
前言
近期所做的项目,与Linux内核的IOMMU机制有关,因此自己尝试去了解IOMMU的相关知识。我在网上多方查找,却总觉得是盲人摸象,难以形成一套系统化的知识体系。并且,许多代码是基于Linux v2.x、v3.x内核,而我当前项目是基于较新的Linux 5.5.4内核,有一些代码,乃至实现机制,都发生了根本性的变化。最终,还是决定自己研究代码,终于明白了IOMMU的初始化流程。现撰文分享,希望之后还有同行遇到此类问题时,能够参考本文,节约学习成本。
适用环境
内核版本:Linux 5.5.4(Linux 5.x版本应该都适用)
硬件:Intel x86-64处理器;对于硬件IOMMU的章节,要求BIOS能够支持Intel IOMMU
IOMMU简介
关于IOMMU,网上的资料分析得比较详细,此处仅作简要介绍,以作为后续文章的引子。
IOMMU (Input and Output Memory Management Unit),其名称显然是由MMU衍生而来。之所以二者名称如此相似,是因为它们的功能非常相似。以下是一张解释IOMMU功能的经典图片:
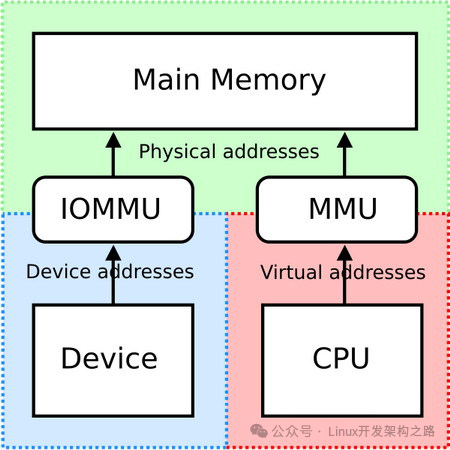
从上图中不难看出,IOMMU是DMA(直接内存访问,即设备与内存直接通信,而无需经过CPU)过程中的一个环节。本系列的文章更多时候会把IOMMU看作一种机制,从这个角度,我们也可以说:IOMMU是DMA的一种实现方式。
愿意阅读本文的读者,相信对于MMU并不陌生:MMU是将CPU虚拟地址转换为内存物理地址的硬件单元。类似地,IOMMU是将设备地址(又称总线地址)转换为内存物理地址的单元。我们完全可以参照虚拟内存机制,来理解IOMMU的作用:
① IOMMU使得设备无法直接访问物理地址,大大增加了设备进行DMA攻击的难度。
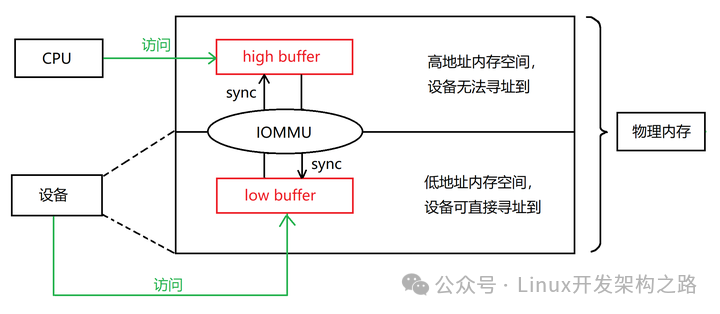
② 部分设备的引脚数较少,导致其位数较低,无法寻址到整个物理内存空间。以目前主流的32位设备为例,其在物理内存中直接寻址的范围是[0, 4GB)。但是,现代操作系统的内存往往大于4GB。如果设备申请DMA时,内核为设备分配的DMA buffer的地址高于4GB(以下简称为“high buffer”),则设备将无法寻址到它。
有了IOMMU以后,IOMMU就可以在[0, 4GB)范围内分配一段与高地址buffer长度相同的内存,让设备能够直接寻址(以下称为“low buffer”)。设备向low buffer写入后,IOMMU就会将low buffer中的内容,复制到high buffer,而后通知CPU从high buffer读取内容。反之亦然——CPU向high buffer写入后,IOMMU就会将high buffer中的内容,复制到low buffer,而后通知设备从low buffer读取内容。这样,CPU和设备都能读取到对方写入的内容。这样在high buffer和low buffer之间复制内容的操作,在IOMMU机制中被称为“sync”或“bounce”。
SWIOTLB概述
IOMMU的核心功能就是,实现在low buffer和high buffer之间的sync,也就是内存内容的复制操作。
读者可能会想,内存的复制,在内核中,不就是调用memcpy()函数来实现的吗?没错,这就是本文要介绍的IOMMU的软件实现方式——SWIOTLB。之所以说是软件实现,是因为sync操作在底层正是调用memcpy()函数,这完全是软件实现的。
SWIOTLB的作用在于,使得寻址能力较低、无法直接寻址到内核所分配的DMA buffer的那些设备,也能够进行DMA操作。记住这句话——它将贯穿全文。由此,我们对本文开头图片稍作修改,制作了一个SWIOTLB的实现版本。
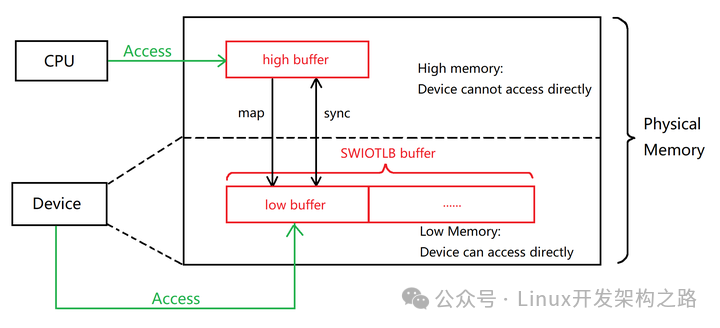
在目前主流的Linux操作系统中,SWIOTLB发挥作用的场合并不多见。这主要是由于以下原因:
现代的外部设备,通常都是32位或64位设备。64位设备毫无疑问可以直接寻址整个物理内存空间;而32位设备能够直接寻址的范围也达到了4G。如果操作系统运行内存不大于4G,则所有内存都可以被这些设备直接寻址到,此时设备的DMA操作,就无需SWIOTLB的辅助。
相比硬件IOMMU,SWIOTLB存在memcpy()操作,需要CPU的参与,降低了效率,这是软件实现的固有弊端。后面的文章将会提到,如果启动参数中同时启用SWIOTLB和硬件IOMMU(即Intel IOMMU),那么当Linux系统启动完成后,SWIOTLB将会被禁用,而仅保留硬件IOMMU。
DMA的两种映射方式与SWIOTLB的关系
DMA映射方式包含两种,一是DMA Coherent Mapping(一致性DMA映射),二是DMA Streaming Mapping(流式DMA映射)。关于这两种映射方式的区别,网上有很多详尽的资料,故本文并不展开介绍。
