
在前面几篇文章中,const出现的频率实在是太高了,这篇文章就让我们一起来手撕const。
const关键字在很多编程语言中都有它的身影,比如JavaScript、Golang、Rust等。当然,我们正在说的C++也是有const的,在一些编程语言中也会有相应的替代方案来实现不可变的特性,比如Java就可以通过final关键字,而Python语言层面虽然没有相应的方案,但社区中通常也会人为约定全大写就表示不能对其进行修改。
const的愿望是,所有被它修饰的变量在程序运行的整个生命周期中,都不可以被改变。我理解这个愿望的背后是对数据安全的考虑,在这个世界上,很多东西不管怎么样,它就是不会被改变的。比如保留2位小数的PI值,它一定是3.14,直角的度数它一定是90度,从三方申请的API访问秘钥,在一定时间内它一定是不会变的。我想,这便是const存在的意义。
const和define有什么区别?
我们在网络编程那个系列文章中,使用的是C语言,我们使用define来定义了一个宏,用来表示服务启动时的端口号,如下:#define SERV_PORT 3000
在C++中如果我们使用const的话,可能就是下面这样
const int serv_port = 3000;
到这里,你可以想一下,宏定义和const有什么不一样?
为了说明这个问题,我们来写一段代码,如下:// main.cpp#define SERV_PORT 3000const int serv_port = 300; int main() { std::cout << SERV_PORT << std::endl; std::cout << serv_port << std::endl; return 0;}在这段码中,我们分别输出SERV_PORT宏和serv_port常量,下面我们预编译一下,看看结果是什么样的
benggee@benggee: g++ -E main.cpp -o tmp_main.cpp
宏的本质其实是替换,在使用它的地方,编译之前会替换成它定义的值。所以,上面的代码中,std::cout << SERV_PORT << std::endl中的SERV_PORT应该会先被替换成3000,我们来看一下。通过-E参数我们将替换后的文件保存到了tmp_main.cpp中,替换后的代码如下:
...const int serv_port = 300; int main() { std::cout << 3000 << std::endl; std::cout << serv_port << std::endl; return 0;}...
替换后的代码有点长,我们直接翻到最后,可以看到,SERV_PORT已经被替换成了3000了,而serv_port并没有被替换。
通过上面的结果,我们可以看出,const和define的区别还是很明显的。第一,const是需要指定一个数据类型的,而define不需要。第二,const是需要内存来存放它的,而define不需要,因为define定义的宏最终都被替换掉了。第三,在调试的时候,你是可以看到const的值的,但是define定义的宏不行,因为在预编译的时候就被替换了。第四,const是可以取地址的,所以它可以作为左值,但define不行。所以,很多书上或者课程上都会叮嘱你不要滥用define,因为define写得太复杂会掉头发的… 哈哈!
const能修饰什么?
修饰普通变量和指针
const可以用来修饰普通的变量和指针,这也是const经常使用的场景。const int len = 1024;const std::string name = "tony";const int *p = &name;int a = 128;int *const p2 = &a;int const * const p3 = &len;上面我们使用const修饰了常用的变量,可以看到,const可以用来修饰变量和指针。对于修饰变量来讲,const的语义是这个变量不能修改,比如:
const int a = 128;a = 256; // 编译报错int *p = &a;*p = 256; // 编译报错
上面的代码说明,即使我们使用指针的方式间接地修改变量a的值也是不被允许的。
对于使用const修饰的指针,其语义是限制通过指针间接改变对应的值,例如:int a = 128;const int *p = &a;*p = 256; // 编译会报错我们使用*p = 256试图修改值,是不允许的。但是,我们是可以通过下面的方式让指针p重新指向另一个变量:
int a = 128;const int *p = &a;int b = 256;p = &b; // 这里是合法的如果我们想要让一个指针第一次赋值之后,就不能指向其它的地址,就可以将对应的变量类型提到const关键字前面,比如:
int a = 128;int *const p = &a;int b = 256;p = &b; // 编译报错
很多人搞不明白,const放在前面和后面的区别是什么,在使用const的时候也是唯唯诺诺,没有信心。其实,我们只需要抠住一句话就可以了,那就是“const修饰的规则是从左到右”,比如const int *p = &a,我们从左到右看,左边没有东西,所以我们看右边,右边是一个int,意思是这个const修饰的是一个int类型的值,而*p加在一起表示的是一个int型的值,所以我们使用p=256是编译不通过的。
再看int *const p = &b,我们从左到右看,const的左边是*号,表示这个const修饰的是一个指针(别忘了指针本身也是一个变量)它也是有地址的。所以,p的地址是不能被改变的,从而就不能指向其它地方了。
我们再来看一个稍微复杂一点的,在前面的代码中,有一行出现了两个constint const * const p3 = &len;
