
内核同步缘起何处?
提到内核同步,这还要从操作系统的发展说起。操作系统在进程未出现之前,只是单任务在单处理器cpu上运行,只是系统资源利用率低,并不存在进程同步的问题。后来,随着操作系统的发展,多进程多任务的出现,系统资源利用率大幅度提升,但面临的问题就是进程之间抢夺资源,导致系统紊乱。因此,进程们需要通过进程通信一起坐下来聊一聊了进程同步的问题了,在linux系统中内核同步由此诞生。

实际上,内核同步的问题还是相对较复杂的,有人说,既然同步问题那么复杂,我们为什么还要去解决同步问题,简简单单不要并发不就好了吗?凡事都有两面性,我们要想获得更短的等待时间,就必须要去处理复杂的同步问题,而并发给我们带来的好处已经足够吸引我们去处理很复杂的同步问题。先提两个概念:
临界资源:
各进程采取互斥的方式,实现共享的资源称作临界资源。属于临界资源的硬件有打印机、磁带机等,软件有消息缓冲队列、变量、数组、缓冲区等。 诸进程间应采取互斥方式,实现对这种资源的共享。
临界区:
每个进程中访问临界资源的那段代码称为临界区。显然,若能保证诸进程互斥地进入自己的临界区,便可实现诸进程对临界资源的互斥访问。为此,每个进程在进入临界区之前,应先对欲访问的临界资源进行检查,看它是否正被访问。如果此刻该临界资源未被访问,进程便可进入临界区对该资源进行访问,并设置它正被访问的标志;如果此刻该临界资源正被某进程访问,则本进程不能进入临界区。
说到此处,内核同步实际上就是进程间通过一系列同步机制,并发执行程序,不但提高了资源利用率和系统吞吐量,而且进程之间不会随意抢占资源造成系统紊乱。
为了防止并发程序对我们的数据造成破坏,我们可以通过锁来保护数据,同时还要避免死锁。这里给出一些简单的规则来避免死锁的发生:
-
注意加锁的顺序
-
防止发生饥饿
-
不要重复请求同一个锁
-
设计锁力求简单
我们知道了可以用锁来保护我们的数据,但我们更需要知道,哪些数据容易被竞争,需要被保护,这就要求我们能够辨认出需要共享的数据和相应的临界区。实际上,我们需要在编写代码之前就设计好锁,所以我们需要知道内核中造成并发的原因,以便更好的识别出需要保护的数据和临界区。内核中造成并发的原因:
-
中断
-
内核抢占
-
睡眠
-
对称多处理
为了避免并发,防止竞争,内核提供了一些方法来实现对内核共享数据的保护。下面将介绍内核中的原子操作、自旋锁和信号量等同步措施。
1、内存屏障(memory-barrier)
内存屏障的作用是强制对内存的访问顺序进行排序,保证多线程或多核处理器下的内存访问的一致性和可见性。通过插入内存屏障,可以防止编译器对代码进行过度优化,也可以解决CPU乱序执行引起的问题,确保程序的执行顺序符合预期。
Linux内核提供了多种内存屏障,包括通用的内存屏障、数据依赖屏障、写屏障、读屏障、释放操作和获取操作等。
Linux内核中的内存屏障源码主要位于include/linux/compiler.h和arch/*/include/asm/barrier.h中。
include/linux/compiler.h中定义了一系列内存屏障相关的宏定义和函数,如:
其中,barrier()是一个内存屏障宏定义,用于实现完整的内存屏障操作;smp_mb()、smp_rmb()、smp_wmb()分别是读屏障、写屏障、读写屏障的宏定义;smp_read_barrier_depends()是一个读屏障函数,用于增加依赖关系,确保之前的读取操作在之后的读取操作之前完成;smp_store_mb()和smp_load_acquire()分别是带屏障的存储和加载函数,用于确保存储和加载操作的顺序和一致性。
内存屏障原语
-
smp_mb():全局内存屏障,用于确保对共享变量的所有读写操作都已完成,并且按照正确顺序进行。
-
smp_rmb():读屏障,用于确保对共享变量的读取不会发生在该读取之前的其他内存访问完成之前。
-
smp_wmb():写屏障,用于确保对共享变量的写入不会发生在该写入之后的其他内存访问开始之前。
-
rmb():读内存屏障,类似于smp_rmb(),但更强制。它提供了一个更明确和可靠的方式来防止乱序执行。
-
wmb():写内存屏障,类似于smp_wmb(),但更强制。它提供了一个更明确和可靠的方式来防止乱序执行。
-
read_barrier_depends():依赖性读栅栏,用于指示编译器不应重排与此函数相关的代码顺序。
这些内存屏障原语主要用于指示编译器和处理器不要对其前后的指令进行优化重排,以确保内存操作按照程序员预期的顺序执行。
读内存屏障(如rmb())只针对后续的读取操作有效,它告诉编译器和处理器在读取之前先确保前面的所有写入操作已经完成。类似地,写内存屏障(如wmb())只针对前面的写入操作有效,它告诉编译器和处理器在写入之后再开始后续的其他内存访问。
smp_xxx()系列的内存屏障函数主要用于多核系统中,在竞态条件下保证数据同步、一致性和正确顺序执行。在单核系统中,这些函数没有实际效果。
而read_barrier_depends()函数是一个特殊情况,在某些架构上使用它可以避免编译器对代码进行过度重排。
在x86系统上,如果支持lfence汇编指令,则rmb()(读内存屏障)的实现可能会使用lfence指令。lfence指令是一种序列化指令,它会阻止该指令之前和之后的加载操作重排,并确保所有之前的加载操作已经完成。
具体而言,在x86架构上,rmb()可能被实现为:
这个宏定义使用了GCC内联汇编语法,将lfence指令嵌入到代码中,通过volatile关键字告诉编译器不要对此进行优化,并且使用了"clobber memory"约束来通知编译器该指令可能会影响内存。
如果在x86系统上不支持lfence汇编指令,那么rmb()(读内存屏障)的实现可能会使用其他可用的序列化指令来达到相同的效果。一种常见的替代方案是使用mfence指令,它可以确保所有之前的内存加载操作已经完成。
在这种情况下,rmb()的实现可能如下:
同样,这个宏定义使用了GCC内联汇编语法,将mfence指令嵌入到代码中,并通过"clobber memory"约束通知编译器该指令可能会影响内存。
内存一致性模型
内存一致性模型是指多个处理器或多个线程之间对共享内存的读写操作所满足的一组规则和保证。
在并发编程中,由于多个处理器或线程可以同时访问共享内存,存在着数据竞争和可见性问题。为了解决这些问题,需要定义一种内存一致性模型,以规定对共享内存的读写操作应该如何进行、如何保证读写操作的正确顺序和可见性。
常见的内存一致性模型包括:
-
顺序一致性(Sequential Consistency):在顺序一致性模型下,所有的读写操作对其他处理器或线程都是按照程序顺序可见的,即每个操作都会立即对所有处理器或线程可见,并且所有处理器或线程看到的操作顺序是一致的。这种模型简单直观,但在实践中由于需要强制同步和屏障,会导致性能开销较大。
-
弱一致性模型(Weak Consistency Models):弱一致性模型允许对共享变量的读写操作可能出现乱序或重排序,但是要求满足一定的一致性条件。常见的弱一致性模型有Release-Acquire模型、Total Store Order(TSO)模型和Partial Store Order(PSO)模型等。这些模型通过使用特定的内存屏障指令或同步原语,对读写操作进行排序和同步,以实现一定程度的一致性保证。
-
松散一致性模型(Relaxed Consistency Models):松散一致性模型放宽了对共享变量读写操作顺序的限制,允许更多的重排序和乱序访问。常见的松散一致性模型有Release Consistency模型、Entry Consistency模型和Processor Consistency模型等。这些模型通过定义不同的一致性保证级别和同步原语,允许更灵活的访问和重排序,从而提高系统的并发性能。
这些序列关系的正确性和顺序一致性是通过硬件层面的内存屏障指令、缓存一致性协议和处理器乱序执行的机制来实现的。
**顺序一致性(Sequential Consistency)**模型是指内核对于多个线程或进程之间的操作顺序保持与程序代码中指定的顺序一致。简单来说,它要求内核按照程序中编写的顺序执行操作,并且对所有线程和进程都呈现出一个统一的全局视图。
在这个模型下,每个线程或进程看到的操作执行顺序必须符合以下两个条件:
-
串行语义:每个线程或进程内部的操作必须按照原始程序中的指定顺序执行,不会发生重排序。
-
全局排序:所有线程和进程之间的操作必须按照某种确定的全局排序进行。
**弱一致性(Weak Consistency)**模型是指在多个线程或进程之间,对于操作执行顺序的保证比顺序一致性模型更为宽松。在这种模型下,程序无法依赖于全局的、确定性的操作执行顺序。
弱一致性模型允许发生以下情况:
-
重排序:线程或进程内部的操作可以被重新排序,只要最终结果对外表现一致即可。
-
缓存不一致:不同线程或进程之间的缓存数据可能不及时更新,导致读取到过期数据。
-
写入写入冲突:当两个线程同时写入相同地址时,写入结果的先后顺序可能会出现变化。
**松散一致性模型(Relaxed Consistency Models)**是与多处理器系统相关的概念。它涉及到多个处理器或核心共享内存时的数据一致性问题。
在传统的严格一致性模型下,对于所有处理器/核心来说,读写操作都必须按照全局总序列进行排序。这会带来很大的开销和限制,并可能导致性能下降。
而松散一致性模型则允许部分乱序执行和缓存一致性协议的使用,以提高并行度和性能。它引入了几种松散的一致性模型,包括:
-
总线事务内存:TM允许并发线程之间通过事务进行原子操作,并尽可能避免锁竞争。这样可以提高并行度和响应速度。
-
松散记忆顺序:此模型允许处理器乱序执行指令,并通过内存屏障等机制确保特定操作的有序性。
-
内存同步原语:Linux内核提供了多种同步原语(如原子操作、自旋锁、信号量等),用于控制共享数据的访问顺序和正确同步。
对于读取(Load)和写入(Store)指令,一共有四种组合:
-
Load-Load(LL):两个读取指令之间的顺序关系。LL序列表示第一个读取操作必须在第二个读取操作之前完成才能保证顺序一致性。
-
Load-Store(LS):一个读取指令和一个写入指令之间的顺序关系。LS序列表示读取操作必须在写入操作之前完成才能保证顺序一致性。
-