读者应当注意的是,在Linux 4.0及更高的版本,只有DMA Streaming Mapping有可能触发SWIOTLB机制,而DMA Coherent Mapping与SWIOTLB没有任何联系。之所以要强调Linux 4.0及更高版本,是因为,在Linux 4.0之前的版本,DMA Coherent Mapping也会借助SWIOTLB来实现,而这一情况从Linux 4.0起就不复存在了。
SWIOTLB部分术语解释
为了让读者更好地理解本文及其他与SWIOTLB/DMA Streaming Mapping有关的文章,笔者认为还是需要解释一下一些在SWIOTLB中经常出现的术语的含义。
map:直译为映射。本质上,map是DMA Streaming Mapping中一系列函数的统称,它们反映了DMA Streaming Mapping的核心机制(下文称为"map函数")。map函数的典型代表是dma_map_single()和dma_map_sg(),其基本流程是:
设备调用map函数。设备调用时,会提供一个或一组位于高内存地址的页(以下称为“原始页”),作为需要被map的页。map函数需要返回被map页的DMA地址。
map函数根据设备的寻址能力,并结合SWIOTLB启动参数,决定是否采取实际的映射行为。
如果设备能够直接寻址到原始页,则map函数不进行实际映射,而是直接返回原始页的DMA地址(在x86体系中,DMA地址就等于物理地址,所以实际上返回的是原始页的物理地址)。
如果设备不能直接寻址到原始页,则map函数将执行实际映射——在SWIOTLB buffer中申请一个页(low buffer),而后将原始页(high buffer)的内容复制过来,最后将SWIOTLB中申请的页的物理地址,作为DMA地址,返回给设备。之后,low buffer和high buffer之间需要进行sync操作以保证一致性。因此,这种实际映射会降低设备DMA效率。
如果启动参数指定了"swiotlb=force"(后文将会讲到启用SWIOTLB的配置),那么正如其名,即使设备能够直接寻址到原始页,map函数也会强制执行实际映射。
sync:直译为同步。在SWIOTLB机制中,如果CPU/设备向high buffer/low buffer写入内容,那么两段buffer的内容就会不一致,此时便需要进行sync,将被写入的buffer的内容,复制到另一个buffer。sync的方式很简单,就是使用memcpy()函数。
bounce buffer:bounce原意为“弹跳”,这个词形象地描述了low buffer与high buffer之间数据sync的行为,因而可以看作对SWIOTLB机制更为直观的描述。可以这么说:bounce buffer就是map + sync,二者共同构成了SWIOTLB机制。
SWIOTLB实现原理
SWIOTLB的实现原理,并不难理解。
在内核启动过程中,会使用memblock分配器,从较低的内存中,预留出一段连续物理内存(默认为64MB),用于SWIOTLB(以下称为SWIOTLB Buffer)。之所以要从低地址内存中分配SWIOTLB Buffer,原因很简单,是为了保证那些位数较低、寻址范围较小的设备,也能够寻址到SWIOTLB Buffer,从而实现sync。
对于SWIOTLB Buffer,内核会默认按照2KB的粒度,进行切分(至于为何不采用标准页大小4KB,笔者也不甚了解)。每一段2KB的连续物理内存,称为一个slab。
默认情况下,slab数目 = 64MB / 2KB = 32K = 32768。
在预留出SWIOTLB Buffer后,接下来将会初始化SWIOTLB的核心管理数据结构,它是一个名为io_tlb的数组:
static unsigned int *io_tlb_list;
io_tlb_list的每个元素,对应的正是一个slab。
io_tlb_list[i]代表:从SWIOTLB Buffer的第i个slab开始,有多少个连续slab是可用(空闲)的。这个值存在上限,用常量IO_TLB_SEGSIZE表示。IO_TLB_SEGSIZE默认值为128。
以下图为例。io_tlb_list[0] - [1]均为0,代表第0、1个slab已经被占用。io_tlb_list[2] = 5,代表从SWIOTLB Buffer的第2个slab开始,有连续5个slab是可用的,即下标为2-6的slab是可用的。由此可以推断,io_tlb_list[2]-[6]的值分别为4、3、2、1。io_tlb_list[7]一定为0,即第7个slab必然已被占用;否则,io_tlb_list[2]应至少为6。
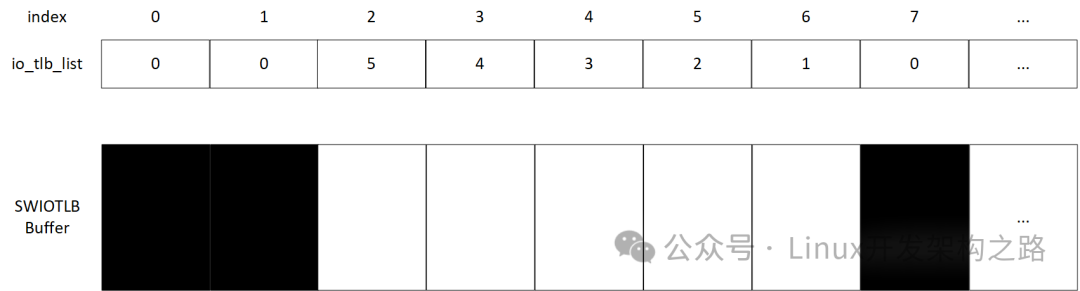
