
前言:
直接渲染管理器(Direct Rendering Manager,DRM)是 Linux 内核的一个子系统,负责与现代显卡的 GPU 进行接口。DRM 提供了一个 API,用户空间程序可以通过这个 API 向 GPU 发送命令和数据,执行如配置显示模式设置等操作。DRM 最初是作为 X 服务器直接渲染基础设施(Direct Rendering Infrastructure,DRI)的内核空间组件开发的,但此后它已被其他图形栈替代方案如 Wayland 以及一些独立的应用程序和库(例如 SDL2 和 Kodi)使用。
用户空间程序可以通过 DRM API 命令 GPU 执行硬件加速的 3D 渲染和视频解码,以及 GPGPU 计算。
Linux 内核已经有一个名为 fbdev 的 API,用于管理图形适配器的(framebuffer)帧缓冲区,但它无法满足现代 3D 加速 GPU 视频硬件的需求。这些设备通常需要在它们自己的内存中设置和管理一个命令队列,以便将命令派发到 GPU,同时还需要管理内存中的缓冲区和空闲空间。最初,用户空间程序(如 X 服务器)直接管理这些资源,但它们通常假设自己是唯一能够访问这些资源的程序。当两个或更多程序试图同时控制相同的硬件,并以各自的方式设置其资源时,大多数情况下会导致灾难性的结果。
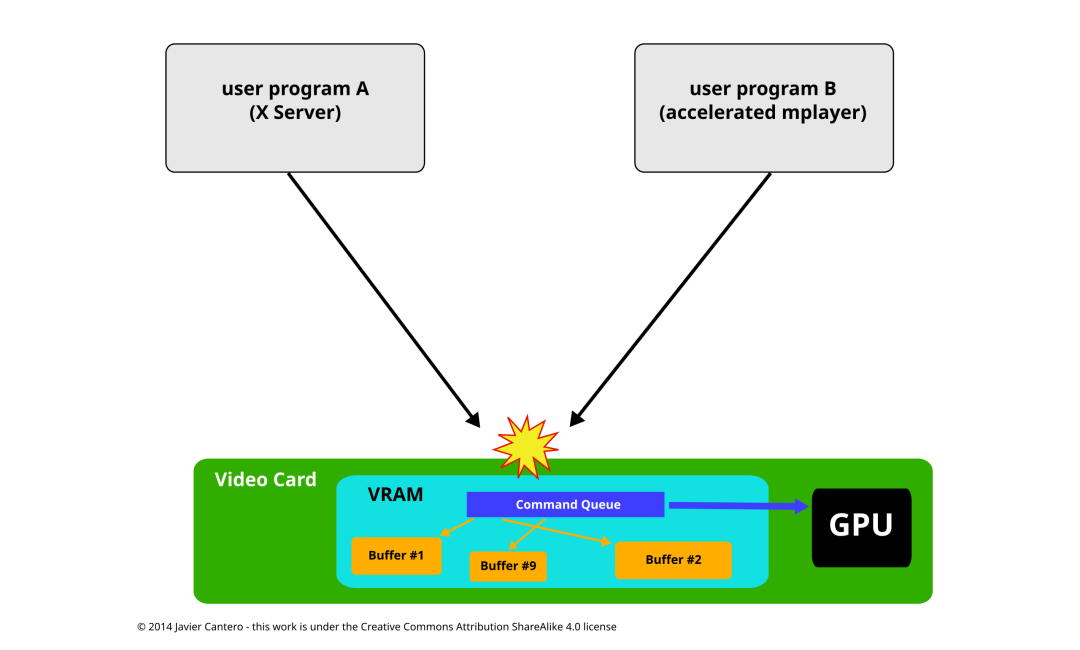 Without DRM
Without DRM
直接渲染管理器(DRM)被创建用来允许多个程序协同使用视频硬件资源。DRM 获取对 GPU 的独占访问权限,负责初始化和维护命令队列、内存以及其他任何硬件资源。希望使用 GPU 的程序向 DRM 发送请求,DRM 作为仲裁者,负责避免可能的冲突。
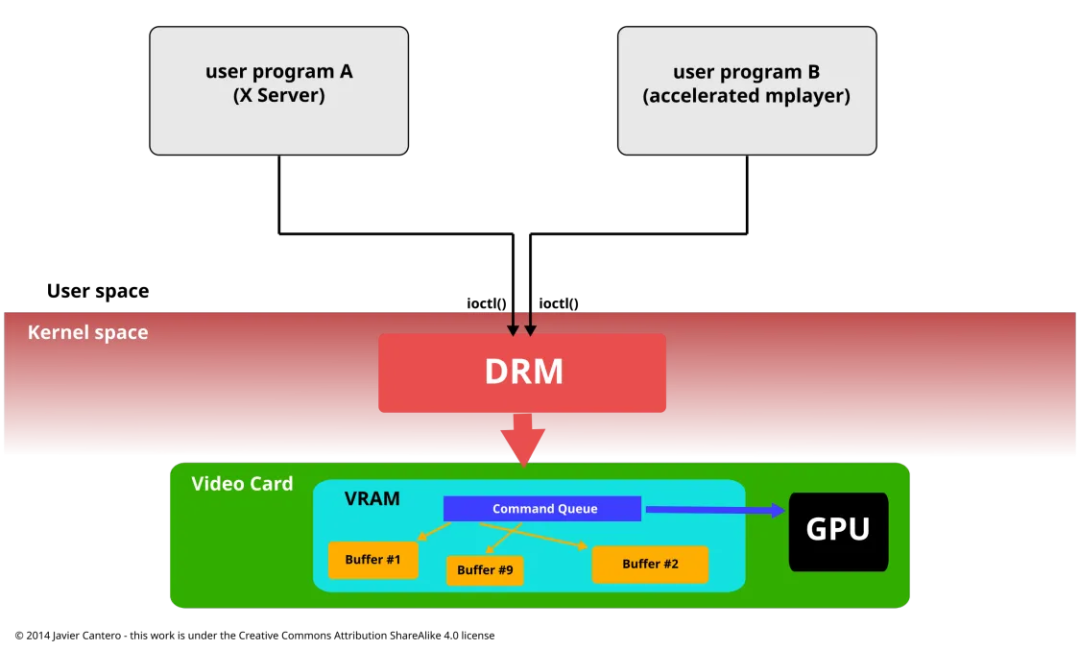 随着时间的推移,DRM 的功能范围不断扩展,涵盖了以前由用户空间程序处理的更多功能,如帧缓冲管理和模式设置、内存共享对象和内存同步等。这些扩展中的一些被赋予了特定的名称,如图形执行管理器(GEM)或内核模式设置(KMS),当专门提到它们所提供的功能时,这些术语通常会被使用。但它们实际上是整个内核 DRM 子系统的一部分。
随着时间的推移,DRM 的功能范围不断扩展,涵盖了以前由用户空间程序处理的更多功能,如帧缓冲管理和模式设置、内存共享对象和内存同步等。这些扩展中的一些被赋予了特定的名称,如图形执行管理器(GEM)或内核模式设置(KMS),当专门提到它们所提供的功能时,这些术语通常会被使用。但它们实际上是整个内核 DRM 子系统的一部分。
将两块 GPU(独立 GPU 和集成 GPU)包含在同一台计算机中的趋势,带来了诸如 GPU 切换等新问题,这些问题也需要在 DRM 层解决。为了匹配 Nvidia Optimus 技术,DRM 被赋予了 GPU 卸载功能,称为 PRIME。
Software architecture(软件架构)
