
今年英伟达 GTC ,Toy Jensen 又出场了。就是在去年 GTC 走红的、以黄仁勋本人为基础定制的一个虚拟人物形象——去年这个角色似乎还叫 Toy-Me。这是个可以进行实时对话的人物形象,能做眼神接触、对话,而且有全套的动画动作。宣传中,英伟达提到 Toy Jensen 是建立在 Omniverse Avatar 框架的基础之上。

就是这么个看起来简单的东西,实则浓缩了很多现代技术。初见此等技术,很多人可能会想:它很高端吗?能对话的智能语音助手不都一抓一大把?事实上,即便抛开对话式 AI 的质量不谈,Toy Jensen 也有很多技术点,或者说在造 Toy Jensen 过程中遇到的实际工程问题。因为这毕竟不是个简单预渲染的动画,而是你跟他说话,他立马做动作、表情、回应的虚拟角色。
首先是 Toy Jensen 的声音——是基于 Riva 语音 AI 的 Text-to-Speech RAD-TTS 语音合成。而面部表情则是用 Omniverse Audio2Face。去年其实我在谈元宇宙的文章里谈到过 Audio2Face,这个应用的神奇之处是在只有人声的情况下就能生成 3D 面部表达,嘴型都能和输入的音频完美匹配。
而支配 Toy Jensen 身体动作的是 Omniverse Animation 的 Animation Graph——这是应用于骨骼动画合成、回放和控制的一个 runtime 框架。Toy Jensen 的手、胳膊、头部和其他肢体动作都依托于此。
至于黄仁勋标志性的黑色皮衣,为了凸显 Toy Jensen 身上皮衣本身的皮革质感,令其看起来不像是塑料,需要用到英伟达开源的 MDL(Material Definition Language)。去年的 SIGGRAPH 上,英伟达宣布推出一个叫 Omnisurface 的东西,就是 MDL 的一部分,大约与此是相关的。
此外,要让 Toy Jensen 与人对话又需要动用到对话式 AI,也就是 Riva 和英伟达的 Megatron 530B NLP 模型……所以这称得上是现阶段集 AI 大成的作品了。
当涉足具体应用时,其关联的技术点还会更多。比如在今年 GTC 的 Omniverse Cloud 演示中,Toy Jensen 和另外三名设计师一起远程协作,也就是和真人一起完成设计工作:则其中涉及的 AI 和图形技术还会更多。
Toy Jensen 现阶段还只能说是英伟达用于炫技的一个虚拟角色,但同样建基于 Omniverse Avatar 的 Tokkio 虚拟机器人却是着眼于应用的,包括零售店、快餐店的服务 AI;今年英伟达也演示了 Tokkio 在智能驾驶汽车上直接与乘客对话并完成指定工作的过程。
当我们谈元宇宙这个话题时,图形计算、AI 一定是避不开的。而 Toy Jensen、Tokkio 必然成为元宇宙形成初期的某种示例和构成元素,即便我们现在离构建完整的元宇宙还略有些遥远。
这几件事让我感觉元宇宙有眉目
参加今年的英伟达 GTC,有三件事让我印象非常深刻——让我感觉我们离元宇宙并没有很遥远,或者我们周遭原本就有了越来越多虚拟的东西。第一就是 Toy Jensen。
第二是黄仁勋在亚太区答记者问时,有个记者提问像 Omniverse 这样一个虚拟世界和技术,未来是否将模糊虚拟和现实的界限。“比如可能现在接受我们采访的 Jensen 就不是个真人。这会给世界带来混乱还是希望呢?”近两年受到疫情影响,GTC 活动的答记者问都是从线上接入的。
黄仁勋在画面那头是这么作答的:“其实现在我眼前的你,并不是真正的你。你经过了 H.264 编码、你数字化了,然后经过传输又以 H.264 解码,然后我才看到了这样的你——这已经不是你本人了,而是你的一个重构版本。”