io_tlb_list[i]的最大值为IO_TLB_SEGSIZE,即128。我们可以把每128个连续slab看成一组。假定一个极端场景:SWIOTLB Buffer中所有slab都是空闲的。那么,此时io_tlb_list各元素的值将会是:
io_tlb_list[i] = IO_TLB_SEGSIZE - i % IO_TLB_SEGSIZE;
例如:
io_tlb_list[0] = 128
io_tlb_list[1] = 127
io_tlb_list[127] = 1
io_tlb_list[128] = 128
IO_TLB_SEGSIZE限制了DMA Streaming Mapping的最大可申请内存 —— 128 * 2KB = 256KB,也就是说,每次DMA Streaming Mapping申请,不得超过256KB的内存。如果确实需要申请超过256KB的内存呢?那么请使用DMA Coherent Mapping,这才是适用于较大内存申请的DMA方式。
当内核接收到DMA Streaming Mapping请求时,如果判定需要map(是否需要map,取决于启动参数和设备寻址能力,详见最后一部分展示的函数dma_direct_map_page()代码),则会将请求的size(以字节为单位)换算为slab数目n(向上取整)。而后,内核从上一次查找时停下的位置开始,沿下标递增方向查找(若已经到达数组末尾,则回到数组开头,继续查找)。若找到一个下标k,使得io_tlb_list[k] >= n成立,则表明找到需要分配的区段,查找停止。之后,内核将会更新io_tlb_list中对应下标元素的值。最后,返回这连续n个slab的起始地址,之后允许设备在该区段上进行DMA操作。如果遍历完io_tlb_list,仍未找到符合条件的k(遍历完的条件是,先到达数组末尾,而后从头查找,最后又回到了初始查找的下标),则拒绝此次DMA请求。
仍以上图场景为例。假设此时查找起始位置为下标2。内核接收到一个需要sync的DMA Streaming Mapping请求,其长度被换算为4个slab。由于io_tlb_list[2] = 5,5 > 4,因此找到需要分配的起始slab。此时,内核会将io_tlb_list[2]-[5]均置为0,表明它们已被分配。下次查找的起始下标变为6。最后,将下标为2的slab起始地址返回给设备,设备可以占用下标[2, 5]区间的slab(即low buffer),用于DMA。
如果其他条件不变,长度被换算为6个slab呢?显然,io_tlb_list[2] = 5,5 < 6,因而下标为2的slab无法满足需求,需要继续查找。下一个查找的下标,并不是3,而是直接跳到2 + 5 + 1 = 8。之后重复此步骤。
启用SWIOTLB的配置
Linux内核默认是禁用SWIOTLB的。如需启用,则需要分别修改.config文件和启动参数文件(在主流的Linux发行版本中,启动参数文件就是grub文件)。
.config文件
在.config文件中进行如下配置:
CONFIG_SWIOTLB=y
启动参数文件
在启动参数文件中,推荐使用:
iommu=soft intel_iommu=off # Recommended
以下方式也可,但不推荐:
swiotlb=force # Not recommended!
原因前文已经解释过——第二种方式会强制进行SWIOTLB map,即使设备能够直接寻址到DMA地址也是如此。这一配置会从整体上降低操作系统的DMA效率——因为绝大部分现代设备具备较强的寻址能力,无需实际映射,强制映射将会降低它们的DMA效率。因此,建议读者在对SWIOTLB机制尚未透彻理解的情况下,使用第一种方式,而不要使用第二种方式。
读取SWIOTLB启动参数
SWIOTLB的启动参数格式为:
swiotlb=[nslabs],[force|noforce]
解析SWIOTLB启动参数的函数是setup_io_tlb_npages():
static int __initsetup_io_tlb_npages(char *str){ if (isdigit(*str)) { io_tlb_nslabs = simple_strtoul(str, &str, 0); /* avoid tail segment of size < IO_TLB_SEGSIZE */ io_tlb_nslabs = ALIGN(io_tlb_nslabs, IO_TLB_SEGSIZE); } if (*str == ',') ++str; if (!strcmp(str, "force")) { swiotlb_force = SWIOTLB_FORCE; } else if (!strcmp(str, "noforce")) { swiotlb_force = SWIOTLB_NO_FORCE; io_tlb_nslabs = 1; } return 0;}
