3+1



用户1454308 2015-8-10 15:50
Good
sinsow_139482477 2013-5-21 08:53
用户1138908 2013-3-23 09:43
sicom_973192125 2013-2-1 15:16
用户1406868 2013-2-1 10:56
CAN也有自己的上层纠错机制。目前应该没有绝对可靠的总线系统。
用户987244 2013-1-31 00:46
用户822765 2013-1-30 08:49
用户1173460 2013-1-28 21:23