Store-Load(SL):一个写入指令和一个读取指令之间的顺序关系。SL序列表示写入操作必须在读取操作之前完成才能保证顺序一致性。
-
Store-Store(SS):两个写入指令之间的顺序关系。SS序列表示第一个写入操作必须在第二个写入操作之前完成才能保证顺序一致性。
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

内存屏障的使用规则
常见的内存屏障使用场景和相应的规则:
-
在读写共享变量时,应该使用对应的读屏障和写屏障来确保读写操作的顺序和一致性。例如,在写入共享变量后,应该使用写屏障(smp_wmb())来确保写入操作已经完成,然后在读取共享变量前,应该使用读屏障(smp_rmb())来确保读取操作是在之前的写入操作之后进行的。
-
在多个 CPU 访问同一个共享变量时,应该使用内存屏障来保证正确性。例如,在使用自旋锁等同步机制时,应该在获取锁和释放锁的操作之前加上读写屏障(smp_mb())来确保操作的顺序和一致性。
-
在编写高并发性能代码时,可以使用内存屏障来优化代码的性能。例如,在使用无锁算法时,可以使用适当的内存屏障来减少 CPU 的缓存一致性花费,从而提高性能。
-
在使用内存屏障时,应该遵循先使用再优化的原则,不应该过度依赖内存屏障来解决并发问题。例如,在使用锁时,应该尽量减少锁的使用次数和持有时间,以避免竞争和饥饿等问题。
-
在选择内存屏障时,应该考虑所在的 CPU 架构和硬件平台,以选择最适合的屏障类型和实现方式。例如,在 x86 架构下,应该使用 lfence、sfence 和 mfence 指令来实现读屏障、写屏障和读写屏障。
内核中隐式的内存屏障
在 Linux 内核中,存在一些隐式的内存屏障,它们无需显式地在代码中添加,而是由编译器或硬件自动插入。这些隐式的内存屏障可以确保代码在不同的优化级别下保持正确性和一致性,同时提高代码的性能。
以下是一些常见的隐式内存屏障:
-
编译器层面的内存屏障:编译器会根据代码的语义和优化级别自动插入适当的内存屏障。例如,编译器会在函数调用前后插入内存屏障来确保函数的参数和返回值在内存中的正确性。
-
硬件层面的内存屏障:现代处理器中的指令重排和缓存一致性机制会自动插入内存屏障。例如,处理器会根据内存访问模式自动插入读写屏障,以确保读写操作的顺序和一致性。
-
内核层面的内存屏障:Linux 内核中的同步原语(如自旋锁、互斥锁)会在关键代码段中插入内存屏障,以确保多个 CPU 访问共享变量的顺序和一致性。
Linux内核有很多锁结构,这些锁结构都隐含一定的屏障操作,以确保内存的一致性和顺序性。
-
spin locks(自旋锁):在LOCK操作中会使用一个类似于原子交换的操作,确保只有一个线程能够获得锁。UNLOCK操作包括适当的内存屏障以保证对共享数据的修改可见。
-
R/W spin locks(读写自旋锁):用于实现读写并发控制。与普通自旋锁类似,在LOCK和UNLOCK操作中都包含适当的内存屏障。
-
mutexes(互斥锁):在LOCK操作中可能会使用比较和交换等原子指令,并且在UNLOCK操作中也会包含适当的屏障来保证同步和顺序性。
-
semaphores(信号量):在LOCK和UNLOCK操作中均包含适当的内存屏障来确保同步和顺序性。
-
R/W semaphores(读写信号量):与普通信号量类似,在LOCK和UNLOCK操作中都会有相应的内存屏障。
-
RCU(Read-Copy Update,读拷贝更新):RCU机制不直接使用传统意义上的锁,但它涉及到对共享数据进行访问、更新或者删除时需要进行同步操作,确保数据的一致性和顺序性。
优化屏障
在 Linux 中,"优化屏障"是通过barrier()宏定义来实现的。这个宏定义确保编译器不会对其前后的代码进行过度的优化,以保证特定的内存访问顺序和可见性。
在 GCC 编译器中,"优化屏障"的定义可以在linux-5.6.18\include\linux\compiler-gcc.h源码文件中找到。这个头文件通常包含一些与编译器相关的宏定义和内联汇编指令,用于处理一些特殊情况下需要控制代码生成和优化行为的需求。
具体而言,barrier()宏定义使用了GCC内置函数__asm__ volatile("": : :"memory")来作为一个空的内联汇编语句,并加上了"memory"约束来告知编译器,在此处需要添加一个内存屏障。
内存屏障指令
在ARM架构中,有三条内存屏障指令:
-
DMB (Data Memory Barrier):用于确保在指令执行之前的所有数据访问操作都已完成,并且写回到内存中。
-
DSB (Data Synchronization Barrier):用于确保在指令执行之前的所有数据访问操作都已完成,并且其结果可见。
-
ISB (Instruction Synchronization Barrier):用于确保在指令执行之前的所有指令已被处理器执行完毕,并清空处理器流水线。
2、原子操作
原子操作,指的是一段不可打断的执行。也就是你不可分割的操作。
在 Linux 上提供了原子操作的结构,atomic_t :
把整型原子操作定义为结构体,让原子函数只接收atomic_t类型的参数进而确保原子操作只与这种特殊类型数据一起使用,同时也保证了该类型的数据不会被传递给非原子函数。
初始化并定义一个原子变量:
atomic_t v = ATOMIC_INIT(0);
基本调用
Linux 为原子操作提供了基本的操作宏函数:
这里定义的都是通用入口,真正的操作和处理器架构体系相关,这里分析 ARM 架构体系的实现:
具体实现
对于 add 来说:
所以,这里我们需要着重分析两条汇编:
LDREX 和 STREX
LDREX和STREX指令,是将单纯的更新内存的原子操作分成了两个独立的步骤。
1)LDREX 用来读取内存中的值,并标记对该段内存的独占访问:
LDREX Rx, [Ry]
上面的指令意味着,读取寄存器Ry指向的4字节内存值,将其保存到Rx寄存器中,同时标记对Ry指向内存区域的独占访问。如果执行LDREX指令的时候发现已经被标记为独占访问了,并不会对指令的执行产生影响。
2)STREX 在更新内存数值时,会检查该段内存是否已经被标记为独占访问,并以此来决定是否更新内存中的值:
STREX Rx, Ry, [Rz]
如果执行这条指令的时候发现已经被标记为独占访问了,则将寄存器Ry中的值更新到寄存器Rz指向的内存,并将寄存器Rx设置成0。指令执行成功后,会将独占访问标记位清除。
而如果执行这条指令的时候发现没有设置独占标记,则不会更新内存,且将寄存器Rx的值设置成1。
一旦某条STREX指令执行成功后,以后再对同一段内存尝试使用STREX指令更新的时候,会发现独占标记已经被清空了,就不能再更新了,从而实现独占访问的机制。
在ARM系统中,内存有两种不同且对立的属性,即共享(Shareable)和非共享(Non-shareable)。共享意味着该段内存可以被系统中不同处理器访问到,这些处理器可以是同构的也可以是异构的。而非共享,则相反,意味着该段内存只能被系统中的一个处理器所访问到,对别的处理器来说不可见。
为了实现独占访问,ARM系统中还特别提供了所谓独占监视器(Exclusive Monitor)的东西,一共有两种类型的独占监视器。每一个处理器内部都有一个本地监视器(Local Monitor),且在整个系统范围内还有一个全局监视器(GlobalMonitor)。
如果要对非共享内存区中的值进行独占访问,只需要涉及本处理器内部的本地监视器就可以了;而如果要对共享内存区中的内存进行独占访问,除了要涉及到本处理器内部的本地监视器外,由于该内存区域可以被系统中所有处理器访问到,因此还必须要由全局监视器来协调。
对于本地监视器来说,它只标记了本处理器对某段内存的独占访问,在调用LDREX指令时设置独占访问标志,在调用STREX指令时清除独占访问标志。
而对于全局监视器来说,它可以标记每个处理器对某段内存的独占访问。也就是说,当一个处理器调用LDREX访问某段共享内存时,全局监视器只会设置针对该处理器的独占访问标记,不会影响到其它的处理器。当在以下两种情况下,会清除某个处理器的独占访问标记:
1)当该处理器调用LDREX指令,申请独占访问另一段内存时;
2)当别的处理器成功更新了该段独占访问内存值时。
对于第二种情况,也就是说,当独占内存访问内存的值在任何情况下,被任何一个处理器更改过之后,所有申请独占该段内存的处理器的独占标记都会被清空。
另外,更新内存的操作不一定非要是STREX指令,任何其它存储指令都可以。但如果不是STREX的话,则没法保证独占访问性。
现在的处理器基本上都是多核的,一个芯片上集成了多个处理器。而且对于一般的操作系统,系统内存基本上都被设置上了共享属性,也就是说对系统中所有处理器可见。因此,我们这里主要分析多核系统中对共享内存的独占访问的情况。
为了更加清楚的说明,我们可以举一个例子。假设系统中有两个处理器内核,而一个程序由三个线程组成,其中两个线程被分配到了第一个处理器上,另外一个线程被分配到了第二个处理器上。且他们的执行序列如下:
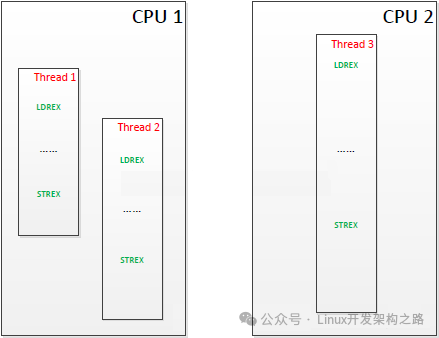
大致经历的步骤如下:
1)CPU2上的线程3最早执行LDREX,锁定某段共享内存区域。它会相应更新本地监视器和全局监视器。
2)然后,CPU1上的线程1执行LDREX,它也会更新本地监视器和全局监视器。这时在全局监视器上,CPU1和CPU2都对该段内存做了独占标记。
3)接着,CPU1上的线程2执行LDREX指令,它会发现本处理器的本地监视器对该段内存有了独占标记,同时全局监视器上CPU1也对该段内存做了独占标记,但这并不会影响这条指令的操作。
4)再下来,CPU1上的线程1最先执行了STREX指令,尝试更新该段内存的值。它会发现本地监视器对该段内存是有独占标记的,而全局监视器上CPU1也有该段内存的独占标记,则更新内存值成功。同时,清除本地监视器对该段内存的独占标记,还有全局监视器所有处理器对该段内存的独占标记。
5)下面,CPU2上的线程3执行STREX指令,也想更新该段内存值。它会发现本地监视器拥有对该段内存的独占标记,但是在全局监视器上CPU1没有了该段内存的独占标记(前面一步清空了),则更新不成功。
6)最后,CPU1上的线程2执行STREX指令,试着更新该段内存值。它会发现本地监视器已经没有了对该段内存的独占标记(第4步清除了),则直接更新失败,不需要再查全局监视器了。