swiotlb的第一个值是反直觉的——它代表SWIOTLB Buffer中slab的数目,而非SWIOTLB Buffer的起始地址或长度。由于每个slab长度为2KB,因此,指定slab的数目,也就相当于指定SWIOTLB Buffer的长度。
如果不指定slab数目,那么在后续的函数swiotlb_init()中,SWIOTLB Buffer长度会被设置为默认的64MB。而后,默认slab数目 = 64MB / 2KB = 32K。
预留SWIOTLB Buffer
终于要讲到SWIOTLB的初始化函数swiotlb_init()。
事实上,swiotlb_init()函数并不一定会被调用。在调用此函数之前,内核还会做很多准备工作,包括根据启动参数,以及机器硬件环境,设置一些与SWIOTLB相关的全局变量,它们最终将决定swiotlb_init()函数是否会被调用。这些内容并不会在本文中介绍,而是被放到本系列的后续文章中——前文已经提到,SWIOTLB和Intel IOMMU并不会同时存留。笔者希望先向读者介绍它们各自的原理,之后再讨论内核在初始化过程中,选择保留SWIOTLB或Intel IOMMU的原因。
因此,在本文中,我们假定swiotlb_init()函数会被执行。
前文已经提到,内核在启动过程中,会使用memblock分配器,从较低的内存中,预留出SWIOTLB Buffer。这正是swiotlb_init()函数的主要工作。
void __initswiotlb_init(int verbose){ /* SWIOTLB Buffer默认大小为64MB */ size_t default_size = IO_TLB_DEFAULT_SIZE; unsigned char *vstart; unsigned long bytes; if (!io_tlb_nslabs) { io_tlb_nslabs = (default_size >> IO_TLB_SHIFT); io_tlb_nslabs = ALIGN(io_tlb_nslabs, IO_TLB_SEGSIZE); } /* * io_tlb_nslabs代表bounce buffer中包含的slab个数。 * 每个slab长度为2KB(IO_TLB_SHIFT = 11,2 ^ 11 = 2K)。 */ bytes = io_tlb_nslabs << IO_TLB_SHIFT; /* Get IO TLB memory from the low pages */ vstart = memblock_alloc_low(PAGE_ALIGN(bytes), PAGE_SIZE); if (vstart && !swiotlb_init_with_tbl(vstart, io_tlb_nslabs, verbose)) return; if (io_tlb_start) memblock_free_early(io_tlb_start, PAGE_ALIGN(io_tlb_nslabs << IO_TLB_SHIFT)); pr_warn("Cannot allocate buffer"); no_iotlb_memory = true;}
注意上述代码中的:
vstart = memblock_alloc_low(PAGE_ALIGN(bytes), PAGE_SIZE);
它要求内核需要从低内存地址预留SWIOTLB Buffer,以保证即使是寻址能力较为有限的设备,也能够直接访问SWIOTLB Buffer。
初始化SWIOTLB管理数据结构
函数swiotlb_init()会调用swiotlb_init_with_tbl(),后者初始化SWIOTLB管理数据结构,主要包括两个数组:一是io_tlb_list,前文已经详细介绍其功能;二是io_tlb_orig_addr,该数组的作用是保存sync的物理地址——io_tlb_orig_addr[i]保存第i个slab所映射的高地址,即本文开头的图片中high buffer的起始地址。
有了io_tlb_orig_addr,内核就可以根据SWIOTLB Buffer的slab下标,很方便地找到需要进行sync的两段内存地址。
举个例子:假设设备向下标为2的slab写入了数据,现在需要sync。则:
起始地址src = SWIOTLB Buffer起始地址 + 2 * 2K 目标地址dst = io_tlb_orig_addr[2]
后续将这两个地址传给memcpy()函数即可。