直接渲染管理器(DRM)驻留在内核空间,因此用户空间程序必须使用内核系统调用来请求其服务。然而,DRM 并没有定义自己的定制系统调用。相反,它遵循 Unix 的“万物皆文件”原则,通过文件系统命名空间暴露 GPU,使用 /dev 层级下的设备文件。每个 DRM 检测到的 GPU 被称为一个 DRM 设备,并为其创建一个设备文件 /dev/dri/cardX(其中 X 是一个顺序编号)。想要与 GPU 通信的用户空间程序必须打开该文件,并使用 ioctl 调用与 DRM 进行通信。不同的 ioctl 调用对应 DRM API 的不同功能。
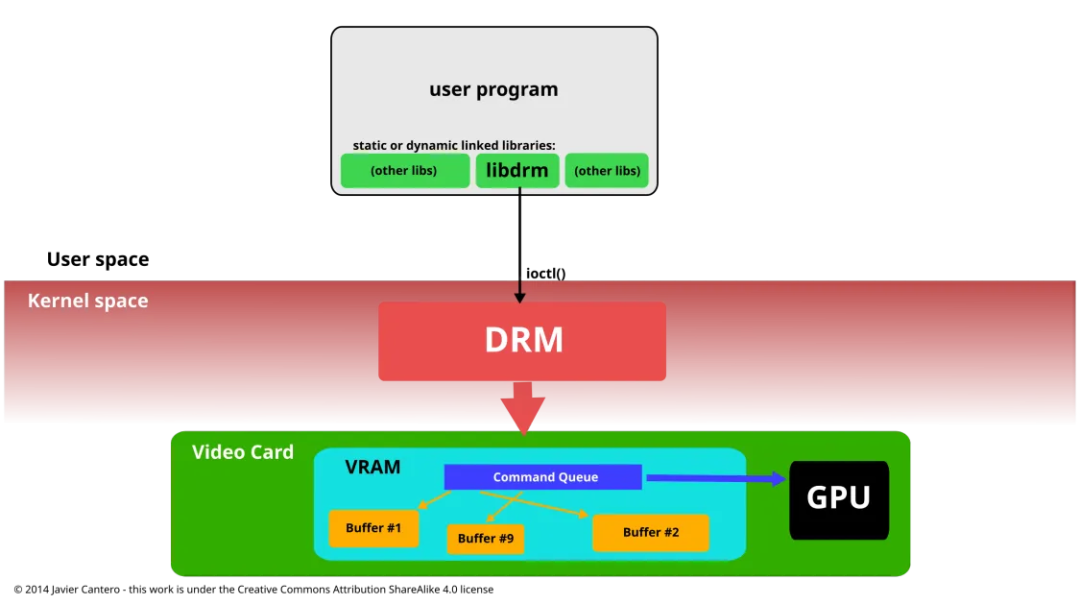
为了方便用户空间程序与 DRM 子系统的接口,创建了一个名为 libdrm 的库。该库只是一个包装器,为 DRM API 的每个 ioctl 提供了一个用 C 语言编写的函数,以及常量、结构体和其他辅助元素。使用 libdrm 不仅避免了将内核接口直接暴露给应用程序,还带来了代码复用和程序间共享代码的常见优势。
libdrm源码链接:
https://www.linuxfromscratch.org/blfs/view/systemd/x/libdrm.html
DRM 由两部分组成:一个通用的“DRM 核心”和一个针对每种支持硬件的特定部分(“DRM 驱动”)。DRM 核心提供了一个基本框架,允许不同的 DRM 驱动进行注册,并为用户空间提供一组最小的 ioctl,包含通用的、硬件无关的功能。而 DRM 驱动则实现了 API 中与硬件相关的部分,针对其支持的 GPU 类型;它应该提供 DRM 核心未涵盖的剩余 ioctl 的实现,但也可以扩展 API,提供额外的 ioctl,提供仅在特定硬件上可用的额外功能。当某个特定的 DRM 驱动提供增强的 API 时,用户空间的 libdrm 也会通过一个额外的库 libdrm-driver 扩展,以便用户空间可以与额外的 ioctl 接口进行交互
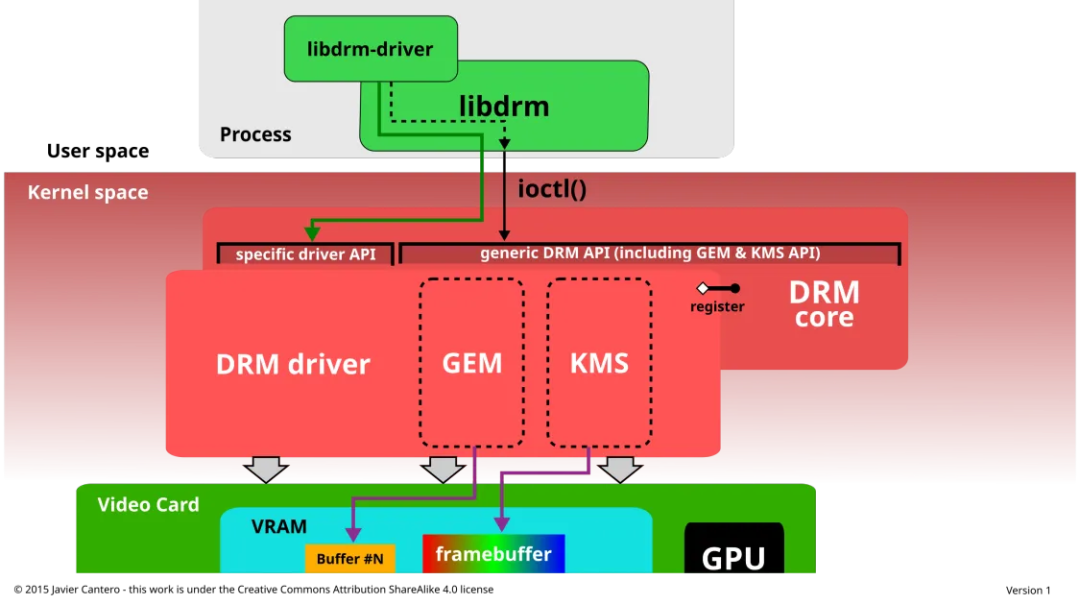
API、DRM-Master and DRM-Auth:
DRM 核心向用户空间应用程序导出了几个接口,通常通过相应的 libdrm 包装函数来使用。此外,驱动程序还通过 ioctl 和 sysfs 文件导出了特定设备的接口,供用户空间驱动程序和设备感知的应用程序使用。外部接口包括:内存映射、上下文管理、DMA 操作、AGP 管理、垂直同步控制、围栏管理、内存管理和输出管理。
在 DRM API 中,有几个操作(ioctl)由于安全原因或并发问题,必须限制为每个设备只能由一个用户空间进程使用。为了实现这一限制,DRM 将这些 ioctl 限制为只能由被认为是 DRM 设备“主控”进程调用,通常称为 DRM-Master。所有打开设备节点 /dev/dri/cardX 的进程中,只有一个进程会被标记为主控进程,具体来说,是第一个调用 SET_MASTER ioctl 的进程。任何没有成为 DRM-Master 的进程试图使用这些受限 ioctl 时都会返回错误。进程还可以通过调用 DROP_MASTER ioctl 放弃其主控角色,并让另一个进程获得该角色。
