
TTP/C由出错到功能失效的过程
TTP/C与我们有什么关系?
我在博文http://forum.eet-cn.com/BLOG_ARTICLE_18727.HTM
中讲了A380的多次座舱压力系统失效,那是性命攸关的。2012年3月27日,北京至广州的CZ3000航班A380客机起飞时,因客舱增压系统发生故障致中途返航,多名艺人也在这架飞机上,故引得较大关注。南航引进的A380客机,昨天(2012年5月2日)在执飞北京到广州航线时发生故障,起飞后一个多小时后又返回首都机场。南航方面称,返航原因系客舱增压系统发生故障。自从南航购入A380客机后,这已是第三次故障,众多乘客对频频故障表示不解。南航的A380出问题的飞机可能是同一架,一而再,再而三说明不是偶然。然而2013年11月8日报道的马来西亚航空公司A380座舱压力发生故障,出现在另一架飞机上就可能是系统性的问题了。
我在博文http://forum.eet-cn.com/BLOG_ARTICLE_18817.HTM
中讲了TTP/C脆弱的原因。这里再补充点资料,说明TTP/C与我们的大飞机项目有关。
下面要说明TTP/C是如何由出错到发展为功能失效的。
TTP/C是时间触发的通信协议,每个节点占一个时隙进行发送,它有时间同步机制以及时隙保护机制(bus guardian),任何节点只能在调度表指定的时隙内发送。但是它没有像CAN那种即时报错机制,传送中出了错怎么办?会不会一直错下去?TTP/C就设计了一个组籍算法,让节点间得到节点状态的相互间一致的看法,如果出错多,那些出错的节点就会切除,经干预之后重新加入通信,切除节点的信息也可被上面的应用利用,从而改进应用的可信赖性。这种报错虽不像CAN那样及时(发现错就在下一位开始报错,最快1us),但也算及时(1个Round,ms级)。
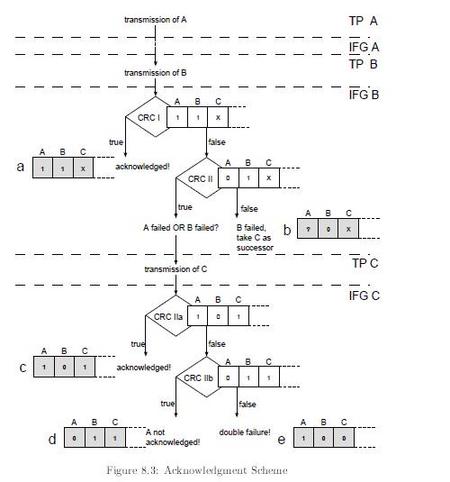
所谓组籍就是一个向量,其中每一位代表一个节点的状态,节点正常收发时该位设为1,出错时设为0。正确的节点要有3组参数都相同,第一是工作模式相同,第二是对当前时隙的位置认识相同,第三是组籍相同。C-State包含了这三组参数,又以显式放在初始化用帧(I-Frame)内,以隐含方式放在正常数据帧(N-Frame)的CRC内。所以CRC检验通不过就一定发生错了:可能是数据错、或者是工作状态不同、或者是组籍不同,这个节点就可能要从组籍中除名。每个节点的组籍向量如何确定?其中对应其他节点的各位由接收时的成败决定,对应自己的那位由称为”隐认可“算法确定。有些作者的文章对“隐认可“算法的解释是非权威的,下面是从TTP官方的Specification上的截图。
简单地说,这一位向量由后续的二次发送的2票决定,它自己的发送设为1票,若后面再有1次成功接收就算1票,就可确定这位为1(case a, c)。但是如果后续的二次发送均收下来错时,它再作一次判断:以自己错、后后续的二次发送的节点组籍向量对,这样的组籍重新校核CRC,成功就采纳此假设(case d),失败就决定自己的发送是正确的,后后续的二个节点均错(case e)。这里用到了一个Round只出一个错和没有拜占庭错的假设,如果不满足,这个对自己的判断就会错。例如有拜占庭错决定自己状态的依据就不可靠了。
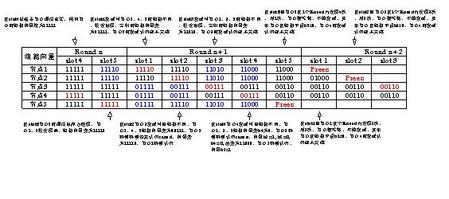
上图以5个节点的系统为例,组籍向量中各位b1b2b3b4b5代表节点1~5的状态,它们在对应的slot发送(以红字表示),发生接收错的节点,其组籍用蓝字表示,接收正确的节点,其组籍用黑字表示。在Round n 的slot 5发送前,系统正常,组籍均为11111。在slot 5发送时出了拜占庭错,节点1、2收错,它们的组籍中b5便变为=0,节点3、4收对。这就突破了TTP/C的故障假设。在slot1节点1的发送因与别的节点的组籍的差别,引起出错,使节点3、4、5中b1=0,且节点5的发送没有结束隐含认可。在slot2节点2的发送因组籍差别,引起节点3、4、5中b2=0,且节点5的发送得到否定的隐含认可,前图中的case d,所以向量对应修改为11100。后续的变化不再细述。到了Round n+1的slot5,因为正确收发次数没有大于错误收发次数,节点5被疑有故障而冻结,不可发送,在该slot中其余节点未收到帧,就b5设为0,但正确/错误记数器的值不作改变。随后又发生了节点1、2节点的冻结,整个系统一半以上节点停止工作。
如果在Round n+2的slot1、2中再发生错(这还没有破坏TTP/C一个Round一个错的假设),节点1、2中还会有节点冻结。
此时TTP/C的要害是什么呢?
