
我们前面的文章从一个比较宏观的角度展开,谈到怎么写出一个合格的C++类,在那篇文章里面我们提到了类的321,也就是3个构造,2个赋值和1个析构。那么这篇文章我们就从一个比较微观的角度,通过实现一个自己的string类,来拆解这几个基础函数到底是怎么回事。
不知道大家在学C++的时候有没有这样的困惑:就是看了很多文章,读了很多书,知识点也了解了很多,但是一旦开始写代码的时候眼前就像有一层什么东西挡住一样,自己写的代码总是觉得心里没底。
我自己在很长一段时间里都有这种感觉,后来我总结了一下原因,其中最主要的原因就是我对一个类的运行机制了解得不够透彻。所以,导致不管代码怎么写都觉得有问题,但又不知道哪里有问题。我举几个例子,你感受一下:A a("abc");A a1 = a; A a2;a2 = a;上面的代码中,你觉得a2和a1的运行过程有什么区别?再看一个例子
// 这是《C++ Primer》这本书中的例子class X { int i; int j;public: X(int val): j(val), i(j) {}};上面的代码,你觉得有什么问题吗?再比如
class A{public: A() = default; A(const std::string& name) { name = name; }private: std::string name = "";}; int main() { A a = "Tony";}
上面的代码发生了什么?是合法的吗?你看,要写好C++代码是不是真的不如想象的那般简单?如果上面这几个例子没看明白也没关系,我们这篇文章就是为了解决这些问题的。下面我们就开始来实现一个自己的string类,在实现的过程中来一步步搞明一个类的321。
在C++的标准库中有一个字符串类型std::string,如果之前接触过Java、Golang对于字符串这种类型应该是比较熟悉了,字符串类型在C++的使用也比较简单,比如:#include#include int main() { std::string str = "Hello, World!"; std::cout << str << std::endl;}
要注意,这里的和C语言中的头文件不是一个东西,在C语言中我们引入的是
class Person { ...}; class Bird{ ... };
上面的示例中,Person和Bird各自代表一种类型,这个类型是我们自己定义的,它们的类型分别是Person和Bird。从类型这个角度来看,它和C语言中的struct是一样的。当然,C++中也可以使用struct来声明类,这个本文后面会提到。
回到我们实现string类这件事情上,我们需要创建一个类型来容纳自定义的string,代码如下:class xstring final{ };
还记得面向对象的抽象特性吗?在前面的文章中我们讲,抽象这个词本来就很抽象。那么从抽象到具体其实就是把一个类写出来的完整过程,在这个过程中,每个人对抽象的理解不一样,写出来的代码也就不一样。
上面的代码中,xstring就是一种抽象,它表示的是我们抽象出一个xstring名字的类,用来实现一个类std::string的类。
上面的类里面什么也没有,一个空的类没有实际意义。为了保存字符串的内容,我们需要在这个类中加入一些成员来承载字符串的实际内容,在这里我们使用字符数组作为底层的实现,如下:class xstring final{private: char* m_str; size_t m_len;}
在xstring类中,我们声明了两个私有的类成员,m_str表示底层字符数组,m_len表示字符串的长度,获取字符串长度是一个高频的操作。所以,这里我们直接把字符串的长度保存起来了。
构造函数
一个类有3个基础的构造函数,它们分别是默认和带参构造(也叫构造函数)、拷贝构造、赋值构造,它们的作用就如字面意思一样,用来构造一个类。
上面我们写了一个xstring类,这个类中只有两个成员变量。我们试着用一下,看看会发生什么,如下:int main() { xstring s1; return 0;}
上面我们创建了一个s1对象,代码虽然可以编译通过。但是,在xstring类中m_str是一个指针,当s1这个对象创建的时候,m_str指向哪里是未知的,回忆一下在C语言中如果声明一个指针但没有初始化会发生什么?所以,严格来讲,这里是有问题的。
对于字符串的使用,我们期望在创建的时候给它一个字符串,比如:int main() { xstring s1("Hello World!"); return 0;}
上面的代码是编译不通过的,这是因为,我们没有实现一个带参数的构造函数。你可能觉得奇怪,第一次为什么没报错呢?我们明明一个构造函数都没有啊。这是因为默认情况下编译器会给出一个默认构造函数的实现,这个默认构造函数是没有参数的。
带参构造函数
