
英伟达宣布推出“世界基础模型”NVIDIA Cosmos。Cosmos模型可以接受文本、图像或视频的提示,生成虚拟世界状态,作为针对自动驾驶和机器人应用独特需求的视频输出。开发人员可以利用Cosmos为强化学习生成AI反馈,从而改善策略模型并测试在不同场景下的性能。黄仁勋表示,通过Cosmos,开发人员可以使用0mniverse创建三维场景,然后使用Cosmos将其转换为照片级逼真的场景,再通过同时生成多个模型,帮助机器人找到完成任务的最佳方法,从而实现机器人更快学习和进步。
机器人相关软硬件技术渐趋成熟,大模型+具身智能打开人形机器人产业成长空间。星动纪元创始人、清华大学交叉信息研究院助理教授陈建宇表示,现在人形机器人最大的技术瓶颈是具身智能。根据智源研究院发布的2025十大AI技术趋势,2025年的具身智能(包括人形机器人),将继续从本体扩展到具身脑的叙事主线。在行业格局上,近百家具身初创企业或将迎来洗牌,厂商数量开始逐步收敛;在技术路线上,端到端模型继续迭代,小脑大模型的尝试或有突破;在商业变现上,将看到更多工业场景下的具身智能应用,部分人形机器人迎来量产。
01
跨维智能:SAM-6D
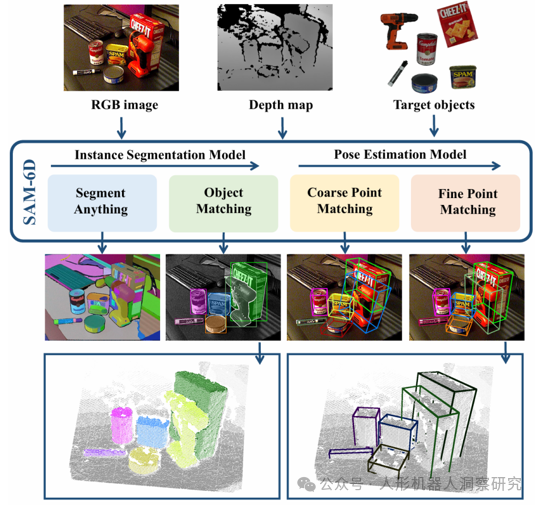
- 零样本姿态估计:SAM-6D可从RGB-D图像中快速估计未见过物体的6D姿态,助力机器人在复杂场景中精准抓取。
- 增强适应性与泛化能力:基于零样本学习,SAM-6D仅需CAD模型即可估计姿态,显著提升机器人在未知环境中的泛化能力。
- 复杂场景鲁棒性:通过Background Token设计,SAM-6D能有效解决遮挡问题,提高机器人在杂乱环境中的操作成功率。
- 多阶段优化:SAM-6D采用两阶段点集匹配,先粗匹配后精优化,显著提高姿态估计精度,为操作提供可靠支持。
- 助力具身智能:SAM-6D使机器人能快速适应新环境和任务,推动具身智能的灵活自主操作。

应用场景
SAM-6D 在具身智能机器人操作中具有巨大的应用潜力,能够显著提升机器人在复杂场景中的适应性和操作精度。这种技术为机器人在家庭服务、工业自动化和物流等领域的广泛应用提供了新的可能性。02
智平方 & 北京大学:RoboMamba
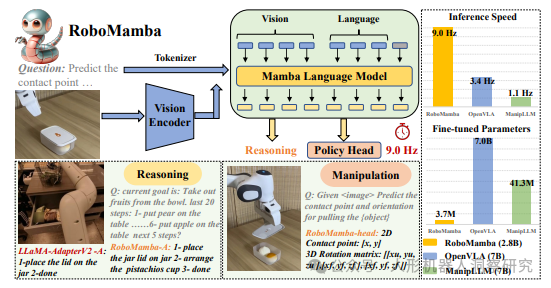
- 多模态设计:RoboMamba结合了视觉编码器和线性复杂度的状态空间语言模型(SSM,即Mamba),通过协同训练赋予模型强大的视觉常识理解和机器人相关推理能力。
- 高效推理与微调:该模型通过一种高效的微调策略,仅需调整模型参数的0.1%,即可在短时间内(约20分钟)完成微调,显著提升了操作泛化能力和任务适应性。
- 推理与操控能力:RoboMamba能够处理从高层次推理到低层次精细操控的多任务场景,推理速度比现有模型快3倍。