“如果我用 CV(计算机视觉)来对你进行检测感知,实际上检测的并不只是构成你的那一堆像素,还在于这背后的很多东西。比如说,能算出如果你现在要是站着,会是什么样子(因为采访时大家都坐着)。CV 所做的不只是‘所见’还在于‘所想’。然后再用计算机图形学来对‘想象中’你的样子(比如站着的你)进行重构。我就能以我期望的任何方式与你进行交互了。”
“比如说可以 VR 的方式和你交互,我们可以在同一个房间里走来走去。”黄仁勋说,“这就不光是数字化、编解码的问题了。这是我们所做的工作,改变通信过程的一个例子。”
“而 Omniverse 是我们的一个平台,用于模拟现实世界。我们的首个应用就是机器人——要是没有 Omniverse 的话,机器人的编程、测试就只能放到真实的环境里去进行。但机器人很笨重,测试过程会存在各种危险。那我们就需要一个虚拟的版本,机器人的数字孪生版本,把它放到 Omniverse 世界里——在这样的环境下对机器人进行编程测试。而且在该环境下,机器人的运作也是符合各种物理学定律的,就像真实世界一样。”
这是现在已经达成且在高速发展中的技术。说更近一点的,Zoom、腾讯视频之类的远程会议 app 如今都有“虚拟背景”功能。这大概就是最初级和简单的虚拟世界存在我们身边的佐证了吧。


第三,是黄仁勋在主题演讲过程中展示了某个虚拟人物(如上图,点击看动图,或者叫 AI-powered character)。黄仁勋说:“我们用强化学习来开发更贴近真实生活,和能够进行真实响应的模拟角色。这些角色基于人类动作数据——比如说走路、跑步、挥剑——来学习各种人类真实动作。”
据说这些角色训练机制是要求 10 年期的模拟的,而基于英伟达大规模并行 GPU 模拟,只需要现实世界中花 3 天时间就能训练完成。随后这些角色还能掌握各种技能,执行更复杂的任务。比如说撞倒某个东西、往不同方向前进,甚至我们可以随便输入一句话来控制角色。从演示来看,其动作流畅、自然程度与人类基本无异。
“我们希望这项技术最终能让虚拟人物的交互,就像和真人对话一样简单、流畅。”这项演示因为是基于模拟出的人形角色(而不是机械臂、物流机器人),所以第一次让我感觉“AI”是如此生动和真实的存在,仿佛随算法与算力堆砌,这些人形角色总有一天会有科幻电影呈现出的行动力。将其复制一份到现实世界,是否就是真正的生化人?
以上这三者都与虚拟世界、AI 有着莫大关联。在英伟达的生态帝国里,NVIDIA Omniverse 和 NVIDIA AI 是平台层的两个支柱,下面这张图展示了其间关系。感觉这张图的梳理,对于理解英伟达涉足的业务,有着相当大的帮助——否则,这公司的市场概念如此之多,而且有些隔年还改名,我们这些普通人实在很难记得住…
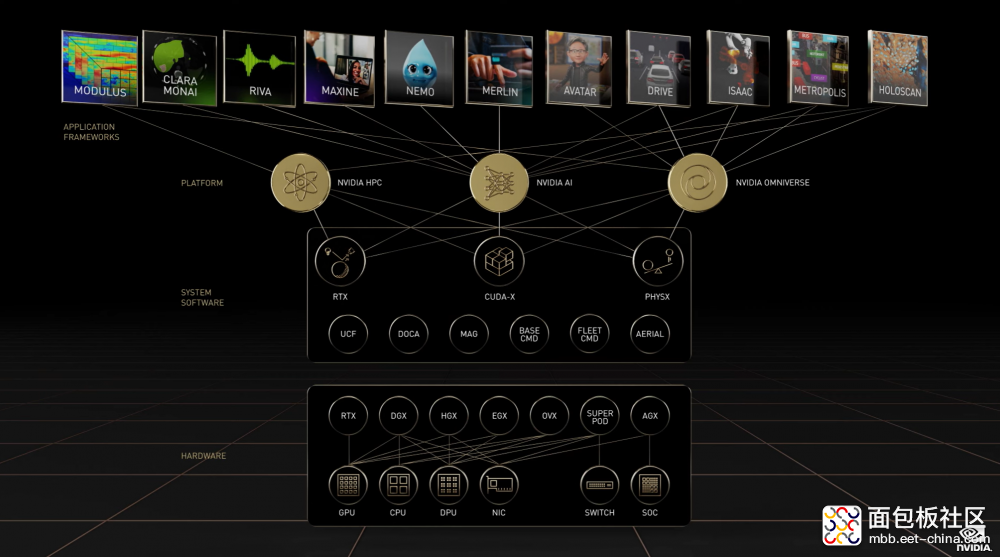
总结一下,今年 GTC 有关 Omniverse 和 AI 的发布内容主要有以下这些:
• 发布 Nvidia Omniverse Cloud;
• 发布 Nvidia OVX 与 OVX SuperPOD;
• 发布 Spectrum-4 交换机;
• 发布面向桌面 PC 的 RTX A5500 GPU;面向笔记本的更多绘图专业 GPU;
• Omniverse 平台与生态的相关发展与更新(如 Connector 增加到 82 个;有更多新的客户;Omniverse Kit、Nucleus、XR、Replicator、DeepSearch 等应用和组件更新);
• 发布 Nvidia AI Accelerated 项目;
• 发布 Nvidia AI Enterprise 2.0;
• Nvidia AI 部分库、软件和工具的更新(如 Triton、Riva 2.0、Maxine SDK、Merlin 1.0、Nemo Megatron)
• 发布代理气候模型 FourCastNet;用于 6G 通信研究的 Sionna 框架;还有一些公布的信息是往届 GTC 有过介绍的(或者这些内容有新的更新),比如说用 Modulus 打造 Earth-2 地球的数字孪生,再度介绍用于网络安全的深度学习模型 Morpheus 等。