所以,可以看出来,这套机制的精髓就是,无论有多少个处理器,有多少个地方会申请对同一个内存段进行操作,保证只有最早的更新可以成功,这之后的更新都会失败。失败了就证明对该段内存有访问冲突了。实际的使用中,可以重新用LDREX读取该段内存中保存的最新值,再处理一次,再尝试保存,直到成功为止。
还有一点需要说明,LDREX和STREX是对内存中的一个字(Word,32 bit)进行独占访问的指令。如果想独占访问的内存区域不是一个字,还有其它的指令:
1)LDREXB和STREXB:对内存中的一个字节(Byte,8 bit)进行独占访问;
2)LDREXH和STREXH:中的一个半字(Half Word,16 bit)进行独占访问;
3)LDREXD和STREXD:中的一个双字(Double Word,64 bit)进行独占访问。
它们必须配对使用,不能混用。
3、自旋锁
内核当发生访问资源冲突的时候,可以有两种锁的解决方案选择:
-
一个是原地等待
-
一个是挂起当前进程,调度其他进程执行(睡眠)
Spinlock 是内核中提供的一种比较常见的锁机制,自旋锁是“原地等待”的方式解决资源冲突的,即,一个线程获取了一个自旋锁后,另外一个线程期望获取该自旋锁,获取不到,只能够原地“打转”(忙等待)。由于自旋锁的这个忙等待的特性,注定了它使用场景上的限制 ——自旋锁不应该被长时间的持有(消耗 CPU 资源)。
自旋锁的使用
在linux kernel的实现中,经常会遇到这样的场景:共享数据被中断上下文和进程上下文访问,该如何保护呢?如果只有进程上下文的访问,那么可以考虑使用semaphore或者mutex的锁机制,但是现在“中断上下文”也参和进来,那些可以导致睡眠的lock就不能使用了,这时候,可以考虑使用spin lock。
这里为什么把中断上下文加引号呢?因为在中断上下文,是不允许睡眠的,所以,这里需要的是一个不会导致睡眠的锁——spinlock。
换言之,中断上下文要用锁,首选 spinlock。
使用自旋锁,有两种方式定义一个锁:
动态的:
静态的:
DEFINE_SPINLOCK(lock);
自旋锁的死锁和解决
自旋锁不可递归,自己等待自己已经获取的锁,会导致死锁。
自旋锁可以在中断上下文中使用,但是试想一个场景:一个线程获取了一个锁,但是被中断处理程序打断,中断处理程序也获取了这个锁(但是之前已经被锁住了,无法获取到,只能自旋),中断无法退出,导致线程中后面释放锁的代码无法被执行,导致死锁。(如果确认中断中不会访问和线程中同一个锁,其实无所谓)
一、考虑下面的场景(内核抢占场景):
(1)进程A在某个系统调用过程中访问了共享资源 R
(2)进程B在某个系统调用过程中也访问了共享资源 R
会不会造成冲突呢?假设在A访问共享资源R的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的B,在中断返回现场的时候,发生进程切换,B启动执行,并通过系统调用访问了R,如果没有锁保护,则会出现两个thread进入临界区,导致程序执行不正确。OK,我们加上spin lock看看如何:A在进入临界区之前获取了spin lock,同样的,在A访问共享资源R的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的B,B在访问临界区之前仍然会试图获取spin lock,这时候由于A进程持有spin lock而导致B进程进入了永久的spin……怎么破?linux的kernel很简单,在A进程获取spin lock的时候,禁止本CPU上的抢占(上面的永久spin的场合仅仅在本CPU的进程抢占本CPU的当前进程这样的场景中发生)。如果A和B运行在不同的CPU上,那么情况会简单一些:A进程虽然持有spin lock而导致B进程进入spin状态,不过由于运行在不同的CPU上,A进程会持续执行并会很快释放spin lock,解除B进程的spin状态
二、再考虑下面的场景(中断上下文场景):
(1)运行在CPU0上的进程A在某个系统调用过程中访问了共享资源 R
(2)运行在CPU1上的进程B在某个系统调用过程中也访问了共享资源 R
(3)外设P的中断handler中也会访问共享资源 R
在这样的场景下,使用spin lock可以保护访问共享资源R的临界区吗?我们假设CPU0上的进程A持有spin lock进入临界区,这时候,外设P发生了中断事件,并且调度到了CPU1上执行,看起来没有什么问题,执行在CPU1上的handler会稍微等待一会CPU0上的进程A,等它立刻临界区就会释放spin lock的,但是,如果外设P的中断事件被调度到了CPU0上执行会怎么样?CPU0上的进程A在持有spin lock的状态下被中断上下文抢占,而抢占它的CPU0上的handler在进入临界区之前仍然会试图获取spin lock,悲剧发生了,CPU0上的P外设的中断handler永远的进入spin状态,这时候,CPU1上的进程B也不可避免在试图持有spin lock的时候失败而导致进入spin状态。为了解决这样的问题,linux kernel采用了这样的办法:如果涉及到中断上下文的访问,spin lock需要和禁止本 CPU 上的中断联合使用。
三、再考虑下面的场景(底半部场景)
linux kernel中提供了丰富的bottom half的机制,虽然同属中断上下文,不过还是稍有不同。我们可以把上面的场景简单修改一下:外设P不是中断handler中访问共享资源R,而是在的bottom half中访问。使用spin lock+禁止本地中断当然是可以达到保护共享资源的效果,但是使用牛刀来杀鸡似乎有点小题大做,这时候disable bottom half就OK了
四、中断上下文之间的竞争
同一种中断handler之间在uni core和multi core上都不会并行执行,这是linux kernel的特性。
如果不同中断handler需要使用spin lock保护共享资源,对于新的内核(不区分fast handler和slow handler),所有handler都是关闭中断的,因此使用spin lock不需要关闭中断的配合。
bottom half又分成softirq和tasklet,同一种softirq会在不同的CPU上并发执行,因此如果某个驱动中的softirq的handler中会访问某个全局变量,对该全局变量是需要使用spin lock保护的,不用配合disable CPU中断或者bottom half。
tasklet更简单,因为同一种tasklet不会多个CPU上并发。
自旋锁的实现
1、文件整理
和体系结构无关的代码如下:
(1) include/linux/spinlock_types.h
这个头文件定义了通用spin lock的基本的数据结构(例如spinlock_t)和如何初始化的接口(DEFINE_SPINLOCK)。这里的“通用”是指不论SMP还是UP都通用的那些定义。
(2)include/linux/spinlock_types_up.h
这个头文件不应该直接include,在include/linux/spinlock_types.h文件会根据系统的配置(是否SMP)include相关的头文件,如果UP则会include该头文件。这个头文定义UP系统中和spin lock的基本的数据结构和如何初始化的接口。当然,对于non-debug版本而言,大部分struct都是empty的。
(3)include/linux/spinlock.h
这个头文件定义了通用spin lock的接口函数声明,例如spin_lock、spin_unlock等,使用spin lock模块接口API的驱动模块或者其他内核模块都需要include这个头文件。
(4)include/linux/spinlock_up.h
这个头文件不应该直接include,在include/linux/spinlock.h文件会根据系统的配置(是否SMP)include相关的头文件。这个头文件是debug版本的spin lock需要的。
(5)include/linux/spinlock_api_up.h
同上,只不过这个头文件是non-debug版本的spin lock需要的
(6)linux/spinlock_api_smp.h
SMP上的spin lock模块的接口声明
(7)kernel/locking/spinlock.c
SMP上的spin lock实现。
对UP和SMP上spin lock头文件进行整理:
|
UP需要的头文件 |
SMP需要的头文件 |
|---|---|
|
linux/spinlock_type_up.h: |
asm/spinlock_types.h |
2、数据结构
首先定义一个 spinlock_t 的数据类型,其本质上是一个整数值(对该数值的操作需要保证原子性),该数值表示spin lock是否可用。初始化的时候被设定为1。当thread想要持有锁的时候调用spin_lock函数,该函数将spin lock那个整数值减去1,然后进行判断,如果等于0,表示可以获取spin lock,如果是负数,则说明其他thread的持有该锁,本thread需要spin。
内核中的spinlock_t的数据类型定义如下:
通用(适用于各种arch)的spin lock使用spinlock_t这样的type name,各种arch定义自己的struct raw_spinlock。听起来不错的主意和命名方式,直到linux realtime tree(PREEMPT_RT)提出对spinlock的挑战。real time linux是一个试图将linux kernel增加硬实时性能的一个分支(你知道的,linux kernel mainline只是支持soft realtime),多年来,很多来自realtime branch的特性被merge到了mainline上,例如:高精度timer、中断线程化等等。realtime tree希望可以对现存的spinlock进行分类:一种是在realtime kernel中可以睡眠的spinlock,另外一种就是在任何情况下都不可以睡眠的spinlock。分类很清楚但是如何起名字?起名字绝对是个技术活,起得好了事半功倍,可维护性好,什么文档啊、注释啊都素那浮云,阅读代码就是享受,如沐春风。起得不好,注定被后人唾弃,或者拖出来吊打(这让我想起给我儿子起名字的那段不堪回首的岁月……)。最终,spin lock的命名规范定义如下:
(1)spinlock,在rt linux(配置了PREEMPT_RT)的时候可能会被抢占(实际底层可能是使用支持PI(优先级翻转)的mutext)。
(2)raw_spinlock,即便是配置了PREEMPT_RT也要顽强的spin
(3)arch_spinlock,spin lock是和architecture相关的,arch_spinlock是architecture相关的实现
对于UP平台,所有的arch_spinlock_t都是一样的,定义如下:
typedef struct { } arch_spinlock_t;
什么都没有,一切都是空啊。当然,这也符合前面的分析,对于UP,即便是打开的preempt选项,所谓的spin lock也不过就是disable preempt而已,不需定义什么spin lock的变量。
对于SMP平台,这和arch相关,我们在下面描述。
在具体的实现面,我们不可能把每一个接口函数的代码都呈现出来,我们选择最基础的spin_lock为例子,其他的读者可以自己阅读代码来理解。
spin_lock的代码如下:
当然,在linux mainline代码中,spin_lock和raw_spin_lock是一样的,在这里重点看看raw_spin_lock,代码如下:
UP中的实现:
SMP的实现:
UP中很简单,本质上就是一个preempt_disable而已,SMP中稍显复杂,preempt_disable当然也是必须的,spin_acquire可以略过,这是和运行时检查锁的有效性有关的,如果没有定义CONFIG_LOCKDEP其实就是空函数。如果没有定义CONFIG_LOCK_STAT(和锁的统计信息相关),LOCK_CONTENDED就是调用 do_raw_spin_lock 而已,如果没有定义CONFIG_DEBUG_SPINLOCK,它的代码如下:
__acquire和静态代码检查相关,忽略之,最终实际的获取spin lock还是要靠arch相关的代码实现。
针对 ARM 平台的 arch_spin_lock
代码位于arch/arm/include/asm/spinlock.h和spinlock_type.h,和通用代码类似,spinlock_type.h定义ARM相关的spin lock定义以及初始化相关的宏;spinlock.h中包括了各种具体的实现。
1. 回到2.6.23版本的内核中
和arm平台相关spin lock数据结构的定义如下(那时候还是使用raw_spinlock_t而不是arch_spinlock_t):
一个整数就OK了,0表示unlocked,1表示locked。配套的API包括__raw_spin_lock和__raw_spin_unlock。__raw_spin_lock会持续判断lock的值是否等于0,如果不等于0(locked)那么其他thread已经持有该锁,本thread就不断的spin,判断lock的数值,一直等到该值等于0为止,一旦探测到lock等于0,那么就设定该值为1,表示本thread持有该锁了,当然,这些操作要保证原子性,细节和exclusive版本的ldr和str(即ldrex和strexeq)相关,这里略过。立刻临界区后,持锁thread会调用__raw_spin_unlock函数是否spin lock,其实就是把0这个数值赋给lock。
这个版本的spin lock的实现当然可以实现功能,而且在没有冲突的时候表现出不错的性能,不过存在一个问题:不公平。也就是所有的thread都是在无序的争抢spin lock,谁先抢到谁先得,不管thread等了很久还是刚刚开始spin。在冲突比较少的情况下,不公平不会体现的特别明显,然而,随着硬件的发展,多核处理器的数目越来越多,多核之间的冲突越来越剧烈,无序竞争的spinlock带来的performance issue终于浮现出来,根据Nick Piggin的描述:
多么的不公平,有些可怜的thread需要饥饿的等待1000000次。本质上无序竞争从概率论的角度看应该是均匀分布的,不过由于硬件特性导致这么严重的不公平,我们来看一看硬件block:
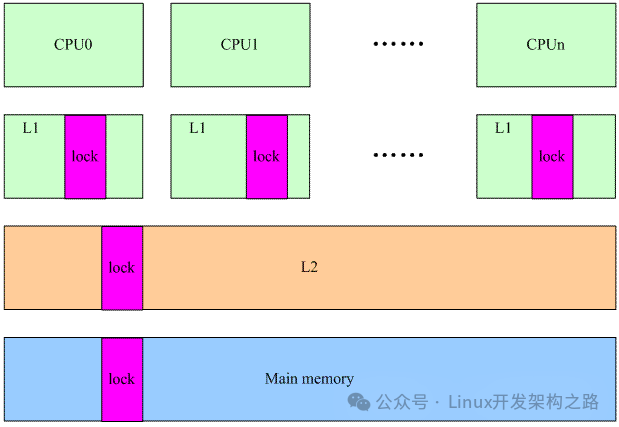
lock本质上是保存在main memory中的,由于cache的存在,当然不需要每次都有访问main memory。在多核架构下,每个CPU都有自己的L1 cache,保存了lock的数据。假设CPU0获取了spin lock,那么执行完临界区,在释放锁的时候会调用smp_mb invalide其他忙等待的CPU的L1 cache,这样后果就是释放spin lock的那个cpu可以更快的访问L1cache,操作lock数据,从而大大增加的下一次获取该spin lock的机会。
2、回到现在:arch_spinlock_t
ARM平台中的arch_spinlock_t定义如下(little endian):
本来以为一个简单的整数类型的变量就搞定的spin lock看起来没有那么简单,要理解这个数据结构,需要了解一些ticket-based spin lock的概念。如果你有机会去九毛九去排队吃饭(声明:不是九毛九的饭托,仅仅是喜欢面食而常去吃而已)就会理解ticket-based spin lock。大概是因为便宜,每次去九毛九总是无法长驱直入,门口的笑容可掬的靓女会给一个ticket,上面写着15号,同时会告诉你,当前状态是10号已经入席,11号在等待。
回到arch_spinlock_t,这里的owner就是当前已经入席的那个号码,next记录的是下一个要分发的号码。下面的描述使用普通的计算机语言和在九毛九就餐(假设九毛九只有一张餐桌)的例子来进行描述,估计可以让吃货更有兴趣阅读下去。最开始的时候,slock被赋值为0,也就是说owner和next都是0,owner和next相等,表示unlocked。当第一个个thread调用spin_lock来申请lock(第一个人就餐)的时候,owner和next相等,表示unlocked,这时候该thread持有该spin lock(可以拥有九毛九的唯一的那个餐桌),并且执行next++,也就是将next设定为1(再来人就分配1这个号码让他等待就餐)。也许该thread执行很快(吃饭吃的快),没有其他thread来竞争就调用spin_unlock了(无人等待就餐,生意惨淡啊),这时候执行owner++,也就是将owner设定为1(表示当前持有1这个号码牌的人可以就餐)。姗姗来迟的1号获得了直接就餐的机会,next++之后等于2。1号这个家伙吃饭巨慢,这是不文明现象(thread不能持有spin lock太久),但是存在。又来一个人就餐,分配当前next值的号码2,当然也会执行next++,以便下一个人或者3的号码牌。持续来人就会分配3、4、5、6这些号码牌,next值不断的增加,但是owner岿然不动,直到欠扁的1号吃饭完毕(调用spin_unlock),释放饭桌这个唯一资源,owner++之后等于2,表示持有2那个号码牌的人可以进入就餐了。
3、ARM 结构体系 arch_spin_lock 接口实现
3.1 加锁
同样的,这里也只是选择一个典型的API来分析,其他的大家可以自行学习。我们选择的是 arch_spin_lock,其ARM32的代码如下:
(0)和preloading cache相关的操作,主要是为了性能考虑
(1)lockval = lock->slock (如果lock->slock没有被其他处理器独占,则标记当前执行处理器对lock->slock地址的独占访问;否则不影响)
(2)newval = lockval + (1 << TICKET_SHIFT)
(3)strex tmp, newval, [&lock->slock] (如果当前执行处理器没有独占lock->slock地址的访问,不进行存储,返回1给temp;如果当前处理器已经独占lock->slock内存访问,则对内存进行写,返回0给temp,清除独占标记) lock->tickets.next = lock->tickets.next + 1
(4)检查是否写入成功 lockval.tickets.next
(5)初始化时lock->tickets.owner、lock->tickets.next都为0,假设第一次执行arch_spin_lock,lockval = *lock,lock->tickets.next++,lockval.tickets.next 等于 lockval.tickets.owner,获取到自旋锁;自旋锁未释放,第二次执行的时候,lock->tickets.owner = 0, lock->tickets.next = 1,拷贝到lockval后,lockval.tickets.next != lockval.tickets.owner,会执行wfe等待被自旋锁释放被唤醒,自旋锁释放时会执行 lock->tickets.owner++,lockval.tickets.owner重新赋值
(6)暂时中断挂起执行。如果当前spin lock的状态是locked,那么调用wfe进入等待状态。
(7)其他的CPU唤醒了本cpu的执行,说明owner发生了变化,该新的own赋给lockval,然后继续判断spin lock的状态,也就是回到step 5。
(8)memory barrier的操作,具体的操作后面描述。
3.1 释放锁
(0)lock->tickets.owner增加1,下一个被唤醒的处理器会检查该值是否与自己的lockval.tickets.next相等,lock->tickets.owner代表可以获取的自旋锁的处理器,lock->tickets.next你一个可以获取的自旋锁的owner;处理器获取自旋锁时,会先读取lock->tickets.next用于与lock->tickets.owner比较并且对lock->tickets.next加1,下一个处理器获取到的lock->tickets.next就与当前处理器不一致了,两个处理器都与lock->tickets.owner比较,肯定只有一个处理器会相等,自旋锁释放时时对lock->tickets.owner加1计算,因此,先申请自旋锁多处理器lock->tickets.next值更新,自然先获取到自旋锁