- 实验表现:在通用和机器人评估基准测试中,RoboMamba展现了出色的推理能力,并在模拟和现实世界实验中实现了令人印象深刻的位姿预测结果。
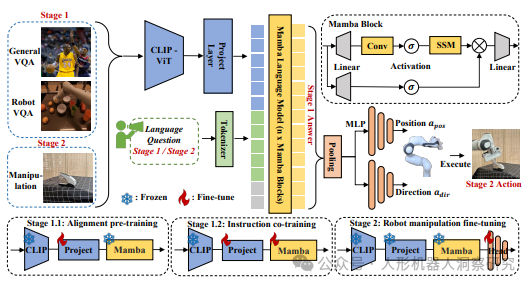
应用场景:RoboMamba适用于多种机器人任务,包括任务规划、长程任务规划、可操纵性判断、未来与过去预测以及末端执行器位姿预测等
03
星动纪元:ERA-42
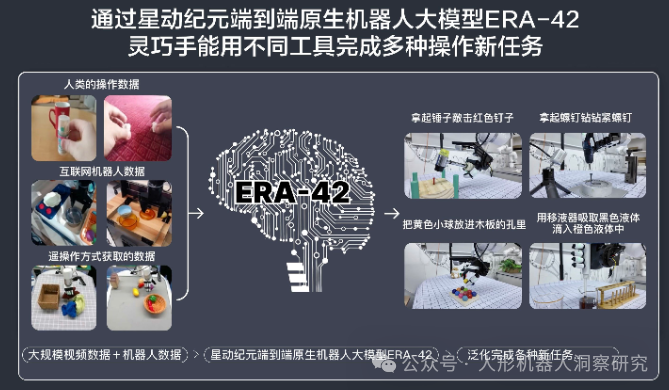
在通用性和灵巧操作能力方面,ERA-42无需任何预编程技能,具备强泛化与自适应能力,基于少量数据收集,可在不到2小时即可学会新任务,并持续快速学习更多新技能。
星动纪元指出,具身大模型作为开启通用具身智能体的密钥,需要具备以下三个要素。第一,统一一个模型泛化多种任务和环境,第二是端到端,从接收全模态数据,到生成最终输出如决策、动作等,通过一个简洁的神经网络链路完成,第三是Scaling up(规模化),允许模型通过持续的数据积累实现自我完善,使得具身大模型在数据量指数级增长的同时,不仅提升性能,还能在未知任务中展现卓越的自适应和泛化能力。

在实际应用中,相比传统的夹爪机器人,基于ERA-42能力的五指灵巧手星动XHAND1能使用多种工具,完成更通用、灵巧性更强、复杂度更高的操作任务。例如,通过简单的彩色方块抓取数据训练后,ERA-42就能成功实现从未见过的多样化物体的抓取泛化。
04
Google & 柏林技术大学:PaLM-E
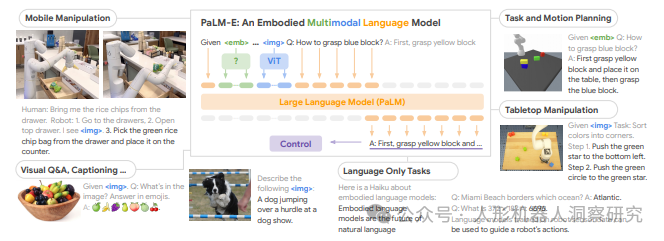
PaLM-E(全称:Pathways Language Model with Embodied)是由Google和柏林技术大学(TU Berlin)合作开发的一种具身多模态语言模型,旨在通过融合视觉、语言和机器人控制能力,实现复杂的机器人任务。PaLM-E的研究成果于2023年3月发布。
项目主页:https://palm-e.github.io/

- 多模态融合:PaLM-E结合了大规模语言模型(LLM)和视觉Transformer(ViT),将视觉、连续状态估计和文本输入编码为多模态句子,从而实现对复杂任务的理解和执行。
- 大规模参数量:PaLM-E的参数量高达5620亿,其中语言模型PaLM为5400亿参数,视觉模型ViT为220亿参数。这是目前已知的最大视觉语言模型。
- 具身化推理能力:该模型能够直接将现实世界的连续传感器模态融入语言模型,从而建立词汇和感知之间的联系。它不仅能够执行视觉问答和图像描述,还能控制机器人完成复杂的操作任务。
- 高效任务执行:PaLM-E能够根据自然语言指令生成高级动作序列,并通过机器人平台执行任务。例如,它可以规划“找到海绵、捡起海绵、拿给用户、放下海绵”等一系列动作。
-
