
一、深入理解IO
1、什么是操作系统IO
I/O,即输入(input)和输出(output),也可以理解为读(Read)和写(Write);
I/O模式可以划分为本地IO,模型(内存、磁盘)和网络IO模型;
I/O关系到用户空间和内核空间的转换,也称为用户缓冲区和内核缓冲区;
用户态的应用程序不能直接操作内核空间,需要将数据从内核空间拷贝到用户空间才能使用。
read和write操作,都只能在内核空间里执行,磁盘IO和网络IO请求都是先放在内核空间,然后加载到用户态内存的数据。
2、IO读写性能差距实操
我们可以发现,参数的不同,会导致磁盘IO速度的不同:
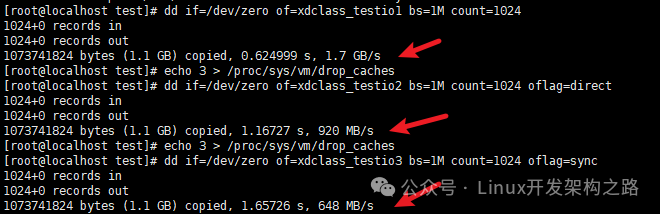
没有oflag参数时,文件复制速度是oflag=direct的数倍:默认是buffered I/O,数据写到缓存层便返回,所以速度最快。
oflag=direct的速度比oflag=sync快一些:数据写到磁盘缓存便返回,但是速度比buffered I/O慢一些。
oflag=sync的速度最慢:写入的数据全部落盘才返回,所以速度比上面的仅写到磁盘缓存慢。
物理磁盘也会带有缓存disk cache,用于提高I/O速度,一般磁盘中带有电容,断电也能把缓存数据刷写到磁盘中。
3、什么是文件系统
(1)简介
在Linux系统中,一切皆是文件,文件系统管理磁盘上的全部文件,文件管理组织方式多种多样,所以文件系统存在多样化。
系统把文件持久化存储在磁盘上,文件系统就会实现文件数据的查询和存储。
文件系统是管理数据,而存储数据的物理设备有硬盘、U盘、SD卡、网络存储设备等。
不同的存储设备其物理结构不同,不同的物理结构就需要不同的文件系统去管理。
比如说,Windows有FAT12、FAT16、FAT32、NTFS、exFAT等文件系统;Linux有Ext2、Ext3、Ext4、tmpfs、NFS等文件系统。
(2)索引节点和目录项
索引节点(index):
简称inode,记录文件的元信息,比如文件大小、访问权限、修改日期、数据存储位置等;
索引节点也需要持久化存储,占用磁盘空间。
目录项(directory entry):
简称为dentry,记录目录结构,比如文件的名字、索引节点和其他目录项的关联关系登,树状结构居多;
存储在内存中,也叫目录项缓存。
(3)什么是虚拟文件系统VFS(Virtual File System)
操作系统上有那么多的文件系统和物理存储介质,就是靠着虚拟文件系统为各类文件系统提供统一的接口进行交互,应用程序调用读写位于不同物理介质上的不同文件系统。
虚拟文件系统在应用程序和具体的文件系统之间引入了一个抽象层,开发者不用关心底层的存储介质和文件系统类型就可以使用。
(4)Linux的IO存储栈
https://www.thomas-krenn.com/en/wiki/Linux_Storage_Stack_Diagram
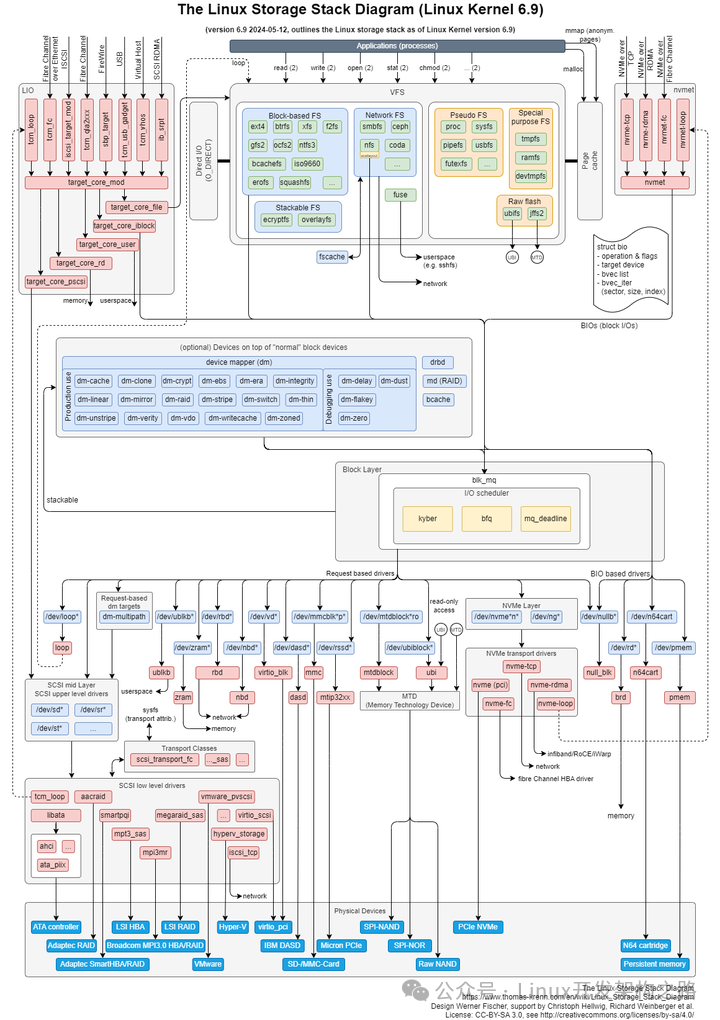
上面的总图实在太复杂,简单总结一下:
平时调用write的时候,数据是从应用写入到了C标准库的IO Buffer(用户态),这个Buffer在应用内存中,应用挂了,数据就没了;
