
前言:
大家好,在上一期文章rtsp端到端到底可以做到多大的延迟?文章发布出去之后,很多朋友下方留言交流:


所以交流的重要性不言而喻,很多朋友有自己的经验分享,感谢分享,哈哈!
回归主题,现在很多soc的硬编解码器在参数配置上,都会提供超低延迟模式配置,但是可能对这块的技术实现原理,没怎么描述,国内的技术文档一直都是简单几句话一笔带过,给俺们这些做开发的,可犯难了,不知道这里到底有啥猫腻呢。
为了理解和掌握这块的技术原理,我这里不以国产的soc来刨析这块,而是以fpga平台来学习这块的技术原理,在xilinx官方手册里面有比较详细的介绍!
那么我们就fpga平台来揭开超低延迟实现的技术面纱!
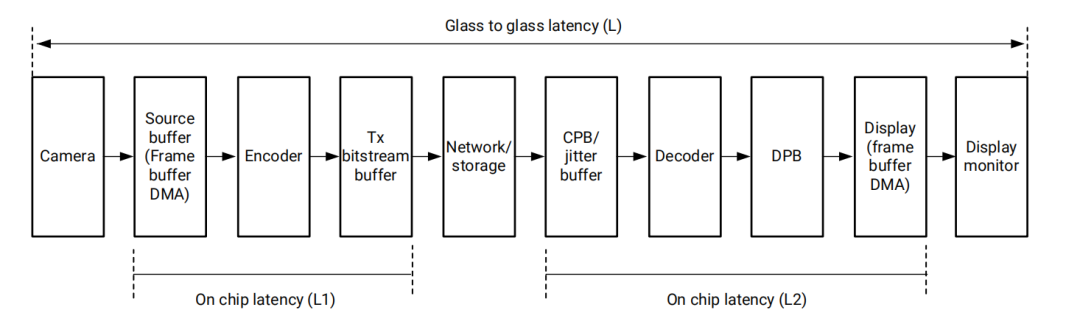
glass to glass延迟,延迟有哪些方面造成的?
首先我们在平时的音视频开发过程中,遇到了延迟问题,我们要定位到到底是什么原因导致这么大的延迟,也就是我们要有一个问题的分析过程,那么在整个摄像头采集原始数据经过网络传输到最终的显示器上显示,这整个过程到底有哪些因素会造成延迟。
-
1、摄像头延迟
-
2、on-chip latency(L1),也就是片上延迟,换句话说芯片内部发生的延迟:
- (1)Source frame buffer DMA latency:使用直接内存访问(DMA)技术时,源帧缓冲区(即存储图像或视频帧的内存区域)的数据传输到另一个设备或处理单元所经历的延迟
- (2) encoder latency:编码器延迟,这里面可能有视频帧进入编码器处理队列前的等待时间以及编码器实际处理视频帧,进行压缩编码的时间、编码后的数据帧准备好被输出的时间。
- (3)transmission bitstream buffer latency:传输比特流缓冲区延迟,是在视频编码和传输过程中,编码后的数据(比特流)在被发送到网络之前在缓冲区中等待的时间。
-
3、network or storage latency: 网络或存储延迟,指的是在数据通过网络传输或从存储设备读取时所经历的延迟。
-
4、On-chip latency(L2):这个片上延迟的第二个层次,我们来看一下有哪些因素:
- (1)coding picture buffer(CPB)/jitter buffer latency: 编码图像缓冲区(CPB)/抖动缓冲区延迟;coding picture buffer是指编码图像缓冲区延迟指的是在视频编码过程中,视频帧数据从被编码器接收到被完全处理并输出为编码后的数据流所需的时间。CPB是视频编码标准中定义的一个概念,用于存储编码后的视频帧,以保证编码过程的平滑性和连续性。CPB的大小直接影响编码的延迟,注意这里的CPB和刚才上面的传输比特流缓冲区延迟有差异哈。jitter buffer latency是指抖动缓冲区延迟是指在网络视频流传输中,用于平滑网络抖动(即数据包到达时间的不规律性)的缓冲区所引入的延迟。抖动缓冲区可以吸收网络延迟的变化,保证视频播放的流畅性。这种缓冲区会存储一定量的数据,以便在网络条件不佳时,仍然能够连续地提供数据给解码器或播放器。
- (2)decoder latency : 解码器延迟,从解码器接收到编码后的视频数据到解码器输出解码后的原始视频帧所需的时间
- (3)decoded picture buffer(DPB) latency : 解码图像缓冲区(DPB)延迟,指在视频解码过程中,解码后的图像帧在解码图像缓冲区中存储并等待进一步处理或显示的时间,这块后面再详细讲解里面的细节,这里大概了解一下就行。
- (4)、display frame buffer DMA latency: 显示帧缓冲区DMA延迟,指的是在图形或视频数据通过直接内存访问(DMA)技术从显示帧缓冲区传输到显示硬件(如显卡或显示控制器)的过程中所经历的延迟。
-
5、display monitor latency : 显示监视器延迟
总结一下,这里没有把B帧加入进去,一般在这种超低延迟模式或者降低延迟方法中,都不会在编码端把B帧加入,因为当启用B帧时,由于使用了重排序缓冲区(reorering buffer),每个B帧会产生一帧的延迟
延迟模式有哪些?