好了,知道什么问题导致的之后,我们实现一下带参数的构造函数,如下:class xstring{public: xstring(const char *s) { if (s == nullptr) { m_str = new char[1]; if (m_str == nullptr) { exit(-1); } *m_str = '\\0'; m_len = 0; } else { m_len = strlen(s); m_str = new char[m_len + 1]; if (m_str == nullptr) { exit(-1); } strcpy(m_str, s); } }private: char *m_str; size_t m_len;};
这个构造函数传入一个字符指针,我们判断如果传的指针为空,就创建一个空字符串,否则我们就给成员变量m_str创建对应大小的空间,然后将传入的s拷贝到m_str。
上面我们说在不传参数的情况下,因为没有实现默认构造函数,m_str不知道会指到哪里去,实际在使用的时候,并不是一开始就知道要给一个字符串赋什么值的,可能只是先声明一下。比如标准字符串类型的使用是这样的int main() { std::string name;}所以,我们也需要实现一下默认构造函数,如下:
class xstring{public: xstring(): m_len(0) { m_str = new char[1]; if (m_str == nullptr) { exit(-1); } *m_str = '\\0'; } ...private: char *m_str; size_t m_len;};在默认构造函数中,我们创建一个空字符串。其中,m_len(1)表示的是将成员m_len设置成1。这在初始化默认值的时候非常有用。并且我们还可以一下子初始化多个,它们使用逗号分隔就可以了。除了这种方式,还可以使用类成员初始化,比如:
class xstring{public: ...private: char *m_str; size_t m_len = 1;};这样,我们就不用在构造函数中去初始化了。其中我们发现带参数的构造函数中当s==nullptr的时候,代码和默认构造函数里的代码几乎一模一样,还记得我们之前的文章中提到过的委托构造吗?其实,我们也可以将有参构造中s==nullptr条件中的代码委托给默认构造,修改后的代码如下:
class xstring{public: xstring(): m_len(1) { m_str = new char[1]; if (m_str == nullptr) { exit(-1); } *m_str = '\\0'; } xstring(const char *s) { if (s == nullptr) { xstring(); } else { ... } }private: char *m_str; size_t m_len;};
这样看起来代码就更精简了。好了,现在我们终于可以创建出xstring对象了。
拷贝构造
我们在使用C++的字符串的时候,经常会使用另一个字符串来声明并初始化一个字符串,假如我们创建一个s1,又创建一个s2,将s2赋值给s1,如下:xstring s1("Hello World!");xstring s2 = s1;
你觉得会发生什么?
这段代码编译是可以通过的,为了说明问题我们重载一下xstring的io输出,如下:class xstring{public: friend std::ostream& operator<<(std::ostream& os, const xstring& s) { return std::cout << s.m_str; } ...};我们先不管这个io重载是怎么回事,如果看不懂没关系。简单来说,这个重载表示我们可以直接使用std::cout<< s1 << std::endl这种方式将xstring类中的字符串内容输出到标准输出。我们来试着输出一下上面的结果,代码如下:
int main() { xstring s1("Hello World!"); xstring s2 = s1; std::cout << s2 << std::endl; return 0;}输出结果:
s1:Hello World!s2:Hello World!
可以看到,s1和s2的输出是一样的,说明这种方式是可以的。但是这中间到底发生了什么呢?有人可能会说,这不是很明显吗?s1赋值给s2了,你说的没错,确实是这样。但是,我问你一个问题,当s1赋值给s2的时候,s2会执行默认构造函数吗?如果你的回答是确定的,那么请仔细看。
我们做个测试,在xstring类的默认构造函数中输出一个标识,如果默认构造函数执行了一定会输出,如下:class xstring{public: xstring(): m_len(1) { std::cout << "this is default construct" << std::endl; ... }};
你可以自己试一下,上面的代码是不会走到默认构造函数的,这就奇怪了,一般我们说对象的创建一定会走构造函数,但为什么这里没有呢?