机器人、汽车原本也属于 Omniverse 和 AI 的组成部分——如前文提到将机器人放进虚拟世界中训练,其中关乎到合成数据生成、训练模型、模型部署测试之类的问题,这些也都在英伟达的射程范围内。
不过因为机器人和汽车风头正劲,所以这两年英伟达都是单独将其拿出来谈的。今年事实上也有一些关键更新,比如说面向 AMR(自主移动机器人)发布了专门的 Isaac SDK,还有面向汽车的 Hyperion 9 发布等等。但这些不成为本文探讨元宇宙的组成部分。
元宇宙的雏形,数字孪生
虽说把 Omniverse 叫做元宇宙是不对的,但私以为 Omniverse 是现阶段最接近元宇宙、且更能落地的东西。如果你不知道什么是 Omniverse 的话,建议你看看这篇文章。
Omniverse 现阶段在做的是两件事:设计协作与模拟仿真。设计协作比较类似于我们用云共享文档,直接合作编辑 word 一样。但 Omniverse 的设计协作是面向 3D 设计、建筑及更多专业视觉向的工作。创作者可能位于全球不同位置,而设计流程则可能涉及到各种不同的软件工具。
而模拟仿真,主要体现在数字孪生(digital twin)上。比如这次 GTC 上列举的一个例子,是 Siemens Gamesa 公司用 Omniverse 和 Modulus 搞风力发电厂的数字孪生。为了让风力发电厂输出电力最大化,可在虚拟世界先做各种环境、配置模拟。据说速度比成本高昂的涡轮仿真要快 4000 倍。

最大规模的数字孪生,则是去年英伟达就宣布要搞的 Earth-2 超算,作为实体地球的数字孪生。而且是可以实时交互的数字版地球。
3D 的数字孪生世界有一个基本前提,就是这个世界是必须符合物理学定律的,包括粒子、液体、材料、弹簧、线缆等等的物理特性模拟。游戏中我们常说的光线追踪就属于这样的模拟。
有没有感觉这稍微有点元宇宙的样子了?我始终认为,数字孪生的精度提高、规模扩大,终极版本就是元宇宙。而模拟仿真、数字孪生本身,又可认为是设计协作的高级阶段。
今年针对 Omniverse 世界的搭建,英伟达发布的硬件主要包括了 Nvidia OVX 服务器、OVX SuperPOD 集群。其配置特点就是满足工业数字孪生需求,处理延迟敏感、更要求实时性的工作——包括 32 台 OVX 服务器组成的 OVX SuperPOD 集群。英伟达说 OVX 要覆盖从汽车、工厂,到城市、地球各个级别的数字孪生项目。
另外这次发布的 Spectrum-4 交换机(用于这类 SuperPOD 集群的互联)也可认为是未来元宇宙发展的某一类基础设施,或者基础设施雏形吧。今年 GTC 的媒体沟通会上,英伟达技术专家提到 Spectrum-4 与那些一般处理 mouse flow 流量(大量用户、但 flow 数没那么多)的交换机不同,偏重在处理 elephant flow 流量(比如模拟整个地球所需的流量)。
所以 Spectrum-4 是为 RocE(RDMA over Converged Ethernet)打造的,数据共享会更快,比如可以实现 GPU direct storage。与此同时“相比一般数据中心毫秒级的抖动,Spectrum-4 可实现纳秒级计时精度,有 5-6 个量级的提升。”

另一个有关 Omniverse 比较值得一提的新发布是 Omniverse Cloud。其本质就是完全云化的 Omniverse。如果打比方的话,它和云游戏是近亲。在本世纪初云游戏概念出现以前,上世纪 80 年代就曾出现过用远程服务器做 3D 图形绘制,并将结果以图像形式回传给客户端的设计思路。