跨模态迁移能力:PaLM-E通过多模态训练,展示了从语言、视觉到具身任务的正向迁移能力。它不仅在机器人任务上表现出色,还在视觉问答(VQA)等任务上达到了最先进的性能

- 机器人任务规划:PaLM-E能够生成复杂的动作序列,完成导航、物体操作等任务。
- 视觉问答:通过图像输入,模型可以生成描述性文字或回答相关问题。
- 故障检测与长期规划:模型能够进行故障检测和长期任务规划,适应复杂环境
05
Microsoft:ChatGPT for Robotics
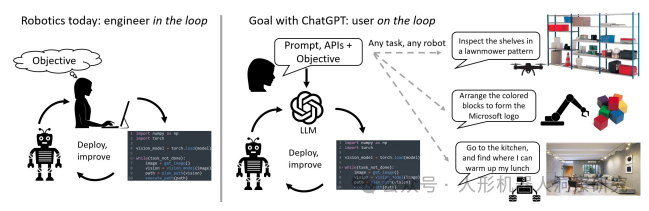
ChatGPT for Robotics是由微软自主系统和机器人研究院(Microsoft Autonomous Systems and Robotics Research)与OpenAI合作开发的一个研究项目,旨在探索如何将ChatGPT应用于机器人任务,通过自然语言交互实现机器人控制和任务规划。
核心内容-
设计原则与能力:该项目提出了结合提示词工程(prompt engineering)和高级函数库的设计原则,使ChatGPT能够适应不同的机器人任务、模拟器和硬件形态。研究重点在于评估不同提示词技术和对话策略在机器人任务中的有效性。
-
多模态交互能力:ChatGPT for Robotics不仅支持自由对话形式,还能解析XML标签、合成代码,并通过对话进行闭环推理。这些能力使其能够处理从基础逻辑、几何和数学推理到复杂任务(如空中导航、操作和具身代理)的多种机器人任务。
- PromptCraft平台:为了促进社区协作,微软推出了一个开源研究工具PromptCraft。该平台允许研究者上传和投票选出优秀的提示词方案,并提供了一个集成ChatGPT的机器人模拟器示例,方便用户快速上手。

应用范围ChatGPT for Robotics的应用范围广泛,包括但不限于:
- 空中机器人任务:如无人机的涡轮机检查、太阳能板检查和障碍物规避。
- 操作任务:如物体抓取、堆叠和构建复杂结构。
-
空间-时间推理:如视觉伺服任务
06
NVIDIA Cosmos 世界基础模型平台
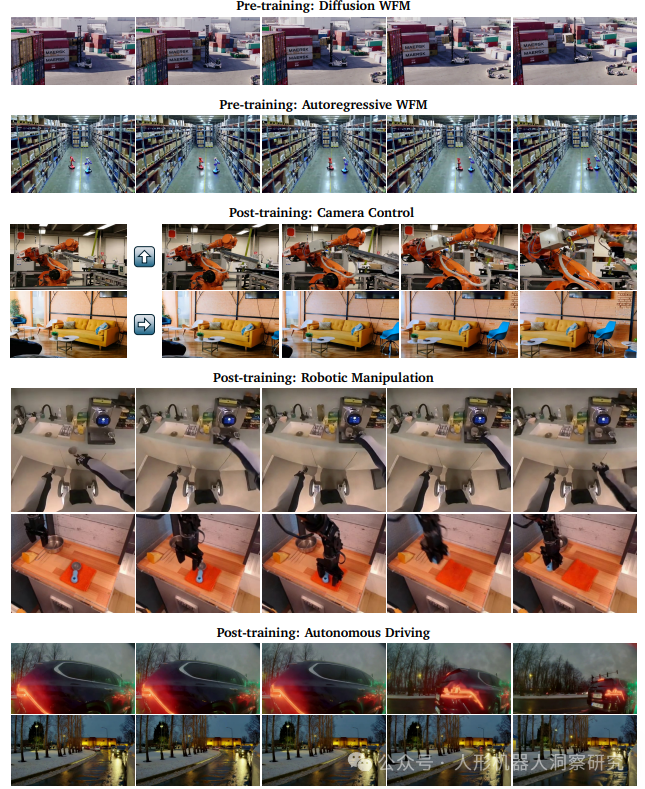
NVIDIA Cosmos 是由英伟达推出的一个面向物理 AI(Physical AI)开发的具身大模型平台,旨在通过生成式世界模型(World Foundation Models, WFM)加速机器人和自动驾驶汽车等物理 AI 系统的开发。
核心功能- 预训练世界模型(Pre-trained World Models):Cosmos 提供了一系列预训练的生成式世界模型,包括扩散模型(Diffusion)和自回归模型(Autoregressive),支持从文本到世界(Text-to-World)和从视频到世界(Video-to-World)的生成。这些模型经过大规模视频数据训练,能够生成高保真、物理感知的视频内容。