int __init swiotlb_init_with_tbl(char *tlb, unsigned long nslabs, int verbose){ unsigned long i, bytes; size_t alloc_size; bytes = nslabs << IO_TLB_SHIFT; io_tlb_nslabs = nslabs; io_tlb_start = __pa(tlb); /* io_tlb_list数组起始地址 */ io_tlb_end = io_tlb_start + bytes; /* io_tlb_list数组结束地址 */ /* * Allocate and initialize the free list array. This array is used * to find contiguous free memory regions of size up to IO_TLB_SEGSIZE * between io_tlb_start and io_tlb_end. */ alloc_size = PAGE_ALIGN(io_tlb_nslabs * sizeof(int)); io_tlb_list = memblock_alloc(alloc_size, PAGE_SIZE); if (!io_tlb_list) panic("%s: Failed to allocate %zu bytes align=0x%lx\n", __func__, alloc_size, PAGE_SIZE); alloc_size = PAGE_ALIGN(io_tlb_nslabs * sizeof(phys_addr_t)); io_tlb_orig_addr = memblock_alloc(alloc_size, PAGE_SIZE); if (!io_tlb_orig_addr) panic("%s: Failed to allocate %zu bytes align=0x%lx\n", __func__, alloc_size, PAGE_SIZE); /* * io_tlb_list[i]表示,从第i个slab开始,有多少个连续的slab是可用(可分配)的。 * 最多只允许分配128个连续slab。因此,io_tlb_list[i]的合法值是0 ~ 128之间的整数。 * * io_tlb_orig_addr记录原始物理地址与slab index的映射关系。 */ for (i = 0; i < io_tlb_nslabs; i++) { io_tlb_list[i] = IO_TLB_SEGSIZE - OFFSET(i, IO_TLB_SEGSIZE); io_tlb_orig_addr[i] = INVALID_PHYS_ADDR; } io_tlb_index = 0; if (verbose) swiotlb_print_info(); swiotlb_set_max_segment(io_tlb_nslabs << IO_TLB_SHIFT); return 0;}
SWIOTLB的触发时机——DMA Streaming与SWIOTLB的函数调用树
DMA Streaming共有两条路径,它们在底层最终都会调用swiotlb_map函数,从而进入SWIOTLB的路径。第一条路径是dma_map_single,每次映射一个页:
dma_map_single -> dma_map_single_attrs -> dma_map_page_attrs -> dma_direct_map_page -> swiotlb_map -> swiotlb_tbl_map_single -> swiotlb_bounce -> memcpy
第二条路径是dma_map_sg,sg是"scatter-gather"的缩写,表示每次映射一系列的页。
dma_map_sg -> dma_map_sg_attrs -> dma_direct_map_sg -> dma_direct_map_page -> swiotlb_map -> swiotlb_tbl_map_single -> swiotlb_bounce -> memcpy
这里面比较重要的函数有dma_direct_map_page()和swiotlb_tlb_map_single()。dma_direct_map_page()是高层函数,其目的是接收一个高地址的物理页,并将其映射到SWIOTLB Buffer的一个slab中。以下展示该函数的代码,其中关键在于调用swiotlb_map()前的判断条件,笔者已经用注释写明。