(1)执行sev指令,唤醒wfe等待的处理器
自旋锁的变体
|
接口API的类型 |
spinlock中的定义 |
raw_spinlock的定义 |
|---|---|---|
|
定义spin lock并初始化 |
DEFINE_SPINLOCK |
DEFINE_RAW_SPINLOCK |
|
动态初始化spin lock |
spin_lock_init |
raw_spin_lock_init |
|
获取指定的spin lock |
spin_lock |
raw_spin_lock |
|
获取指定的spin lock同时disable本CPU中断 |
spin_lock_irq |
raw_spin_lock_irq |
|
保存本CPU当前的irq状态,disable本CPU中断并获取指定的spin lock |
spin_lock_irqsave |
raw_spin_lock_irqsave |
|
获取指定的spin lock同时disable本CPU的bottom half |
spin_lock_bh |
raw_spin_lock_bh |
|
释放指定的spin lock |
spin_unlock |
raw_spin_unlock |
|
释放指定的spin lock同时enable本CPU中断 |
spin_unlock_irq |
raw_spin_unock_irq |
|
释放指定的spin lock同时恢复本CPU的中断状态 |
spin_unlock_irqstore |
raw_spin_unlock_irqstore |
|
获取指定的spin lock同时enable本CPU的bottom half |
spin_unlock_bh |
raw_spin_unlock_bh |
|
尝试去获取spin lock,如果失败,不会spin,而是返回非零值 |
spin_trylock |
raw_spin_trylock |
|
判断spin lock是否是locked,如果其他的thread已经获取了该lock,那么返回非零值,否则返回0 |
spin_is_locked |
raw_spin_is_locked |
小结
spin_lock 的时候,禁止内核抢占
如果涉及到中断上下文的访问,spin lock需要和禁止本 CPU 上的中断联合使用(spin_lock_irqsave / spin_unlock_irqstore)
涉及 half bottom 使用:spin_lock_bh / spin_unlock_bh
4、读-写自旋锁(rwlock)
试想这样一种场景:一个内核链表元素,很多进程(或者线程)都会对其进行读写,但是使用 spinlock 的话,多个读之间无法并发,只能被 spin,为了提高系统的整体性能,内核定义了一种锁:
1. 允许多个处理器进程(或者线程或者中断上下文)并发的进行读操作(SMP 上),这样是安全的,并且提高了 SMP 系统的性能。
2. 在写的时候,保证临界区的完全互斥
所以,当某种内核数据结构被分为:读-写,或者生产-消费,这种类型的时候,类似这种 读-写自旋锁就起到了作用。对读者是共享的,对写者完全互斥。
读/写自旋锁是在保护SMP体系下的共享数据结构而引入的,它的引入是为了增加内核的并发能力。只要内核控制路径没有对数据结构进行修改,读/写自旋锁就允许多个内核控制路径同时读同一数据结构。如果一个内核控制路径想对这个结构进行写操作,那么它必须首先获取读/写锁的写锁,写锁授权独占访问这个资源。这样设计的目的,即允许对数据结构并发读可以提高系统性能。
加锁的逻辑:
(1)假设临界区内没有任何的thread,这时候任何read thread或者write thread可以进入,但是只能是其一。
(2)假设临界区内有一个read thread,这时候新来的read thread可以任意进入,但是write thread不可以进入
(3)假设临界区内有一个write thread,这时候任何的read thread或者write thread都不可以进入
(4)假设临界区内有一个或者多个read thread,write thread当然不可以进入临界区,但是该write thread也无法阻止后续read thread的进入,他要一直等到临界区一个read thread也没有的时候,才可以进入。
解锁的逻辑:
(1)在write thread离开临界区的时候,由于write thread是排他的,因此临界区有且只有一个write thread,这时候,如果write thread执行unlock操作,释放掉锁,那些处于spin的各个thread(read或者write)可以竞争上岗。
(2)在read thread离开临界区的时候,需要根据情况来决定是否让其他处于spin的write thread们参与竞争。如果临界区仍然有read thread,那么write thread还是需要spin(注意:这时候read thread可以进入临界区,听起来也是不公平的)直到所有的read thread释放锁(离开临界区),这时候write thread们可以参与到临界区的竞争中,如果获取到锁,那么该write thread可以进入。
读-写自旋锁的使用
与 spinlock 的使用方式几乎一致,读-写自旋锁初始化方式也分为两种:
动态的:
静态的:
DEFINE_RWLOCK(rwlock);
初始化完成后就可以使用读-写自旋锁了,内核提供了一组 APIs 来操作读写自旋锁,最简单的比如:
读临界区:
写临界区:
注意:读锁和写锁会位于完全分开的代码中,若是:
这样会导致死锁,因为读写锁的本质还是自旋锁。写锁不断的等待读锁的释放,导致死锁。如果读-写不能清晰的分开的话,使用一般的自旋锁,就别使用读写锁了。
注意:由于读写自旋锁的这种特性(允许多个读者),使得即便是递归的获取同一个读锁也是允许的。更比如,在中断服务程序中,如果确定对数据只有读操作的话(没有写操作),那么甚至可以使用 read_lock 而不是 read_lock_irqsave,但是对于写来说,还是需要调用 write_lock_irqsave 来保证不被中断打断,否则如果在中断中去获取了锁,就会导致死锁。
读-写锁内核 APIs
与 spinlock 一样,Read/Write spinlock 有如下的 APIs:
|
接口API描述 |
Read/Write Spinlock API |
|---|---|
|
定义rw spin lock并初始化 |
DEFINE_RWLOCK |
|
动态初始化rw spin lock |
rwlock_init |
|
获取指定的rw spin lock |
read_lock |
|
获取指定的rw spin lock同时disable本CPU中断 |
read_lock_irq |
|
保存本CPU当前的irq状态,disable本CPU中断并获取指定的rw spin lock |
read_lock_irqsave |
|
获取指定的rw spin lock同时disable本CPU的bottom half |
read_lock_bh |
|
释放指定的spin lock |
read_unlock |
|
释放指定的rw spin lock同时enable本CPU中断 |
read_unlock_irq |
|
释放指定的rw spin lock同时恢复本CPU的中断状态 |
read_unlock_irqrestore |
|
获取指定的rw spin lock同时enable本CPU的bottom half |
read_unlock_bh |
|
尝试去获取rw spin lock,如果失败,不会spin,而是返回非零值 |
read_trylock |
读-写锁内核实现
说明:使用读写内核锁需要包含的头文件和 spinlock 一样,只需要包含:include/linux/spinlock.h 就可以了
这里仅看 和体系架构相关的部分,在 ARM 体系架构上:
arch_rwlock_t 的定义:
看看arch_write_lock的实现:
(0) : 先通知 hw 进行preloading cache
(1): 标记独占,获取 rw->lock 的值并保存在 tmp 中
(2) : 判断 tmp 是否等于 0
(3) : 如果 tmp 不等于0,那么说明有read 或者write的thread持有锁,那么还是静静的等待吧。其他thread会在unlock的时候Send Event来唤醒该CPU的
(4) : 如果 tmp 等于0,将 0x80000000 这个值赋给 rw->lock
(5) : 是否 str 成功,如果有其他 thread 在上面的过程插入进来就会失败
(6) : 如果不成功,那么需要重新来过跳转到标号为 1 的地方,即开始的地方,否则持有锁,进入临界区
(7) : 内存屏障,保证执行顺序
arch_write_unlock 的实现:
(0) : 内存屏障
(1) : rw->lock 赋值为 0
(2) :唤醒处于 WFE 的 thread
arch_read_lock 的实现:
(0) : 标记独占,获取 rw->lock 的值并保存在 tmp 中
(1) : tmp = tmp + 1
(2) : 如果 tmp 结果非负值,那么就执行该指令,将 tmp 值存入rw->lock
(3) : 如果 tmp 是负值,说明有 write thread,那么就进入 wait for event 状态
(4) : 判断strexpl指令是否成功执行
(5) : 如果不成功,那么需要重新来过,否则持有锁,进入临界区
arch_read_unlock 的实现:
(0) : 标记独占,获取 rw->lock 的值并保存在 tmp 中
(1) : read 退出临界区,所以,tmp = tmp + 1
(2) : 将tmp值存入 rw->lock 中
(3) :是否str成功,如果有其他thread在上面的过程插入进来就会失败
(4) : 如果不成功,那么需要重新来过,否则离开临界区
(5) : 如果read thread已经等于0,说明是最后一个离开临界区的 Reader,那么调用 sev 去唤醒 WF E的 CPU Core(配合 Writer 线程)