- 视频处理与分词技术(Video Tokenizers):Cosmos 配备了高效的视频分词器,能够将视频数据高效地转换为连续或离散的标记,压缩率比现有技术高出8倍,处理速度提升12倍。
- 数据处理管线(Video Curation Pipeline):平台提供了一个加速数据处理和管理的管线,能够处理超过100PB的数据,显著降低开发成本并加速模型训练。
- 安全与防护机制(Guardrails):Cosmos 内置了安全防护机制,包括预处理阶段的有害内容过滤和后处理阶段的视频内容审查,确保生成内容的安全性和一致性。
- 开放与可扩展性(Open and Extensible):Cosmos 以开放模型许可证(NVIDIA Open Model License)提供,允许开发者免费用于商业用途。开发者可以通过 NVIDIA NeMo 框架对预训练模型进行微调,以适应特定的物理 AI 应用
- 扩散模型(Diffusion Models):如 Cosmos-1.0-Diffusion-14B-Text2World 和 Cosmos-1.0-Diffusion-14B-Video2World,支持从文本或视频提示生成高质量视频。
- 自回归模型(Autoregressive Models):如 Cosmos-1.0-Autoregressive-13B-Video2World,用于预测视频序列中的未来帧。
-
辅助模型(Utility Models):如 Cosmos-1.0-Guardrail 和 Cosmos-1.0-PromptUpsampler-12B-Text2World,用于提升提示质量和生成内容的安全性。
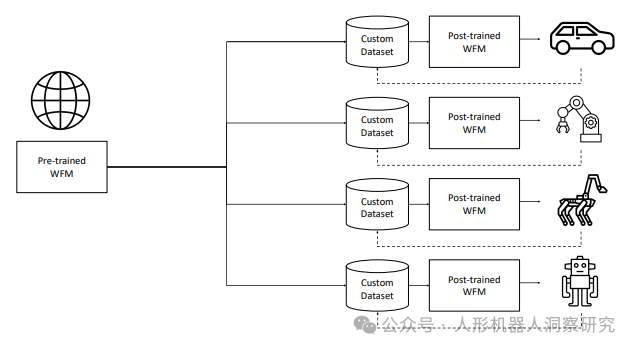 应用场景
应用场景
- 机器人开发:通过生成合成数据,加速机器人在复杂环境中的训练和测试。
- 自动驾驶汽车:提供高保真模拟环境,用于自动驾驶系统的开发和验证。
-
增强现实(AR):支持视频解码和增强现实应用
07
银河通用:GraspVLA

GraspVLA是由银河通用机器人联合北京智源人工智能研究院(BAAI)、北京大学和香港大学研究人员共同发布的全球首个端到端具身抓取基础大模型。该模型完全基于仿真合成大数据进行预训练,展现出强大的泛化能力和真实场景应用潜力。
核心特点- 预训练与后训练:预训练方面,GraspVLA使用了十亿帧“视觉-语言-动作”对的仿真合成数据进行预训练。这种大规模的仿真数据预训练方式突破了传统依赖真实数据的限制,显著降低了数据采集成本;后训练方面,模型可以通过少量真实数据进行微调,快速适应特定场景,同时保持高泛化能力。
- 泛化能力:GraspVLA定义了七大泛化“金标准”,包括光照泛化、背景泛化、平面位置泛化、空间高度泛化、动作策略泛化、动态干扰泛化和物体类别泛化。这些标准为模型的性能评估提供了明确的指导。