这就是我们要引出的第二个构造函数拷贝构造函数了,我们使用一个对象初始化另一个对象的时候就会触发拷贝构造,比如:int main() { xstring s1("Hello World!"); xstring s2 = s1; xstring s3(s2);}上面的代码,s2=s1和s3(s2)都会触发拷贝构造,拷贝构造的函数签名如下:
xstring(const xstring& s);
我们在xstring实现一下拷贝构造,如下:
class xstring{public: ... xstring(const xstring& s) { std::cout << "this is copy construct" << std::endl; }private: char *m_str; size_t m_len;};什么也没干,就输出了一段话,我们再运行一下上面那的那段代码,结果如下:
this is copy constructthis is copy construct可以看到,拷贝构造执行了两次,一次是s2=s1,另一次是s3(s2)。这就是拷贝构造函数,接着,我们自己来实现一下拷贝构造的逻辑,代码如下:
xstring(const xstring& s) { std::cout << "this is copy construct" << std::endl; int len = strlen(s.m_str); m_str = new char[len + 1]; if (m_str == nullptr) { exit(-1); } strcpy(m_str, s.m_str); m_len = len;}拷贝构造的语义是,将传进来的对象赋值给当前对象。其过程大致如下:
s1 = "Hello World!";s2.m_str = s1.m_str;s2.m_len = s1.len;
当然,上面的代码只是伪代码,这段代码是不能正常运行的。
转移构造
在其它编程语言中,比如Java、Golang我们如果将一个对象赋值给另一个对象之后,原来的对象实际上还占着内存空间,需要等到垃圾收集器扫描到,或者函数结束返回的时候才会被回收。比如下面这段Golang的代码:func (u *user) createUser(user User) error { u := model.User{ Username: user.Username, Age : user.Age, CreatedAt: time.Now().Unix(), UpdatedAt: time.Now().Unix(), } err := u.db.insert(&u) ...}
上面的代码,user被传到createUser函数中,然后创建了一个mode,插入到数据库中。实际上,在u这个model创建完之后,user其实就没什么用了,但它必须得等到函数返回才会被销毁。当然,你可能会说为什么不传指针呢?这个是可以的,但这是另外一个话题了。
所以,即使是Golang这种以效率著称的编程语言也是存在这种问题,从C++11标准开始,C++引入了move,也就是移动,或者也叫转移,英文叫(Move Semantics),我个人觉得叫转移可能更贴切一些。
move语义解决的问题场景是,假如现在有一个对象,我们要将它赋值给另一个对象,并且赋值完之后它就没有用了。那么,实现这个功能最好的方案应该是将这个对象的资源(内存)给转让到被赋值的对象上,这样,既避免了新对象开辟空间的开销,又避免了内存销毁的开销(操作系统层的内存管理)。
下面我们就来实现一下转移构造,代码如下:xstring(xstring&& s) { std::cout << "this is move construct" << std::endl; if (s.m_str != nullptr) { m_str = s.m_str; m_len = s.m_len; m_cap = s.m_cap; s.m_str = nullptr; }}
你可以对比一下转移构造和拷贝构造的区别,在拷贝构造中,我们是开辟了新的内存空间,将传进来的m_str拷贝到当前类的m_str中。但转移构造是直接将当前类中的m_str指向传进来的s.m_str,拷贝构造的参数使用了const限定,但转移构造没有使用const,这是因为在转移构造中我们会修改参数s的值。
我们测试一下转移构造,如下:int main() { xstring s1("Hello World!"); xstring s2 = std::move(s1); std::cout << "s2:" << s2 << std::endl; return 0;}
如果我们在上面,经过s2=std::move(s1)之后再尝试输出s1的时候输出的就是空了。
在面向对象编程中,构造函数只会执行一次,也就就是说,上面的三个构造函数并不会同时执行,它们只是在不同的场景下被触发。下面我整理了一张图,画出了各个构造函数执行的场景
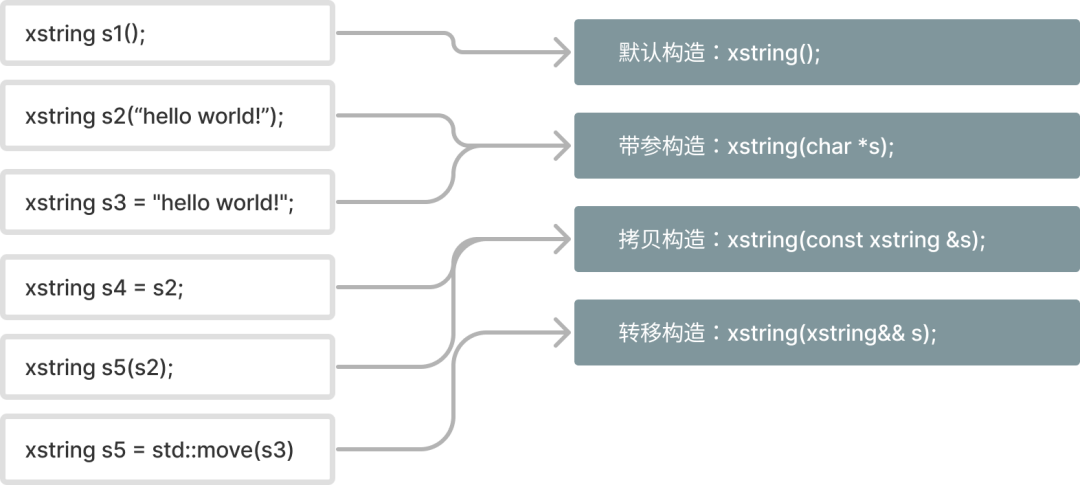
上图中s3可能很多人会觉得奇怪,怎么能把一个字符串直接赋值给一个对象呢?这是因为C++的隐式类型转换起作用了,s3的语义其实和s2是一样的,这里大家要注意一下。
赋值函数