在关闭流之前调用flush,通过flush将数据主动写入到内核的Page Cache中,应用挂了,数据也安全(内核态),但是系统挂了数据就没了;
将内核中的Page Cache中的数据写入到磁盘(缓存)中,系统挂了,数据也不丢失,需要调用fsync(持久化介质)。
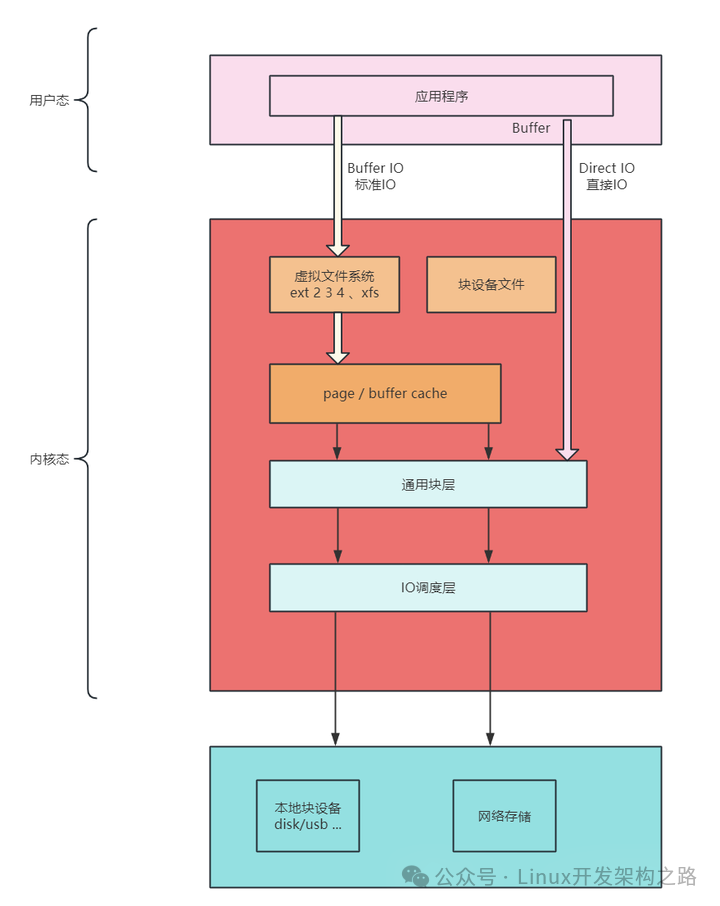
总体来说,这就是操作系统的多级缓存和数据的可用性。操作系统也是程序,靠着多线程、异步、多级缓存实现高性能。
我们日常的业务开发,也可以借鉴这种思想。
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
二、深入理解磁盘
1、机械硬盘
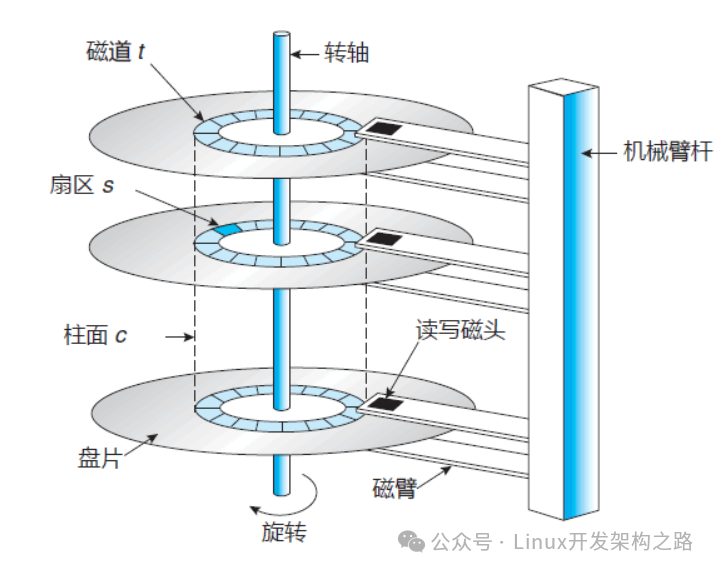
(1)结构

机械硬盘(HDD)组成结构很多,重点关注磁盘、磁头臂、磁头,每个硬盘的正反两面都有对应的磁头。
数据存储在盘片的环状磁道中,最小读写单位是扇区(sector),一般大小为512字节,这样的话读写单位太小,性能不高。
文件系统把连续的扇区组成逻辑块(block),以逻辑块为最小单元来管理数据。
一般逻辑块大小为4KB,是由连续的8个扇区组成。
(2)如何读取数据
磁臂摆动+盘片转动(耗时大所以导致慢,随机在硬盘上找一个数据,需要8-14ms),定位到目标扇区读取数据;
磁臂在一定范围内摆动,来找到目标扇区,靠磁头把某个扇区的数据传输到总线上;
磁臂摆动范围有限,触达不到比较远的扇区,靠转轴来转动盘片,比如磁盘转速有7200转/分,1秒就是120圈;
常规1秒可以做100次随机IO,所以高并发业务单靠磁盘是扛不住的,基本都要结合缓存;
机械硬盘想要优化,就不能用随机IO,要用顺序IO,节省大量的物理耗时,比如Kafka、RockerMQ都是使用顺序IO。
2、磁盘读写常见指标
(1)IOPS(Input/Output Operations per Second)
指每秒能处理的I/O个数,表示块存储处理读写(输出/输入)的能力,单位为次,有顺序IOPS和随机IOPS。
阿里云盘性能参考: 高效云盘:2120 IOPS; ESSD云盘:2280 IOPS; SSD云盘:3000IOPS。
(2)吞吐量/带宽(Throughput)
是指单位时间内可以成功传输的数据数量,单位为MB/s。
比如一个硬盘的读写IO是1MB,硬盘的IOPS是100,那么硬盘总的吞吐率就是100MB/S,带宽=IOPS*IO大小。
如果需要部署大量顺序读写的应用,例如Hadoop离线计算型业务等典型场景,需要关注吞吐量。
(3)访问时延(Latency)
是指IO请求从发出到收到响应的间隔时间,常以毫秒(ms)或者微秒(us)为单位;
硬盘响应时间 = 硬盘访问时间 + IO排队延迟;
过高的时延会导致应用性能下降或报错;
如果应用对高时延比较敏感,例如数据库应用,建议使用ESSD AutoPL云盘、SSD云盘或本地SSD盘类产品;
普通的HDD磁盘,随机IO读写延迟是10毫秒,IO带宽大约100MB/秒,随机IOPS一般在100左右。
(4)容量(Capacity)
是指存储空间大小,单位为TiB、GiB、Mib、Kib,块存储容量按照二进制单位计算:
1B(byte字节)=8bit
1KB(Kilobyte千字节) = 1024B
1MB(Megabyte兆字节,简称兆) = 1024KB
1GB(Gigabyte吉字节,简称“千兆”) = 1024MB
1TB(Terabyte万亿字节,简称“太字节”) = 1024GB
1PB(Petabyte千万亿字节,简称“拍字节”) = 1024TB
1EB(Exabyte百亿亿字节,简称“艾字节”) = 1024PB
(5)使用率(Utilization)
指磁盘处理I/O的时间百分比,过高的使用率,常规字段Utilization-缩写%util表示;
如果超过80%意味着磁盘I/O存在性能瓶颈。
(6)IO等待队列长度(Queue Length)
表示等待处理的I/O请求的数目,如果I/O请求压力持续超出磁盘处理能力,就会增大队列长度。
(7)饱和度
指磁盘处理I/O的繁忙程度,过高的饱和度说明磁盘存在严重的性能瓶颈。
当饱和度为100%时,磁盘无法接受新的IO请求。
注意,使用率和饱和度是完全不同的,使用率只考虑有没有IO,不考虑IO的大小;当使用率是100%时,磁盘也可能接收新的IO请求。
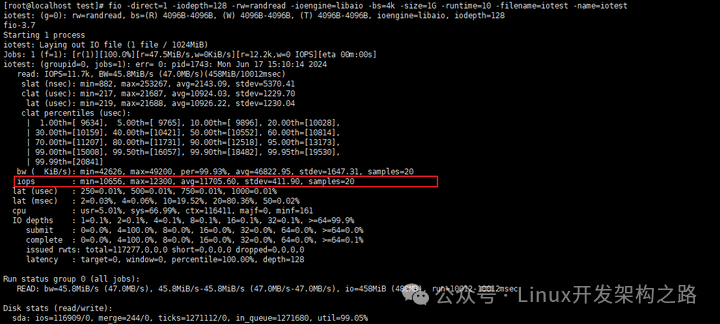
3、磁盘IOPS性能测试
(1)安装fio
yum install -y fio
(2)使用
|
参数 |
说明 |
|---|---|
|
filename |
待测试的文件或块设备 |
|
ioengin |
IO引擎fio支持多种引擎,例如:cpuio、mmap、sync、psync、filecreate、libaio等 |
|
iodepth |
表示使用AIO时,同时发出I/O数的上限为128 |
|
direct |
是否采用直接IO(direct IO)方式进行读写 |
|
rw |
读写模式 |
|
numjobs |
测试进程的并发数,比如-numjobs=16 |
|
bs |
单次IO的大小,比如-bs=4k |
|
size |
测试文件的大小,比如-size=1G |
|
sync |
设置同步模式,同步-sync=1,异步-sync=0 |
|
runtime |
设置测试运行的时间,单位秒,比如-runtime=100 |
|
group_reporting |
结果把多线程汇总输出 |
4、固态硬盘SSD
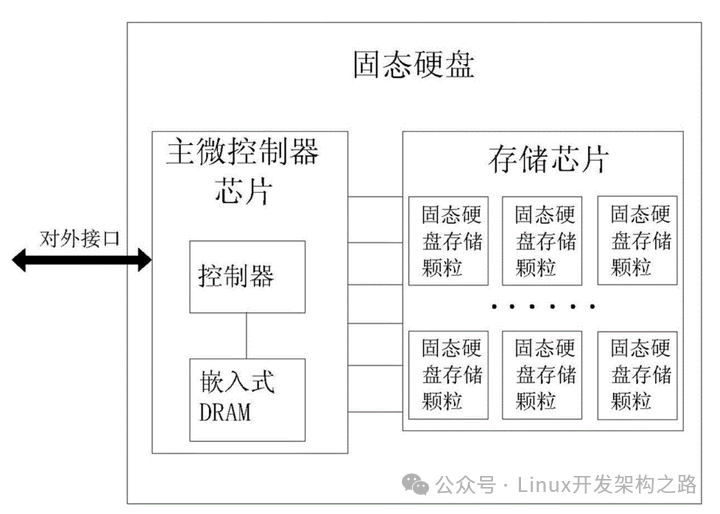
(1)结构
固态硬盘由固态电子元器组成,没有盘片、磁臂等机械部件,不需要磁道寻址,靠电容存储数据。
某块区域存在数据,机械硬盘写入可以直接覆盖,而固态硬盘需要先擦除,再写入,block块擦的越多寿命越短,业务数据高频更新,则不太建议使用固态硬盘。
最小读写单位是页,通常大小是4KB、8KB。
性能高,IOPS可以达到几万以上,价格比机械硬盘贵,寿命较短。
固态硬盘由多个裸片叠加组成,一个裸片有多个块,一个块有很多的页,一个页的大小通常是4KB。
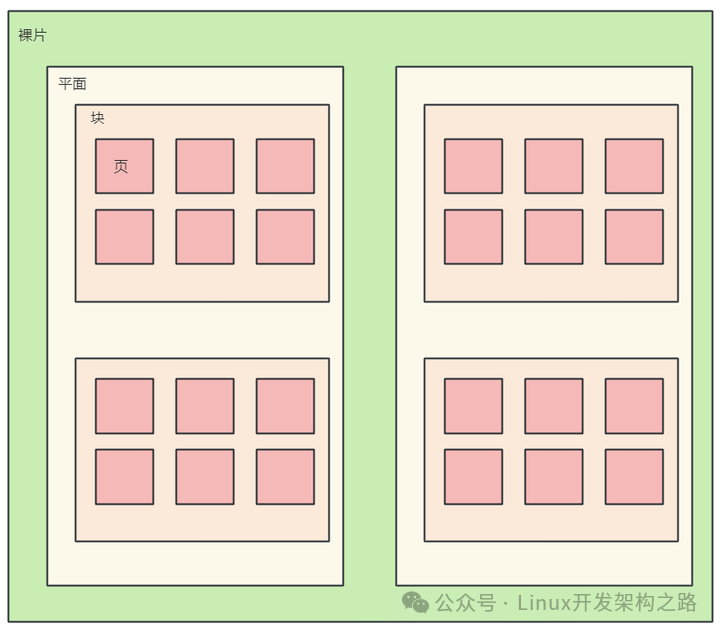
(2)磁盘数据的擦写
SSD里面最小读写单位是page,但是最小擦除单位是block。