- 零样本测试能力:预训练完成后,GraspVLA可以直接在未见过的真实场景中进行零样本测试,展现出卓越的适应性。
-
技术创新:GraspVLA是全球首个完全基于仿真合成大数据进行预训练的具身大模型。这一创新突破了具身通用机器人领域的两大瓶颈:数据瓶颈和泛化瓶颈
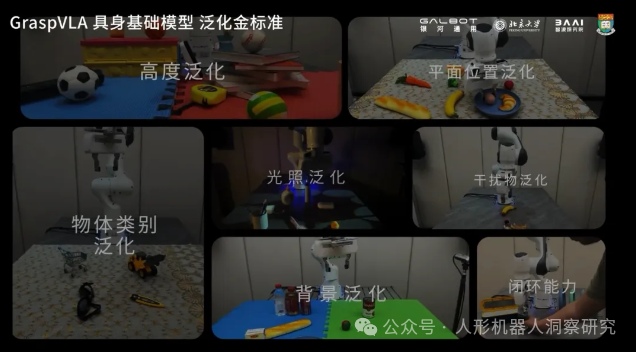
- 自主操作:机器人在复杂环境中的自主抓取和操作。
- 物体识别:在多样化背景下识别和操作不同物体。
- 复杂环境交互:在动态环境中进行实时交互
08
斯坦福 & Google等:OpenVLA

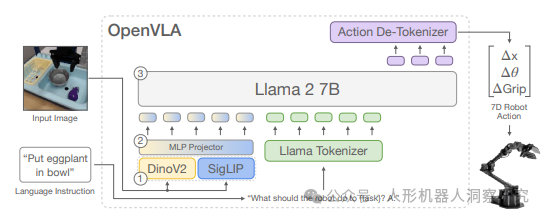
OpenVLA 是一个开源的视觉-语言-动作(Vision-Language-Action, VLA)模型,由斯坦福大学、加州大学伯克利分校、谷歌DeepMind、丰田研究院(Toyota Research Institute)和麻省理工学院(MIT)的研究人员联合开发。该模型旨在通过预训练的视觉和语言基础模型(VLMs),为机器人提供泛化能力强的动作生成能力,从而推动机器人技术的发展。
项目主页:https://openvla.github.io。GitHub 代码库:https://github.com/openvla/openvla核心特点- 模型架构:OpenVLA 是一个参数量为70亿的模型,基于Llama 2构建,并融合了DINOv2和SigLIP等视觉语言基础模型。它通过视觉和语言输入生成机器人动作,支持多种机器人平台的开箱即用,并可以通过参数高效微调快速适应新任务。
- 预训练数据:OpenVLA 使用了Open X-Embodiment数据集中的97万条机器人操作轨迹进行微调。这种大规模的预训练数据使模型具备了强大的泛化能力,能够处理未见过的任务指令和场景。
- 开源与灵活性:OpenVLA 的所有预训练检查点和训练代码均在MIT许可下开源。这使得研究人员和开发者可以轻松地使用、微调和扩展该模型,以适应不同的机器人任务和应用场景。
-
应用范围:OpenVLA 可以在多种机器人平台上直接使用,支持零样本(zero-shot)控制,也可以通过少量演示数据进行微调以适应新任务。它特别适用于需要泛化能力的机器人操作任务,如物体抓取、环境交互等
- 零样本控制:OpenVLA 可以直接控制机器人完成预训练数据中见过的任务和机器人平台组合。
- 快速微调:通过少量演示数据,OpenVLA 可以快速适应新任务和机器人平台。
- 多机器人支持:支持多种机器人平台,无需针对每个平台重新训练。
- 开源性:OpenVLA 是第一个开源的VLA模型,填补了该领域的空白。
- 泛化能力:通过大规模预训练数据,OpenVLA 能够泛化到未见过的任务和场景。
-
高效微调:支持多种微调方式,包括LoRA(低秩适配)和全参数微调
