
互连系统的范围比较广,包含了PCB上的互连,也包括了芯片之间的互连和芯片内部的互连,还包括了系统之间的互连等等。互连不在是简单的连连看或者施工布线,互连已经变得越来越重要。

英伟达对于计算系统拓展的愿景:未来数据中心将取代单个芯片,成为计算系统的基本单元,而数据中心也会像芯片一样持续迭代计算能力,不断优化性能和能效。如同芯片依赖架构和制程工艺创新从而实现性能升级一样,高速、高带宽、低延迟的互连解决方案对于数据中心规模化计算也十分关键。
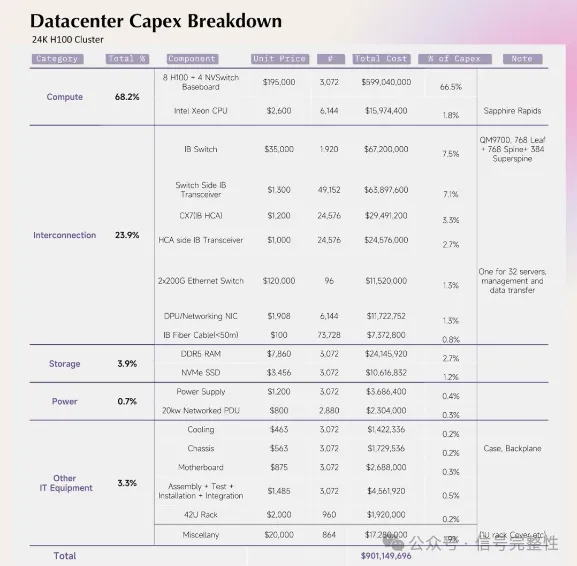
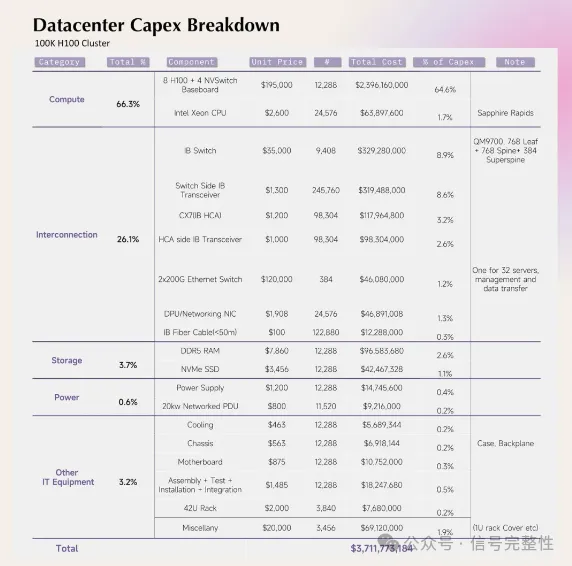
互连环节是计算中心除了计算芯片之外的第二大成本,并且随着 datacenter 规模的提升,互连成本的占比也会增加。以 Meta 的 24k-GPU 计算集群为例,Compute 部分成本为 68.2%,而互连占到了 23.9%,而在 100k-GPU 的情况下,互连则占到了 26.1%,计算芯片的占比为 66.3%。
带来计算中心互连升级的还有技术侧的变化。提升互连与宽带的升级的关键技术有 CXL(Compute Express Link)和 CPO(Copackage Optic) ,二者交汇有望成为下一代计算中心的主要变革。
1. HBM 为 GPU和 ASIC 提供高带宽内存,高带宽能够支持模型训练和推理中的大规模并行计算,HBM 虽然提供了高带宽,但当前的内存容量有限;
2. CXL 可以将大容量 DRAM 资源共享给加速器,从而扩展 HBM 的有效容量。
3. CPO 作为光互连技术能够提供更高带宽、更低延迟的CPU-加速器、加速器-内存链路。
HBM、CXL 和 CPO 单点技术的突破都在为下一代计算中心和互连升级,当三者能够有机结合时,数据中心架构会被重构。
CXL
CXL 由 Intel 和 AMD 在 2019 年提出,它是对上一代计算机硬件传输协议 PCIe 的升级,能够让各个计算机部件(计算芯片、内存、硬盘和互联设备等)之间进行高速数据传输,让它们更好的协同工作。
CXL 之于 PCIe 的升级主要体现在:不仅可以提供 PCIe 的传输功能,还支持组网,从而增强了各个设备间的内存共享和互操作性,还降低了设备间的响应延迟、提升了数据传输带宽,更重要的是,CXL 协议下允许对服务器的每一个部件都分解并池化,CXL 所具备的内存池化能力也是 CXL 替代 PCIe 过程中最值得期待的变革性应用。

