
在本教程中,你将学习如何使用OpenCV,Keras / TensorFlow和Deep Learning训练COVID-19面罩检测器。
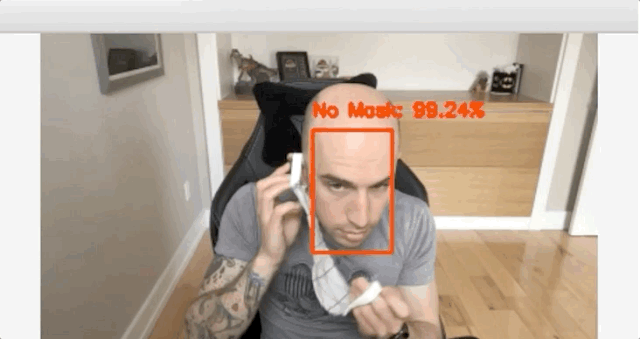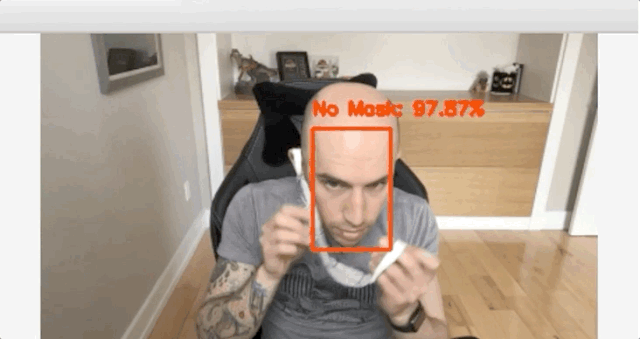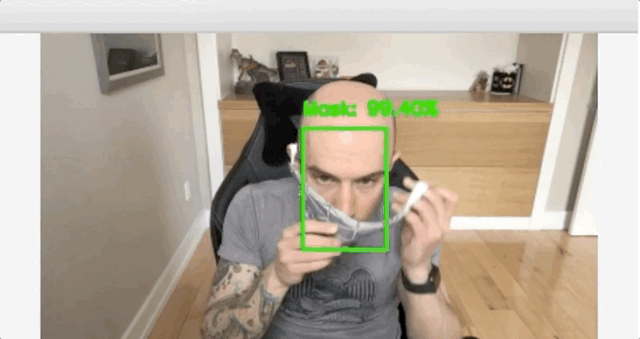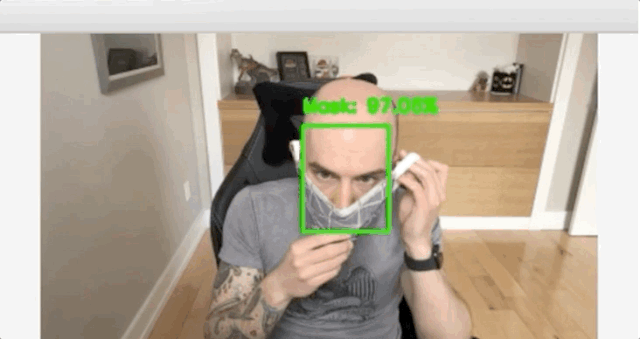
在使用Keras和TensorFlow的数据集上训练一个面罩检测器,然后使用这个Python脚训练口罩检测器并检查结果。
-
在图像中检测COVID-19口罩
-
检测实时视频流中的口罩
具体的实现过程主要分成两个阶段:
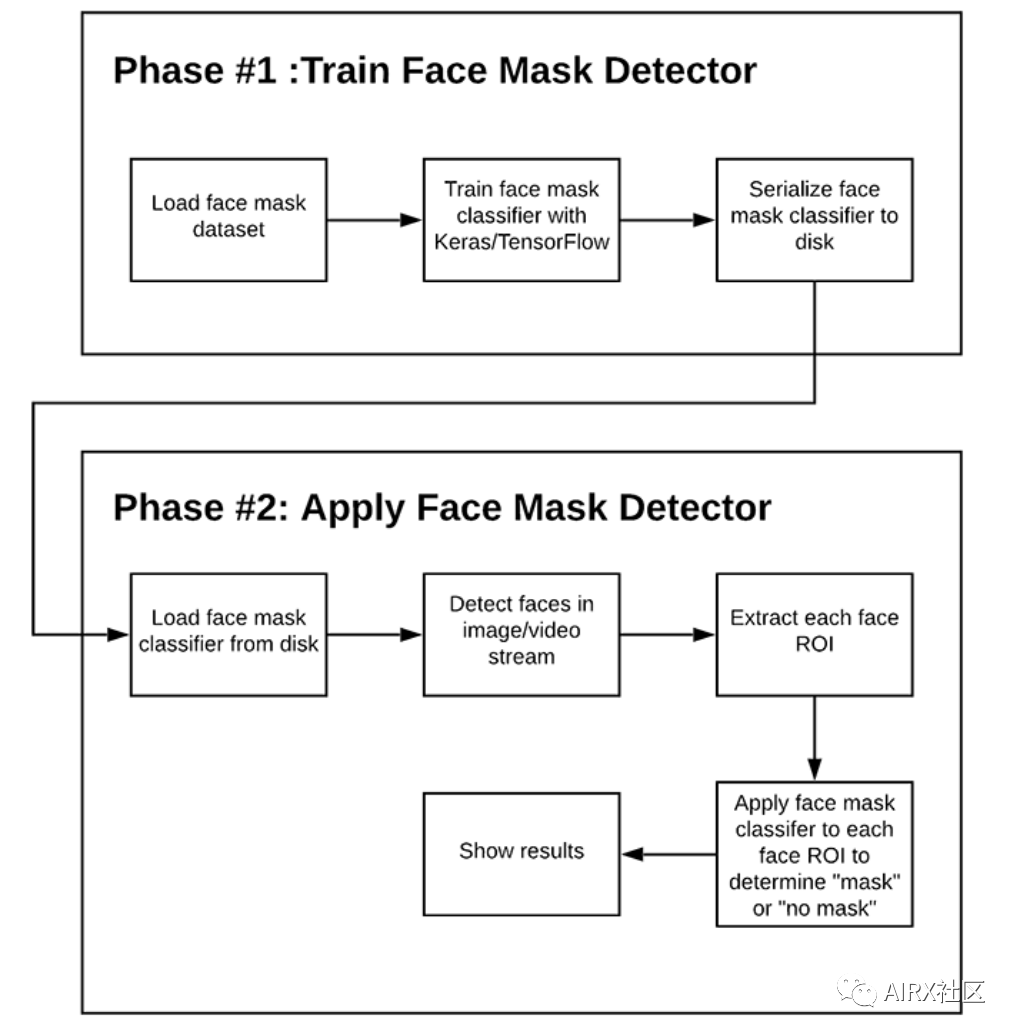
为了训练一个自定义口罩检测器,我们需要将我们的项目分为两个不同的阶段,每个阶段都有其各自的子步骤(如上图所示):
-
培训:这里我们主要从磁盘加载口罩检测数据集,在该数据集上培训一个模型(使用Keras/TensorFlow),然后将口罩检测器序列化到磁盘
-
部署:一旦口罩检测器接受了训练,我们就可以加载口罩检测器,执行人脸检测,然后将每个脸分类为with_mask或without_mask
我们的COVID-19面罩检测数据集,此数据集包含1,376张图像,类别:
-
with_mask:690张图片
-
without_mask:686张图片

数据集下载链接:
https://link.zhihu.com/?target=https%3A//t.dripemail2.com/c/eyJhY2NvdW50X2lkIjoiNDc2ODQyOSIsImRlbGl2ZXJ5X2lkIjoibXFobzZ6OGpnbWJhYWRibzB1MDIiLCJ1cmwiOiJodHRwczovL3MzLXVzLXdlc3QtMi5hbWF6b25hd3MuY29tL3N0YXRpYy5weWltYWdlc2VhcmNoLmNvbS9mYWNlLW1hc2stZGV0ZWN0aW9uL2ZhY2UtbWFzay1kZXRlY3Rvci56aXA_X19zPXoyNW04eW9idG41NnR3enZ6eGI3In0
面部标志可以让我们自动推断出面部结构的位置,包括:眼睛、眉毛、鼻子、口、颚线。要使用面部标志构建戴着口罩的面部数据集,我们首先需要从不戴着口罩的人的图像开始:

我们应用面部检测(opencv)来计算图像中面部的边界框位置:

使用OpenCV和NumPy切片提取面部ROI:

然后,我们使用dlib 检测面部标志(能够定位眼睛,鼻子,嘴巴等)以便我们知道将遮罩放置在脸上哪里:

接下来,我们需要一张带有透明背景的蒙版图像,例如以下图像,COVID-19 冠状病毒面罩/护罩的示例。由于我们知道面部标志位置,因此该面罩将自动覆盖在原始面部ROI上:

然后调整面罩的大小并旋转,将其放在脸上:

然后,我们可以对所有输入图像重复此过程,从而创建人造面罩数据集:

涵盖如何使用ROI将蒙版应用于面部的方法不在本教程的讨论范围之内,但是,如果你想了解更多信息,可以查看:
https://github.com/prajnasb/observations/tree/master/mask_classifier/Data_Generator
项目结构
下载文件之后的目录结构如下:
$ tree --dirsfirst --filelimit 10.├── dataset│ ├── with_mask [690 entries]│ └── without_mask [686 entries]├── examples│ ├── example_01.png│ ├── example_02.png│ └── example_03.png├── face_detector│ ├── deploy.prototxt│ └── res10_300x300_ssd_iter_140000.caffemodel├── detect_mask_image.py├── detect_mask_video.py├── mask_detector.model├── plot.png└── train_mask_detector.py5 directories, 10 files
数据集/目录包含“COVID-19口罩检测数据集”的数据。提供了三个图像示例,以便你可以测试静态图像口罩检测器。在本教程中,我们将使用三个Python脚本:
-
train_mask_detector.py:接受我们的输入数据集并对MobileNetV2进行微调,以创建我们的mask_detector.model。同时制作了包含精度/损失曲线的训练历史图。
-
detect_mask_image.py:使用静态图像中执行口罩检测
-
detect_mask_video.py:使用camera流
训练脚本
接下来使用Keras和TensorFlow训练分类器,以自动检测一个人是否戴着口罩。打开 train_mask_detector.py 文件并插入以下代码:
# import the necessary packagesfrom tensorflow.keras.preprocessing.image import ImageDataGeneratorfrom tensorflow.keras.applications import MobileNetV2from tensorflow.keras.layers import AveragePooling2Dfrom tensorflow.keras.layers import Dropoutfrom tensorflow.keras.layers import Flattenfrom tensorflow.keras.layers import Densefrom tensorflow.keras.layers import Inputfrom tensorflow.keras.models import Modelfrom tensorflow.keras.optimizers import Adamfrom tensorflow.keras.applications.mobilenet_v2 import preprocess_inputfrom tensorflow.keras.preprocessing.image import img_to_arrayfrom tensorflow.keras.preprocessing.image import load_imgfrom tensorflow.keras.utils import to_categoricalfrom sklearn.preprocessing import LabelBinarizerfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import classification_reportfrom imutils import pathsimport matplotlib.pyplot as pltimport numpy as npimport argparseimport os
上述import的目的主要是:
