
现阶段半导体晶片商多采用ARM的处理器核心,来制造旗下处理器或等产品。ARM的核心可分为A、R、M三个系列,各有不同性能,因此晶片商也须依各自瞄准的市场、功耗需求和作业系统等差异,来选择较适合的核心,藉以制造性价比佳的产品。
现今嵌入式应用内须用到诸多处理器,因此半导体厂商也积极投入布局,举例来说安谋国际(ARM)的处理器便广泛应用于嵌入式领域。ARM Cortex-A系列处理器经常使用在需要多功能作业系统(Rich OS)或高效能的应用中,Cortex-R系列处理器拥有较佳的即时效能,Cortex-M系列处理器则用于微控制器等类型的小型应用。
目前采用Cortex-M的产品范围涵盖非常多样化的选项,从外型设计小巧、功耗低的Cortex-M0,其使用在深层嵌入、对成本敏感的应用如智慧型感测器节点上,到应用在大众市场的微控制器的Cortex-M3及Cortex-M4。最佳的则是Cortex-M7,其具备更高的效能,可以执行密集运算的工作负载,像是讯号处理等。
Cortex-M处理器采用的ARMv6-M和ARMv7-M架构,是更为简易且逻辑化的程式设计模型,专为简易使用所设计。处理器核心本身在设定上较弹性,能够用于更多样化的实作。
虽然Cortex-M核心的简易性对大部分的嵌入式应用来说是较佳的优势,但仍有其他应用需要更多功能、效能更高的环境。此类应用同样重视效率和耗电量,且经常需要Linux或Android等类型的平台作业系统。采用此类型的作业系统,则能够使用应用范围更广、更具多功能且复杂的软体生态系统,开发新的契机。
Cortex-M处理器的设计并非针对这些高阶的作业系统,因此未包含其所需要的特定必要功能。举例来说,这些处理器未具备记忆体管理单元(MMU),在无法支援虚拟记忆体环境的情况下,当然也就不支援这一类的作业系统。若某项应用需要更多功能的作业环境,首选的通常是较高效率的Cortex-A核心。这些核心提供平台作业系统所需的较进阶功能,同时仍相当重视功耗,整体来说是更为高阶且弹性化的程式设计模型。
有鉴于此,ARM Cortex-A处理器多部署于各种深度嵌入的应用,尤其是在需要Linux或其他多功能作业系统的市场。
图1显示Cortex-A处理器目前的应用范围,重点在于其中的较低功耗核心。本文以此一系列中的最新型Cortex-A32处理器为主。
.jpg)
图1 Cortex-A处理器与架构
Cortex-A32是进入Cortex-A系列较理想的入门款,可用于需要多功能作业系统环境,或从Cortex-A处理器所提供的效能及功能中获益的应用。该处理器为目前拥有低功耗的ARMv8-A处理器,为穿戴式装置、物联网(IoT)和多功能嵌入式应用,尤其是需要Linux这一类平台作业系统之应用的较佳选择。
抢攻32位元运算市场 A系列新处理器功耗更低
Cortex-A32在ARM架构中扮演着独特的角色。其采用ARMv8-A架构,但仅支援32位元的运算。图2显示Cortex-A32如何融入ARMv8-A架构设定,以及与Cortex-A35的差异。
.jpg)
图2 Cortex-A32与Cortex-A35比较
Cortex-A35同时采用32位元的AArch32和64位元的AArch64两种执行状态,能够完整提供ARMv8-A架构的64位元功能。另一方面,Cortex-A32则只采用32位元的AArch32执行状态。移除了64位元的功能以后,不仅体积缩减,对于不需要64位元功能的使用来说,更能降低其功耗。尽管嵌入式领域中有许多应用都可从64位元的执行中获益,但有许多仍着重在32位元,且将在可预见的未来保持现况,而这些应用便是Cortex-A32的目标市场。
AArch32执行状态为更早期的Cortex-A处理器所采用的ARMv7-A架构的进化版。据了解,Cortex-A32即使不具备64位元的功能,但仍提供某些重要的强化,因此功耗还是优于Cortex-A7和Cortex-A5。
此外,对于仍采用这些旧版ARM处理器的延伸设计,或以此相同市场为目标的新设计而言,Cortex-A32仍是理想选择。
AArch32优于ARMv7-A的特点包括:
.新增许多新指令,加密演算功能效能更佳
.新加入Load Acquire和Store Release指令,提供更有效率的记忆体排序功能,符合最新的C++11记忆体排序语法
.额外的纯量与SIMD浮点指令
.广泛的系统控制指令