在服务器的通讯主要依赖于 PCIe Switch。GPU 能从 CPU 获取指令和内存数据,并通过 NIC 与其他 GPU 进行协作,随着 GPU 数量的增长,对 PCIeCXL 的需求也会相应递增,
在常见的服务器中,这样的通讯主要依赖 PCIe Switch,GPU 能从从 CPU 获取指令和内存数据,从 NIC 和数万张 GPU 进行协作。PCIe/CXL Switch 将在未来 3-5 年内以 30% 左右的 CAGR 从 8 亿美元扩展到 32 亿美元左右,目前中高端市场由博通全面垄断,由前博通部门主管所创立的 Xconn 计划在 25 年开始大规模量产,Xconn 在实现领先的性能的同时又能提供一定的性价比优势,作为创业团队也会在 CXL 环节威胁博通的市场地位。

CPO
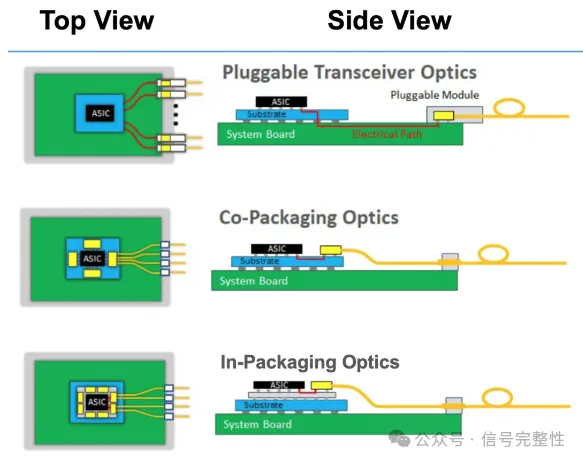
CPO,Coherent Processor Optic是一种基于光学互连技术的高速芯片间互连接口规范,CPO 的核心是通过硅光子学技术将传统互连接口集成到光学芯片上,用硅片来构建光子收发器里的所有组件,不仅从原材料角度对传统设计中的不同元件材料进行替代、整合,制作上也复用了成熟的 CPU 制造工艺,这些都有效降低了光模块(Optical Module)的成本。