我们上面实现的xstring类,虽然可以正常创建了,但是创建的方式看起来和标准库的string还有差异的。比如int main() { xstring s1 = "hello world!"; xstring s2; s2 = s1; std::cout << s1 << std::endl; return 0;}乍一看,上面的代码和我们之前讲构造函数中的例子没啥区别。但是,注意但是,仔细看了,看下面两组代码
int main() { // 第一组 xstring s1 = "hello world!"; xstring s2; s2 = s1; // 第二组 xstring s3 = "hello world!"; xstring s4 = s3; return 0;}
你觉得上面的s2和s4的创建有区别吗?如果你的答案是没区别,那接下的内容你要睁大眼睛了。
我们首先来看第一组,s1没啥可说的,在赋值那一刻执行了有参构造函数被创建出来了,然后是xstring s2这一行实际上是调用了默认构造函数被创建出来了,接着我们看s2=s1这一行,这一行会报错,这是因为,s2事先已经被创建出来了,现在执行的是赋值操作,而s2对象是没有默认的赋值操作实现的,我们可以编译一下看看到底报什么错xstring.cpp:82:10: error: use of deleted function 'constexpr xstring& xstring::operator=(const xstring&)
这个错是说我们使用了一个已经删除的function:constexpr xstring& xstring::operator=(const xstring&)这个是不是似曾相识,我们在运算符重载的时候有实现过=运算符的重载,这个实际上就是=运算符的重载实现。
那你可能会说,xstring s4=s3看起来和s2差不多,为什么它没有报错呢?这是因为s4并没有触发对象的赋值,在xstring s4=s3这一行直接就构造出了对象s4,而构造s4的正是拷贝构造函数,如果忘了再回过头去看一下拷贝构造函数是怎么回事。
好了,到这里是不是觉得有些毁三观了?开始对C++产生敬畏之心了?C++的难实际上就是难在这些细节上。而C++相对又是比较简单的,简单也是简单在它其实也不过是一堆规则而已…
拷贝赋值函数
为了解决上面的问题,我们来实现一个拷贝赋值函数,如下:class xstring{public: ... xstring& operator=(const xstring &s) { if (this != &s) { delete[] m_str; int len = strlen(s.m_str); m_str = new char[len + 1]; if (m_str == nullptr) { exit(-1); } m_len = len; strcpy(m_str, s.m_str); } return *this; }private: char *m_str; size_t m_len;};
我们判断要赋值的是不是自己,如果不是自己才进行赋值处理。赋值的操作和拷贝构造的逻辑很像。和拷贝构造不一样的地方是,拷贝赋值的时候对象中可能已经存在一个字符串了,所以我们需要先将原来的给清除掉,再重新申请空间。
转移赋值
转移赋值和转移构造也很像,只不过转移赋值是发生在已经存在的两个类之间,而转移构造是发生在类创建的时候。我们来实现一下转移赋值函数class xstring{public: ... xstring& operator=(xstring&& s) { std::cout << "this is = construct" << std::endl; if (this != &s) { delete[] m_str; m_len = s.m_len; m_str = s.m_str; s.m_str = nullptr; } return *this; }private: char *m_str; size_t m_len;};
和转移构造不同的是,转移赋值中被转移对象原来可能已经存在数据了,所以要先清掉再赋值,最后要将转移对象的m_str置为null,这是和拷贝赋值不一样的地方。
析构函数
面向对象中的构函数在对象被销毁时执行,可以做一些收尾的操作。比如,对于我们实现的xstring,当对象被销毁的时候,实际上m_str还在内存中呢?而C++没有runtime,也没有垃圾收集器,如果我们不手动释放m_str的空间,那么它就会一直占用内存,随着xstring类的不断创建就会导致内存泄露。
所以,我们就可以在析构函数中去手动释放m_str,代码如下:class xstring{public: ~xstring() { delete m_str; m_str = nullptr; }private: char *m_str; size_t m_len;};
完善xstring类
上面我们实现了xstring类的创建、赋值以及对象销毁时内存空间的释放。但一般情况下,字符串还有很多其它的操作,比如获取长度,追加子串,判断一个字符串是否包含另一个子串等等。
我们先实现一个函数,用来返回字符串的长度,如下:class xstring{public: size_t len() const { return m_len; }};
是不是很简单,我们在创建、赋值的时候已经维护了m_len,所以这里只需要将m_len返回就可以了。这里敲黑板,函数len()后面的const是什么意思呢?