-
数据增加
-
加载MobilNetV2分类器(我们将使用预先训练的ImageNet权重对该模型进行微调)
-
预处理
-
加载图像数据
我们使用scikit-learn (sklearn)对类标签进行二值化,对数据集进行分段,并打印分类报告。imutils路径实现将帮助我们在数据集中查找和列出图像。我们将使用matplotlib来绘制训练曲线。
接下来来分析一些命令行参数,从终端启动脚本:
# construct the argument parser and parse the argumentsap = argparse.ArgumentParser()ap.add_argument("-d", "--dataset", required=True, help="path to input dataset")ap.add_argument("-p", "--plot", type=str, default="plot.png", help="path to output loss/accuracy plot")ap.add_argument("-m", "--model", type=str, default="mask_detector.model", help="path to output face mask detector model")args = vars(ap.parse_args())
--dataset:面部和带有口罩的面部的输入数据集的路径
--plot:输出训练历史plot的路径,它将使用matplotlib生成
--model:生成的序列化口罩分类模型的路径
INIT_LR = 1e-4EPOCHS = 20BS = 32
在这里,我指定了超参数常量,包括初始学习率、训练时间和批处理大小。稍后,我们将应用一个学习速率衰减时间表,这就是为什么我们将学习速率变量命名为INIT_LR。
至此,我们已经准备好加载和预处理的训练数据:
# grab the list of images in our dataset directory, then initialize# the list of data (i.e., images) and class imagesprint("[INFO] loading images...")imagePaths = list(paths.list_images(args["dataset"]))data = []labels = []# loop over the image pathsfor imagePath in imagePaths: # extract the class label from the filename label = imagePath.split(os.path.sep)[-2] # load the input image (224x224) and preprocess it image = load_img(imagePath, target_size=(224, 224)) image = img_to_array(image) image = preprocess_input(image) # update the data and labels lists, respectively data.append(image) labels.append(label)# convert the data and labels to NumPy arraysdata = np.array(data, dtype="float32")labels = np.array(labels)
上面的代码行假设你的整个数据集足够小,可以装入内存。如果数据集大于可用内存,我建议使用HDF5。
# perform one-hot encoding on the labelslb = LabelBinarizer()labels = lb.fit_transform(labels)labels = to_categorical(labels)# partition the data into training and testing splits using 80% of# the data for training and the remaining 20% for testing(trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.20, stratify=labels, random_state=42)# construct the training image generator for data augmentationaug = ImageDataGenerator( rotation_range=20, zoom_range=0.15, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15, horizontal_flip=True, fill_mode="nearest")
数据将采用以下格式:
$ python train_mask_detector.py --dataset dataset [INFO] loading images...-> (trainX, testX, trainY, testY) = train_test_split(data, labels,(Pdb) labels[500:]array([[1., 0.], [1., 0.], [1., 0.], ..., [0., 1.], [0., 1.], [0., 1.]], dtype=float32)(Pdb)
