
一、 前言
DPDK是intel工程师开发的一款用来快速处理数据包的框架,最初的目的是为了证明传统网络数据包处理性能低不是intel处理器导致的,而是传统数据的处理流程导致,后来随着dpdk的开源及其生态的快速发展,dpdk成为了高性能网络数据处理的优秀框架。本篇文章主要介绍DPDK接收与发送报文的流程,包括CPU与网卡DMA协同工作的整个交互流程、数据包在内存、CPU、网卡之间游走的过程。
二、场景
DPDK从2013开始开源,经过前辈们的缝缝补补到现在为止DPDK框架比较成熟、使用比较方便,使得现在开发者在不需要深入了解底层数据包收发原理的情况下也可以做简单的项目开发。但是个人感觉做简单的项目尚且可以应付,如果需要做性能优化等类似的需求时就需要取全面的了解DPDK的收发包机制,因为收发包性能与驱动工作流程、前期初始化配置息息相关。话不多说,下面我们进入正题。
三、收发包处理流程

数据包接收的大体流程:
-
数据包到达网卡
-
网卡经过DMA操作将数据包从网卡拷贝到收包队列
-
DPDK应用从收包队列中取包
数据包发送的大体流程:
-
DPDK应用将数据包送到发包队列
-
网卡经过DMA操作将网卡队列中的数据包拷贝到网卡
-
数据包从网卡发出
收发包流程中的关键操作,主要是网卡如何与DPDK应用交互:
-
网卡的初始化配置操作有哪些,因为网卡要想正常工作肯定需要进行初始化配置一些属性
-
网卡的DMA操作怎么找到DMA 地址,进而将数据包拷贝到系统主存供DPDK读取
-
网卡把数据包成功放到队列后如何通知DPDK应用去队列中读取
-
DPDK从队列中取完数据包后需要做哪些操作通知网卡为下一次收包做准备
-
DPDK将数据包送到发送队列中需要做哪些预操作
-
网卡从发送队列中取包需要做哪些操作
四、收包软件处理流程
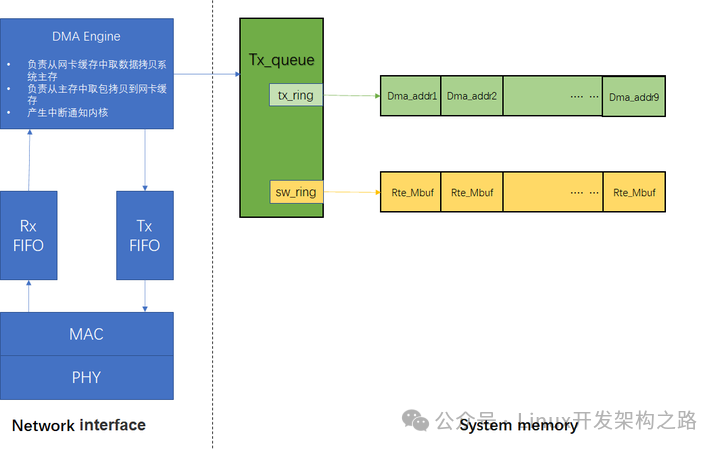
DPDk在初始化阶段通过igb_alloc_rx_queue_mbufs 负责将描述符,mbuf, dma,接收队列给关联起来,如下图所示。
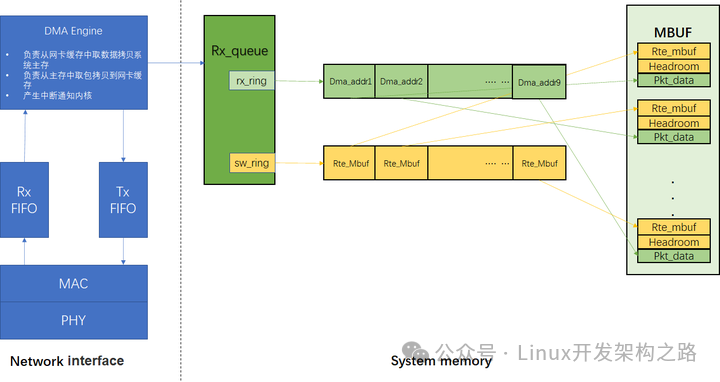
1、模块/硬件介绍
Network interface: 指以太网卡,它工作在OSI的下两层(物理层、数据链路层),工作在物理层的芯片称为PHY,工作在数据链路层的芯片称为MAC控制器,即Media Access Control,即媒体访问控制子层协议.该协议位于OSI七层协议中数据链路层的下半部分,但是目前好多网卡是将MAC和PHY功能做到了一颗芯片中,但是MAC和PHY的机制还是单独存在的,只是对外体现为一颗芯片。MAC控制器的功能主要是数据帧的构建、数据差错检查、传送控制、向网络层提供标准的数据接口等功能;PHY芯片的主要功能是将从PHY来的并行数据转换为穿行流数据,再按照物理层的编码规则把数字信号进行编码,最后再转换为模拟信号把数据发出去。
RX_FIFO: 数据接收缓冲区
TX_FIFO: 数据发送缓冲区
DMA Engine:Direct Memory Access,即直接寄存器访问,是一种告诉的数据传输方式,允许在外部设备和存储器之间直接读写数据,数据的读写不消耗CPU资源,DMA控制器通过一组描述符环形队列与CPU互相操作完成数据包的收发。CPU通过操作DMA寄存器来与DMA控制器进行部分通信与初始化配置,主要寄存器有Base、Size、Tail、Head,head寄存器用于DMA往rx_ring里插入时使用,tail是应用通过写寄存器通知给DMA控制器当前可用的最后一个描述符(head->next 为tail时表示当前rx_ring存满了,再来报文会被记录rx_missed_error)。