X 服务器或其他显示服务器通常是获取每个它管理的 DRM 设备的 DRM-Master 状态的进程,通常是在启动时打开相应的设备节点时获得,并在整个图形会话期间保持这些特权,直到会话结束或进程退出。
对于其他用户空间进程,还有另一种方式可以获得调用 DRM 设备上一些受限操作的权限,称为 DRM-Auth。这基本上是一种对 DRM 设备的认证方法,用以证明该进程已经获得 DRM-Master 的批准,从而获得这些特权。该过程包括:
-
客户端通过调用 GET_MAGIC ioctl 从 DRM 设备获取一个唯一的令牌(一个 32 位整数),并通过某种方式(通常是某种 IPC,例如在 DRI2 中,任何 X 客户端都可以向 X 服务器发送 DRI2Authenticate 请求)将其传递给 DRM-Master 进程。
-
DRM-Master 进程随后通过调用 AUTH_MAGIC ioctl 将令牌发送回 DRM 设备。
-
设备将特别权限授予与 DRM-Master 接收到的令牌匹配的进程文件句柄。
Graphics Execution Manager:
由于视频内存的不断增大以及像 OpenGL 这样的图形 API 越来越复杂,在每次上下文切换时重新初始化显卡状态的策略在性能上已经变得过于昂贵。此外,现代 Linux 桌面环境需要一种优化的方式来与合成管理器共享离屏缓冲区。这些需求促使了在内核中开发新的图形缓冲区管理方法。图形执行管理器(GEM)便是其中的一种方法。
GEM 提供了一个具有显式内存管理原语的 API。通过 GEM,用户空间程序可以创建、处理和销毁驻留在 GPU 视频内存中的内存对象。这些对象被称为“GEM 对象”,从用户空间程序的角度来看是持久的,无需每次程序重新控制 GPU 时重新加载。当用户空间程序需要一块视频内存(用于存储帧缓冲区、纹理或 GPU 所需的其他数据)时,它会通过 GEM API 向 DRM 驱动程序请求分配。DRM 驱动程序会跟踪已使用的视频内存,并在有空闲内存时满足请求,返回一个“句柄”给用户空间,供其在后续操作中引用已分配的内存。GEM API 还提供了填充缓冲区和在不再需要时释放缓冲区的操作。未释放的 GEM 句柄所占用的内存会在用户空间进程关闭 DRM 设备文件描述符时(无论是故意关闭还是进程终止时)被回收。
GEM 还允许两个或多个使用相同 DRM 设备(因此使用相同 DRM 驱动程序)的用户空间进程共享一个 GEM 对象。GEM 句柄是每个进程独有的 32 位整数,但在其他进程中可能会重复,因此不适合共享。所需要的是一个全局命名空间,GEM 通过使用全局句柄(称为 GEM 名称)提供了这一点。GEM 名称通过使用唯一的 32 位整数来引用同一 DRM 设备中由相同 DRM 驱动程序创建的一个且只有一个 GEM 对象。GEM 提供了一个 flink 操作,通过它可以从 GEM 句柄获取 GEM 名称。然后,进程可以通过任何可用的 IPC 机制将这个 GEM 名称(32 位整数)传递给另一个进程。接收进程可以使用该 GEM 名称来获取一个指向原始 GEM 对象的本地 GEM 句柄。