我们标签数组的每个元素都由一个数组组成,在训练过程中,我们将对图像进行动态突变,以提高泛化能力。随机旋转、缩放、剪切、偏移和翻转参数。我们将在训练时使用aug对象。我们需要准备MobileNetV2微调:
# load the MobileNetV2 network, ensuring the head FC layer sets are# left offbaseModel = MobileNetV2(weights="imagenet", include_top=False, input_tensor=Input(shape=(224, 224, 3)))# construct the head of the model that will be placed on top of the# the base modelheadModel = baseModel.outputheadModel = AveragePooling2D(pool_size=(7, 7))(headModel)headModel = Flatten(name="flatten")(headModel)headModel = Dense(128, activation="relu")(headModel)headModel = Dropout(0.5)(headModel)headModel = Dense(2, activation="softmax")(headModel)# place the head FC model on top of the base model (this will become# the actual model we will train)model = Model(inputs=baseModel.input, outputs=headModel)# loop over all layers in the base model and freeze them so they will# *not* be updated during the first training processfor layer in baseModel.layers: layer.trainable = False
通过准备好数据并进行模型调整以进行微调,我们现在可以编译和训练面罩检测器网络了:
# compile our modelprint("[INFO] compiling model...")opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"])# train the head of the networkprint("[INFO] training head...")H = model.fit( aug.flow(trainX, trainY, batch_size=BS), steps_per_epoch=len(trainX) // BS, validation_data=(testX, testY), validation_steps=len(testX) // BS, epochs=EPOCHS)
训练完成后,我们将在测试集中评估结果模型:
# make predictions on the testing setprint("[INFO] evaluating network...")predIdxs = model.predict(testX, batch_size=BS)# for each image in the testing set we need to find the index of the# label with corresponding largest predicted probabilitypredIdxs = np.argmax(predIdxs, axis=1)# show a nicely formatted classification reportprint(classification_report(testY.argmax(axis=1), predIdxs, target_names=lb.classes_))# serialize the model to diskprint("[INFO] saving mask detector model...")model.save(args["model"], save_format="h5")
我们的最后一步是绘制精度和损耗曲线:
# plot the training loss and accuracyN = EPOCHSplt.style.use("ggplot")plt.figure()plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")plt.title("Training Loss and Accuracy")plt.xlabel("Epoch #")plt.ylabel("Loss/Accuracy")plt.legend(loc="lower left")plt.savefig(args["plot"])
训练COVID-19面罩检测器
现在,我们准备使用Keras,TensorFlow和Deep Learning训练我们的面罩检测器。确保在文章开头下载源代码和面罩数据集。从那里打开一个终端,然后执行以下命令:
$ python train_mask_detector.py --dataset dataset[INFO] loading images...[INFO] compiling model...