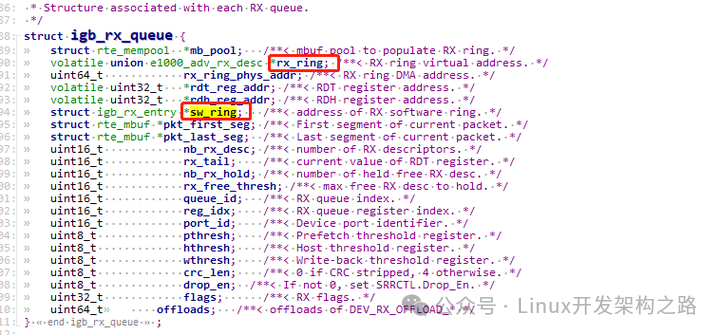
Rx_queue: 收包队列结构体:我们主要关注两个环形队列rx_ring、sw_ring
Rx_ring:一个地址连续环形队列,存储的是描述符,描述符中包含将来存放数据包的物理地址、DD标志(下面会介绍DD标志)等,上面图中只画了存放数据包的物理地址,物理地址供网卡DMA模块使用,也称为DMA地址(硬件使用物理地址,当网卡收到数据包后会通过DMA操作将数据包拷贝到物理地址,物理地址是通过虚拟地址转换得到的,下面分析源码时会介绍)
Sw_ring: 存储的是将来存放数据包的虚拟地址,虚拟地址供应用使用(软件应用使用虚拟地址,应用往虚拟地址读写数据包)
DD标志:用于标识一个描述符buf是否可用,无论网卡是工作在轮询方式下还是中断方式,判断数据包接收成功或者是否发送成功都需要检查描述符中的完成状态位(Description Done)DD,该状态位由DMA控制器在完成操作后进行回写
Mbuf:对应于Mbuf内存池中的元素,通过alloc或者free操作内存池获取或者释放mbuf对象,这里需要说的一点是mbuf池创建的时候是连续的,但是rx_ring和sw_ring里指向的数据地址不一定是连续的,下面分析收包流程时会介绍
PCIE总线:采用高速串行通信互联标准,自上而下分为事务传输层、数据链路层、物理层,网卡与CPU之间数据包的传输、CPU对网卡寄存器的MMIO操作都通过PCIE进行传输
DMA寄存器:CPU配置网卡的操作通过操作网卡的寄存器,寄存器主要
2、收包流程
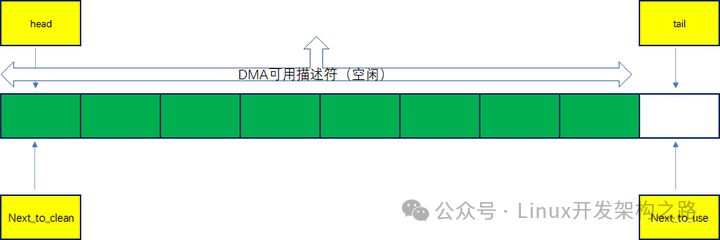
Rx_ring收数据时的状态如下:
DMA控制器收到数据后往head写,当head=tail时表示当前队列为空,head->bext = tail表示当前队列已存满,dpdk启动刚初始化完后如下图所示:
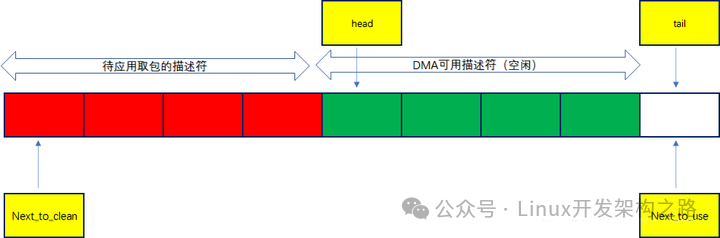
可以看出来cpu对tail寄存器的更新并不是在rx_ring描述符中填充完dma地址后立马就执行,而是等dma可用描述符低于一定阈值时才执行写寄存器更新tail
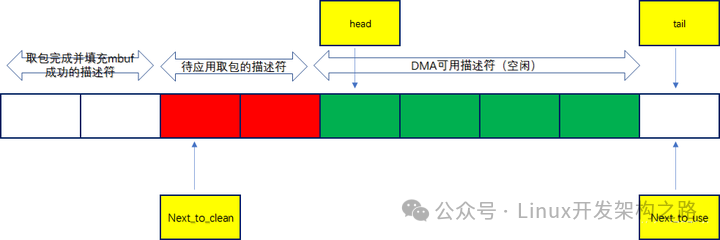
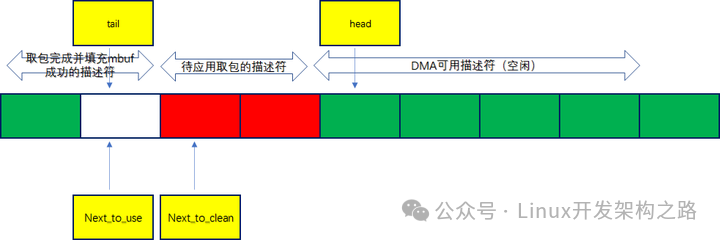
具体详细流程如下:
(1)CPU填缓冲地址(mbuf中的data)到收接收侧描述符(在dpdk初始化时就会第一次填充),也就是上图中rx_ring会指向mbuf池中的 部分mbuf用于接收数据包;另外CPU通过操作网卡的base、size寄存器,将rx_ring环形队列的起始地址和内存卡大小告诉给DMA控制器,将描述符队列的物理地址写入到寄存器后,dma 通过读这个寄存器就知道了描述符队列的地址,进而 dma收到报文后,会将报文保存到描述符指向的 mbuf 空间
(2)网卡读取rx_ring队列里接收侧的描述符进而获取系统缓冲区地址
(3)从外部到达网卡的报文数据先存储到网卡本地的RX_FIFO缓冲区
(4)DMA通过PCIE总线将报文数据写到系统的缓冲区地址
(5)网卡回写rx_ring接收侧描述符的更新状态DD标志,置1表示接收完毕
(6)CPU读取描述符sw_ring队列中元素的DD状态,如果为1则表示网卡已经接收完毕,应用可以读取数据包
(7)CPU从sw_ring中读取完数据包后有个“狸猫换太子”的动作,重新从mbuf池中申请一个mbuf替换到sw_ring的该描述符中 将新分配的mbuf虚拟地址转换为物理地址更新到rx_ring中该条目位置的dma物理地址、更新描述符rx_ring队列里的DD标志置0,这样网卡就可以持续往rx_ring缓冲区写数据了