不幸的是,使用 GEM 名称共享缓冲区并不安全。访问同一 DRM 设备的恶意第三方进程可能会通过探测 32 位整数来猜测由两个其他进程共享的缓冲区的 GEM 名称。一旦找到了 GEM 名称,就可以访问和修改其内容,从而破坏缓冲区数据的机密性和完整性。这个缺点后来通过引入 DMA-BUF 支持得以解决,因为 DMA-BUF 将用户空间中的缓冲区表示为文件描述符,允许安全地共享。
除了管理视频内存空间外,任何视频内存管理系统的另一个重要任务是处理 GPU 与 CPU 之间的内存同步。当前的内存架构非常复杂,通常涉及多个级别的缓存,既包括系统内存,也有时包括视频内存。因此,视频内存管理器还需要处理缓存一致性,以确保 CPU 和 GPU 之间共享的数据是一致的。这意味着,视频内存管理的内部实现通常高度依赖于 GPU 和内存架构的硬件细节,因此是驱动程序特定的。
GEM 最初由英特尔工程师开发,目的是为其 i915 驱动程序提供一个视频内存管理器。英特尔的 GMA 9xx 系列是具有统一内存架构(UMA)的集成 GPU,GPU 和 CPU 共享物理内存,并且没有专用的显存。GEM 定义了“内存域”用于内存同步,虽然这些内存域是 GPU 无关的,但它们特别为 UMA 内存架构设计,因此不太适合具有分离显存的其他内存架构。因此,其他 DRM 驱动程序决定向用户空间程序公开 GEM API,但在内部实现了更适合其特定硬件和内存架构的不同内存管理器。
GEM API 还提供了用于控制执行流(命令缓冲区)的 ioctl,但它们是英特尔特有的,只能与英特尔 i915 及以后的 GPU 配合使用。没有其他 DRM 驱动程序尝试实现 GEM API 中超出内存管理相关 ioctl 以外的部分。
Translation Table Maps:
翻译表映射(TTM) 是在 GEM 之前开发的通用 GPU 内存管理器的名称。它专门设计用于管理 GPU 可能访问的不同类型的内存,包括专用显存(通常安装在显卡中)和通过 I/O 内存管理单元访问的系统内存,这个单元被称为图形地址重映射表(GART)。TTM 还应该处理 CPU 无法直接寻址的显存部分,并在考虑到用户空间图形应用通常需要处理大量视频数据的情况下,提供最佳的性能。另一个重要问题是保持不同内存和缓存之间的一致性。
TTM 的主要概念是“缓冲区对象”,即必须在某个时刻可以被 GPU 寻址的显存区域。当一个用户空间图形应用需要访问某个缓冲区对象(通常是为了填充内容)时,TTM 可能需要将其移动到 CPU 可以寻址的内存类型中。当 GPU 需要访问某个缓冲区对象而它还不在 GPU 的地址空间中时,可能会发生进一步的重定位或 GART 映射操作。每个这样的重定位操作必须处理与之相关的数据和缓存一致性问题。