一个块上的某些页的数据被标记删除,不能直接擦除这些的页,除非整个块上的页都被标记删除;
块还有其他有效数据,当有新数据只能写入白色区域,并不能利用红色区域,时间越长,不能被使用的碎片越多。
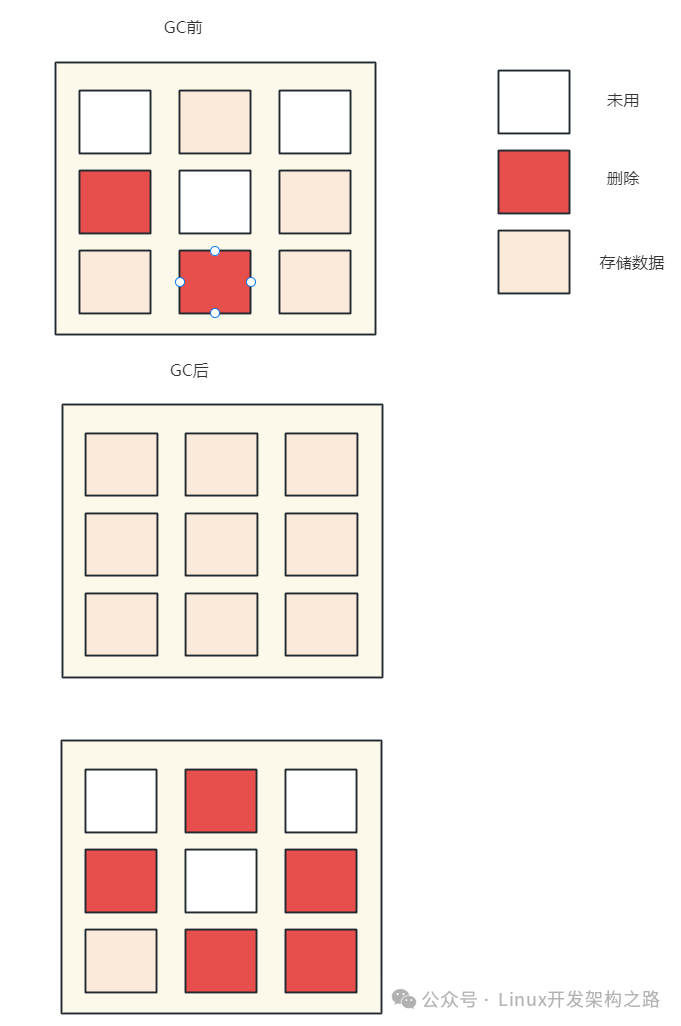
GC(Garbagecollection)垃圾回收:
有一套标记整理机制程序,“有效”页数据复制到一个“空白”块里,然后把这个块完全擦除;
那些被移动出数据的块上面的页要么没数据,要么是标记删除的数据,直接对这个块进行擦除;
擦除数据类似JVM的GC,使用标记整理算法Mark Compact。(先对对象进行一个标记,看看哪些对象是垃圾;整理会在清除的过程中,把可用的对象向前移动,让内存更为紧凑,避免内存碎片的产生;整理之后发现内存更紧凑,连续的空间更多,就不会造成内存碎片的问题)
5、磁盘分区
(1)概念
计算机中存放信息的主要存储设备就是硬盘,但是硬盘不能直接使用,必须对硬盘进行分割成一块块的硬盘区域就是磁盘分区。
磁盘分区(比如windows的C、D、E盘),方便管理、提升系统的效率和做好存储空间隔离分配:
将系统中的程序数据按不同的使用分为几类,将不同类型的数据分别存放在不同的磁盘分区中;
在每个分区上存放的都是相似的数据或程序,这样管理和维护就容易多;
分区可以提升系统的效率,系统读写磁盘时,磁头移动的距离缩短了,即搜寻的范围小了;
如果不运用分区,每次在硬盘上寻找信息时可能要寻找整个硬盘,所以速度会很慢。
磁盘分区,允许在一个磁盘上有多个文件系统,每个分区可以分配不同的文件系统;
从而使操作系统可以识别每个分区的文件系统,从而实现文件的存储和管理;
创建硬盘分区后,还不能立即使用,还需要创建文件系统,即格式化;
格式化后常见的磁盘格式有:FAT(FAT16)、FAT32、NTFS、ext2、ext3等。
(2)硬盘分区类型
不同类型磁盘支持分区的数量有限制。
主分区:主直接在硬盘上划分的,一个硬盘可以有1到3个主分区和1个扩展分区。
扩展分区:是一个概念,实际在硬盘中是看不到的,也无法直接使用扩展分区,在扩展分区中建立逻辑分区。
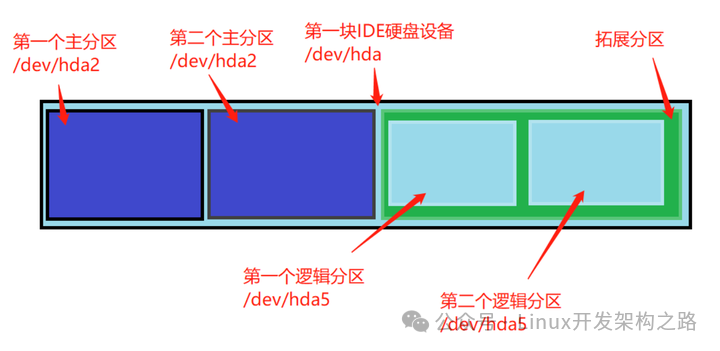
(3)容量
硬盘的容量 = 主分区的容量 + 扩展分区的容量
扩展分区的容量 = 各个逻辑分区的容量之和
(4)Linux系统下磁盘分区设备名称
|
设备 |
介绍 |
设备在Linux中的文件名 |
|---|---|---|
|
IDE硬盘Hard Disk |
Integrated Drive Electronics电子集成驱动器 |
/dev/hd[字母递增][数字递增] |
|
SCSI光盘Solid Disk |
Small Computer System Interface 小型计算机系统接口 |
/dev/sd[字母递增][数字递增] |
|
virtio虚拟磁盘Virtual Disk |
/dev/vd虚拟磁盘分区,一般用于在虚拟机上扩展存储空间 |
/dev/vd[字母递增][数字递增] |
注:字母表示硬盘,数字代表硬盘的分区 比如:/dev/hda1表示第一块硬盘的第一个分区
(5)管理磁盘分区
6、磁盘高可用:磁盘冗余阵列
(1)简介
