
国家兴亡匹夫有责,从神九用到CAN总线讲起(9)知和识
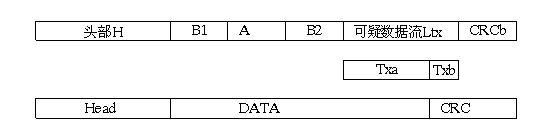
在文(7)中分析存在于数据域的可疑数据流,但是CAN的位填充规则适用的范围还不止这些,本文分析可疑数据流部分或全部覆盖CRC域的情况(图1)。可疑数据流的一部分Txb进入了CRC,而CRC余下的部分用CRCb表示。
图1可疑数据流对CRC的覆盖
我们在数据域内划出一小段15位的连续空间A,它的位置可以在数据域内非可疑数据流的任何地方,它的前后有数据块B1、B2。根据CRC计算的的原理,总的帧长的CRC校验和是各分段CRC校验和的异或的结果。所以对选定的可疑数据流,Txa是已知的,假定任取HB1B2(这表示一个串,其对应位置各为H、B1、B2,未定义的位置全为0。各位置的xi多项式阶次是不同的,所以串在一起时只要把多项式相加),在串后加Txa,得到HB1B2Txa,有一个相应的校验和CRC1(15位),我们可找到合适的A,使串HB1AB2Txa的校验和(15位)正好有TxbCRCb(15位)。因为串HB1AB2Txa是HB1B2Txa和A组合成的,设A的校验和为CRC2(15位),故有CRC1+CRC2=TxbCRCb。显然,已知TxbCRCb和CRC1,CRC2就是确定的。而根据文(7)图3介绍,已知CRC2就完全可确定原来的数据A。对应一个TxbCRCb就有在特定位置的唯一的A,这里在特定的可疑多项式覆盖部分CRC域时,只有覆盖部分的Txb是已知的,CRCb可以任选,就可以在特定位置对应多个A。这些情况就构成了概率分析的基础。
发生可疑数据流部分或全部覆盖CRC域的情况时,错帧漏检的条件有如下几项:1。可疑数据流占同长度数据的比率(包括不同头部形式、尾部形式);2。对应可疑数据流覆盖CRC位数,存在的数据A的数目占A可能的数据的比率(包括A在数据域内可取得不同的位置);3。位错发生在特定位置的概率。
由文(7)式(3)每一种长度的可疑数据流LTx,在LTx〉=30时有3*2(LTx-27)种,有4种头部形式和5种尾部形式,每种LTx长有2LTx种可能的数据流,所以可疑数据流占同长度数据的比率为P1=4*5*3*2(LTx-27)/2LTx=15*2-25。
LTx为23~30时如表8所示。这里P1=4*n(L)/2LTx。
由CRC2确定A时存在概率问题。假定A在数据域内的位置已设定,因为CRC2中只有Txb几位是固定的,那么A有多个取值,如用指针m表示Txb的位数,那么CRC2就有215-m种,对应的A也有215-m种,而A为15位,所以合适的A的比率为2-m。而A可以处在数据域内未被可疑数据流占用的部分任意位置,位置空大小为64-15-(LTx-m)=49-LTx+m。即使位置空为0,也可以算一次,所以合适的A的比率为P2=(50-LTx+m)*2-m。当LTX比较大时,若留在数据域内还很多,不足以留出A需要的15位空间,那么就无法靠A来产生漏检条件,所以要求LTX-m+A<=64,即LTX-m<=49时才算。
8字节数据域的帧帧长为107位(不计填充位),发生2个位错的位置组合共有107*106/2=5671种,所以位错发生在特定位置的概率是P3=1.76*10-4。
于是我们得到的漏检概率Pun计算程序为:
n=(1 2 4 6 17 21 31); %由表8得到
P3=2/107/106;
Pun=0;
for LTx=23:1:64
if LTx < 30 P1=4*n(LTx-22)/2LTx;
else P1=15*2-25
end
temp=0;
for m=1:1:15
if LTx-m<=49
temp=temp+(50-LTx+m)*2-m
end
end
Pun=Pun+temp*P1*P3
end
运行结果为3.32*10-8。
特别要提一下,对CAN2.0B来讲,在ID中有一个连续的18位,这个区间可以放置上述A块。此时LTX可扩大到整个数据域与CRC域,即LTX=79;由于A块不再在数据域,计算的条件“LTX-m<=49时才算“分为二种,当LTX-m<=49时LTX和A均可在数据域内,移动的次数由(50-LTx+m)再加ID内移动4次。当LTX-m<=64时A在ID内,移动次数为4次。于是我们得到CAN2.0B的漏检概率Pun计算程序为:

用户1100283 2013-5-24 18:13
用户869009 2013-3-23 09:31
用户1042819 2013-3-12 08:38
用户1602177 2013-3-11 14:57
用户1610239 2013-3-11 14:49