dma_addr_t dma_direct_map_page(struct device *dev, struct page *page, unsigned long offset, size_t size, enum dma_data_direction dir, unsigned long attrs){ phys_addr_t phys = page_to_phys(page) + offset; dma_addr_t dma_addr = phys_to_dma(dev, phys); /* * 如果启动参数指定了swiotlb=force,或者设备无法直接寻址到物理页所对应的dma地址, * 那么就会调用swiotlb_map(),触发SWIOTLB映射流程 * * 这里需要强调的是,如果启动参数指定了swiotlb=force,那么 * swiotlb_map()会被无条件调用,即使设备能够直接寻址到原来的DMA地址。 * 这里印证了前文所述。 */ if (unlikely(!dma_direct_possible(dev, dma_addr, size)) && !swiotlb_map(dev, &phys, &dma_addr, size, dir, attrs)) { report_addr(dev, dma_addr, size); return DMA_MAPPING_ERROR; } if (!dev_is_dma_coherent(dev) && !(attrs & DMA_ATTR_SKIP_CPU_SYNC)) arch_sync_dma_for_device(phys, size, dir); return dma_addr;}EXPORT_SYMBOL(dma_direct_map_page);
swiotlb_tbl_map_single()则是寻找该slab的过程,原理前文已经详细解释过。这里只展示查找slab的算法对应的代码,读者可结合前文提到的SWIOTLB原理,来理解代码。
phys_addr_t swiotlb_tbl_map_single(struct device *hwdev, dma_addr_t tbl_dma_addr, phys_addr_t orig_addr, size_t mapping_size, size_t alloc_size, enum dma_data_direction dir, unsigned long attrs){ unsigned long flags; phys_addr_t tlb_addr; unsigned int nslots, stride, index, wrap; int i; unsigned long mask; unsigned long offset_slots; unsigned long max_slots; unsigned long tmp_io_tlb_used; /* ...... */ /* * Carefully handle integer overflow which can occur when mask == ~0UL. */ max_slots = mask + 1 ? ALIGN(mask + 1, 1 << IO_TLB_SHIFT) >> IO_TLB_SHIFT : 1UL << (BITS_PER_LONG - IO_TLB_SHIFT); /* * For mappings greater than or equal to a page, we limit the stride * (and hence alignment) to a page size. */ nslots = ALIGN(alloc_size, 1 << IO_TLB_SHIFT) >> IO_TLB_SHIFT; /* ...... */ /* * Find suitable number of IO TLB entries size that will fit this * request and allocate a buffer from that IO TLB pool. */ /* ... */ wrap = index; do { while (iommu_is_span_boundary(index, nslots, offset_slots, max_slots)) { index += stride; if (index >= io_tlb_nslabs) index = 0; if (index == wrap) goto not_found; } /* * If we find a slot that indicates we have 'nslots' number of * contiguous buffers, we allocate the buffers from that slot * and mark the entries as '0' indicating unavailable. */ if (io_tlb_list[index] >= nslots) { int count = 0; for (i = index; i < (int) (index + nslots); i++) io_tlb_list[i] = 0; for (i = index - 1; (OFFSET(i, IO_TLB_SEGSIZE) != IO_TLB_SEGSIZE - 1) && io_tlb_list[i]; i--) io_tlb_list[i] = ++count; tlb_addr = io_tlb_start + (index << IO_TLB_SHIFT); /* * Update the indices to avoid searching in the next * round. */ io_tlb_index = ((index + nslots) < io_tlb_nslabs ? (index + nslots) : 0); goto found; } index += stride; if (index >= io_tlb_nslabs) index = 0; } while (index != wrap); not_found: /* ...... */ found: io_tlb_used += nslots; spin_unlock_irqrestore(&io_tlb_lock, flags); /* * Save away the mapping from the original address to the DMA address. * This is needed when we sync the memory. Then we sync the buffer if * needed. */ for (i = 0; i < nslots; i++) io_tlb_orig_addr[index+i] = orig_addr + (i << IO_TLB_SHIFT); if (!(attrs & DMA_ATTR_SKIP_CPU_SYNC) && (dir == DMA_TO_DEVICE || dir == DMA_BIDIRECTIONAL)) swiotlb_bounce(orig_addr, tlb_addr, mapping_size, DMA_TO_DEVICE); return tlb_addr;}
最后,展示一下swiotlb_bounce()函数代码。在删除了冗长而又无用的分支后(见代码注释),可以看到,这个函数是直接调用了memcpy()。注意,memcpy()需要CPU参与,这降低了效率,也与DMA的初衷背道而驰(CPU:还得我亲自出马?那我要这DMA有何用)。
正因为SWIOTLB会降低效率,因此,它只被用于少数的DMA场景中——具体来说,只有在DMA Streaming Mapping,并且设备无法直接寻址到内核分配的DMA地址时,SWIOTLB才会派上用场。
/* * Bounce: copy the swiotlb buffer from or back to the original dma location */static void swiotlb_bounce(phys_addr_t orig_addr, phys_addr_t tlb_addr, size_t size, enum dma_data_direction dir){ unsigned long pfn = PFN_DOWN(orig_addr); unsigned char *vaddr = phys_to_virt(tlb_addr); /* 目前主流的64位机器已经没有highmem,因此完全可以忽略此分支 */ if (PageHighMem(pfn_to_page(pfn))) { /* ...... */ } else if (dir == DMA_TO_DEVICE) { memcpy(vaddr, phys_to_virt(orig_addr), size); } else { memcpy(phys_to_virt(orig_addr), vaddr, size); }}
Intel IOMMU与SWIOTLB的比较
Intel IOMMU与SWIOTLB同为IOMMU的实现方式,二者在目的上存在共性——都能够解决“设备无法直接寻址到内核分配给它的DMA buffer”这一问题。
二者的不同点在于:
-
功能。Intel IOMMU最大的功能,并不是用来解决“设备寻址能力有限”这一问题——解决上述问题仅仅是Intel IOMMU顺便附带的一个功能。事实上,Intel IOMMU只是我们从功能角度的称谓,它的全称叫做Intel Virtualization Technology for Direct I/O,简称为Intel VT-d。其核心功能是重映射(Remapping),指的是在启用虚拟化技术(Virtualization Technology,可以简单理解为开启虚拟机)的机器上,对I/O操作(包括DMA和中断)进行重映射。关于什么是重映射,后文将会详细介绍。
-
实现方式。SWIOTLB底层是用memcpy()实现的,需要CPU的参与;而Intel IOMMU是通过专门的硬件实现的。
什么是重映射
