

冠状病毒时间序列数据
冠状病毒统治着整个世界,无论我转到哪个站点,COVID-19都是头条新闻。值得庆幸的是,全球许多研究实验室和组织一直在收集有关此方面的数据,并已将其开源。那么,为什么不使用我们的数据科学知识和技能来解决社会福利问题呢?

我在这里链接的GitHub库包括追踪全球冠状病毒感染人数的时间序列数据,包括:
-
确诊的冠状病毒病例
-
死于冠状病毒的人数
-
从致命感染中康复的人数
该项目的作者每天更新数据集ina.CSV格式,所以你可以下载它。
地址:
https://github.com/datasets/covid-19
NLP论文摘要
在过去的三年中,自然语言处理(NLP)领域得到了突飞猛进的发展。从2017年的Transformer架构开始,此后我们见证了一系列突破和突破性的NLP库,包括Google的BERT,OpenAI的GPT-2等。

该GitHub库是NLP关键论文的集合,这些论文针对更广泛的数据科学专业人员进行了总结。这是此存储库中涵盖的主题的关键列表:
-
对话与互动系统
-
道德与自然语言处理
-
文字产生
-
信息提取
-
信息检索与文本挖掘
-
NLP模型的可解释性和分析
-
语言扎根于视觉,机器人技术及其他
-
语言建模
-
NLP机器学习
-
机器翻译
-
多任务学习
-
NLP应用
-
问题回答
-
资源与评估
-
语义学
-
情感分析,文字分析和参数挖掘
-
言语与多模态
-
文字摘要
-
语法:标记,分块和解析
地址:
https://github.com/dair-ai/nlp_paper_summaries
Google Brain AutoML
自动机器学习,或称AutoML,是为了实现典型机器学习管道中某些任务的自动化。几年前为了节省时间而开始的一个小项目现在已经成为一个成熟的研究领域。市场上有大量的自动化工具可以为组织自动化整个ML管道。
AutoML尤其吸引那些没有专门的数据科学团队,或者无力从头雇佣一个团队的企业。从谷歌的Cloud AutoML到百度的EZDL,几乎每个科技巨头在市场上都有一个自动解决方案。

地址:
https://github.com/google/automl
Google’s ELECTRA
这是谷歌研究团队的另一个很棒的开源项目。这与前面提到的自然语言处理(NLP)领域和Transformer体系结构有关。谷歌研究团队是这样定义ELECTRA的:
ELECTRA是一种新的自监督语言表示学习方法。它可以用相对较少的计算量对变压器网络进行预训练。ELECTRA模型被训练来区分“真实的”输入标记和由另一个神经网络生成的“虚假的”输入标记。
让我印象深刻的是ELECTRA的准确性,我们甚至可以在一个GPU上实现。ELECTRA在大规模数据集上达到了一个完全不同的水平,并在SQuAD 2.0基准上实现了最先进的性能。你可以在谷歌的研究论文中深入了解ELECTRA。目前,该团队已经发布了三款预先训练过的模型:

在开始之前,需要在机器上安装以下:
-
Python 3
-
TensorFlow 1.15
-
NumPy
-
scikit-learn和SciPy
地址:
https://github.com/google-research/electra
GAN Compression
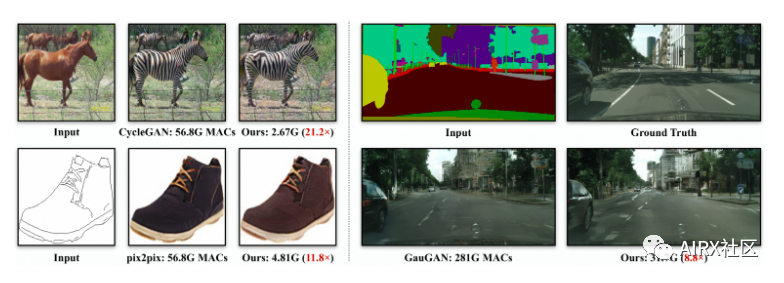
2014年,伊恩•古德费洛(Ian Goodfellow)推出了生成式对抗网络(GANs),席卷了数据科学领域。但是训练GAN模型的一个重要问题是所需的强大计算能力。这就是GAN压缩的用武之地。
地址:
https://github.com/mit-han-lab/gan-compression
StyleGAN2
StyleGAN在计算机视觉社区中很受欢迎,StyleGAN2是一个最先进的生成逼真图像的网络。

地址:
https://github.com/EvgenyKashin/stylegan2-distillation
其他资源链接
参考链接:
https://www.analyticsvidhya.com/blog/2020/04/6-open-source-data-science-projects-industry-ready/
推荐阅读
AIRX
国内领先的AI、AR、VR技术学习与交流平台
扫码关注我们
AR开发者交流群:626914771
AR开发交流:891555732
 0
0