[INFO] training head...Train for 34 steps, validate on 276 samplesEpoch 1/2034/34 [==============================] - 30s 885ms/step - loss: 0.6431 - accuracy: 0.6676 - val_loss: 0.3696 - val_accuracy: 0.8242Epoch 2/2034/34 [==============================] - 29s 853ms/step - loss: 0.3507 - accuracy: 0.8567 - val_loss: 0.1964 - val_accuracy: 0.9375Epoch 3/2034/34 [==============================] - 27s 800ms/step - loss: 0.2792 - accuracy: 0.8820 - val_loss: 0.1383 - val_accuracy: 0.9531Epoch 4/2034/34 [==============================] - 28s 814ms/step - loss: 0.2196 - accuracy: 0.9148 - val_loss: 0.1306 - val_accuracy: 0.9492Epoch 5/2034/34 [==============================] - 27s 792ms/step - loss: 0.2006 - accuracy: 0.9213 - val_loss: 0.0863 - val_accuracy: 0.9688...Epoch 16/2034/34 [==============================] - 27s 801ms/step - loss: 0.0767 - accuracy: 0.9766 - val_loss: 0.0291 - val_accuracy: 0.9922Epoch 17/2034/34 [==============================] - 27s 795ms/step - loss: 0.1042 - accuracy: 0.9616 - val_loss: 0.0243 - val_accuracy: 1.0000Epoch 18/2034/34 [==============================] - 27s 796ms/step - loss: 0.0804 - accuracy: 0.9672 - val_loss: 0.0244 - val_accuracy: 0.9961Epoch 19/2034/34 [==============================] - 27s 793ms/step - loss: 0.0836 - accuracy: 0.9710 - val_loss: 0.0440 - val_accuracy: 0.9883Epoch 20/2034/34 [==============================] - 28s 838ms/step - loss: 0.0717 - accuracy: 0.9710 - val_loss: 0.0270 - val_accuracy: 0.9922[INFO] evaluating network... precision recall f1-score support with_mask 0.99 1.00 0.99 138without_mask 1.00 0.99 0.99 138 accuracy 0.99 276 macro avg 0.99 0.99 0.99 276weighted avg 0.99 0.99 0.99 276
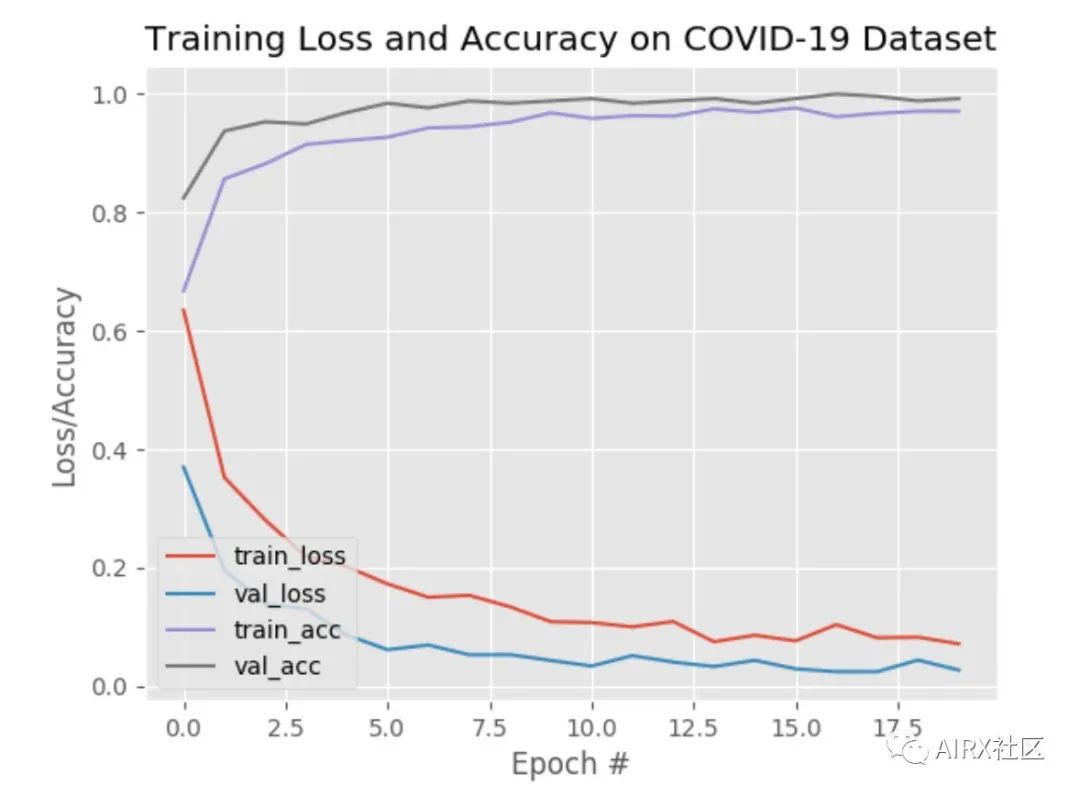
实施COVID-19面罩检测器
现在我们的口罩检测器已经训练好了,让我们学习如何:
-
从磁盘加载输入图像
-
检测图像中的人脸
-
应用我们的口罩检测器来将脸部分类为with_mask或without_mask
打开目录结构中的detect_mask_image.py文件:
# import the necessary packagesfrom tensorflow.keras.applications.mobilenet_v2 import preprocess_inputfrom tensorflow.keras.preprocessing.image import img_to_arrayfrom tensorflow.keras.models import load_modelimport numpy as npimport argparseimport cv2import os
我们的驱动脚本需要三个TensorFlow/Keras导入(1)加载MaskNet模型,(2)预处理输入图像。OpenCV用于显示和图像操作。下一步是解析命令行参数:
# construct the argument parser and parse the argumentsap = argparse.ArgumentParser()ap.add_argument("-i", "--image", required=True, help="path to input image")ap.add_argument("-f", "--face", type=str, default="face_detector", help="path to face detector model directory")ap.add_argument("-m", "--model", type=str, default="mask_detector.model", help="path to trained face mask detector model")ap.add_argument("-c", "--confidence", type=float, default=0.5, help="minimum probability to filter weak detections")args = vars(ap.parse_args())
四个命令行参数包括:
--image:包含用于推理的人脸的输入图像的路径
--face: face detector model目录的路径(在对人脸进行分类之前,我们需要对人脸进行本地化)
--model:我们在本教程前面培训过的口罩检测器模型的路径
--confidence:可选的概率阈值可设置为覆盖50%,以过滤微弱的人脸检测
接下来,我们将加载我们的人脸检测器和口罩分类器模型:
# load our serialized face detector model from diskprint("[INFO] loading face detector model...")prototxtPath = os.path.sep.join([args["face"], "deploy.prototxt"])weightsPath = os.path.sep.join([args["face"], "res10_300x300_ssd_iter_140000.caffemodel"])net = cv2.dnn.readNet(prototxtPath, weightsPath)# load the face mask detector model from diskprint("[INFO] loading face mask detector model...")model = load_model(args["model"])
下一步是加载和预处理一个输入图像:
# load the input image from disk, clone it, and grab the image spatial# dimensionsimage = cv2.imread(args["image"])orig = image.copy()(h, w) = image.shape[:2]# construct a blob from the imageblob = cv2.dnn.blobFromImage(image, 1.0, (300, 300), (104.0, 177.0, 123.0))# pass the blob through the network and obtain the face detectionsprint("[INFO] computing face detections...")net.setInput(blob)detections = net.forward()
知道每张面孔的预测位置后,我们将确保它们满足 --confidence提取faceROIs之前的阈值:
# loop over the detectionsfor i in range(0, detections.shape[2]): # extract the confidence (i.e., probability) associated with # the detection confidence = detections[0, 0, i, 2] # filter out weak detections by ensuring the confidence is # greater than the minimum confidence if confidence > args["confidence"]: # compute the (x, y)-coordinates of the bounding box for # the object box = detections[0, 0, i, 3:7] * np.array([w, h, w, h]) (startX, startY, endX, endY) = box.astype("int") # ensure the bounding boxes fall within the dimensions of # the frame (startX, startY) = (max(0, startX), max(0, startY)) (endX, endY) = (min(w - 1, endX), min(h - 1, endY))
接下来,我们将通过我们的MaskNet模型运行面部ROI:
# extract the face ROI, convert it from BGR to RGB channel # ordering, resize it to 224x224, and preprocess it face = image[startY:endY, startX:endX] face = cv2.cvtColor(face, cv2.COLOR_BGR2RGB) face = cv2.resize(face, (224, 224)) face = img_to_array(face) face = preprocess_input(face) face = np.expand_dims(face, axis=0) # pass the face through the model to determine if the face # has a mask or not (mask, withoutMask) = model.predict(face)[0]
# determine the class label and color we'll use to draw # the bounding box and text label = "Mask" if mask > withoutMask else "No Mask" color = (0, 255, 0) if label == "Mask" else (0, 0, 255) # include the probability in the label label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100) # display the label and bounding box rectangle on the output # frame cv2.putText(image, label, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(image, (startX, startY), (endX, endY), color, 2)# show the output imagecv2.imshow("Output", image)cv2.waitKey(0)
首先,我们根据掩码检测器模型返回的概率确定类标签,并分配一个关联的颜色。with_mask的颜色为“绿色”,without_mask的颜色为“红色”。然后,我们使用OpenCV绘图函数绘制标签文本(包括类和概率),以及用于face的边框矩形。
使用OpenCV在图像中进行COVID-19面罩检测
打开一个终端,执行以下命令:
$ python detect_mask_image.py --image examples/example_01.png [INFO] loading face detector model...[INFO] loading face mask detector model...[INFO] computing face detections...