函数后面的const表示的是返回的值是一个const,不能被修改。放在上面的语义中就是m_len被返回之前,中途是不可以修改它的值的。这个const的出镜率实在是太高了,但这篇文章我们暂时不展开,后面起一篇专门的文章来讲。
总之,一个原则,如果我们非常清楚的知道值不会变就大胆用const去修饰,别人看你代码的时候一定会直呼专业的!
关于,字符串的追加、判断是否存在子串等操作,篇幅有限,本文就不展开了,你可以试着自己去实现一下。
上面的代码其实还有优化的空间,我们来看一段Golang的代码:s := make([]int, 0, 100)
上面的代码是Golang中声明一个切片,元素类型是int,实际长度是0,容量是100,我个人是非常喜欢这种方式的,后面的容量我们可以事先创建一块比较大的空间,这样可以减少后期扩容的开销。我也把这种方式引入到了我们的xstring类中,新加了一个m_cap成员,然后在对应的函数增加了对cap的支持,最后还实现了一个cap的成员函数,用来获取当前的容量,最终代码如下:
class xstring{public: size_t len() const { return m_len; } size_t cap() const { return m_cap; } public: friend std::ostream& operator<<(std::ostream& os, const xstring& s) { return std::cout << s.m_str; } public: xstring() = default; xstring(const char *s) { if (s == nullptr) { m_str = new char[1]; if (m_str == nullptr) { exit(-1); } *m_str = '\\0'; m_len = 0; m_cap = 0; } else { int len = strlen(s); m_str = new char[len + 1]; if (m_str == nullptr) { exit(-1); } strcpy(m_str, s); m_len = len; m_cap = len; } } // 拷贝构造函数 xstring(const xstring &s) { int len = strlen(s.m_str); m_str = new char[len + 1]; if (m_str == nullptr) { exit(-1); } strcpy(m_str, s.m_str); m_len = len; m_cap = len; } // 转移构造函数 xstring(xstring&& s) { if (s.m_str != nullptr) { m_str = s.m_str; m_len = s.m_len; m_cap = s.m_cap; s.m_str = nullptr; } } // 拷贝赋值函数 xstring& operator=(const xstring &s) { if (this != &s) { delete[] m_str; int len = strlen(s.m_str); if (m_cap < len) { m_str = new char[len + 1]; if (m_str == nullptr) { exit(-1); } m_len = len; m_cap = len; } else { memset(m_str, 0, len + 1); m_len = len; m_cap = s.m_cap; } strcpy(m_str, s.m_str); } return *this; } // 移动赋值函数 xstring& operator=(xstring&& s) { if (this != &s) { delete[] m_str; m_str = s.m_str; m_len = s.m_len; m_cap = s.m_cap; s.m_str = nullptr; } return *this; } // 析构函数 ~xstring() { delete[] m_str; m_str = nullptr; } private: char* m_str; size_t m_len; size_t m_cap;};当然,我还希望在初始化的时候可以只指定字符的容量就可以了,我们可以再实现一个带参的构造函数,这个构造函数接收一个size_t的cap,表示字符串的空间容量。代码实现如下:
class xstring{public: ... xstring(const size_t cap) { m_str = new char[cap + 1]; if (m_str == nullptr) { exit(-1); } m_len = 0; m_cap = cap; } ...private: char* m_str; size_t m_len; size_t m_cap;};我们在创建的时候就可以使用下面的代码来创建一个指定容量大小的xstring了:
int main() { xstring s4(5); return 0;}一切看起来都很完美,直到我将代码写成下面这样:
int main() { xstring = 5; return 0;}由于我们有一个参数是size_t的带参构造函数,上面的代码是可以成功运行的。但是,这样就会带来歧义了,比如:
int main() { xstring s1 = "hello world"; xstirng s2 = 5;}是不是看起来奇奇怪怪的?我们希望容量只能使用s2(5)这种方式,这样我们就只保留了参数是char *s的带参构造函数的隐式类型转换。实现也非常简单,我们在对应的构造函数前使用explicit关键字就可以终止隐式类型转换了,如下:
class xstring{public: ... explicit xstring(const size_t cap) { m_str = new char[cap + 1]; if (m_str == nullptr) { exit(-1); } m_len = 0; m_cap = cap; } ...private: char* m_str; size_t m_len; size_t m_cap;};
这样,我们再通过xstring s2 = 5这种方式就会直接报错。进而只能使用s2(5)这种方式。
好了,到这里xstring类就实现完了。对于321的理解,直接会决定实现类的质量,如果你对321理解得不透彻,在写代码的时候会觉得眼睛前面老是被什么东西档着,看不清,写出来的代码老是觉得心里没底。那么这篇文章的目标就是期望可以帮助大家在写代码的时候变得心里有底气。
C++的面向对象编程细节之多,我觉得再用10篇20篇文章也不一定能全讲明白。但是,我们可以先抓住一条主线,今天的321就是非常重要的一条主线,牢牢的抓住这根线一步步往前走,见鬼捉鬼,遇魔杀魔,一步到位的方法是没有的,我觉得学习C++首先要接受这个现实。
接下来我整理几个面向对象中比较重要的点,给大家再唠叨唠叨
再谈抽象与封装
我们上面实现的xstring类,xstring这个类名是抽象,len和cap方法也是抽象。简单点来讲,我们凭空造出一个盒子xstring,然后在它身上挖了两个洞,一个是len,另一个是cap。你不能将这个盒子拆开了去看里面有什么东西?而只能透过这两个洞去看。
这就像是我们买了一台音响,我们不会拆开音响的盒子手动换不同阻值的电阻去调节音量,我们只需要转动音响上的音量旋钮就可以了。这便是封装,封装的好处是屏蔽细节,避免滥用。如果我们自已去换电阻调节音响的音量大小,首先我们要学习怎么使用电阻,电阻的阻值怎么看?会不会超过最大阻值?学习成本太高。厂家标明最小阻值是100欧,我非得换一个1欧的电阻结果可想而知。
在xstring中,我们使用了public和private来控制对象的访问权限,public表示在类的外面也可以访问,private表示只能在class{}的括号内访问。除了public和private之外,c++也支持protected关键字,表示在当前类和子类中可见。
如果我们不显示的指定访问权限呢?比如:class Demo {char *m_str;}这里的*m_str和public的效果和private的效果是一样的。在C++中使用struct也可以定义一个类,比如:
struct { char *m_str;}
此时,m_str和使用public的效果是一样的。
我们再回顾一下上面xstring的代码xstring(const xstring &s) { int len = strlen(s.m_str); m_str = new char[len + 1]; if (m_str == nullptr) { exit(-1); } strcpy(m_str, s.m_str); m_len = len; m_cap = len;}
不知道你有没有觉得奇怪,这里传进来的xstring& s它居然能直接访问一个private的成员m_str。
这里我们可以这么理解,对成员权限的控制是针对象而不是针对类的,在一个类中我们可以访问所有同类对象的所有成员,也就是说,只要是传入的参数和当前对象是同一个类,那么,传入的这个类在当前对象的成员函数中同样可以访问自己的私有成员。
this指针
在C++类中,this有隐身功能,大部分时候我们在类中访问类成员,只需要使用成员的名字就可以了,比如:class xstring{public: ... xstring(const size_t cap) { m_str = new char[cap + 1]; ... m_len = 0; m_cap = cap; } ...private: char* m_str; size_t m_len; size_t m_cap;};
在xstring(const size_t cap)构造函数中,我们直接给m_str、m_len、m_cap赋值,实际上访问的是类成员m_str、m_len和m_cap。不知道你有没有这样的疑问,构造函数不是第一个执行的吗?m_str明明在构造函数后面声明的,那在构造函数中是怎么访问到的呢?