凭借能耗和可扩展性优势,光学元件(Optics)已经在 Sever-to-Server 的互连上得到应用,例如 Meta 的 VP of Infra 就透露过, Meta 内部的 AI 训练服务器集群已基本采用 Optics,在 NVIDIA 的设计中,有望在 NVLink 6.0-7.0 时实现从电信号向光信号的转化。
伴随对计算提升,Chip-to-Chip 互联环节同样存在光学元件替换传统铜线通讯的需求,但对 Optics 的体积和成本提出了更进一步的要求,硅光子学的成熟成功解决了这部分问题,预计会成为 Chip-to-Chip 互连的主流解决方案。
芯片层的互连涵盖了 Die-to-Die 和 Chip-to-Chip 两部分,其中,Die 间互连解决的是单颗芯片内不同 Die 之间的互连,例如,是计算芯片公司主要的迭代路径。Chip-to-Chip 则解决的是单个服务器节点内的不同独立芯片之间互连需求。
Die-to-Die
Die-to-Die 能够让不同的单独的硅芯片直接连接起来,从而在这些硅片之间它们快速共享数据、提升计算性能、降低延迟。Die 间互连已经成为计算芯片公司主要的迭代路径。
现阶段, Die-to-Die 互连主要依赖 TSMC 迭代 CoWos 来升级 2.5D 封装。TSMC COWOS 的目前年收入大概在 40 亿美元,市场预期 CoWos 未来会保持 50% 以上的 CAGR,预计未来会是很大的赛道。不过也有市场观点认为,TSMC 不太可能在落后制程上做过多 Capex 投入,这可能会带来 CoWos 长期产能不足的风险。
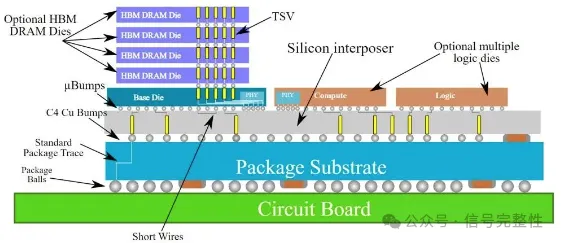
而在 3D 封装层面,目前 TSMC 和 Intel 只提供了概念性的技术展示,除了巨头外,例如 Whalechip 这样的早期团队在做类似尝试,并且技术方案更为激进。TSMC 的 3D 封装最多做到 2 层,但 Whalechip 可以做到 3 层。
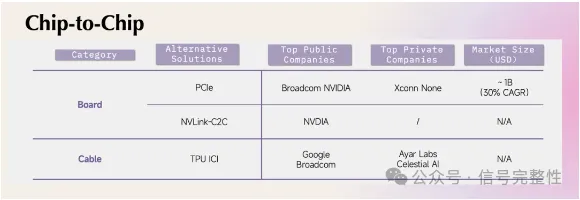
Chip-to-Chip
Chip 间互连主要涵盖的是 CPU、GPU 和 Network Interface Card(NIC)之间的互连,现阶段,片间互连环节的主流技术路径包括了 PCIe(Peripheral Component Interconnect Express)、NVLink-C2C和Google的TPU ICI(Inter-Chip Interconnect)。
LLM 热潮带来对算力需求的升级,算力的可扩展性(Scalability)也成为芯片公司的重要竞争指标,NVIDIA 凭借 NVLink 在模型训练市场占据了领先优势,也驱动计算中心的互连架构的变化。
• NVLink
由于 NVIDIA 不满于 PCIe 的弱性能和过慢的迭代速度,自己研发了 NVLink-C2C 来提升互连性能。
NVLink 协议之所能比传统 Ethernet 协议更快,根本原因是砍掉了 Server-to-Server 架构下的复杂网络功能,例如端到端重试、自适应路由和数据包重新排序等,并将 CUDA 和 NVLink 协议结合,从而实现了极高带宽和能耗的互连性能。例如 B100 采用的 NVLink C2C 速率已能做到 1.8TB/s,是 PCIEv5 128GB/s 的 14 倍左右。


Nvidia 在这个环节的超前布局也迫使博通的 PCIE Switch 和谷歌 TPU ICI 去追求更极致的性能,甚至采用或收购初创公司的前沿技术实现追赶。
• Google ICI
Google TPU 则采用了和 Braodcom 合研的 ICI 系统,可以看到,同张主板上的 4 片 TPU 通过光缆进行互连,TPU v5p 的互联速率高达 600GB/s,是 PCIEv5 128GB/s 的 5 倍左右。
Broadcom 所提供业界领先的 HBM PHY 和 SerDes IP 是 Google 选择 Braodcom 的重要原因,但 TPUv6 预计将采用独立的互连芯片,类似于 Ayar Labs 所提供的技术方案,以追求更极致的互连性能,但其目前正在考量多个替代方案的性能和兼容性。
 0
0