磁盘阵列高可用方案 - 独立磁盘冗余阵列(RAID - Redundant Array of Independent Disks)。
是一种提供高可用性和数据容错性的数据存储技术,把几块硬盘组成一个阵列,并将它们的数据分布在不同的磁盘上。
在磁盘发生故障时保护数据,还可以提高I/O性能,使系统能够更快地完成任务。
简单来说,就是把相同的数据存储在多个硬盘的不同的地方,储存冗余数据增加了容错性。
根据性能、容量、可靠性,有多个级别,比如RAID0、RAID1、RAID5、RAID10。
(2)RAID0磁盘阵列
至少需要两块硬盘,磁盘越多,读写速度越快,读写速度约等于一个磁盘的吞吐量 * 磁盘数,没有冗余。
这种方案磁盘利用率100%,安全性最低,一块硬盘出现故障就会导致数据损坏。
读写性能好。
(类似redis、mongodb的数据分片存储)
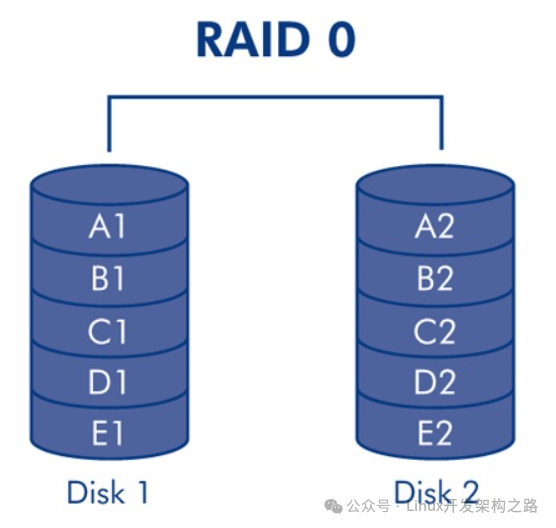
(3)RAID1镜像阵列
全部数据都分别复制到多块硬盘上,当其中一块硬盘出现故障时,另一块硬盘的数据可以被立即使用,从而保证数据的安全性。
每次写入数据时都会同时写入镜像盘,读写性能较低,只能用两块硬盘,一块硬盘冗余,磁盘利用率为50%。
优点是数据冗余性高,缺点是读写性能比一般硬盘差。
适合服务器、数据库存储等领域。
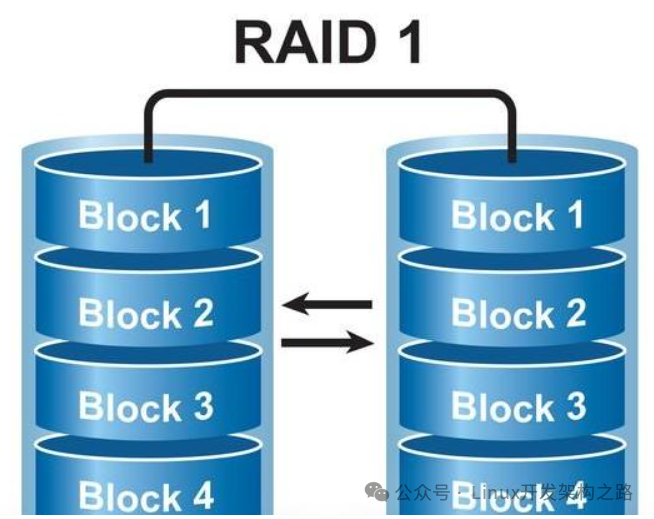
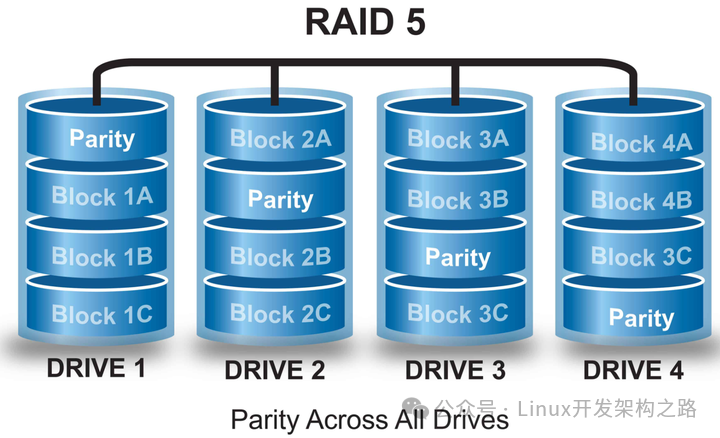
(4)RAID5条带阵列
至少需要3块磁盘,一块磁盘冗余,是将多块磁盘按特定顺序组合起来,是最通用流行的配置方式。
在每块磁盘上都会存储1份数据和1份校验信息,1块硬盘出现故障时,根据另外2块磁盘的校验信息可以恢复数据。
这种存储方式只允许有一块硬盘出现故障,出现故障时需要尽快更换。
综合了RAID0和RAID1的优点和缺点,是RAID0和RAID1的折中方案。
适合需要安全和成本兼顾的领域,性能要求稍高,比如金融数据库存储。
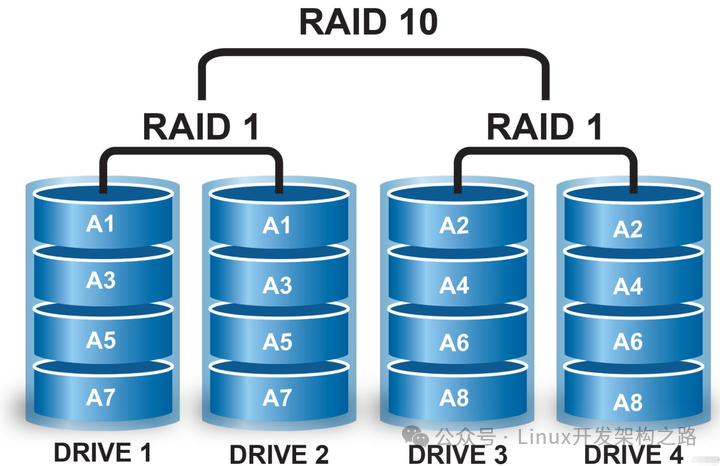
(5)RAID10、RAID50
安全性和读写性能高,但是价格昂贵。
7、磁盘IO性能分析
(1)iostat
sysstat提供了Linux性能监控的工具集,包括iostat、mpstat、pidstat、sar等。
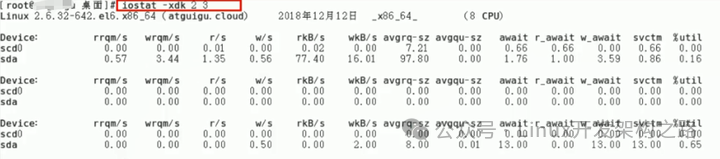
iostat查看系统综合的磁盘IO情况
|
字段 |
说明 |
|---|---|
|
【重要】r/s |
每秒发送给磁盘的读请求次数,r/s+w/s 是磁盘 IOPS |
|
【重要】w/s |
每秒发送给磁盘的写请求次数,r/s+w/s 是磁盘IOPS |
|
【重要】rkB/s |
每秒从磁盘读取的数据量,rkB/s+wkB/s 是吞吐量 |
|
【重要】wkB/s |
每秒向磁盘写入的数据量,rkB/s+wkB/s 是吞吐量 |
|
【重要】r_await |
读请求处理完成等待时间,包括在队列中的等待时间和设备实际处理时间 |
|
【重要】w_await |
写请求处理完成等待时间,包括在队列中的等待时间和设备实际处理时间 |
|