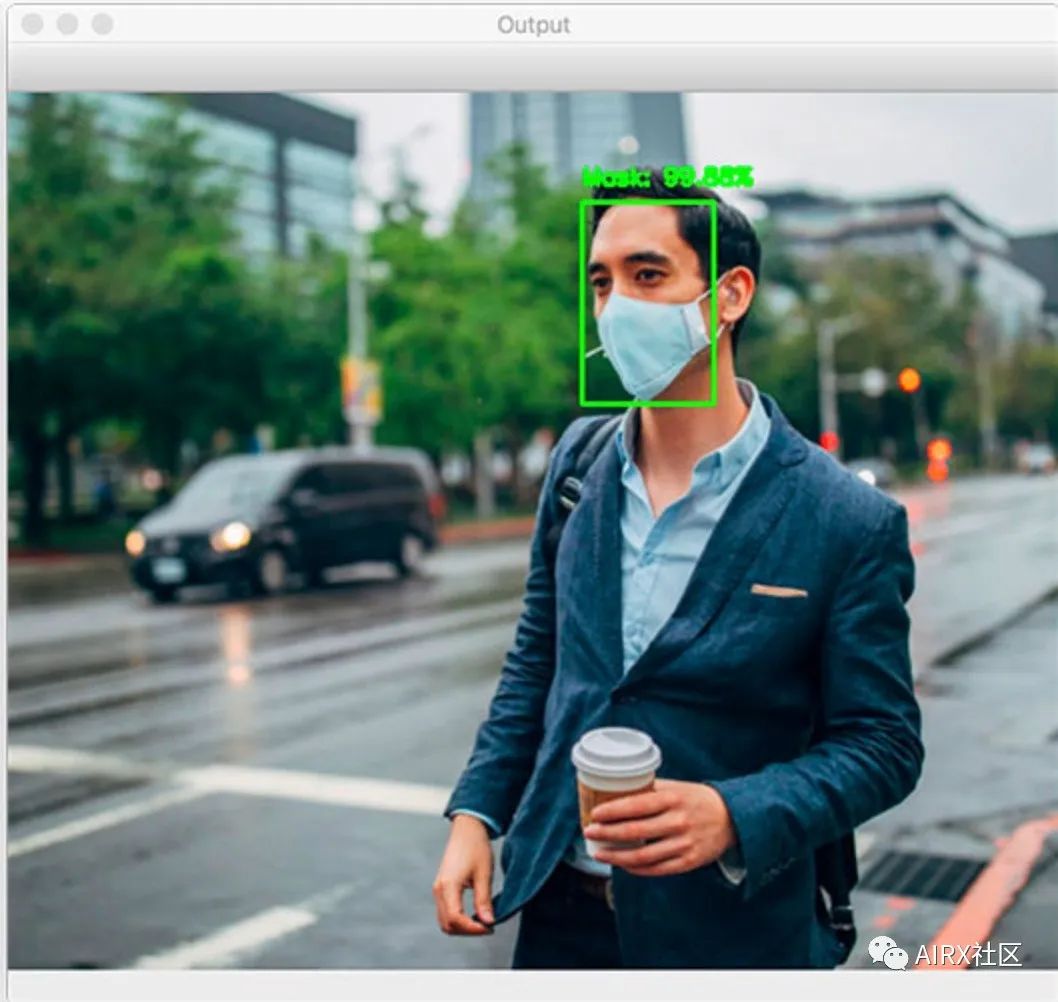
我们的面罩检测器正确地将此图像标记为戴口罩。让我们再看另一张图片,这张是一个没有戴口罩的人:
$ python detect_mask_image.py --image examples/example_02.png [INFO] loading face detector model...[INFO] loading face mask detector model...[INFO] computing face detections...