所以看起来,读-写锁使用了一个 32bits 的数来存储当前的状态,最高位代表着是否有写线程占用了锁,而低 31 位代表可以同时并发的读的数量,看起来现在至少是绰绰有余了。
小结
读-写锁自旋锁本质上还是属于自旋锁。只不过允许了并发的读操作,对于写和写,写和读之间,都需要互斥自旋等待。
注意读-写锁自旋锁的使用,避免死锁。
合理运用内核提供的 APIs (诸如:write_lock_irqsave 等)。
5、顺序锁(seqlock)
上面讲到的读-写自旋锁,更加偏向于读者。内核提供了更加偏向于写者的锁 —— seqlock
这种锁提供了一种简单的读写共享的机制,他的设计偏向于写者,无论是什么情况(没有多个写者竞争的情况),写者都有直接写入的权利(霸道),而读者呢?这里提供了一个序列值,当写者进入的时候,这个序列值会加 1,而读者去在读出数值的前后分别来check这个值,便知道是否在读的过程中(奇数还偶数),被写者“篡改”过数据,如果有的话,则再次 spin 的去读,一直到数据被完全的篡改完毕。
顺序锁临界区只允许一个writer thread进入(在多个写者之间是互斥的),临界区只允许一个writer thread进入,在没有writer thread的情况下,reader thread可以随意进入,也就是说reader不会阻挡reader。在临界区只有有reader thread的情况下,writer thread可以立刻执行,不会等待
Writer thread的操作:
对于writer thread,获取seqlock操作如下:
(1)获取锁(例如spin lock),该锁确保临界区只有一个writer进入。
(2)sequence counter加一
释放seqlock操作如下:
(1)释放锁,允许其他writer thread进入临界区。
(2)sequence counter加一(注意:不是减一哦,sequence counter是一个不断累加的counter)
由上面的操作可知,如果临界区没有任何的writer thread,那么sequence counter是偶数(sequence counter初始化为0),如果临界区有一个writer thread(当然,也只能有一个),那么sequence counter是奇数。
Reader thread的操作如下:
(1)获取sequence counter的值,如果是偶数,可以进入临界区,如果是奇数,那么等待writer离开临界区(sequence counter变成偶数)。进入临界区时候的sequence counter的值我们称之old sequence counter。
(2)进入临界区,读取数据
(3)获取sequence counter的值,如果等于old sequence counter,说明一切OK,否则回到step(1)
适用场景:
一般而言,seqlock适用于:
(1)read操作比较频繁
(2)write操作较少,但是性能要求高,不希望被reader thread阻挡(之所以要求write操作较少主要是考虑read side的性能)
(3)数据类型比较简单,但是数据的访问又无法利用原子操作来保护。我们举一个简单的例子来描述:假设需要保护的数据是一个链表,header--->A node--->B node--->C node--->null。reader thread遍历链表的过程中,将B node的指针赋给了临时变量x,这时候,中断发生了,reader thread被preempt(注意,对于seqlock,reader并没有禁止抢占)。这样在其他cpu上执行的writer thread有充足的时间释放B node的memory(注意:reader thread中的临时变量x还指向这段内存)。当read thread恢复执行,并通过x这个指针进行内存访问(例如试图通过next找到C node),悲剧发生了……
顺序锁的使用
定义
定义一个顺序锁有两种方式:
DEFINE_SEQLOCK(seqlock)
写临界区:
读临界区:
例子:在 kernel 中,jiffies_64 保存了从系统启动以来的 tick 数目,对该数据的访问(以及其他jiffies相关数据)需要持有jiffies_lock 这个 seq lock:
读当前的 tick :
内核更新当前的 tick :
顺序锁的实现
1. seqlock_t 结构:
2. write_seqlock/write_sequnlock
可以看到 seqlock 其实也是基于 spinlock 的。smp_wmb 是写内存屏障,由于seq lock 是基于 sequence counter 的,所以必须保证这个操作。
3. read_seqbegin:
如果有writer thread,read_seqbegin函数中会有一个不断polling sequenc counter,直到其变成偶数的过程,在这个过程中,如果不加以控制,那么整体系统的性能会有损失(这里的性能指的是功耗和速度)。因此,在polling过程中,有一个cpu_relax的调用,对于ARM64,其代码是:
yield指令用来告知硬件系统,本cpu上执行的指令是polling操作,没有那么急迫,如果有任何的资源冲突,本cpu可以让出控制权。
4. read_seqretry
start参数就是进入临界区时候的sequenc counter的快照,比对当前退出临界区的sequenc counter,如果相等,说明没有writer进入打搅reader thread,那么可以愉快的离开临界区。
还有一个比较有意思的逻辑问题:read_seqbegin为何要进行奇偶判断?把一切都推到read_seqretry中进行判断不可以吗?也就是说,为何read_seqbegin要等到没有writer thread的情况下才进入临界区?其实有writer thread也可以进入,反正在read_seqretry中可以进行奇偶以及相等判断,从而保证逻辑的正确性。当然,这样想也是对的,不过在performance上有欠缺,reader在检测到有writer thread在临界区后,仍然放reader thread进入,可能会导致writer thread的一些额外的开销(cache miss),因此,最好的方法是在read_seqbegin中拦截。
6、信号量(semaphore)
Linux Kernel 除了提供了自旋锁,还提供了睡眠锁,信号量就是一种睡眠锁。信号量的特点是,如果一个任务试图获取一个已经被占用的信号量,他会被推入等待队列,让其进入睡眠。此刻处理器重获自由,去执行其他的代码。当持有的信号量被释放,处于等待队列的任务将被唤醒,并获取到该信号量。
从信号量的睡眠特性得出一些结论:
-
由于竞争信号量的时候,未能拿到信号的进程会进入睡眠,所以信号量可以适用于长时间持有。
-
而且信号量不适合短时间的持有,因为会导致睡眠的原因,维护队列,唤醒,等各种开销,在短时间的锁定某对象,反而比忙等锁的效率低。
-
由于睡眠的特性,只能在进程上下文进行调用,无法再中断上下文中使用信号量。
-
一个进程可以在持有信号量的情况下去睡眠(可能并不需要,这里只是假如),另外的进程尝试获取该信号量时候,不会死锁。
-
期望去占用一个信号量的同时,不允许持有自旋锁,因为企图去获取信号量的时候,可能导致睡眠,而自旋锁不允许睡眠。
在有一些特定的场景,自旋锁和信号量没得选,比如中断上下文,只能用自旋锁,比如需要要和用户空间做同步的时候,代码需要睡眠,信号量是唯一选择。如果有的地方,既可以选择信号量,又可以选自旋锁,则需要根据持有锁的时间长短来进行选择。理想情况下是,越短的时间持有,选择自旋锁,长时间的适合信号量。与此同时,信号量不会关闭调度,他不会对调度造成影响。
信号量允许多个锁持有者,而自旋锁在一个时刻,最多允许一个任务持有。信号量同时允许的持有者数量可以在声明信号的时候指定。绝大多数情况下,信号量允许一个锁的持有者,这种类型的信号量称之为二值信号量,也就是互斥信号量。
一个任务要想访问共享资源,首先必须得到信号量,获取信号量的操作将把信号量的值减1,若当前信号量的值为负数,表明无法获得信号量,该任务必须挂起在该信号量的等待队列等待该信号量可用;若当前信号量的值为非负数,表示可以获得信号量,因而可以立刻访问被该信号量保护的共享资源。
当任务访问完被信号量保护的共享资源后,必须释放信号量,释放信号量通过把信号量的值加1实现,如果信号量的值为非正数,表明有任务等待当前信号量,因此它也唤醒所有等待该信号量的任务。
信号量的操作
信号量相关的东西放置到了: include/linux/semaphore.h 文件
初始化一个信号量有两种方式:
DEFINE_SEMAPHORE(sem)
内核针对信号量提供了一组操作接口:
|
函数定义 |
功能说明 |
|---|---|
|
sema_init(struct semaphore *sem, int val) |
初始化信号量,将信号量计数器值设置val。 |
|
down(struct semaphore *sem) |
获取信号量,不建议使用此函数,因为是 UNINTERRUPTABLE 的睡眠。 |
|
down_interruptible(struct semaphore *sem) |
可被中断地获取信号量,如果睡眠被信号中断,返回错误-EINTR。 |
|
down_killable (struct semaphore *sem) |
可被杀死地获取信号量。如果睡眠被致命信号中断,返回错误-EINTR。 |
|
down_trylock(struct semaphore *sem) |
尝试原子地获取信号量,如果成功获取,返回0,不能获取,返回1。 |
|
down_timeout(struct semaphore *sem, long jiffies) |
在指定的时间jiffies内获取信号量,若超时未获取,返回错误-ETIME。 |
|
up(struct semaphore *sem) |
释放信号量sem。 |
注意:down_interruptible 接口,在获取不到信号量的时候,该任务会进入 INTERRUPTABLE 的睡眠,但是 down() 接口会导致进入 UNINTERRUPTABLE 的睡眠,down 用的较少。
信号量的实现