这里主要介绍一下fpga上提供的一些延迟模式配置:视频处理单元(VCU)支持四种延迟模式:正常延迟、降低延迟(也称为无重排序模式)、低延迟和Xilinx低延迟模式。pipeline的瞬时延迟可能会根据帧结构、编码标准、级别(levels)、配置文件(profiles)和目标比特率而有所不同:
-
1、nomal-latency : 视频处理单元(VCU)的编码器和解码器在帧级别工作。支持所有可能的帧类型(I帧、P帧和B帧),并且对组画面(GOP)结构没有任何限制。端到端的延迟取决于配置文件/级别(profile/level)、GOP结构以及用于处理的内部缓冲区数量。这是标准延迟,并且可以与任何控制速率模式(target bitrate)一起使用。
-
2、no reordering(reduced-latency): 视频处理单元(VCU)的编码器在帧级别工作。使用硬件速率控制来减少比特率变化。支持仅I帧、IPPP和低延迟P帧。没有输出重排序,从而降低了解码器端的延迟。VCU继续在帧级别操作。这里的IPPP:这通常指的是一种帧序列结构,其中包含一个I帧后跟三个P帧(Intra-coded Picture, Predictive-coded Picture)。这种结构在视频编码中用于平衡压缩效率和解码性能。I帧提供了解码的独立点,而随后的P帧利用与I帧的时序冗余进行编码,从而提高压缩效率。
-
3、low-latency : 帧被划分为多个切片;视频处理单元(VCU)编码器的输出和解码器的输入都以切片模式进行处理。VCU编码器的输入和解码器的输出仍然以帧模式工作。VCU编码器在每个切片结束时生成一个切片完成中断,并为切片输出流缓冲区,它将立即可供下一个元素处理。因此,通过使用多个切片,可以将VCU处理延迟从一帧减少到一帧/(帧数/切片数)。在低延迟模式下,编码器最多可以运行四个流,解码器可以运行两个流。这里面我把这段话拆解开来理解:
- 这里简单解释一下帧划分为多个切片:在视频编码中,为了提高编码效率和容错能力,一帧视频可以被进一步划分为更小的单元,称为“切片”(Slice)。每个切片可以独立于其他切片进行编码和解码。后面我会在翻译h264和h265里面汇总来详细分析这块内容!
- 切片完成中断:VCU编码器在完成每个切片的编码后,会生成一个中断信号,通知系统切片编码已完成。
- 流缓冲区输出:与每个切片关联的编码后的数据(流缓冲区)在切片编码完成后即可输出,这意味着它可以立即被发送到下一个处理环节,比如通过网络传输或存储到内存中。
- 降低处理延迟:使用切片技术可以减少VCU的总体处理延迟。如果一帧被划分为多个切片,每个切片可以几乎同时开始处理,而不是必须等待整帧处理完成。这样,处理延迟可以从等待整帧的时间减少到等待单个切片的时间,即一帧/(帧数/切片数)。
- 低延迟模式下的多流处理:在VCU的低延迟模式下,可以并行处理更多的数据流。编码器可以同时处理最多四个流,而解码器可以同时处理两个流。这种并行处理机制可以进一步提高处理效率,减少延迟。
-
4、xilinx low-latency : 在低延迟模式下,VCU编码器和解码器在子帧或切片级别的边界工作,但编码器的输入和解码器的输出的其他组件,即捕获DMA和显示DMA仍然在帧级别的边界工作。这意味着编码器只能在捕获完整帧的写入完成后才能读取输入数据。在Xilinx低延迟模式下,捕获和显示也在子帧级别工作,从而显著降低了流水线(pipeline)的延迟。这是通过让生产者(捕获DMA)和消费者(VCU编码器)同时在同一个输入缓冲区上工作来实现的,但同时保持两者之间的同步,这样消费者读取请求只有在生产者完成写入该读取请求所需的数据后才被解除阻塞。维持这种同步的功能是由一个称为Xilinx同步IP的单独IP块管理的。同样,解码器和显示也被允许同时访问同一个缓冲区,但在这里它们之间没有单独的硬件同步IP块。软件通过确保只有在解码器至少写入了半个帧周期的数据后,缓冲区才开始被显示来处理同步。与低延迟模式类似,Xilinx低延迟模式还支持编码器最多四个流和解码器两个流。
总结:
所以这里的低延迟,主要是对帧处理的方式,把他划分成更小的单元去并行处理,来达到降低延迟的目的!
 0
0










