
为确保AD/ADAS系统的安全性,各大车企通常需要收集、处理和分析来自于摄像头、激光雷达等传感器的数据,以找出提高系统安全性和性能的方法。然而在数据收集过程中,不可避免地会出现大量无价值数据,造成数据泛滥的情况,进而影响数据的分析处理进程。为此,本文将为大家分享如何通过合适的指标及分析工具,实现数据的高效管理、解读和正确分析,以避免数据泛滥的不利影响!
对于汽车制造商来说,确保AD/ADAS系统的安全性通常需要收集大量数据。为了开发、验证和改进自动驾驶系统,流程通常是相同的:在各种条件下反复进行驾驶测试,累积大量里程。
这些来自不同来源(摄像头、GPS、激光雷达、仿真等)的驾驶日志随后会被处理和分析,以找出提高系统安全性和性能的方法。由于涉及大量传感器、众多不同的使用场景以及大量的行驶里程,需要处理的信息量会迅速呈指数级增长。
面对如此大量待处理的信息,很容易让人感到不知所措。收集到的很多内容可能毫无用处(设想开车行驶的数千公里却什么有趣的事情都没发生),而且在这个过程中,一些信息可能会丢失或损坏。此外,仅收集数据是不够的。这些数据需要被管理、解读和正确分析。数据池越大,这个过程就越痛苦和昂贵。
基于上述问题,康谋提出2个关键点,助力AD/ADAS系统开发、验证和改进过程,避免被庞大的数据淹没,从中获得最大受益:
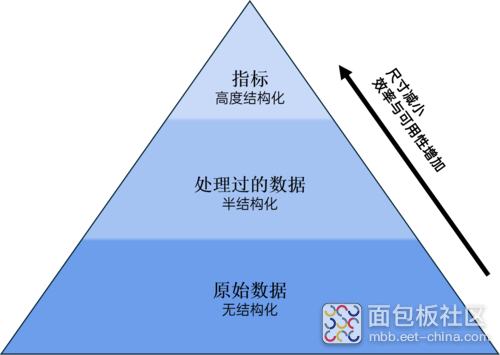
第一个关键点在于一个简单的原则:必须尽可能减少数据池,只保留最相关的信息。内容越少,处理和分析越快。此外,专注于更小的有效信息集合可以降低存储成本和维护负担。
为了减少初始内容池,可以创建有用的信息块,或者说"指标(metrics)",以更简短和有意义的方式总结和描述它。这些指标可以根据使用案例指代多种事物:统计数据、事件或甚至场景。一旦它们与业务需求对齐,就有必要通过适当的算法生成。
设想一下您正在努力提高新车辆的安全性和舒适性。具体来说,您正在试图了解如何减少车辆进行危险紧急制动的情况,即车辆突然刹车导致乘客不适,并构成潜在安全隐患的情况。与其手动检查历史驾驶记录去找到这些情况,不如构建一种算法来完成这项工作。
例如,遍历驾驶测量数据,计算车辆的减速度,并标记超出您定义的舒适限度的时刻。此外,该算法还可以计算其他参数,如与其他车辆的距离,以了解发生这种情况的原因。一旦初始数据已根据所选指标进行标记,您就可以将精力集中在这些上面。
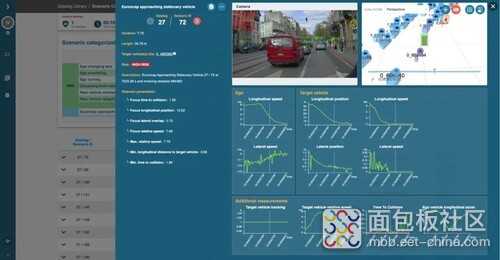
经过了关键点1,最初的原始数据池就被压缩成了少量的相关内容。它们需要被可视化、分析和共享,以便能够用于新车辆、传感器或软件的开发或验证。所有这些都可以通过联系发现与强大的分析平台来完成。
这是一个可以汇总所选指标并控制信息流的集中点。根据具体情况,有许多可视化检查的例子:分析地图上近处的碰撞事故、在时间序列图上提取切入场景、可视化相机图像上消失的物体等。好用的可视化也有助于分析,并允许生成可以跨团队或任何利益相关者共享的报告。
为了说明这一点,让我们继续以上一节中描述的安全和舒适性为例。一旦找到您初始驾驶日志中所有感兴趣的紧急制动情况,就可以理解它们是如何以及更重要的是为什么发生。一种解决方案是在地图上显示这些情况,并绘制相关车辆和周围障碍物的信息。然后可以将这些发现传递给相关团队,进而改进系统。
总而言之,为了从收集的数据中获得最大收益,需要将其归纳为有用的指标,然后在一个强大的分析工具上显示这些指标,以便于可视化和共享。要实现这些,需要拥有一个合适的架构作为处理流程的基底,使算法和工具能够顺利运行。
作者: 康谋, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-4073320.html
版权声明:本文为博主原创,未经本人允许,禁止转载!




 /3
/3 






文章评论(0条评论)
登录后参与讨论