我们先举例说明重映射的应用场景。以最常见的虚拟机软件VMWare Workstation为例,经常使用它的用户一定会有这样的经历:你在一台Windows机器上,使用VMWare Workstation,开启了一台Linux虚拟机。为了方便表述,本文称此时的物理机(Host,Windows机器)为宿主机,而虚拟机(Guest,Linux机器)仍称为虚拟机。
然后,你往机箱上插入一个U盘。U盘就是一个设备,它将会进行I/O操作。这时,系统将会弹出对话框,询问你要把U盘连接到哪台机器,你可以选择连接到Windows机器(宿主机)或是Linux机器(虚拟机)。如果你选择连接到虚拟机,那么该U盘之后的I/O操作,就会触发重映射。
为了理解重映射,我们首先考虑没有启用虚拟化(即没有启动虚拟机)的机器。对于这样的机器,设备发起DMA请求,得到的就是机器物理地址;设备的中断请求,也会被CPU直接接收,而后通过中断向量表,找到对应的中断服务程序,处理该中断请求。这个过程是没有重映射的。
现在,假设一台宿主机上开启了虚拟机(甚至可以开启多个虚拟机),并且设备连接到其中某一台虚拟机。这就意味着,设备能访问到的,只有它所连接的虚拟机的所有资源(一个虚拟机的所有资源,称为一个Domain),而不会访问到其他虚拟机,更不能直接访问宿主机。因此,我们必须确保:
设备发起DMA请求时,操作系统返回给它的,不能是宿主机物理地址(Host Physical Address,HPA),而只能是虚拟机物理地址(Guest Physical Address,GPA)。Intel IOMMU维护从GPA到HPA的映射关系。
设备的DMA和中断请求,只能被它所连接的虚拟机接收,而不能被其他虚拟机接收,也不能被宿主机直接接收。
这个过程对于设备来说应当是透明的。从设备的视角来看,它发起DMA请求,得到一个内存物理地址,并向该地址读写内容;或者,它发起中断请求,最终得到某个中断服务程序的响应。这一切都应该正常发生,与设备所连接的是虚拟机还是宿主机无关——事实上,设备只知道自己连接的是一台“机器”,而根本不知道自己连接的机器是虚拟机还是宿主机。
在这个过程中,Intel IOMMU完成如下功能:
-
DMA重映射:Intel IOMMU截获设备的DMA请求,将它重定位到设备所连接的虚拟机。而后,该虚拟机将DMA请求传递给宿主机,宿主机分配DMA Buffer,并返回用于DMA Buffer的HPA。Intel IOMMU将HPA转换为GPA,而后返回GPA给设备。之后,设备向GPA进行DMA操作,Intel IOMMU又将GPA映射为HPA。
-
中断重映射:Intel IOMMU截获设备的中断请求,将它重定位到设备所连接的虚拟机。而后,找到该虚拟机所占有的CPU,将中断请求转发给这些CPU,而后这些CPU找到适用于该虚拟机的中断重映射表(Interrupt Remapping Table,IRT,原理与中断向量表相同,只是每个虚拟机都有一份),通过中断号索引到对应的中断服务程序并执行。
DMA重映射中的I/O页表
对于DMA重映射,我们完全可以仿照虚拟内存机制(将内存虚拟地址转换为内存物理地址)来理解。事实上,Intel IOMMU硬件维护了一套用于DMA重映射的I/O页表机制,它与虚拟内存机制中的多级页表原理基本一致,只有一点不同——其中的顶级I/O页表,并不是直接用于寻址(Address Translation),而是用于将DMA请求映射到不同的虚拟机Domain。从次级I/O页表开始,才是真正的寻址过程。
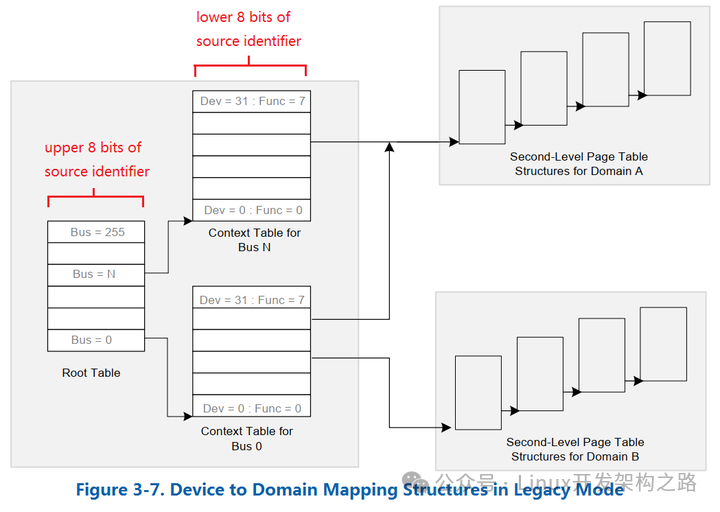
具体来说,在虚拟化环境下,设备发起DMA请求时,除了常规参数以外,还需要附带一系列标识符(称为Request Identifier或Source ID),包括Bus/Device/Function(具体含义笔者也不是很了解…)。标识符的作用就是让Intel IOMMU确定该设备需要将DMA请求发送到哪个虚拟机Domain。

Intel IOMMU根据这些标识符,在顶级I/O页表中进行索引,找到对应的次级I/O页表。事实上,顶级I/O页表又可分为两部分——Root Table和Context Table,如下图所示。Intel IOMMU先根据Request Identifier的Bus区段,在Root Table中索引;而后,再根据Device和Function区段,在Context Table中索引,从而找到对应的次级页表(下图中的Second-Level Page Table)。
从次级页表开始,寻址过程就与内存虚拟地址转换为物理地址的过程,完全相同了。
此外,下图中,有两个Context Table都指向了同一个Domain——Domain A。这表明,不同的设备最终连接到同一个虚拟机,这也是合情合理的——一台机器当然可以连接多个设备,不是吗?
如果上述解释还不够详细,请看《Intel VT-d SPEC》中的原文截图,其中重要语句已用红色下划线标注:

 0
0