(8)CPU判断rx_ring里可用描述符小于配置的阈值时更新tail寄存器,而不是回填一个mbuf到描述符就更新下tail寄存器(因为CPU高频率的操作寄存器是性能的杀手,所以改用此机制)
(9)至此,应用接收数据包完毕
注意:这里有两个非常关键的队列rx_ring、sw_ring,rx_ring描述符里存放的是mbuf里data区的起始物理地址供DMA控制器收到报文后往该地址写入(硬件DMA直接操作物理地址,不需要cpu参与);sw_ring描述符里存放的是mbuf的起始虚拟地址供应用读取数据包
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
3、代码的实现过程
我们以e1000驱动类型网卡举例,来分析数据包接收相关的软件结构及接口
(1)接收队列的结构如下图,图中标出了两个重要的环形队列(上面已介绍):
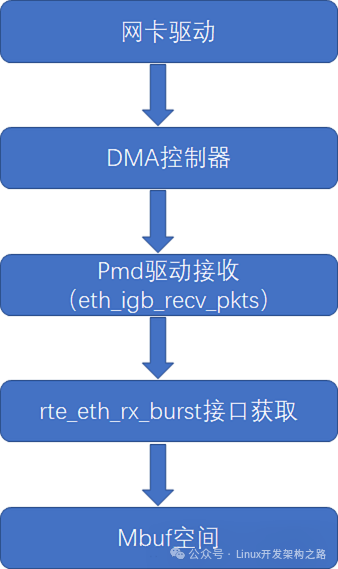
(2)数据包的软件接收流程如下图
(3)分析下eth_igb_recv_pkts接口源码,与第四章的收包内部流程相对应
uint16_teth_igb_recv_pkts(void *rx_queue, struct rte_mbuf **rx_pkts, uint16_t nb_pkts){ struct igb_rx_queue *rxq; volatile union e1000_adv_rx_desc *rx_ring; volatile union e1000_adv_rx_desc *rxdp; struct igb_rx_entry *sw_ring; struct igb_rx_entry *rxe; struct rte_mbuf *rxm; struct rte_mbuf *nmb; union e1000_adv_rx_desc rxd; uint64_t dma_addr; uint32_t staterr; uint32_t hlen_type_rss; uint16_t pkt_len; uint16_t rx_id; uint16_t nb_rx; uint16_t nb_hold; uint64_t pkt_flags; nb_rx = 0; nb_hold = 0; rxq = rx_queue; rx_id = rxq->rx_tail; rx_ring = rxq->rx_ring; sw_ring = rxq->sw_ring; while (nb_rx < nb_pkts) { /*第一步:从描述符队列中找到被应用最后一次接收的那个文件描述符的位置*/ rxdp = &rx_ring[rx_id]; staterr = rxdp->wb.upper.status_error; /*第二步:检查DD状态是否为1,为1则说明驱动已经将报文成功放到接收队列,否则直接退出*/ if (! (staterr & rte_cpu_to_le_32(E1000_RXD_STAT_DD))) break; rxd = *rxdp; PMD_RX_LOG(DEBUG, "port_id=%u queue_id=%u rx_id=%u " "staterr=0x%x pkt_len=%u", (unsigned) rxq->port_id, (unsigned) rxq->queue_id, (unsigned) rx_id, (unsigned) staterr, (unsigned) rte_le_to_cpu_16(rxd.wb.upper.length)); /*第三步:从mbuf池中重新申请一个mbuf,为下面的填充做准备*/ nmb = rte_mbuf_raw_alloc(rxq->mb_pool); if (nmb == NULL) { PMD_RX_LOG(DEBUG, "RX mbuf alloc failed port_id=%u " "queue_id=%u", (unsigned) rxq->port_id, (unsigned) rxq->queue_id); rte_eth_devices[rxq->port_id].data->rx_mbuf_alloc_failed++; break; } nb_hold++; /*第四步:找到了描述符的位置,也就找到了需要取出的mbuf*/ rxe = &sw_ring[rx_id]; rx_id++; if (rx_id == rxq->nb_rx_desc) rx_id = 0; /* Prefetch next mbuf while processing current one. */ rte_igb_prefetch(sw_ring[rx_id].mbuf); /* * When next RX descriptor is on a cache-line boundary, * prefetch the next 4 RX descriptors and the next 8 pointers * to mbufs. */ if ((rx_id & 0x3) == 0) { rte_igb_prefetch(&rx_ring[rx_id]); rte_igb_prefetch(&sw_ring[rx_id]); } rxm = rxe->mbuf; /*第五步:给描述符sw_ring队列重新填写新申请的mbuf*/ rxe->mbuf = nmb; /*第六步:将新申请的mbuf的虚拟地址转换为物理地址,为rx_ring的缓冲区填充做准备*/ dma_addr = rte_cpu_to_le_64(rte_mbuf_data_iova_default(nmb)); /*第七步:将rx_ring描述符中该条目的DD标志置0,表示允许DMA控制器操作*/ rxdp->read.hdr_addr = 0; /*第八步:重新填充rx_ring描述符中该条目的dma地址*/ rxdp->read.pkt_addr = dma_addr; /* * Initialize the returned mbuf. * 1) setup generic mbuf fields: * - number of segments, * - next segment, * - packet length, * - RX port identifier. * 2) integrate hardware offload data, if any: * - RSS flag & hash, * - IP checksum flag, * - VLAN TCI, if any, * - error flags. */ /*第九步:对获取到的数据包做部分封装,比如:报文类型、长度等*/ pkt_len = (uint16_t) (rte_le_to_cpu_16(rxd.wb.upper.length) - rxq->crc_len); rxm->data_off = RTE_PKTMBUF_HEADROOM; rte_packet_prefetch((char *)rxm->buf_addr + rxm->data_off); rxm->nb_segs = 1; rxm->next = NULL; rxm->pkt_len = pkt_len; rxm->data_len = pkt_len; rxm->port = rxq->port_id; rxm->hash.rss = rxd.wb.lower.hi_dword.rss; hlen_type_rss = rte_le_to_cpu_32(rxd.wb.lower.lo_dword.data); /* * The vlan_tci field is only valid when PKT_RX_VLAN is * set in the pkt_flags field and must be in CPU byte order. */ if ((staterr & rte_cpu_to_le_32(E1000_RXDEXT_STATERR_LB)) && (rxq->flags & IGB_RXQ_FLAG_LB_BSWAP_VLAN)) { rxm->vlan_tci = rte_be_to_cpu_16(rxd.wb.upper.vlan); } else { rxm->vlan_tci = rte_le_to_cpu_16(rxd.wb.upper.vlan); } pkt_flags = rx_desc_hlen_type_rss_to_pkt_flags(rxq, hlen_type_rss); pkt_flags = pkt_flags | rx_desc_status_to_pkt_flags(staterr); pkt_flags = pkt_flags | rx_desc_error_to_pkt_flags(staterr); rxm->ol_flags = pkt_flags; rxm->packet_type = igb_rxd_pkt_info_to_pkt_type(rxd.wb.lower. lo_dword.hs_rss.pkt_info); /* * Store the mbuf address into the next entry of the array * of returned packets. */ /*第十步:将获取到的报文放入将要返回给用户操作的指针数组中*/ rx_pkts[nb_rx++] = rxm; } rxq->rx_tail = rx_id; /* * If the number of free RX descriptors is greater than the RX free * threshold of the queue, advance the Receive Descriptor Tail (RDT) * register. * Update the RDT with the value of the last processed RX descriptor * minus 1, to guarantee that the RDT register is never equal to the * RDH register, which creates a "full" ring situtation from the * hardware point of view... */ /*第十步:CPU判断rx_ring里可用描述符小于配置的阈值时更新尾部寄存器供DMA控制器参考*/ nb_hold = (uint16_t) (nb_hold + rxq->nb_rx_hold); if (nb_hold > rxq->rx_free_thresh) { PMD_RX_LOG(DEBUG, "port_id=%u queue_id=%u rx_tail=%u " "nb_hold=%u nb_rx=%u", (unsigned) rxq->port_id, (unsigned) rxq->queue_id, (unsigned) rx_id, (unsigned) nb_hold, (unsigned) nb_rx); rx_id = (uint16_t) ((rx_id == 0) ? (rxq->nb_rx_desc - 1) : (rx_id - 1)); E1000_PCI_REG_WRITE(rxq->rdt_reg_addr, rx_id); nb_hold = 0; } rxq->nb_rx_hold = nb_hold; return nb_rx;}