【重要】aqu-sz |
平均请求队列长度 |
|
rareq-Sz |
平均读请求大小 |
|
wareg-Sz |
平均写请求大小 |
|
【重要】%util |
磁盘处理I/O的时间百分比,表示的是磁盘的忙碌情况;如果>80%就是磁盘可能处于忙碌状态 |
(2)iotop
参数:
-o:只显示正在读写磁盘的程序 -d:跟一个数值,表示iotop命令刷新时间
三、深入理解操作系统IO底层
1、DMA(Direct Memory Access)
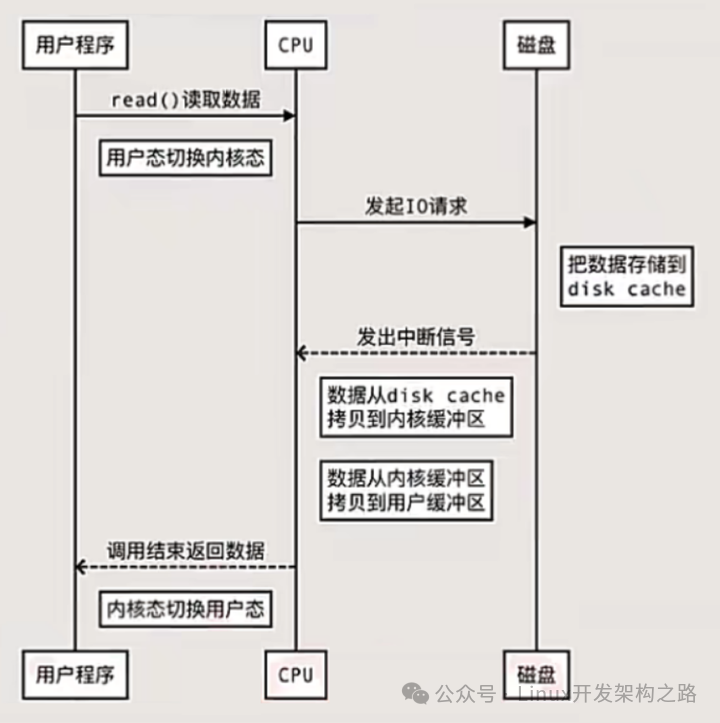
(1)应用程序从磁盘读写数据的时序图(未用DMA技术)
我们发现,应用程序如果想从磁盘读取数据,CPU会发生两次上下文的切换,并且数据会进行两次拷贝。
(2)使用DMA(Direct Memory Access)直接内存访问
直接内存访问,直接内存访问是计算机科学中的一种内存访问技术。
DMA之前,要把外设的数据读入内存或把内存的数据传送到外设,一般都要通过CPU控制完成,利用中断技术。
DMA允许某些硬件系统能够独立于CPU直接读写操作系统的内存,不需要CPU介入处理。
数据传输操作在一个DMA控制器(DMAC)的控制下进行,在传输过程中CPU可以继续进行其它的工作。
在大部分时间CPU和I/O操作都处于并行状态,系统的效率更高。
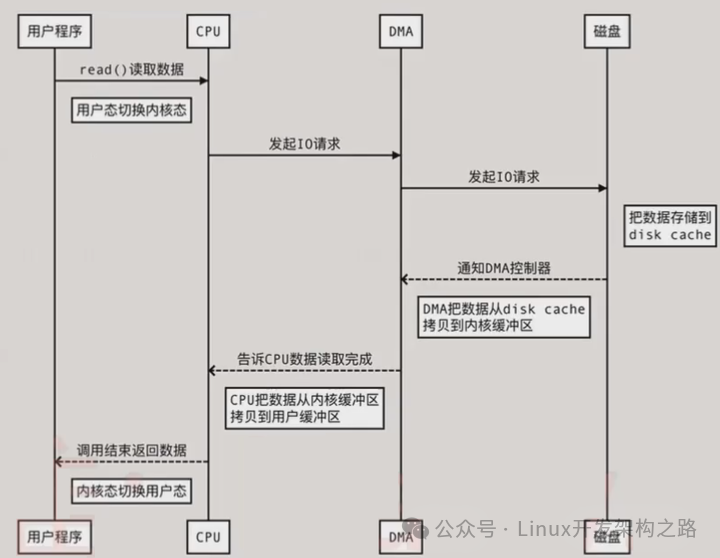
此时,如果是读数据:
1、操作系统检查内核缓冲区读取,如果存在则直接把内核空间的数据copy到用户空间(CPU处理),应用程序即可使用。
2、如果内核缓冲区没数据,则从磁盘中读取文件数据到内核缓冲区(DMA处理),再把内核空间的数据copy到用户空间(CPU处理),应用程序即可使用。
3、硬盘 ->内核缓冲区 ->用户缓冲区。
写操作:
根据操作系统的写入方式不一样,buffer IO和direct IO,写入磁盘时机不一样。
buffer IO:应用程序把数据从用户空间copy到内核空间的缓冲区(CPU处理),再把内核缓冲区的数据写到磁盘(DMA处理)。
direct IO:应用程序把数据直接从用户态地址空间写入到磁盘中,直接跳过内核空间缓冲区,减少操作系统缓冲区和用户地址空间的拷贝次数,降低了CPU和内存开销。
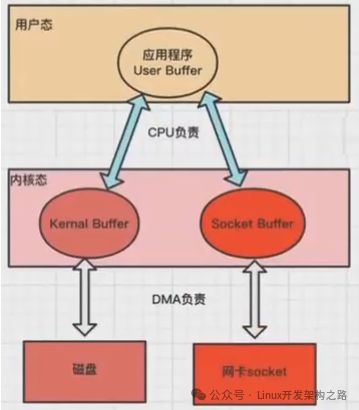
读网络数据:
网卡Socket(类似磁盘)中读取客户端发送的数据到内核空间(DMA处理),再把内核空间的数据copy到用户空间(CPU处理),然后应用程序使用。
写网络数据:
用户缓冲区中的数据copy到内核缓冲区的Socket Buffer中(CPU处理),再将内核空间中的Socket BUffer拷贝到Socket协议栈(网卡设备)进行传输(DMA处理)。
(3)DMA技术里面的损耗
(读)从磁盘的缓冲区到内核缓冲区的拷贝工作; (读)从网卡设备到内核的socket buffer的拷贝工作; (写)从内核缓冲区到磁盘缓冲区的拷贝工作; (写)从内核的socket buffer到网卡设备的拷贝工作。
所以,内核缓冲区到用户缓冲区之间的拷贝工作仍然由CPU负责。