TTM 另一个重要概念是围栏。围栏本质上是一种管理 CPU 和 GPU 之间并发性的方法。围栏跟踪缓冲区对象何时不再被 GPU 使用,通常是为了通知任何有权访问该对象的用户空间进程。
TTM 试图以合适的方式管理各种内存架构,包括有专用显存和没有显存的架构,并为任何类型的硬件提供所有可以想到的内存管理功能,这导致了一个过于复杂的解决方案,其 API 远比实际需要的要大。部分 DRM 开发人员认为它并不适合任何特定的驱动程序,尤其是其 API。当 GEM 作为一个更简单的内存管理器出现时,它的 API 比 TTM 更受欢迎。但一些驱动程序开发人员认为 TTM 采用的方法更适合于具有专用显存和 IOMMU 的独立显卡,因此他们决定在内部使用 TTM,同时将其缓冲区对象作为 GEM 对象暴露,从而支持 GEM API。当前使用 TTM 作为内部内存管理器但提供 GEM API 的驱动程序例子包括用于 AMD 显卡的 radeon 驱动和用于 NVIDIA 显卡的 nouveau 驱动。
DMA Buffer Sharing and PRIME:
DMA 缓冲区共享 API(通常简称 DMA-BUF)是一个 Linux 内核内部 API,旨在提供一种通用机制,用于在多个设备之间共享 DMA 缓冲区,这些设备可能由不同类型的设备驱动程序管理。例如,Video4Linux 设备和图形适配器设备可以通过 DMA-BUF 共享缓冲区,实现视频流数据的零拷贝:视频流由第一个设备产生,第二个设备消费。任何 Linux 设备驱动程序都可以作为导出者、用户(消费者)或两者的角色来实现这个 API。
这个功能首次在 DRM 中被利用,实施了 PRIME,一种用于 GPU 卸载的解决方案,它使用 DMA-BUF 来共享离散 GPU 和集成 GPU 之间的结果帧缓冲区。DMA-BUF 的一个重要特性是,共享缓冲区在用户空间呈现为文件描述符。为了开发 PRIME,DRM API 添加了两个新的 ioctl,一个用于将本地 GEM 句柄转换为 DMA-BUF 文件描述符,另一个用于执行相反的操作。
这两个新的 ioctl 后来被重新用于解决 GEM 缓冲区共享的固有不安全性。与 GEM 名称不同,文件描述符无法被猜测(它们不是全局命名空间),而 Unix 操作系统提供了一种通过 Unix 域套接字使用 SCM_RIGHTS 语义安全地传递文件描述符的方法。希望与另一个进程共享 GEM 对象的进程,可以将其本地 GEM 句柄转换为 DMA-BUF 文件描述符并将其传递给接收方,接收方则可以通过接收到的文件描述符获取自己的 GEM 句柄。这种方法被 DRI3 用于在客户端和 X 服务器之间共享缓冲区,也被 Wayland 使用。
Kernel Mode Setting:
为了正常工作,显卡或图形适配器必须设置一个模式——即屏幕分辨率、颜色深度和刷新率的组合——该模式必须在显卡本身和连接的显示器所支持的范围内。这个操作叫做模式设置(mode-setting),通常需要直接访问图形硬件——即能够写入显卡显示控制器的某些寄存器。模式设置操作必须在开始使用帧缓冲之前执行,而且当应用程序或用户要求更改模式时,也需要执行。