1。当有半数以上节点冻结时,余下节点的数量可能不能支持TTP/C节点间时间同步的需要(至少3个),因为并不是每个节点都定义为时间同步的参考节点。在本文例子中就无法保证节点的时间同步了。
2。冻结节点重新加入通信有一个过程,它要观察总线上的I帧,从中获取同步的必要信息(当前调度表的位置,组籍向量,以及工作模式)。TTP/C只规定了每Round的I帧数量不少于2个,但是在不满足故障假设的条件下,必须规定每Round至少有一半以上的I帧,才可以避免发I帧的节点全被冻结。
3。在满足故障假设的条件下,考虑到Round n+2中再出错时留下的节点更少,如果只有1个了,怎么办?难道要100%的I帧?那么正常的N帧在什么时候传送?这就使TTP/C在总线效率与可靠性中落入两难境地。
这个过程说明故障还会发展,有变为事故的可能。例如只留下很少的节点在运行,而冻结了的节点无法再进行同步加入。整个系统的一部分应用就收不到必须的消息,就会出事故。此时可以由应用中的时限设定来发现这种失效,可以设想会选一种系统重启的策略。但是系统重启由健康节点执行还是冻结节点执行?这是需要选择的,因为重启是全系统的全局的事情,只有让还在运行的节点全部冻结才可以重启,这就把一个应用的事故扩大为全部应用的事故。这样,每个节点还需要在应用程序中时时监视总线上发I帧的节点还在不在?另外通信的重启动与应用有牵制吗?因为上述故障发展过程中应用已受影响,特别是有些状态信息已经丢失(没收到),对先开后开等联锁的系统是对状态信号非常敏感的,重启会需要确定断点的位置,可能需要先同步于特定的重启帧,这会非常复杂。
我在博文http://forum.eet-cn.com/BLOG_ARTICLE_18817.HTM中计算出TTP/C容错的故障假设会失效的概率在条件非常好的情况下(ber=10-9)是8.6*10-5/h。假定飞架生产2000架,每架飞了1000小时,那么会有176架出现TTP/C失效引起的功能故障,或许小故障,或许是大故障。真实的ber会更大,那么出事的概率就更大,想想就令人害怕!
最近EE-Time发表了关于在Oklahoma case 中因Toyota车突然加速造成撞车死亡案件独家对控方证人的专访。其中证人列举软件错误有许多条。其中有一条涉及外购软件的内容,即操作系统OSEK版本未认可,由于操作系统的关键数据未保护而任务死亡,可以引起节气门不受控制,从而突然加速。Toyota在此案中败诉。在这个指控中,实际上要求主机厂自己要有能力发现这样的问题。给我们的启发是,如果我们没有这种能力,就要发展这种能力,因为无法卸去这样的责任。
我最近读到这段话,与大家共勉;“知識每天都在更新,作為做學問的人,不能疏於學習,更不能因為自己的保守因循而誤導公眾,可以因為不知而有所保留,但不可以一棒打死。“
图看不清的话,可下载附件


 /4
/4 




用户1418560 2014-1-7 10:47
用户1406868 2014-1-6 10:47
用户1602177 2014-1-3 16:03