这些额外功能提供更佳的效能,更胜旧版32位元ARMv7-A处理器。
Cortex-A32汇流排介面加入了先进同步扩展(ACE),因此能通过Cortex-A32来建构完全同步的多重处理系统,提高所需要的更高效能。
假如空间或耗电量为主要的限制,Cortex-A32也有变体版本,特别针对单处理器应用最佳化,省略互连逻辑,以节省更多的功耗。
Cortex-A32透过Large Physical Address Extension(LPAE)扩大了定址实体记忆体空间,超越Cortex-A5所提供的32位元(4GB)空间,可提供40位元定址空间。
核心本身也整合其他多项有助于改善功耗的进阶功能,包括更弹性化的电源管理、更细微分布的电力区域,并使用保存功率闸级。
下文将比较ARMv7-M与ARMv8-A AArch32的架构特色与差异。
ARMv7-M架构特色
ARM Cortex-M处理器系采用ARMv7-M架构设定,Cortex-M0和Cortex-M0+则采用类似的ARMv6-M架构。
此架构与先前的ARM架构有许多共同的特色,且经过特殊设计,以支援深层嵌入、低成本的即时应用。所以移除了旧架构的许多功能,但也加入新功能,制造出一个更像类微控制器的程式设计模型。
举体来说,从旧型处理器(像是常见的ARM7TDMI)的变动可总结如下:
.作业模式的数量从七个以上大幅减少到两个:Handler模式和Thread模式。其中一项模式(Handler模式)具选择性优先权限。
.暂存器档经过简化。虽然开放供程式设计人员使用的暂存器基本上仍同样是十六个,旧型架构中所用的备份暂存器复制机制也大幅减少,因此只有Stack Pointer(r13)会在两个作业模式中加以暂存。备份暂存器为选择性使用,甚至可以省略。
.最大的变动在于异常模式。由于一般的微控制器应用可能会有大量的晶片周边中断,所以标准的巢状向量中断控制器(Nested Vectored Interrupt Controller, NVIC)规格会包含在架构中,所有的Cortex-M核心均包含该规格。同样地,异常处理模式已在包含处理常式位址的向量表上加以标准化。内容的储存与回复作业完全在硬体上实作,简化写入中断处理的软体工作,如此可在实作时达到非常低且可预测的中断延迟时间。
.ARMv7-M定义选择性的记忆体保护架构,该架构与某些旧型ARM处理器所用的架构类似。裸机系统或在即时作业系统(RTOS)下运作的系统由于通常不需要虚拟记忆体,因此不支援虚拟记忆体。
.为支援各种即时作业系统的运作和执行,有些标准的晶片周边也会在架构中加以定义,如SysTick Timer。
.为缩小处理器核心的大小,ARMv7-M处理器的运行限缩到只有Thumb指令集(包含Thumb-2延伸),仅执行最小的子集,进而实现最小的核心。
ARMv8-A AArch32特色
Cortex-A处理器采用ARMv7-A或ARMv8-A架构设定。ARMv8-A处理器提供AArch32执行状态,为32位元ARMv7-A架构的向下相容演化版。这些架构可实现专门设计用来支援Linux、Android、Windows等平台作业系统的功能,而这些系统需要虚拟记忆体环境。
其与Cortex-M处理器核心截然不同的特定功能包括:
.有七个以上的作业模式:User、Supervisor、阻断要求(IRQ)、快速中断(Fast Interrupt, FIQ)、Undefined、Abort、System。每一模式皆用于处理特定类型事件(例如IRQ模式便是设计用于处理IRQ中断)。AArch32亦支援Hyp和Monitor这两个额外的模式,这两个模式分别用于虚拟化及ARM TrustZone技术。
.除了可用的登录数量相同(16),AArch32还有许多与上述作业模式相关的“备份”暂存器。进入相关的作业模式时,这些暂存器将取代User模式下的暂存器。如此可简化许多异常处理工作,但也表示机器的管理和初始化工作将增加。
.其异常模式极为不同,其原型存在于最早的ARM架构装置中。具体来说,向量表包含一组可执行的指令集,而不是位址,且内容的储存与回复Restore工作几乎完全交给程式设计人员执行。
.最大的差异是加入了记忆体管理单元,可执行核心所核发之虚拟位址,以及记忆体系统所需要的实体位址间的转译。如此便能实作完全的随选分页虚拟记忆体环境,以供Linux等平台作业系统使用。