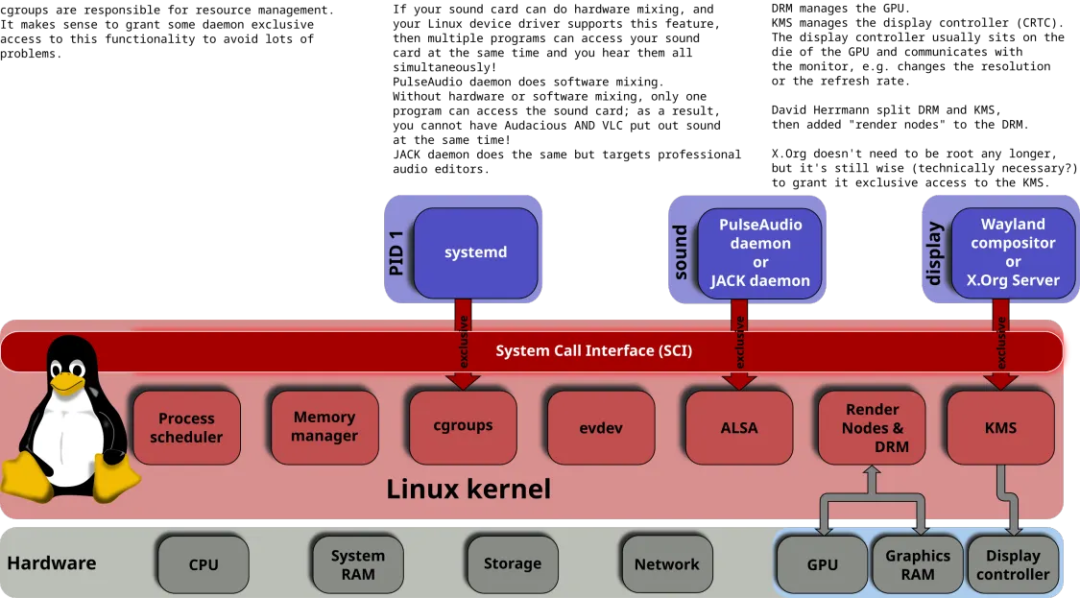
在早期,想要使用图形帧缓冲的用户空间程序也负责提供模式设置操作,因此它们需要以特权访问显卡硬件的方式运行。在类 Unix 操作系统中,X 服务器是最显著的例子,它的模式设置实现位于针对每种特定类型显卡的 DDX 驱动程序中。这个方法后来被称为用户空间模式设置(User Space Mode-Setting,简称 UMS),并引发了一些问题。它不仅破坏了操作系统应该提供的程序与硬件之间的隔离,导致稳定性和安全性问题,而且如果两个或多个用户空间程序同时尝试执行模式设置,可能会使显卡处于不一致的状态。为了避免这些冲突,X 服务器实际上成为了唯一执行模式设置操作的用户空间程序;其他用户空间程序依赖于 X 服务器来设置适当的模式并处理任何与模式设置相关的操作。最初,模式设置只在 X 服务器启动过程中执行,但后来 X 服务器也获得了在运行时执行模式设置的能力。XFree86-VidModeExtension 扩展在 XFree86 3.1.2 中被引入,允许任何 X 客户端请求更改分辨率(modeline)到 X 服务器。VidMode 扩展后来被更通用的 XRandR 扩展取代。
然而,这并不是 Linux 系统中唯一进行模式设置的代码。在系统启动过程中,Linux 内核必须为虚拟控制台设置最基本的文本模式(基于 VESA BIOS 扩展定义的标准模式)。此外,Linux 内核帧缓冲驱动程序中也包含了用于配置帧缓冲设备的模式设置代码。为了避免模式设置冲突,XFree86 服务器——后来是 X.Org 服务器——在用户从图形环境切换到文本虚拟控制台时,会保存其模式设置状态,并在用户切换回 X 时恢复该状态。这个过程会在切换时造成恼人的闪烁,有时还会失败,导致输出显示损坏或无法使用。
用户空间模式设置方法还带来了其他问题:
挂起/恢复过程依赖用户空间工具来恢复之前的模式。任何一个工具的失败或崩溃都可能导致由于模式设置配置错误而使系统无法显示,因此无法使用。当屏幕处于图形模式(例如 X 正在运行)时,内核也无法显示错误或调试信息,因为内核只能知道 VESA BIOS 标准文本模式。更紧迫的问题是,越来越多的图形应用程序绕过 X 服务器,并且出现了其他图形栈替代方案,这使得模式设置代码在系统中进一步重复。为了解决这些问题,模式设置代码被移到了内核中的一个单独位置,具体来说,是现有的 DRM 模块中。然后,所有进程——包括 X 服务器——都可以命令内核执行模式设置操作,内核确保并发操作不会导致不一致的状态。内核中新增的用于执行这些模式设置操作的 API 和代码被称为内核模式设置(Kernel Mode-Setting,简称 KMS)。
内核模式设置提供了几个好处。最直接的好处当然是消除了内核(Linux 控制台、fbdev)和用户空间(X 服务器 DDX 驱动程序)中的重复模式设置代码。KMS 还使得编写替代图形系统变得更加容易,因为它们不再需要自己实现模式设置代码。通过提供集中式的模式管理,KMS 解决了在切换控制台和 X 之间以及不同 X 实例之间的闪烁问题(例如快速用户切换)。由于它位于内核中,因此它也可以在引导过程的早期阶段使用,从而避免了这些早期阶段中的模式变化闪烁。