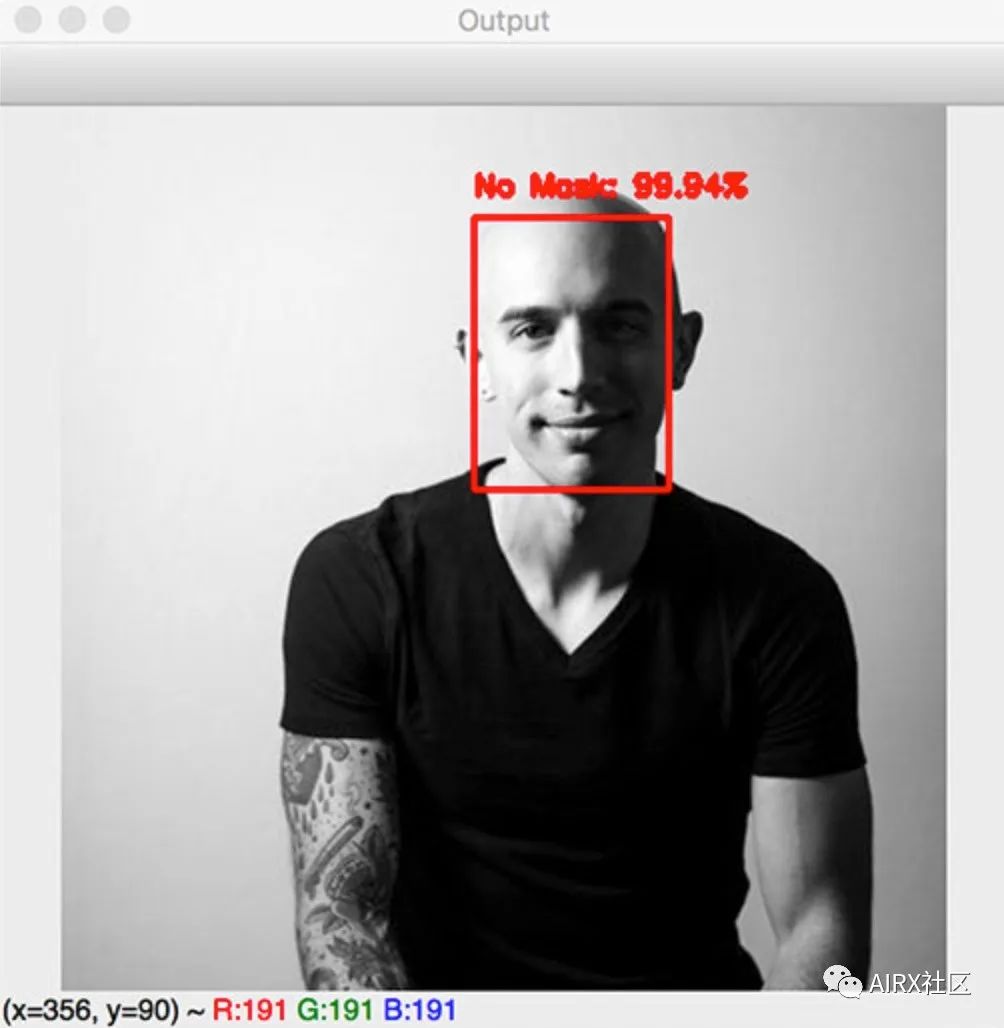
$ python detect_mask_image.py --image examples/example_03.png [INFO] loading face detector model...[INFO] loading face mask detector model...[INFO] computing face detections...

这里发生了什么?为什么我们能够检测到背景中的两位先生的脸,并正确地为他们分类蒙版/无蒙版,但我们无法检测到前景中的女性?请记住,为了区分一个人是否戴着口罩,我们首先需要进行人脸检测——如果没有找到一张脸,那么就不能使用口罩检测器!我们无法在前景中检测到人脸的原因是:它被面具遮住了,用于训练人脸检测器的数据集不包含戴口罩的人的示例图像。因此,如果面部很大一部分被遮挡,我们的面部检测器很可能无法检测到面部。
使用OpenCV在实时视频流中实现COVID-19面罩检测器
打开 detect_mask_video.py文件放在目录结构中,并插入以下代码:
# import the necessary packagesfrom tensorflow.keras.applications.mobilenet_v2 import preprocess_inputfrom tensorflow.keras.preprocessing.image import img_to_arrayfrom tensorflow.keras.models import load_modelfrom imutils.video import VideoStreamimport numpy as npimport argparseimport imutilsimport timeimport cv2import os
我们针对此脚本的面部检测/遮罩预测逻辑位于 detect_and_predict_mas:
def detect_and_predict_mask(frame, faceNet, maskNet): # grab the dimensions of the frame and then construct a blob # from it (h, w) = frame.shape[:2] blob = cv2.dnn.blobFromImage(frame, 1.0, (300, 300), (104.0, 177.0, 123.0)) # pass the blob through the network and obtain the face detections faceNet.setInput(blob) detections = faceNet.forward() # initialize our list of faces, their corresponding locations, # and the list of predictions from our face mask network faces = [] locs = [] preds = []
这个函数检测人脸,然后将我们的人脸面具分类器应用到每个人脸ROI。这样一个函数合并了我们的代码,它可以被移动到一个单独的Python文件中。
我们的detect_and_predict_mask函数接受三个参数:
-
frame帧:我们的流的帧
-
faceNet:用于检测图像中人脸位置的模型
-
maskNet:我们的COVID-19口罩分类器模型
# loop over the detectionsfor i in range(0, detections.shape[2]):# extract the confidence (i.e., probability) associated with# the detection confidence = detections[0, 0, i, 2]# filter out weak detections by ensuring the confidence is# greater than the minimum confidenceif confidence > args["confidence"]:# compute the (x, y)-coordinates of the bounding box for# the object box = detections[0, 0, i, 3:7] * np.array([w, h, w, h]) (startX, startY, endX, endY) = box.astype("int")# ensure the bounding boxes fall within the dimensions of# the frame (startX, startY) = (max(0, startX), max(0, startY)) (endX, endY) = (min(w - 1, endX), min(h - 1, endY))
# extract the face ROI, convert it from BGR to RGB channel # ordering, resize it to 224x224, and preprocess itface = frame[startY:endY, startX:endX]face = cv2.cvtColor(face, cv2.COLOR_BGR2RGB)face = cv2.resize(face, (224, 224))face = img_to_array(face)face = preprocess_input(face)face = np.expand_dims(face, axis=0) # add the face and bounding boxes to their respective # listsfaces.append(face)locs.append((startX, startY, endX, endY))
我们现在准备好让我们的脸通过面具预测器:
# only make a predictions if at least one face was detectedif len(faces) > 0: # for faster inference we'll make batch predictions on *all* # faces at the same time rather than one-by-one predictions # in the above `for` looppreds = maskNet.predict(faces) # return a 2-tuple of the face locations and their corresponding # locationsreturn (locs, preds)
接下来,我们将定义命令行参数:
# construct the argument parser and parse the argumentsap = argparse.ArgumentParser()ap.add_argument("-f", "--face", type=str, default="face_detector",help="path to face detector model directory")ap.add_argument("-m", "--model", type=str, default="mask_detector.model",help="path to trained face mask detector model")ap.add_argument("-c", "--confidence", type=float, default=0.5,help="minimum probability to filter weak detections")args = vars(ap.parse_args())
我们的命令行参数包括:
-
--face:面部检测器目录的路径
-
--model:我们训练好的口罩分类器的路径
-
--confidence:过滤弱脸检测的最小概率阈值
通过我们的导入,便捷功能和命令行 args 准备好了,在循环遍历帧之前,我们只需要处理一些初始化工作:
# load our serialized face detector model from diskprint("[INFO] loading face detector model...")prototxtPath = os.path.sep.join([args["face"], "deploy.prototxt"])weightsPath = os.path.sep.join([args["face"],"res10_300x300_ssd_iter_140000.caffemodel"])faceNet = cv2.dnn.readNet(prototxtPath, weightsPath)# load the face mask detector model from diskprint("[INFO] loading face mask detector model...")maskNet = load_model(args["model"])# initialize the video stream and allow the camera sensor to warm upprint("[INFO] starting video stream...")vs = VideoStream(src=0).start()time.sleep(2.0)
在这里,我们已经初始化了:
-
人脸检测器
-
COVID-19面罩检测仪
-
网络摄像头视频流
让我们继续遍历流中的帧:
# loop over the frames from the video streamwhile True: # grab the frame from the threaded video stream and resize it # to have a maximum width of 400 pixelsframe = vs.read()frame = imutils.resize(frame, width=400) # detect faces in the frame and determine if they are wearing a # face mask or not(locs, preds) = detect_and_predict_mask(frame, faceNet, maskNet)
# loop over the detected face locations and their corresponding# locationsfor (box, pred) in zip(locs, preds):# unpack the bounding box and predictions (startX, startY, endX, endY) = box (mask, withoutMask) = pred# determine the class label and color we'll use to draw# the bounding box and text label = "Mask" if mask > withoutMask else "No Mask" color = (0, 255, 0) if label == "Mask" else (0, 0, 255)# include the probability in the label label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100)# display the label and bounding box rectangle on the output# frame cv2.putText(frame, label, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2)
在我们对预测结果的循环中,我们:
-
打开脸部包围框和蒙版/非蒙版预测
-
确定标签和颜色
-
标注标签和面包围框
-
最后,我们显示结果并执行清理:
# show the output frame cv2.imshow("Frame", frame) key = cv2.waitKey(1) & 0xFF # if the `q` key was pressed, break from the loop if key == ord("q"): break# do a bit of cleanupcv2.destroyAllWindows()vs.stop()
使用OpenCV实时检测COVID-19口罩
你可以使用以下命令在实时视频流中启动掩码检测器:
$ python detect_mask_video.py[INFO] loading face detector model...[INFO] loading face mask detector model...[INFO] starting video stream...
参考:
https://www.pyimagesearch.com/2020/05/04/covid-19-face-mask-detector-with-opencv-keras-tensorflow-and-deep-learning/
 0
0