在 Omniverse Cloud 服务下,终端设备不需要 RTX GPU,可以是平板、手机、轻薄本、Mac 电脑,通过 GeForce Now 接入到 Omniverse Cloud。黄仁勋形容“一键设计协作”,就是只需要给你的同事发个 URL 链接,他在任何算力的终端设备上,点击链接就能进入到 Omniverse 的设计协作项目中。(似乎也有部分算力下放到本地的选择)
这在 3D 设计、数字孪生领域应该是挺举颠覆性的。只不过 Omniverse Cloud 目前还处在测试阶段,正式发布时间尚未知。而且以我对云游戏的了解,这种追求实时交互的云计算基础设施的建设和运维成本会是非常高的,尤其要达成比较好的体验,有大量工程问题要解决。
但我想,英伟达这么做主要应该也是为了扩大 Omniverse 的覆盖范围,让任何设备,即便是算力比较弱的设备也能用上 Omniverse。而且一键设计协作,以及通过 Omniverse Cloud 在数字孪生环境里测试新软件,都非常像是元宇宙的必要组成了。在元宇宙构成中,大家也是这么看云游戏的。
元宇宙发展要素,AI
原本谈元宇宙的基础设施应该去聊一聊底层芯片的。英伟达的芯片,尤其是 CPU、GPU 是今年 GTC 的重头戏。不过这部分我已经写了一篇7000字文章。对于 Hopper GPU,和 Grace CPU 感兴趣的同学可以移步看一看。虽说英伟达常年强调,自己不只是一家芯片公司,这仍是其赚钱和各项业务开展的基础。
而英伟达 GPU 架构迭代,越来越有 DSA 的样子;类似 Grace 超级芯片这样的 CPU,也有特别的场景针对性。对未来需求海量算力和芯片资源的元宇宙而言,这些可为此奠定基础。
而且 Hopper GPU 更新今年强调的就是 AI 算力,反倒没那么在意 HPC。不管是因为英伟达在 AI 市场吃下了多少红利,所以在堆料方面有了偏向性,还是英伟达在数据中心方面有别的发展思路,AI 作为元宇宙的必然要素是毋庸置疑的。
从前文英伟达的那张四层图就能看出 Omniverse 和 AI 之间有着错综复杂的关系。包括前面举的例子,虚拟角色走路、跑步、挥剑训练本身就是在一个符合物理学原理的虚拟图形世界里,与此同时这种训练必须借助 AI 技术。而机器人、汽车的模拟测试就更是如此了,像 DRIVE Sim,可以理解为把汽车的数字孪生,放在虚拟世界里路测,甚至可以搞一些 AI 生成的对抗场景(Adversarial Scenarios),以训练自动驾驶应对各类极端突发状况的能力。(汽车本身就是一种特殊的机器人)
英伟达是从 AI 基础设施硬件,到上层应用框架,提供全栈支持的企业——包括很多现成的预训练模型和迁移学习工具,还有合成数据之类。我采访过很多 AI 芯片公司,他们对于英伟达的态度普遍是 PPT 吊打,但私下很明了市场覆盖和生态搭建上,相比英伟达难以望其项背,所以只考虑一些竞争没那么激烈的市场——包括一些你们现在所知的顶尖的独角兽 AI 芯片公司。
今年 GTC,英伟达宣布开启 AI Accelerated 计划。英伟达给的数字是现在已经有超过 100 名成员加入。这个计划似乎是英伟达会帮助开发者来解决部署问题;或者说应该是加速 AI 发展,以及加速自家 AI 技术覆盖的计划。
Nvidia AI 这次的几个主要更新包括了 Nvidia AI Enterprise 2.0 发布。Nvidia AI Enterprise 本身是面向企业可应用 AI 技术的套装和服务。英伟达的说法是,让那些没有 AI 专家的企业,也能用上 AI;让 AI 开发部署流线化;企业自身可以专注在 AI 创造的价值上,而不必在意基础设施管理之类的问题。
除了企业级支持,更新到 2.0 版本的重点在于,可以跑在 vmware 和 Red Hat 认证平台上,包括裸金属虚拟化或者 container;以及获得 AWS、Azure、Google Cloud 支持;基于英伟达认证的服务器配置。