由于 KMS 是内核的一部分,它可以使用只有内核空间可用的资源,例如中断。例如,挂起/恢复过程后的模式恢复在内核的管理下变得更加简单,并且顺便提高了安全性(不再需要用户空间工具获取 root 权限)。内核还允许轻松地热插拔新的显示设备,解决了长期存在的问题。模式设置还与内存管理密切相关——因为帧缓冲本质上是内存缓冲区——因此与图形内存管理器的紧密集成是强烈推荐的。这就是为什么内核模式设置代码被纳入到 DRM 中,而不是作为单独的子系统的主要原因。
为了避免破坏 DRM API 的向后兼容性,内核模式设置作为某些 DRM 驱动程序的附加驱动程序特性提供。任何 DRM 驱动程序都可以选择在注册到 DRM 核心时提供 DRIVER_MODESET 标志,以表示它支持 KMS API。那些实现了内核模式设置的驱动程序通常被称为 KMS 驱动程序,以此来区分它们与没有 KMS 的旧版 DRM 驱动程序。
KMS 已经被广泛采用,以至于某些没有 3D 加速(或者硬件供应商不想暴露或实现 3D 加速)的驱动程序,仍然实现了 KMS API,而没有实现 DRM API 的其他部分,这样显示服务器(如 Wayland)也可以轻松运行。
KMS device model:
KMS(内核模式设置)将显示控制器的显示输出管道中的硬件块抽象为一系列硬件块来管理和建模输出设备。这些硬件块包括:
CRTCs:每个 CRTC(来自 CRT 控制器)代表显示控制器的扫描引擎,指向一个扫描缓冲区(帧缓冲区)。CRTC 的作用是读取当前在扫描缓冲区中的像素数据,并利用 PLL 电路从中生成视频模式时序信号。可用的 CRTC 数量决定了硬件能够同时处理多少独立的输出设备,因此,为了使用多显示器配置,每个显示设备至少需要一个 CRTC。两个(或更多)CRTC 也可以在克隆模式下工作,如果它们从同一个帧缓冲区扫描输出,相同的图像将被发送到多个输出设备。Connectors:连接器表示显示控制器将视频信号从扫描操作发送到显示的地方。通常,KMS 中的连接器概念对应于硬件中的物理连接器(VGA、DVI、FPD-Link、HDMI、DisplayPort、S-Video 等),在这些连接器上,输出设备(如显示器、笔记本电脑面板等)通常是永久连接的,或者可以临时连接。有关当前物理连接的输出设备的信息(例如连接状态、EDID 数据、DPMS 状态或支持的视频模式)也存储在连接器中。
Encoders:显示控制器必须使用适合目标连接器的格式对来自 CRTC 的视频模式时序信号进行编码。编码器表示能够执行这些编码操作的硬件块。数字输出的编码示例有 TMDS 和 LVDS;对于 VGA 和电视输出等模拟输出,通常使用特定的 DAC(数字模拟转换)块。每个连接器只能接收来自一个编码器的信号,并且每种类型的连接器只支持某些编码类型。此外,可能存在额外的物理限制,导致并非每个 CRTC 都能连接到每个可用的编码器,从而限制了 CRTC-编码器-连接器的可能组合。