1. 信号量的结构:
信号量用结构semaphore描述,它在自旋锁的基础上改进而成,它包括一个自旋锁、信号量计数器和一个等待队列。用户程序只能调用信号量API函数,而不能直接访问信号量结构。
2. 初始化函数sema_init
初始化了信号量中的 spinlock 结构,count 计数器和初始化链表。
3. 可中断获取信号量函数down_interruptible
down_interruptible进入后,获取信号量获取成功,进入临界区,否则进入 __down_interruptible->__down_common
加入到等待队列,将状态设置成为 TASK_INTERRUPTIBLE , 并设置了调度的 Timeout : MAX_SCHEDULE_TIMEOUT
在调用了 schedule_timeout,使得进程进入了睡眠状态。
4. 释放信号量函数 up
如果等待队列为空,即,没有睡眠的进程期望获取这个信号量,则直接 count++,否则调用 __up:
取出队列中的元素,进行唤醒操作。
7、互斥体(mutex)
互斥体是一种睡眠锁,他是一种简单的睡眠锁,其行为和 count 为 1 的信号量类似。
互斥体简洁高效,但是相比信号量,有更多的限制,因此对于互斥体的使用条件更加严格:
-
任何时刻,只有一个指定的任务允许持有 mutex,也就是说,mutex 的计数永远是 1;
-
给 mutex 上锁这,必须负责给他解锁,也就是不允许在一个上下文中上锁,在另外一个上下文中解锁。这个限制注定了 mutex 无法承担内核和用户空间同步的复杂场景。常用的方式是在一个上下文中进行上锁/解锁。
-
递归的调用上锁和解锁是不允许的。也就是说,不能递归的去持有同一个锁,也不能够递归的解开一个已经解开的锁。
-
当持有 mutex 的进程,不允许退出
-
mutex 不允许在中断上下文和软中断上下文中使用过,即便是mutex_trylock 也不行
-
mutex 只能使用内核提供的 APIs操作,不允许拷贝,手动初始化和重复初始化
信号量和互斥体
他们两者很相似,除非是 mutex 的限制妨碍到逻辑,否则这两者之间,首选 mutex
自旋锁和互斥体
多数情况,很好区分。中断中只能考虑自旋锁,任务睡眠使用互斥体。如果都可以的的情况下,低开销或者短时间的锁,选择自旋锁,长期加锁的话,使用互斥体。
互斥体的使用
|
函数定义 |
功能说明 |
|
mutex_lock(struct mutex *lock) |
加锁,如果不可用,则睡眠(UNINTERRUPTIBLE) |
|
mutex_lock_interruptible(struct mutex *lock); |
加锁,如果不可用,则睡眠(TASK_INTERRUPTIBLE) |
|
mutex_unlock(struct mutex *lock) |
解锁 |
|
mutex_trylock(struct mutex *lock) |
试图获取指定的 mutex,或得到返回1,否则返回 0 |
|
mutex_is_locked(struct mutex *lock) |
如果 mutex 被占用返回1,否则返回 0 |
互斥体的实现
互斥体的定义在:include/linux/mutex.h
1. mutex 的结构
2. mutex 初始化
3. mutex 加锁
首先check是否能够获得锁,否则调用到 __mutex_lock_slowpath:
所以调用到了 __mutex_lock_common 函数:
进入等待队列。
4. mutex 解锁
调用到 __mutex_unlock_slowpath :
做唤醒操作。
8、RCU机制
RCU 的全称是(Read-Copy-Update),意在读写-复制-更新,在Linux提供的所有内核互斥的设施当中属于一种免锁机制。在之前讨论过的读写自旋锁(rwlock)、顺序锁(seqlock)一样,RCU 的适用模型也是读写共存的系统。
-
读写自旋锁:读者和写者互斥,读者和读者共存,写者和写者互斥。(偏向读者)
-
顺序锁:写者和写者互斥,写者直接打断读者(偏向写者)
上述两种都是基于 spinlock 的一种用于特定场景的锁机制。
RCU 与他们不同,它的读取和写入操作无需考虑两者之间的互斥问题。
之前的锁分析中,可以知道,加锁、解锁都涉及内存操作,同时伴有内存屏障引入,这些都会导致锁操作的系统开销变大,在此基础之上, 内核在Kernel的 2.5 版本引入了 RCU 的免锁互斥访问机制。
什么叫免锁机制呢?对于被RCU保护的共享数据结构,读者不需要获得任何锁就可以访问它,但写者在访问它时首先拷贝一个副本,然后对副本进行修改,最后使用一个回调(callback)机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据。这个时机就是所有引用该数据的CPU都退出对共享数据的操作。
因此RCU实际上是一种改进的 rwlock,读者几乎没有什么同步开销,它不需要锁,不使用原子指令。不需要锁也使得使用更容易,因为死锁问题就不需要考虑了。写者的同步开销比较大,它需要延迟数据结构的释放,复制被修改的数据结构,它也必须使用某种锁机制同步并行的其它写者的修改操作。读者必须提供一个信号给写者以便写者能够确定数据可以被安全地释放或修改的时机。有一个专门的垃圾收集器来探测读者的信号,一旦所有的读者都已经发送信号告知它们都不在使用被RCU保护的数据结构,垃圾收集器就调用回调函数完成最后的数据释放或修改操作。
RCU与rwlock的不同之处是:它既允许多个读者同时访问被保护的数据,又允许多个读者和多个写者同时访问被保护的数据(注意:是否可以有多个写者并行访问取决于写者之间使用的同步机制),读者没有任何同步开销,而写者的同步开销则取决于使用的写者间同步机制。但RCU不能替代rwlock,因为如果写比较多时,对读者的性能提高不能弥补写者导致的损失。
读者在访问被RCU保护的共享数据期间不能被阻塞,这是RCU机制得以实现的一个基本前提,也就说当读者在引用被RCU保护的共享数据期间,读者所在的CPU不能发生上下文切换,spinlock和rwlock都需要这样的前提。写者在访问被RCU保护的共享数据时不需要和读者竞争任何锁,只有在有多于一个写者的情况下需要获得某种锁以与其他写者同步。写者修改数据前首先拷贝一个被修改元素的副本,然后在副本上进行修改,修改完毕后它向垃圾回收器注册一个回调函数以便在适当的时机执行真正的修改操作。等待适当时机的这一时期称为宽限期 grace period,而CPU发生了上下文切换称为经历一个quiescent state,grace period就是所有CPU都经历一次quiescent state所需要的等待的时间(读的时候禁止了内核抢占,也就是上下文切换,如果在某个 CPU 上发生了进程切换,那么所有对老指针的引用都会结束之后)。垃圾收集器就是在grace period之后调用写者注册的回调函数(call_rcu 函数注册回调)来完成真正的数据修改或数据释放操作的。
总的来说,RCU的行为方式:
1、随时可以拿到读锁,即对临界区的读操作随时都可以得到满足
2、某一时刻只能有一个人拿到写锁,多个写锁需要互斥,写的动作包括 拷贝--修改--宽限窗口到期后删除原值
3、临界区的原始值为m1,如会有人拿到写锁修改了临界区为m2,则在写锁修改临界区之后拿到的读锁获取的临界区的值为m2,之前获取的为m1,这通过原子操作保证
对比发现RCU读操作随时都会得到满足,但写锁之后的写操作所耗费的系统资源就相对比较多了,并且只有在宽限期之后删除原资源。
针对对象
RCU 保护的对象是指针。这一点尤其重要.因为指针赋值是一条单指令.也就是说是一个原子操作.因它更改指针指向没必要考虑它的同步.只需要考虑cache的影响。
内核中所有关于 RCU 的操作都应该使用内核提供的 RCU 的 APIs 函数完成,这些 APIs 主要集中在指针和链表的操作。
使用场景
RCU 使用在读者多而写者少的情况.RCU和读写锁相似.但RCU的读者占锁没有任何的系统开销.写者与写写者之间必须要保持同步,且写者必须要等它之前的读者全部都退出之后才能释放之前的资源
读者是可以嵌套的.也就是说rcu_read_lock()可以嵌套调用
从 RCU 的特性可知,RCU 的读取性能的提升是在增加写入者负担的前提下完成的,因此在一个读者与写者共存的系统中,按照设计者的说法,如果写入者的操作比例在 10% 以上,那么久应该考虑其他的互斥方法,反正,使用 RCU 的话,能够获取较好的性能。
使用限制
读者在访问被RCU保护的共享数据期间不能被阻塞。
在读的时候,会屏蔽掉内核抢占。
RCU 的实现原理
在RCU的实现过程中,我们主要解决以下问题:
1,在读取过程中,另外一个线程删除了一个节点。删除线程可以把这个节点从链表中移除,但它不能直接销毁这个节点,必须等到所有的读取线程读取完成以后,才进行销毁操作。RCU中把这个过程称为宽限期(Grace period)。
2,在读取过程中,另外一个线程插入了一个新节点,而读线程读到了这个节点,那么需要保证读到的这个节点是完整的。这里涉及到了发布-订阅机制(Publish-Subscribe Mechanism)。
3, 保证读取链表的完整性。新增或者删除一个节点,不至于导致遍历一个链表从中间断开。但是RCU并不保证一定能读到新增的节点或者不读到要被删除的节点。
1. 宽限期
通过例子,方便理解这个内容。以下例子修改于Paul的文章:
如上的程序,是针对于全局变量gbl_foo的操作。假设以下场景。有两个线程同时运行foo_ read和foo_update的时候,当foo_ read执行完赋值操作后,线程发生切换;此时另一个线程开始执行foo_update并执行完成。当foo_ read运行的进程切换回来后,运行dosomething的时候,fp 已经被删除,这将对系统造成危害。为了防止此类事件的发生,RCU里增加了一个新的概念叫宽限期(Grace period)。如下图所示:
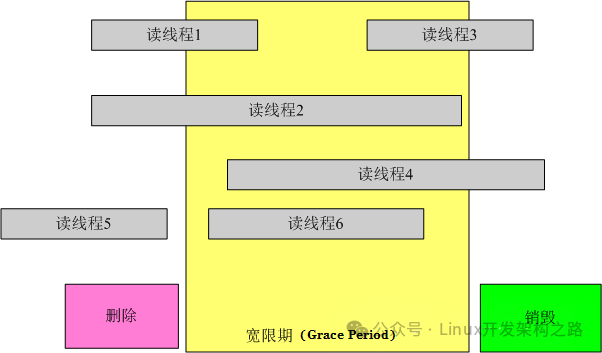
图中每行代表一个线程,最下面的一行是删除线程,当它执行完删除操作后,线程进入了宽限期。宽限期的意义是,在一个删除动作发生后,它必须等待所有在宽限期开始前已经开始的读线程结束,才可以进行销毁操作。这样做的原因是这些线程有可能读到了要删除的元素。图中的宽限期必须等待1和2结束;而读线程5在宽限期开始前已经结束,不需要考虑;而3,4,6也不需要考虑,因为在宽限期结束后开始后的线程不可能读到已删除的元素。为此RCU机制提供了相应的API来实现这个功能。