在C++中,或者说在其它支持面向对象的编程语言中,是先将整个类加载完,再去执行构造函数的,这样在构造函数中就能访问成员变量了。所以,我们也可以得出一个结论,成员变量和成员函数的书写不用遵循任何顺序。但是,成员变量在某些情况下是有顺序要求的,比如:class X { int i; int j;public: X(int val): j(val), i(j) {}};
这是我们文中一开始的例子,这段代码是有问题的,类中的成员初始化的顺序是按照定义的先后顺序,上面的例子中,i比j要先初始化。所以,在构造函数初始的时候i(j),j还没有被初始化,这里使用了一个未初始化的j去初始化i。
在C++的类中有一个隐形的this,只是这个this被省略了,如果我们加上this就像下面这样class xstring{public: ... xstring(this, const size_t cap) { ... }};当然,C++中这样写是编译不通过的,但是其它的一些编程语言,比如Python就需要写上这个this
class demo: init(this): // todo setName(this, name): this.name = name;实际上,在C++中虽然函数没有传这个this,我们也可以使用this显式的访问,比如:
class xstring{public: ... xstring(const size_t cap) { this->m_str = new char[cap + 1]; ... this->m_len = 0; this->m_cap = cap; }};
这个this就是指向当前对象的指针。所以,在命名的时候我们要注意,不要使用this这个关键字。
省略this会造成另外一个问题就是重名,比如:class A {public: A(std::string str){ str = str.append(str); }private: std::string str;}
上面的代码中str.append(str),这里的str到底是哪个str呢?所以,一般我们在给成员变量命名的时候都会加一个标识,比如我们的xstring类就使用m_前缀。这样,就可以很大程度上避免重名了。
友元
上面我们还留了一个坑,就是class xstring{public: friend std::ostream& operator<<(std::ostream& os, const xstring& s) { return std::cout << s.m_str; }}这里的friend是个什么玩意儿?这是C++的友元,所谓友元就是说,在别的函数或者类中是无法直接访问当前类中的成员的,如果我们要突破这个限制怎办呢?那就用友元,我们看一段代码你就明白了。
class A{public: A() = default; A(std::string name) { m_name = name; } private: std::string m_name = "";}; void printName(A a) { std::cout << a.m_name << std::endl;} int main() { A a("Tony"); printName(a);}这段代码明显是有问题的,我们在类外边的printName方法中尝试访问对象a中private的m_name。但是,我们只要做一件事件就能使这个操作变得合法,代码如下:
class A{public: A() = default; A(std::string name) { m_name = name; } friend void printName(A a); private: std::string m_name = "";}; void printName(A a) { std::cout << a.m_name << std::endl;} int main() { A a("Tony"); printName(a);}在类A中我们使用friend关键字声明了一个void printName()的函数,这个函数的签名和类外面的printName是一模一样的,我们说将printName方法声明为了类A的友元函数。当然,如果是类函数成员我们只需要加上类名做限定就可以了,比如:
class A{public: A() = default; A(std::string name) { m_name = name; } friend void B::printName(A a);};
好了,到这里今天的内容就结束了。
总结
这篇文章中讲了实现一个类要遵循的一些原则,这篇文章则从更微观的角度实现了一个类,但它还不完整,这里的不完整有两层意思。
第一,这个类本身的功能还不够完整,比如字符串拼接,查找子串等功能都还没实现。
第二,通过这个类的实现并不能完全窥见C++面向对象编程的全貌,依然还有很多细节没法塞进这一篇文章中,这需要大家自己去慢慢探索了。
当然,在后面的文章中还会继续深入面向对象编程,相信很多人学习C++很大的原因里面一定有因为它是支持面向对象编程范式的。所以,学习C++很大程度上就是要搞懂面向对象编程的方方面面,虽然搞明白面向对象所有细节非常困难,但是,我们在抓住一条主线的前提下再慢慢去拓展就会事半功倍,我们说这条主条就是类的321。
 0
0