根据从左到右的原则,第一个const修饰的是int类型的变量,第二个const修饰的是一个指针,加在一起它们的语义是p3指针不能指向其它的地址,同时p3指向的内容也不能被修改。比如:
int a = 128;int b = 256;int const * const p = &a; p = &b; // 编译会报错*p = 512; // 编译会报错
修饰对象类型的函数参数
我们前面的文章中经常使用const修饰一个对象类型的函数参数,比如:xstring(const xstring& s) { ...}
这里传引用相信大家应该是理解的,因为我们不想对象发生拷贝,关于引用和指针很多人也满是问号,引用和指针有什么区别?为什么我们要使用引用?关于引用和指针一时半会儿也说不清楚,这个我们后面有机会专门出一篇文章单独讲。
回到上面的代码,我们使用const修饰参数s,表示我们非常确定,在函数中一定不会修改对象s的值。这个值指的是对象中所有的成员。
这种方式建议大家多多使用,这样可以让使用你API的人更加有信心,避免很多不必要的麻烦。
修饰返回对象类型
返回值和参数很像,比如:const Person& buildPersion() { ...} Person p1= buildPersion()
上面的p1是不能进行任何的修改的,即使调用Person的成员函数间接修改也是不行的。
修饰成员函数
严格来讲,const只能修饰类成员函数,它的语义是,这个函数所引用的对象在这个函数运行的过程中是不能被修改的,例如:class Person {public: Person() = default; ~Person() = default; void setName(std::string val) const { name = val; // 编译不通过 }private: std::string name = "default name";};对于const修饰的对象也只能调用const修饰的成员函数,比如:
class Person {public: Person() = default; ~Person() = default; std::string getNameV2() { return name; } std::string getName() const { return name; }private: std::string name = "default name";}; int main() { const Person p; std::cout << p.getName() << std::endl; std::cout << p.getNameV2() << std::endl; // 编译不通过}
走后门
C++的设计者们应该是整个计算机行业最纠结的一群人了,通过const控制住了变量的可变性。可他们想得多,发现很多时候不能一刀切,还是得开个后门,允许修改。
mutable关键字
mutable关键字用于修饰类的成员变量,被mutable修饰的成员变量,即使对象被声明成了const也可以修改,例如:class Person {public: Person() = default; ~Person() = default; void setName(std::string val) const { name = val; } std::string getName() const { return name; }private: mutable std::string name;}; int main() { const Person p; p.setName("tony"); // 这是合法的,因为name被mutable修饰了 std::cout << p.getName() << std::endl;}
很多人可能会觉得不能理解,既然用了const为什么还要用mutable。确实,在很多场景中是有些多余,但在一些特殊的场景,比如我们拿到一个const修饰的对象,而这个对象中有一个锁,我们要获取这个锁就势必会修改这个对象。在这种场合下,我们就可以单独使用mutable来修饰这把锁。
要注意的是,我们不要陷入另一种极端,就是成员变量全都用mutable,这其实就失去了const的意义了。
volatile关键字
volatile关键字用于阻止编译器的优化,在某些场景比如在单片机中读取寄存器的值// 假设 0x4000 是某个硬件寄存器的地址volatile int* reg = reinterpret_cast<volatile int*>(0x4000); void readRegister() { int value = *reg; // 寄存器的值 ...}
上面的例子中,寄存器中的值可能会随着外部传感器接收到的数据而改变,如果没有volatile关键字,编译器会认为没有任何地方修改reg的值,所以就将reg的值缓存起来。下次再去读就读不到新的值了。而在这个场景中,我们期望每次都读取最新的值,这个时候我们就可以使用volatile关键字了。
const是魔法吗?
const并不是魔法,而是有人替我们负重前行,它就是编译器,我们声明了一个全局的变量a,使用g++ -S编译成汇编,如下:
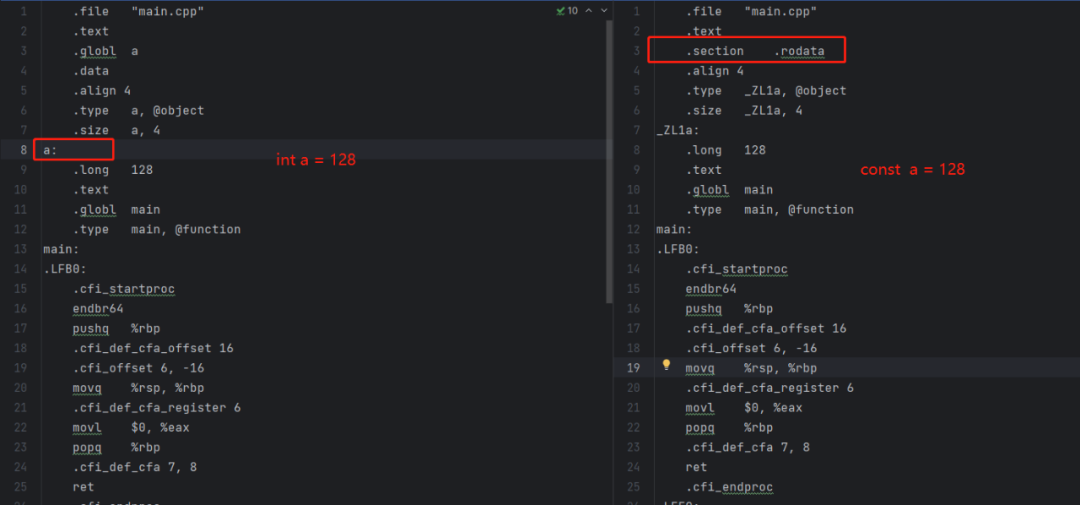
左边是没有const修饰的变量,变量a被定义成了一个新的代码段。而右边是使用const修饰后的情况,可以看到,变量a被放在了一个叫.rodata的代码段中,在这个段中的变量都是只读的。
你看,在你C++前进的每一步编译器都在为你负重前行,是不是觉得很酷呢?
总结
这篇文章也是纠结过后的结果,还是那句话,C++可以讲的东西实在是太多了,决定写这个系列文章是我做过的最正确的决定,也是最掉头发的决定。大家加油!


 0
0