09
UC 伯克利 & 斯坦福等:Octo
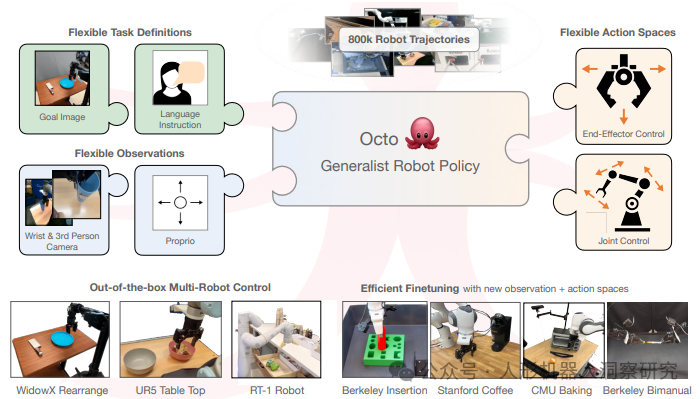
Octo 是由加州大学伯克利分校、斯坦福大学、卡内基梅隆大学和谷歌DeepMind等机构联合开发的开源通用机器人策略(Generalist Robot Policy)。它是一个基于Transformer架构的具身大模型,旨在通过大规模预训练数据提升机器人在多种任务和环境中的泛化能力。Octo 的预训练数据来自Open X-Embodiment数据集,涵盖了多种机器人形态、场景和任务。这些数据不仅在机器人类型上具有多样性,还在传感器配置(如是否包含腕部相机)和标签(如是否包含语言指令)上表现出异质性。
项目主页:https://octo-models.github.io/
核心特点- 架构设计:Octo 是一个基于Transformer的扩散策略模型,预训练使用了来自Open X-Embodiment数据集的80万条机器人操作轨迹。它支持多种输入模态,包括自然语言指令、目标图像、观察历史以及多模态动作预测。
- 灵活性与适应性:Octo 的设计强调灵活性和可扩展性。它支持多种机器人平台、传感器配置和动作空间,并能够通过微调快速适应新的观察和动作空间。这使得Octo可以广泛应用于不同的机器人学习场景。
- 预训练与微调:Octo 在多个机器人平台上展示了强大的零样本(zero-shot)控制能力,并且可以通过少量目标域数据(如100条轨迹)进行微调,以适应新任务和环境。
- 开源与可复现性:Octo 提供了完整的预训练检查点、训练代码和微调脚本,支持开源和可复现性。这使得研究人员和开发者可以轻松地使用和扩展该模型。
- 性能表现:在跨机构的9个机器人平台上进行的实验表明,Octo 在多机器人控制任务中表现出色,尤其是在使用目标图像进行任务定义时,其性能优于现有的开源通用机器人策略
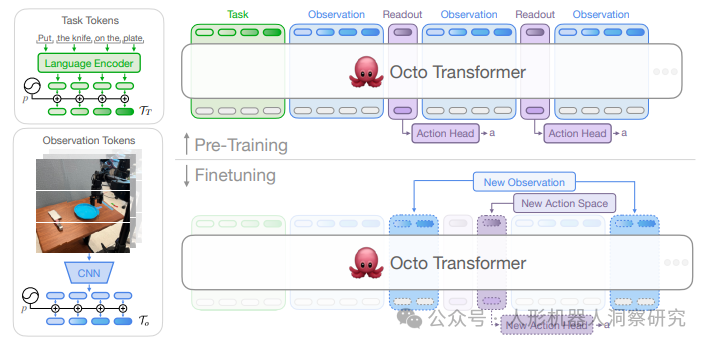
- 零样本控制:在预训练数据涵盖的任务和环境中直接控制机器人。
- 快速微调:通过少量数据微调以适应新任务和机器人平台。
-
多机器人支持:支持多种机器人平台,无需为每个平台重新训练
10
谷歌 DeepMind:RT-2
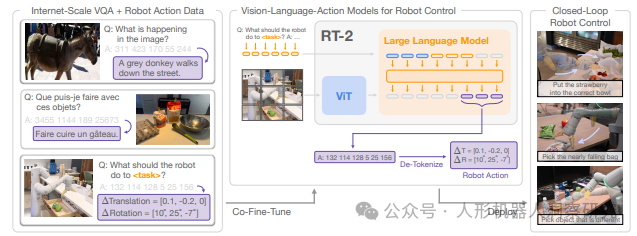
RT-2(Robotic Transformer 2)是由谷歌 DeepMind 推出的一种新型视觉-语言-动作(Vision-Language-Action, VLA)模型,旨在通过大规模互联网数据和机器人轨迹数据的结合,提升机器人控制的泛化能力和语义推理能力。