以下是应用程序从磁盘读取文件到发送到网络的流程,程序先read数据,然后write网络,其中包含四次内核态和用户态的切换、四次缓冲区的拷贝:
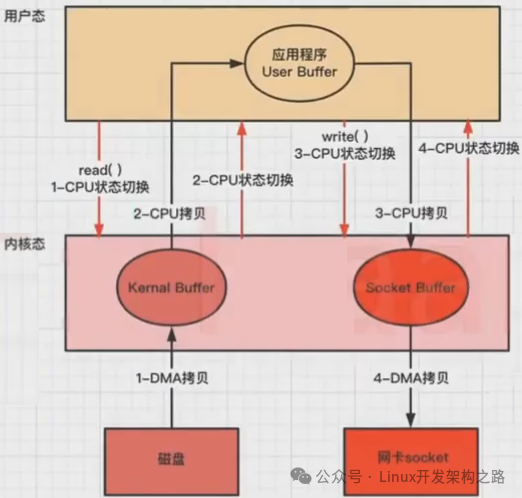
DMA技术虽然能提高一部分性能,但是仍然有一些不必要的资源损耗,其中包括CPU的用户态和内核态的切换、CPU内存拷贝的消耗。
2、零拷贝
(1)概念
零拷贝旨在减少不必要的内核缓冲区跟用户缓冲区之间的拷贝工作,从而减少CPU的开销和减少了kernel和user模式的上下文切换,提升性能。
从磁盘中读取文件通过网络发送出去,只需要拷贝2/3次和2/4的内核态和用户态的切换即可。
ZeroCopy技术实现有两种(内核态和用户态切换次数不一样):
方式一:mmap + write;
方式二:sendfile。
(2)mmap实现
mmap+write是ZeroCopy的实现方式之一。
操作系统都使用虚拟内存,虚拟地址通过多级页表来映射物理地址,多个虚拟内存可以指向同一个物理地址,虚拟内存的总空间远大于物理内存空间。
如果把内核空间和用户空间的虚拟地址映射到同一个物理地址,就不需要来回复制数据了。
mmap系统调用函数会直接把内核缓冲区里的数据映射到用户空间,这样内核空间和用户空间就不需要进行数据拷贝操作,节省了CPU开销。
相关函数(C):mmap()读取,write()写出。
还是以应用程序从磁盘读取文件到发送到网络的流程为例,步骤:
1、应用程序先调用mmap()方法,将数据从磁盘拷贝到内核缓冲区,返回结束(DMA负责);
2、再调用write(),内核缓冲区的数据直接拷贝到内核socket buffer(CPU负责);
3、然后把内核缓冲区的Socket Buffer直接拷贝给Socket协议栈,即网卡设备中,返回结束(DMA负责)。
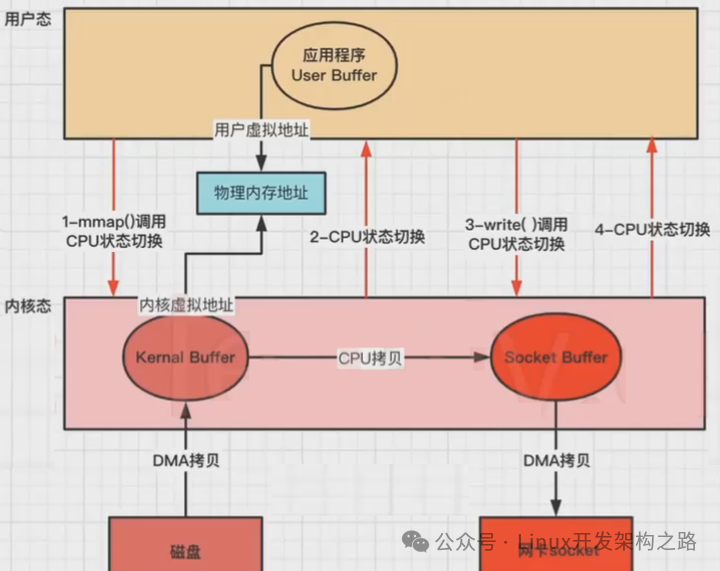
没用零拷贝时,发生4次CPU上下文切换和4次数据拷贝。
使用mmap,CPU用户态和内核态上下文切换仍然是4次,和3次数据拷贝(2次DMA拷贝,1次CPU拷贝)。
减少了1次CPU拷贝(只有内核之间有一次拷贝。)
(3)sendfile实现
sendfile是ZeroCopy的另一种实现方式。
Linux kernal 2.1新增了一个发送文件的系统调用函数sendfile()。
替代read()和write()两个系统调用,减少一次系统调用,即减少2次CPU上下文切换的开销。
调用sendfile(),从磁盘读取数据到内核缓冲区,然后直接把内核缓冲区的数据拷贝到socket buffer缓冲区里,再把内核缓冲区的Socket Buffer直接拷贝给Socket协议栈,即网卡设备中(DMA负责)。
相关函数(C):sendfile()
还是以应用程序从磁盘读取文件到发送到网络的流程为例,步骤:
1、应用程序先调用sendfile()方法,将数据从磁盘拷贝到内核缓冲区(DMA负责);
2、然后把内核缓冲区的数据直接拷贝到内核socket buffer(CPU负责);
3、然后把内核缓冲区的Socket Buffer直接拷贝给Socket协议栈,即网卡设备中,返回结束(DMA负责)。
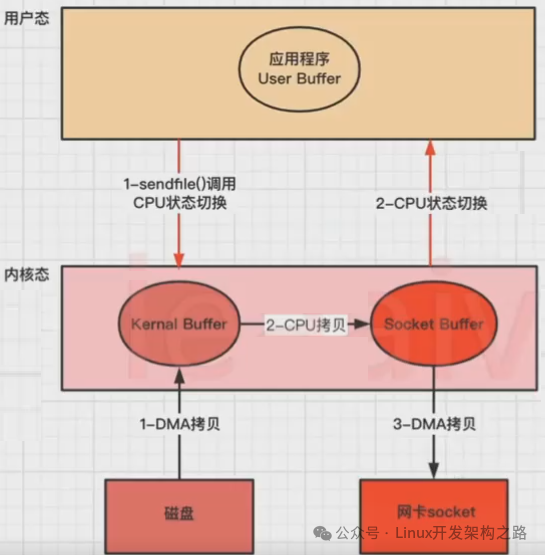