Planes:平面(plane)不是一个硬件块,而是一个包含缓冲区的内存对象,扫描引擎(CRTC)从中获取数据。持有帧缓冲区的平面称为主平面,每个 CRTC 必须与一个主平面关联,因为它是 CRTC 用来确定视频模式(显示分辨率、像素大小、像素格式、刷新率等)的源。如果显示控制器支持硬件光标叠加层,CRTC 还可能有与之关联的光标平面;或者如果它能够从额外的硬件叠加层扫描输出并“实时”合成或混合最终图像,则可能有附加平面。
Render nodes:
在原始的 DRM API 中,DRM 设备 /dev/dri/cardX 被用于既包括特权操作(如模式设置、其他显示控制)也包括非特权操作(如渲染、GPGPU 计算)。出于安全原因,打开关联的 DRM 设备文件需要特殊权限,这些权限相当于 root 权限。这导致了一种架构,其中只有一些可靠的用户空间程序(如 X 服务器、图形合成器等)可以完全访问 DRM API,包括像模式设置 API 这样的特权部分。其他希望进行渲染或执行 GPGPU 计算的用户空间应用程序,必须通过使用特殊的身份验证接口由 DRM 设备的所有者(“DRM Master”)授予权限。然后,这些经过身份验证的应用程序可以使用受限版本的 DRM API 进行渲染或计算,但不能执行特权操作。这个设计带来一个严苛的限制:必须始终有一个正在运行的图形服务器(如 X 服务器、Wayland 合成器等)充当 DRM 设备的 DRM-Master,这样其他用户空间程序才能被授权使用设备,即使在不涉及任何图形显示的情况下,如 GPGPU 计算。
“渲染节点”(render nodes)概念试图通过将 DRM 用户空间 API 拆分为两个接口——一个特权接口和一个非特权接口——来解决这些场景,并为每个接口使用独立的设备文件(或“节点”)。对于每个 GPU,如果其对应的 DRM 驱动程序支持渲染节点功能,它会创建一个设备文件 /dev/dri/renderDX,即渲染节点,除此之外还会创建主节点 /dev/dri/cardX。使用直接渲染模型的客户端和希望利用 GPU 计算功能的应用程序,可以通过简单地打开任何现有的渲染节点并使用该节点支持的受限子集 DRM API 来执行 GPU 操作,而无需额外的特权——前提是它们拥有打开设备文件的文件系统权限。需要模式设置 API 或任何其他特权操作的显示服务器、合成器及其他任何程序,必须打开标准的主节点,以访问完整的 DRM API,并像往常一样使用它。渲染节点明确禁止 GEM flink 操作,以防止使用不安全的 GEM 全局名称共享缓冲区;只有 PRIME(DMA-BUF)文件描述符可以用于与其他客户端(包括图形服务器)共享缓冲区。
内容参考翻译:
https://en.wikipedia.org/wiki/Direct_Rendering_Manager
 0
0