用 RCU:
其中 foo_ read 中增加了 rcu_read_lock 和 rcu_read_unlock,这两个函数用来标记一个RCU读过程的开始和结束。其实作用就是帮助检测宽限期是否结束。foo_update 增加了一个函数 synchronize_rcu(),调用该函数意味着一个宽限期的开始,而直到宽限期结束,该函数才会返回。我们再对比着图看一看,线程1和2,在 synchronize_rcu 之前可能得到了旧的 gbl_foo,也就是 foo_update 中的 old_fp,如果不等它们运行结束,就调用 kfee(old_fp),极有可能造成系统崩溃。而3,4,6在synchronize_rcu 之后运行,此时它们已经不可能得到 old_fp,此次的kfee将不对它们产生影响。
宽限期是RCU实现中最复杂的部分,原因是在提高读数据性能的同时,删除数据的性能也不能太差。
2. 订阅——发布机制
当前使用的编译器大多会对代码做一定程度的优化,CPU也会对执行指令做一些优化调整,目的是提高代码的执行效率,但这样的优化,有时候会带来不期望的结果。如例:
这段代码中,我们期望的是6,7,8行的代码在第10行代码之前执行。但优化后的代码并不对执行顺序做出保证。在这种情形下,一个读线程很可能读到 new_fp,但new_fp的成员赋值还没执行完成。当读线程执行dosomething(fp->a, fp->b , fp->c ) 的 时候,就有不确定的参数传入到dosomething,极有可能造成不期望的结果,甚至程序崩溃。可以通过优化屏障来解决该问题,RCU机制对优化屏障做了包装,提供了专用的API来解决该问题。这时候,第十行不再是直接的指针赋值,而应该改为 :
rcu_assign_pointer(gbl_foo,new_fp);
<include/linux/rcupdate.h> 中 rcu_assign_pointer的实现比较简单,如下:
我们可以看到它的实现只是在赋值之前加了优化屏障 smp_wmb来确保代码的执行顺序。另外就是宏中用到的__rcu,只是作为编译过程的检测条件来使用的。
<include/linux/rcupdate.h>
这段代码中加入了调试信息,去除调试信息,可以是以下的形式(其实这也是旧版本中的代码):
在赋值后加入优化屏障smp_read_barrier_depends()。
我们之前的第四行代码改为 foo *fp = rcu_dereference(gbl_foo);,就可以防止上述问题。
3. 数据读取的完整性
还是通过例子来说明这个问题:
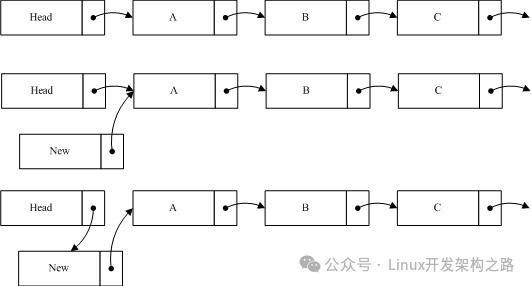
如图我们在原list中加入一个节点new到A之前,所要做的第一步是将new的指针指向A节点,第二步才是将Head的指针指向new。这样做的目的是当插入操作完成第一步的时候,对于链表的读取并不产生影响,而执行完第二步的时候,读线程如果读到new节点,也可以继续遍历链表。如果把这个过程反过来,第一步head指向new,而这时一个线程读到new,由于new的指针指向的是Null,这样将导致读线程无法读取到A,B等后续节点。从以上过程中,可以看出RCU并不保证读线程读取到new节点。如果该节点对程序产生影响,那么就需要外部调用做相应的调整。如在文件系统中,通过RCU定位后,如果查找不到相应节点,就会进行其它形式的查找,相关内容等分析到文件系统的时候再进行叙述。
我们再看一下删除一个节点的例子:
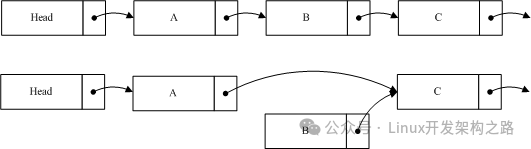
如图我们希望删除B,这时候要做的就是将A的指针指向C,保持B的指针,然后删除程序将进入宽限期检测。由于B的内容并没有变更,读到B的线程仍然可以继续读取B的后续节点。B不能立即销毁,它必须等待宽限期结束后,才能进行相应销毁操作。由于A的节点已经指向了C,当宽限期开始之后所有的后续读操作通过A找到的是C,而B已经隐藏了,后续的读线程都不会读到它。这样就确保宽限期过后,删除B并不对系统造成影响。
如何使用 RCU
除了上一节使用 RCU 的例子,这一节在贴一个使用 RCU 的例子:
Reader Code :
Writer Code :
在上面的例子,写者调用 rcu_assign_pointer 更新老指针后,使用 call_rcu 接口,向系统注册了一会回调函数,系统在确定没有对老指针引用之后,调用这个函数。另一个类似的函数是上一节遇到的 synchronize_rcu 调用,这个函数可能会阻塞,因为他要等待所有对老指针的引用全部结束才返回,函数返回的时候意味着系统所有对老指针的引用都消失,此时在释放老指针才是安全的。如果在中断上下文执行写入者的操作,那么就应该使用 call_rcu ,不能使用 synchronize_rcu。
对于这 call_rcu 和 synchronize_rcu 的分析如下:
在释放老指针方面,Linux内核提供两种方法供使用者使用,一个是调用call_rcu,另一个是调用synchronize_rcu。前者是一种异步 方式,call_rcu会将释放老指针的回调函数放入一个结点中,然后将该结点加入到当前正在运行call_rcu的处理器的本地链表中,在时钟中断的 softirq部分(RCU_SOFTIRQ), rcu软中断处理函数rcu_process_callbacks会检查当前处理器是否经历了一个休眠期(quiescent,此处涉及内核进程调度等方面的内容),rcu的内核代码实现在确定系统中所有的处理器都经历过了一个休眠期之后(意味着所有处理器上都发生了一次进程切换,因此老指针此时可以被安全释放掉了),将调用call_rcu提供的回调函数。
synchronize_rcu的实现则利用了等待队列,在它的实现过程中也会向call_rcu那样向当前处理器的本地链表中加入一个结点,与 call_rcu不同之处在于该结点中的回调函数是wakeme_after_rcu,然后synchronize_rcu将在一个等待队列中睡眠,直到系统中所有处理器都发生了一次进程切换,因而wakeme_after_rcu被rcu_process_callbacks所调用以唤醒睡眠的 synchronize_rcu,被唤醒之后,synchronize_rcu知道它现在可以释放老指针了。 所以我们看到,call_rcu返回后其注册的回调函数可能还没被调用,因而也就意味着老指针还未被释放,而synchronize_rcu返回后老指针肯定被释放了。所以,是调用call_rcu还是synchronize_rcu,要视特定需求与当前上下文而定,比如中断处理的上下文肯定不能使用 synchronize_rcu函数了。
基本RCU操作 APIs
对于reader,RCU的操作包括:
(1)rcu_read_lock:用来标识RCU read side临界区的开始。
(2)rcu_dereference:该接口用来获取RCU protected pointer。reader要访问RCU保护的共享数据,当然要获取RCU protected pointer,然后通过该指针进行dereference的操作。
(3)rcu_read_unlock:用来标识reader离开RCU read side临界区
对于writer,RCU的操作包括:
(1)rcu_assign_pointer:该接口被writer用来进行removal的操作,在witer完成新版本数据分配和更新之后,调用这个接口可以让RCU protected pointer指向RCU protected data。
(2)synchronize_rcu:writer端的操作可以是同步的,也就是说,完成更新操作之后,可以调用该接口函数等待所有在旧版本数据上的reader线程离开临界区,一旦从该函数返回,说明旧的共享数据没有任何引用了,可以直接进行reclaimation的操作。
(3)call_rcu:当然,某些情况下(例如在softirq context中),writer无法阻塞,这时候可以调用call_rcu接口函数,该函数仅仅是注册了callback就直接返回了,在适当的时机会调用callback函数,完成reclaimation的操作。这样的场景其实是分开removal和reclaimation的操作在两个不同的线程中:updater和reclaimer。
RCU 的链表操作:
在 Linux kernel 中还专门提供了一个头文件(include/linux/rculist.h),提供了利用 RCU 机制对链表进行增删查改操作的接口。
(1) list_add_rcu :该函数把链表项new插入到RCU保护的链表head的开头。使用内存栅保证了在引用这个新插入的链表项之前,新链表项的链接指针的修改对所有读者是可见的。
static inline void list_add_rcu(struct list_head *new, struct list_head *head)
(2) list_add_tail_rcu:该函数类似于list_add_rcu,它将把新的链表项new添加到被RCU保护的链表的末尾。
static inline void list_add_tail_rcu(struct list_head *new, struct list_head *head)
(3) list_del_rcu:该函数从RCU保护的链表中移走指定的链表项entry,并且把entry的prev指针设置为LIST_POISON2,但是并没有把entry的next指针设置为LIST_POISON1,因为该指针可能仍然在被读者用于便利该链表。
static inline void list_del_rcu(struct list_head *entry)
(4) list_replace_rcu:该函数是RCU新添加的函数,并不存在非RCU版本。它使用新的链表项new取代旧的链表项old,内存栅保证在引用新的链表项之前,它的链接指针的修正对所有读者可见
(5) list_for_each_entry_rcu:该宏用于遍历由RCU保护的链表head
 0
0