ARMv7-M与AArch32的差异
从采用Cortex-M处理器的系统转换到采用Cortex-A32处理器时,有许多新功能值得关注。
虽然这两种架构有许多类似之处(如备份暂存器和指令集之间有许多相同点),但重要的是ARMv8-A架构的AArch32执行状态所含的许多功能,均是以旧型架构的功能为基础。
接下来说明AArch32所具备,但为ARMv7-M所无或差异极大的功能。
作业模式
如图3所示,ARMv7-M只定义两个作业模式:Thread模式与Handler模式。若无需要,Handler模式可选择性取消优先权限,虽然这项功能未必须要在软体内使用。Handler模式适用于处理异常,Thread模式则用于使用者处理程序。这两个模式转换基本上是自动的,会在特定事件下发生,如图3所示。例如,发生异常时会自动进入Handler模式,异常处理完成时则会退出Handler模式。SVCall指令为主要的方法,软体用其来进入Handler模式(也可将启用的IRQ设定为待处理状态,以执行Handler)。
.jpg)
图3 ARMv7-M作业模式
图4则显示AArch32执行状态支援的作业模式。与ARMv7-M相较,AArch32有七个基本模式,其中五个指定用于处理特定异常。例如,取得FIQ异常时会进入FIQ模式;若发生未定义指令等情形,会进入Undef模式。
.jpg)
图4 AArch32作业模式
模式的转换通常为自动发生,但也可在Current Program Status Register(CPSR)中写入Mode栏位,用软体控制来完整切换模式。其细节描述如下。与SVCall指令类似,SVC指令用于让软体引发SVC异常并进入SVC模式。
图4中未显示AArch32所支援的另两个模式(为节省空间),也就是Hyp模式(用于Hypervisor)与Monitor模式(用于TrustZone安全性)。相关主题较为复杂,本文不予讨论。
备份暂存器
图5显示ARMv7-M和AArch32的备份暂存器。可看出,许多暂存器为共有,因为这两种架构均是沿袭自ARMv6及先前的架构。
.jpg)
图5 ARMv7-M登录集
多数指令可存取十三个通用型的暂存器r0-r12。在这两种架构中,r13保留为Stack Pointer(SP),r14保留为Link Register(LR),r15则保留为Program Counter(PC)。在ARMv7-M中,这些特殊暂存器的存取仅限于某些反映这些暂存器功能的特定使用状况;在AArch32中,这些暂存器的存取则类似任何其他通用的暂存器(虽然变更Program Counter的数值可能造成非预期的副作用)。
ARMv7-M指定小部分额外特殊用途的暂存器PRIMASK、FAULTMASK、xPSR、CONTROL和BASEPRI,用于控制及设定处理器,及用于管理异常处理。
指令集
图5与图6分别是ARMv7-M与AArch32登录集,两相比较可看出AArch32也提供许多与特定作业模式关联的暂存器。这些暂存器会在进入相关的模式时与其在User模式下的暂存器交换。除了少数特殊指令,其他指令均无法存取这些暂存器,但也无法直接存取。其数值在模式变更时亦会保留,有助于处理异常。每个异常模式皆有自己的专属SP,每个异常均可在独立的堆叠上处理,因此异常处理的程式设计更为稳固且安全。取得异常时,相关模式下的LR设定为异常传回位址。
.jpg)
图6 AArch32登录集
每个异常模式下会出现的还有叫SPSR的额外暂存器。SPSR用于在进入例外时取得目前CPSR数值的快照,搭配LR使用下,可提供自动化的内容储存。
AArch32图中未显示Mon和Hyp模式,其各自支援备份暂存器的R13和R14,如同其他的模式。
在Cortex-A中,另有一个与ARM NEON SIMD指令集(如下所述)相关的备份暂存器,共包含三十二个128位元宽度的暂存器。每个暂存器均可定址为字组、双字组或四字组,且NEON指令集从位元组到四字组均支援向量作业。
异常模式
这两个架构的异常模式有相当大的差异,两者均支援内部与外部异常,可由系统事件或外部周边中断所执行。
ARMv7-M支援与传统极为类似的模型,所有外部中断分别透过包含处理常式位址的向量表来向量。