没用零拷贝时,发生4次CPU上下文切换和4次数据拷贝。
使用sendfile(),CPU用户态和内核态上下文切换是2次,3次数据拷贝(2次DMA拷贝,1次CPU拷贝)。
(4)改进的sendfile
linux2.4+版本之后改进了sendfile,利用DMA Gather(带有收集功能的DMA),变成了真正的零拷贝(没有CPU Copy)。
还是以应用程序从磁盘读取文件到发送到网络的流程为例,步骤:
1、应用程序先调用sendfile()方法,将数据从磁盘拷贝到内核缓冲区(DMA负责);
2、把内存地址、偏移量的缓冲区fd描述符 拷贝到Socket Buffer中去,(拷贝很少的数据,可忽略,本质和虚拟内存的解决方法思路一样,就是内存地址的记录);
3、然后把内核缓冲区的Socket Buffer直接拷贝给Socket协议栈,即网卡设备中,返回结束(DMA负责)。
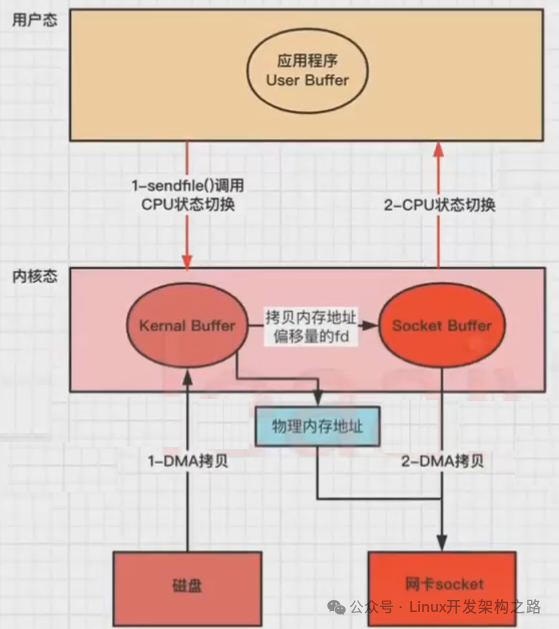
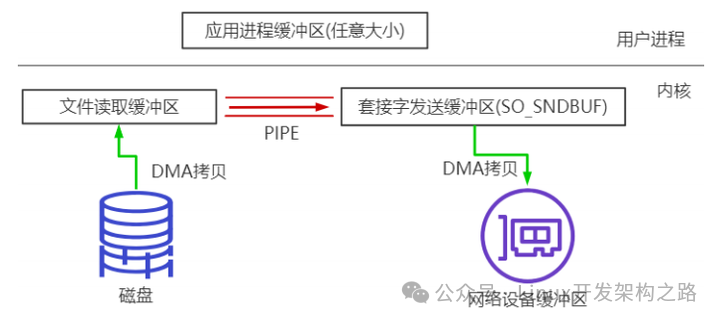
(5)splice
Linux 从 2.6.17 支持 splice。
数据从磁盘读取到 OS 内核缓冲区后,在内核缓冲区直接可将其转成内核空间其他数据buffer,而不需要拷贝到用户空间。
如下图所示,从磁盘读取到内核 buffer 后,在内核空间直接与 socket buffer 建立 pipe管道。
和 sendfile()不同的是,splice()不需要硬件支持。
注意 splice 和 sendfile 的不同,sendfile 是 DMA 硬件设备不支持的情况下将磁盘数据加载到 kernel buffer 后,需要一次 CPU copy,拷贝到 socket buffer。
而 splice 是更进一步,连这个 CPU copy 也不需要了,直接将两个内核空间的 buffer 进行 pipe。
splice 会经历 2 次拷贝: 0 次 cpu copy 2 次 DMA copy;
以及 2 次上下文切换
3、总结
(1)零拷贝的目标
解放CPU,避免CPU做太多事情;
减少内存带宽占用;
减少用户态和内核态上下文切换过多;
在文件较小的时候mmap用时更短,文件较大时sendfile方式最优。
(2)零拷贝方式对比
sendfile:
无法在调用过程中修改数据,只适用于应用程序不需要对所访问数据进行处理修改情况;
比如静态文件传输、MQ的Broker发送消息给消费者;
想要在传输过程中修改数据,可以使用mmap系统调用;
文件大小:适合大文件传输;
切换和拷贝:2次上下文切换,最少2次数据拷贝。
mmap:
mmap调用可以在应用程序中直接修改Page Cache中的数据,使用的是mmap+write两步;
调用比sendfile成本高,但优于传统I/O的零拷贝实现方式,虽然比sendfile多了上下文切换;
用户空间与内核空间并不需要数据拷贝,在正确使用情况下并不比sendfile效率差;
适用于多个线程以只读的方式同时访问同一个文件,mmap机制下多线程共享同一物理内存,节约内存;
文件大小:适合小数据量读写;
切换和拷贝:4次上下文切换,3次数据拷贝。
 0
0











