
对于《基于 SoC 的卷积神经网络车牌识别系统设计》的设计总览,可以参考上一篇文章《基于 SoC 的卷积神经网络车牌识别系统设计(1)引言》。接下来,就大概讲一下整体的设计流程,主要分为系统的搭建和车牌的识别。对于更加详细的系统设计,会单独发文详解~
1、系统的搭建
基于 SoC 的卷积神经网络车牌识别系统设计的硬件架构
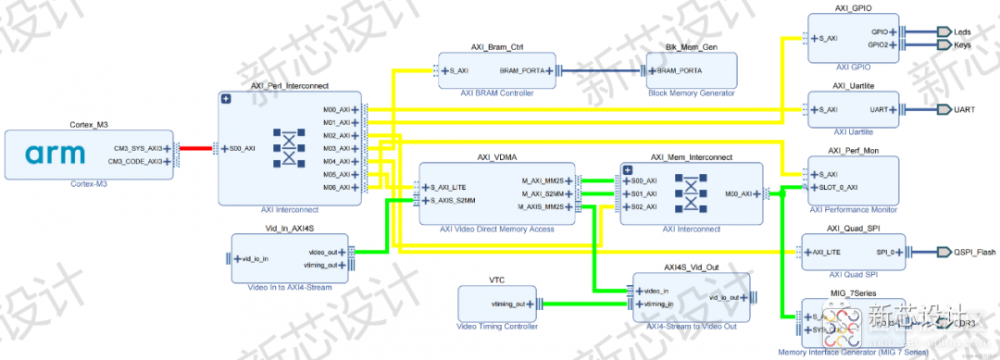
首先呢,就是系统的搭建(如上所示)。当然,在系统的搭建之前,需要先确定好硬件平台,如 Xilinx Artix-7 FPGA 开发板(集成了 28nm 中端芯片)、OV5640 摄像头模块、HDMI 线以及 HDMI 显示屏模块(或者 FPGA 引脚杜邦线以及 LCD 显示屏模块)、JTAG 调试器(VCC、GND、TCK、TMS)。另外,需要再确定好软件平台,如 Win10、Vivado 2018.2、Arm Keil uVision(MDK525)、PyCharm(OpenCV + TensorFlow)、JLink.exe、车牌生成器。因此,这是一个软硬件协同设计的智能 SoC 系统。
搭建的系统能够通过 HDMI 接口,在 HDMI 显示屏上(或者通过 FPGA 引脚在 LCD 显示屏上)实时显示 OV5640 摄像头所采集的车牌视频数据。(当然,这个功能描述的貌似简单粗暴,其实搭建起来能把你累成 Dog,其中就有 CPU 软核 IP 的导入与测试,AXI4 总线的互联,OV5640 和 HDMI 的 IIC 的设计,OV5640 和 HDMI 寄存器的配置,OV5640 解码模块的 IP 设计,VGA 行场同步的时序协议与基于 AXI4-Stream 流协议的数据流格式的转换,VDMA 和 DDR3 MIG7 的配置,以及许多常见的 Xilinx IP 如 Vid_In、Vid_Out、VTC 等等 IP 的载入与配置,Clock Wizard 时钟分频 IP 的添加与配置,最终还有 Xilinx Vivado Verilog 代码和 ARM Keil C 代码的交叉编译等等,哎,各个模块都是一门学问啊,贴出来的是一个简化版的系统搭建,只留下了 IP 和 AXI 总线)。
总而言之,系统合理地划分了软硬件的功能,充分地展示了异构平台的优势。
2、车牌的识别
接着,就是车牌的识别。对于车牌的识别,主要分为车牌识别预处理(RGB2HSV、HSV2Binary、形态学)、定位、分割、缩放、卷积神经网络(字符识别)五大部分。(其它文献中分为车牌定位、字符分割、字符识别)。当然,在基于 Verilog 车牌识别设计之前,我们首先需要在 PyCharm 软件平台上进行设计、训练、测试与验证(AI 芯片开发都是这样的),例如在 PC 端进行车牌识别预处理、定位、分割、以及神经网络模型的训练,这里是基于 OpenCV 的车牌识别预处理和基于 TensorFlow 的神经网络框架训练的,训练的模型准确率能够高达 99%。通过获取所有识别车牌的训练集,即 00000→99999 ,训练完毕之后,通过对测试集测试能够达到一定的识别率之后,提取网络中的权重参数(全连接层占据主要部分,卷积层占据次要部分),便完成了能够在硬件上实现的固定的网络模型与参数(当然,量化、缓存、加速策略等等还是需要自己定的啦),然后便开始你的 AI 芯片设计,这里主要是作为 CPU 的一个协处理器,一个字符识别的硬件加速 IP。
软件平台实现之后,于是就生成了如下的车牌识别框图,从头到尾分别是OV5640 输入、基于 OpenCV 的车牌识别预处理(RGB2HSV、HSV2Binary、Morphology)、定位、分割、缩放、基于 TensorFlow 的卷积神经网络(网络输入、第一层填充 + 卷积层 + ReLU + 池化层、第二层填充 + 卷积层 + ReLU + 池化层、全连接层、Softmax、网络输出)、LCD 显示。最终,就可以启动基于 FPGA 的硬件设计。
基于 SoC 的卷积神经网络车牌识别系统设计的实现框架





 /4
/4 






文章评论(0条评论)
登录后参与讨论