五、发包软件处理流程
发包流程与第四章的收包流程有些区别,DPDk在初始化阶段不会从mbuf池中获取缓冲区插到描述符队列空间里,只有在真正的发送过程中才会从mbuf池中获取mbuf,然后插入到描述符队列空间里。
1、模块/硬件介绍
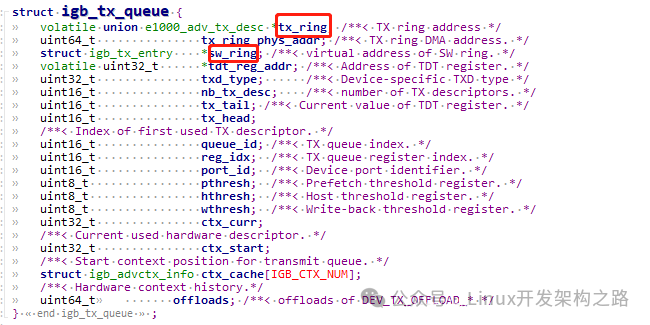
Tx_queue: 发包队列结构体:我们主要关注两个环形队列tx_ring、sw_ring
Tx_ring:一个地址连续环形队列,存储的是描述符,描述符中包含将来存放数据包的物理地址、DD标志(下面会介绍DD标志)等,上面图中只画了存放数据包的物理地址,物理地址供网卡DMA模块使用,也称为DMA地址(硬件使用物理地址,当网卡收到数据包后会通过DMA操作将数据包拷贝到物理地址,物理地址是通过虚拟地址转换得到的,下面分析源码时会介绍)
2、发包流程
Tx_ring发数据时的状态如下:
dpdk初始化完成时tx_ring的队列为空
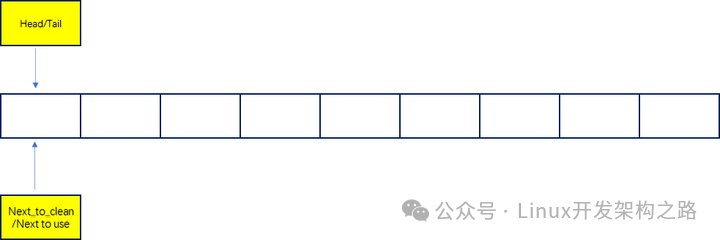
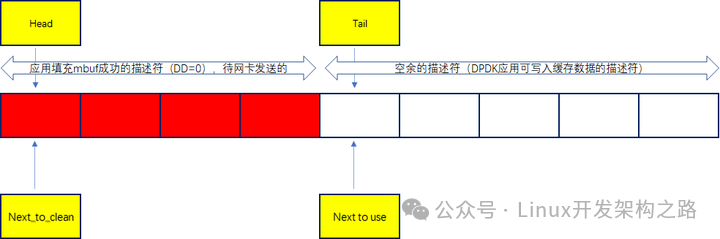
DMA控制器通过head去判断当前的DD状态,如果为0则可以执行发送动作
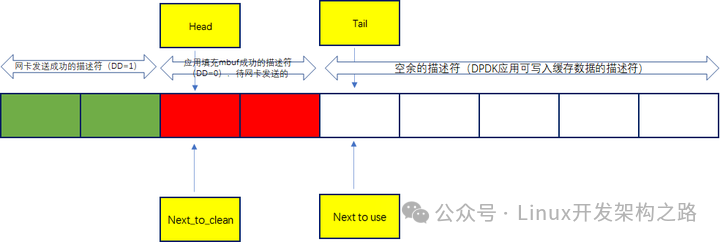
CPU需要对tx_ring上网卡发送成功的描述符的缓存空间进行释放操作,待应用下次继续写入

(1)CPU读取发送侧描述符tx_ring队列,检查DD标志是否为1,为1则说明发送完毕
(2)针对发送完毕的描述符需要释放该描述符里对应的缓冲区
(3)CPU将准备发送的缓冲区mbuf的虚拟地址填充到描述符sw_ring
(4)CPU通过将准备发送的缓冲区mbuf的虚拟地址转换得到该mbuf里data数据部分的物理地址填充到发送测描述符tx_ring队列中,并将DD标志清0
(5)DMA控制器读取base寄存器,获取发送侧描述符,根据发送测描述符获取tx_ring队列地址,读取head指针里的元素,判断DD标志释放为0则从描述符中获取数据缓存区地址,通过PCIE总线将数据拷贝到网卡硬件Tx_FIFO缓存中往外发送数据
(6)DMA控制器回写该描述符中队列里DD的标志置1,通知CPU该缓存中数据已成功发送
(7)至此,应用发送数据包完毕
注意:这里有两个非常关键的队列tx_ring、sw_ring,tx_ring描述符里存放的是mbuf里data区的起始物理地址供DMA控制器读取报文(硬件DMA直接操作物理地址,不需要cpu参与);sw_ring描述符里存放的是mbuf的起始虚拟地址供应用写入数据包
3、代码的实现过程
我们以e1000驱动类型网卡举例,来分析数据包发送相关的软件结构及接口
(1)发送队列的结构如下图,图中标出了两个重要的环形队列(上面已介绍):
(2)数据包的软件发送流程如下图
(3) eth_igb_xmit_pkts接口源码,发包逻辑参考上面小节,这里不做补充了
六 、总结
到目前位置分析完了数据包在网卡、CPU、主存上游走的流程,可以看到DPDK收发包的流程设计的还是比较震撼的,充分考虑到了高性能收发数据,其中一些处理流程、数据结构的设计经验等值得我们在平时的开发项目中去运用和学习。
 0
0