另外两个比较重要的更新是 Riva 语音 AI SDK 更新至 2.0 版,以及 Merlin 推荐系统框架发布 1.0 版——就是互联网公司现在普遍会给用户搞各类推荐服务(如推荐商品)的实现基础。
Riva 在前面谈 Toy Jensen 的时候就提到过,是个可用于语音识别、text-to-speech 的套件,里面也包括了模型——可以用迁移学习工具来做个性化的模型精调。2.0 版这次总算是宣布面向大众了。另外还有新发布的 Riva Enterprise,面向大规模部署,其中当然也有 Nvidia 的企业级支持服务。
而 Merlin 是面向数据科学家、ML 工程师的推荐框架。英伟达说只需要少很多的代码就能扩展出一个 recommender。这次 1.0 版的发布,也是让 Merlin 正式面向大众开放了。限于篇幅,更多有关 AI 的发布不再做介绍。
黄仁勋说现在很多公司都开始出现一个名叫 MLOps 的部门,职能就是把手里掌握的数据转为可预测的模型,实现智能化,最终转化为利润。这可能就是未来诸多企业的发展归属吧。像这样的发展,本身就是在为元宇宙添砖加瓦。
推进再推进
今年英伟达发布了一个叫做 FourCastNet 的模型,全拼 Fourier Forecasting Neural Network,是好几所高校的研究人员,外加英伟达一起打造的气候预测模型,可以预测飓风、大气河流、极端降水等灾难性事件。而且据说精度、准确度非常高。
“这是我们第一次能够用深度学习的方式去实现,相较于传统数值模型有着更高的精度和能力。”英伟达的工程师说相比传统的数值模型,速度快 45000 倍,而且能效高出 12000 倍。以前一年才模拟出来,现在只需要几分钟。另外还强调这个模型是所谓 physics-informed 的。
与此同时,英伟达再度谈到了 Modulus,这是个用于开发物理学机器学习神经网络模型的框架,以符合物理原理为准则,构建 AI 模型。FourCastNet 就是基于 Modulus,融入 Omniverse,辅以 10TB 的 Earth 系统数据,以数字孪生的方式打造的模型。

这应该是英伟达构建地球数字孪生的一个组成部分,部分达成与地球数字孪生的实时交互。那么我们是否可以说,客观上它就成为了元宇宙的一部分?虽然或许人们对于元宇宙的需求,还需要更多内容的填充。这个例子也是 Omniverse+AI 的一个绝佳体现。
这两年我们常说以前以视频加速卡起家的一家企业,有没有想过未来某一天会要去考虑人工智能、基因测序、计算化学、数字孪生、自动驾驶、智能机器人、元宇宙这样宏大的议题。今年 GTC 上看到有关 Omniverse 和 AI 的更新,已经不像前两年那样是看各种琳琅满目的新词汇和新概念了,而是有更多的东西正在稳步更新、推进中。
不过从英伟达这些年在 HPC、AI、Omniverse 生态的努力上更能看到元宇宙构建的难度,这绝不是任何企业凭借一己之力就能轻松达成的。比如 Omniverse 的生态建设就尚在早期,Omniverse Cloud 也才刚刚发布测试版而已;而 FourCastNet 的达成,更是多方长时间合作的结果。
作者: 欧阳洋葱, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-3893689.html
版权声明:本文为博主原创,未经本人允许,禁止转载!




 /4
/4 







自做自受 2022-4-3 16:24
摘要:
这项技术让我每天晚上都锻炼了好几个星期。虚拟现实健身即将成为一场革命吗?
周五晚上,我克服重重困难,来到了健身房。只有我,几个沙包,一个拳击台,还有西尔维斯特·史泰龙(Sylvester Stallone)。他招呼我过去。我知道我根本不配和他交手。
是吗?我低头看看自己。我赤裸着上身。我的体型很健壮,看起来就像一个拳击冠军。在这个虚拟现实世界里,史泰龙是我的师傅,他帮助我打磨自己的身体和技能。
自做自受 2022-4-2 22:13