项目主页:https://robotics-transformer2.github.io/。代码仓库:https://github.com/kyegomez/RT-2核心特点- 模型架构:RT-2 基于视觉语言模型(VLM)的主干网络,如 PaLM-E 和 PaLI-X,通过将动作表示为文本标记(tokens),使其能够直接输出机器人动作。这种设计允许模型将视觉、语言和动作统一在一个框架内处理。
- 预训练与微调:RT-2 在互联网规模的视觉语言数据上进行预训练,然后在机器人轨迹数据上进行微调。这种方法不仅保留了大规模预训练带来的语义理解能力,还使模型能够适应具体的机器人任务。
- 泛化能力与涌现能力:RT-2 展示了显著的泛化能力,能够处理未见过的对象、背景和指令。此外,模型还表现出多种涌现能力,例如对新命令的解释能力、基于用户指令的推理能力(如选择最小或最大的物体),以及多阶段语义推理(如选择合适的工具或饮料)。
-
实时推理与部署:为了实现高效的实时控制,RT-2 可以部署在云端,机器人通过云服务请求控制指令,从而实现快速响应

- 泛化能力:RT-2 在6000次评估试验中表现出色,显著优于基线模型,尤其是在处理新对象、背景和指令时。
-
涌现能力:模型能够执行复杂的推理任务,例如根据用户指令选择合适的工具或饮料。

- 物体抓取与操作:在复杂环境中识别和操作新对象。
- 语义推理:根据用户指令执行多阶段任务。
-
实时控制:通过云端部署实现高效的实时机器人控制
11
Physical intelligence:π0
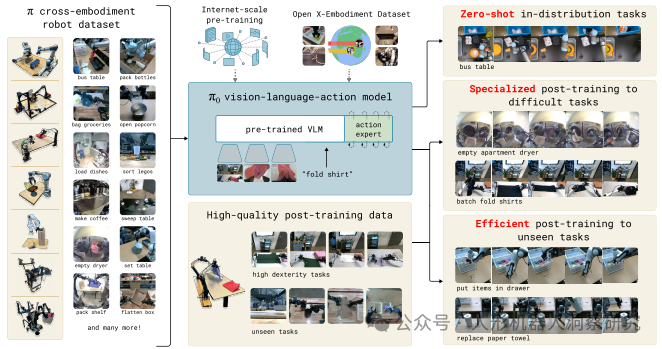
π₀ 是由 Physical Intelligence 公司开发的一种具身大模型,旨在通过视觉-语言-动作(Vision-Language-Action, VLA)流模型实现通用机器人控制。该模型展示了强大的泛化能力和实时推理能力,能够完成复杂的多阶段任务,如叠衣服、清理餐桌和组装盒子。
项目主页:Physical Intelligence π₀ Blog
核心特点- 架构设计:π₀ 基于预训练的视觉语言模型(VLM),如 PaliGemma,并在此基础上添加了一个动作专家(action expert),通过流匹配(flow matching)技术生成连续动作。这种设计使得模型能够直接输出低级电机命令,从而实现精确和流畅的操作技能。
- 预训练与微调:π₀ 的训练分为两个阶段,预训练阶段,在大规模互联网数据上进行预训练,继承互联网规模的语义知识。微调阶段,在多样化的机器人数据集上进行微调,这些数据集涵盖了7种不同的机器人配置和68种任务。
- 泛化能力:π₀ 在零样本任务评估中表现出色,能够完成未见过的任务,如衬衫折叠和餐桌清理。与 OpenVLA 和 Octo 等其他模型相比,π₀ 在复杂任务中的表现更为突出。
- 实时推理:π₀ 的设计使其能够进行实时推理,适用于动态环境中的任务执行。
-
多机器人适配:π₀ 可以直接控制多种机器人平台,无需为每个平台重新训练
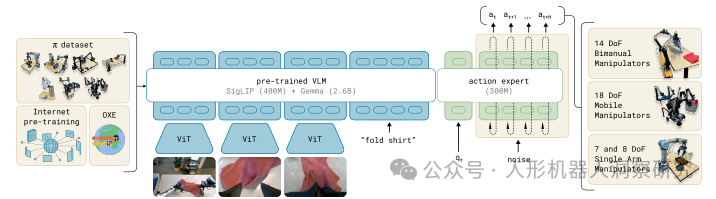
- 数据集:π₀ 使用了 OXE 数据集以及 Physical Intelligence 自行收集的机器人操作数据。
- 模型规模:π₀ 的基础模型 PaliGemma 拥有30亿参数,动作专家部分额外增加了3亿参数。
-
训练方法:π₀ 使用条件流匹配损失(Conditional Flow Matching)来监督动作的生成。

- 复杂操作任务:如叠衣服、清理餐桌、组装盒子。
- 实时控制:在动态环境中执行任务。
-
多机器人适配:通过微调适应不同的机器人平台
12
清华TSAIL团队:RDT
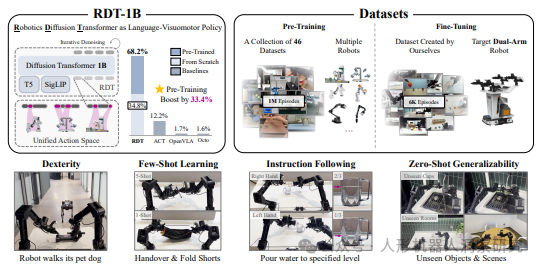
RDT(Robotics Diffusion Transformer)是由清华大学人工智能研究院 TSAIL 团队开发的全球最大的双臂机器人操作任务扩散基础模型。该模型旨在通过扩散模型(Diffusion Model)和可扩展的 Transformer 架构,提升机器人在复杂环境中的双臂协调与精确操作能力。
项目主页:https://rdt-robotics.github.io/rdt-roboticsGitHub 仓库:https://github.com/thu-ml/RoboticsDiffusionTransformerHugging Face 模型库:https://huggingface.co/robotics-diffusion-transformer/rdt-1b
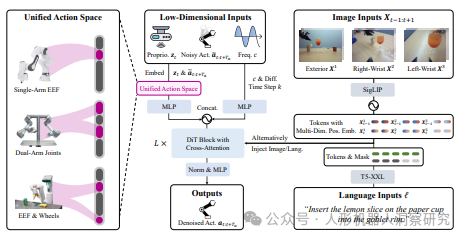

- 模型架构:RDT 基于扩散模型设计,采用可扩展的 Transformer 架构,能够高效处理多模态输入的异质性,捕捉机器人数据的非线性和高频特性。模型通过扩散模型的多模态行为分布表示,展现出卓越的动作预测与执行能力。
- 统一动作空间:为解决数据稀缺问题,RDT 引入了物理可解释的统一动作空间,统一不同机器人的动作表示,同时保留原始动作的物理意义。这种设计极大地提升了模型的跨平台知识迁移能力。
- 大规模预训练与微调:RDT 在目前最大的多机器人数据集上进行预训练,扩展到 1.2B 参数量,并在自建的多任务双臂数据集上进行微调。该数据集包含超过 6000+ 个任务实例,显著提升了模型的双臂操作能力。
- 泛化能力与少样本学习:RDT 展现出强大的零样本泛化能力,能够处理未见过的物体和场景,仅通过 1~5 次演示即可学习新技能。在真实机器人实验中,RDT 明显优于现有方法,能够理解和遵循语言指令,有效处理复杂任务。
-
应用场景:RDT 在多种复杂任务中表现出色,例如调酒、遛狗、倒水、清洗杯子等。这些任务展示了 RDT 的灵巧操作能力、指令遵循能力和对未知环境的适应性
本文来源:智猩猩ROBOT
 0
0