AArch32支援的模型则类似旧型ARM架构,当中只有八个有独立向量的异常类型。向量表包含可执行的指令,其通常为直接连往合适的异常处理常式的分支指令。仅支援两个外部中断来源:FIQ和IRQ。一般只会有一个高优先的中断连接至FIQ,其余则连接至IRQ。亦即系统必须整合软体分配器,或如同现代化系统所常见的,包含可用个别向量位址进行程式设计的Vectored Interrupt Controller(VIC)。
许多Cortex-A系统包含采用ARM之Generic Interrupt Controller(GIC)架构的标准中断控制器。GIC可作为许多实体中断和ARM核心的两个中断输入(FIQ和IRQ)之间的介面。其可处理优先顺序的决定、遮掩、个别中断启用/停用和抢夺。
指令集
ARM指令集自25年前在ARM1首次推出后已经过许多演进。Cortex-A处理器实际上支援两个指令集,每个指令集均有许多延伸。
.ARM指令集
ARM指令集以第一个ARM处理器所支援的原始指令集为基础,但已经过多次延伸。其为load-store指令集,内含独立指令群组,可用于资料处理、记忆体存取、系统控制及控制流量。现代的ARM指令集具有高效能,且范围广泛。此指令集中的所有指令均以固定长度的32位元字组编码,且字组边界必须对齐。
.Thumb指令集
Thumb指令集为ARM指令集的子集,其中每个指令均编码为16位元的半字组,其半字组边界必须对齐。Thumb指令集的原始概念是为了在编译C之类的高阶语言时,缩小最常用指令的大小,藉此改善程式码的密度。指令缩小后,由于指定的快取行内可放入更多指令,因此也有助于从指令快取内执行。
.进阶SIMD延伸集
进阶SIMD延伸集(Advanced SIMD Extensions)亦称为NEON,是大型的指令集,可利用延伸暂存器组合提供SIMD向量处理功能。
.向量浮点(VFP)
VFP指令集在与NEON相同的备份暂存器上执行,其可提供高效能的IEEE-754相容单一与双重精准浮点作业。
.Thumb-2技术
Thumb-2为延伸集的名称,在ARMv6T2(首先出现在ARM1156T2-S处理器)加入到Thumb指令集内。其为混合长度的指令集,结合Thumb的程式码密度与ARM指令集的较高效能与弹性。
假如使用者已利用Cortex-M微控制器进行开发,应该会对Thumb-2很熟悉。这些程式码在从最小(Cortex-M0和Cortex-M0+)到最大(Cortex-M7)的各种子集中仅支援Thumb-2。转移到Cortex-A处理器,能为程式码生成开启许多可能性。
一般来说,多数针对Cortex-A处理器编译的高阶程式码将以Thumb(含Thumb-2)为目标。因此编译人员可获得最大的自由,在有多重选择下合理选择所要使用的指令,在针对程式码空间进行编译与针对效能进行编译两种情况下实现最高的差异。
ARM指令集通常用于必须要达到最高效能的程式码区段。这些区段有时可在组译器内手动编码,而ARM指令集通常会是最好的选择。
NEON指令集可用下列多种方式存取:
.有程式库支援常见的数学与分析功能及演算法。
.编译器支援完整的内部功能集,允许从C直接存取完整的NEON指令集。透过这种方法,NEON作业便能以最便利的方式与C程式码交错处理。
.NEON可直接在组译器内手动执行。
.编译器亦支援反覆回路的自动向量。只要遵循一些简单的指示来编写程式码,即使是稍显复杂的回路,编译器也能有效执行及向量化。
如果使用者熟悉ARMv7-A处理器,应该也会注意到ARMv8-A加入一些额外的指令。
.密码编译延伸模组(Cryptographic Extensions)
这些指令为ARMv8-A新加入,目的是为了有效实作常见的加密功能建构区块演算法。这些延伸是在NEON备份暂存器上运作。
.Load-Acquire和Store-Release
这些新指令符合C++11记忆体排序语法,能提升编译效率。也可用来减少对资料侧记忆体局限的需求,并部分减少与其相关的工作量。
还有一些其他与浮点和限制指令有关的小型延伸。
虚拟记忆体支援
支援完整虚拟记忆体环境为ARMv8-A主要功能之一,正是透过这项功能,这些装置才能支援Linux和Android等平台作业系统。因此,虚拟记忆体功能经常也是在这些核心中进行选择时最为关键的条件。
虚拟记忆体环境可让作业系统管理记忆体时更富弹性,像是使个别处理程序动态延伸堆叠区,启用个别的程式码,让资料区能视需要在外部储存空间内部和外部进行分页,让个别的使用者处理程序可以检视完全相同的系统记忆体配置图。
为发挥作用,虚拟记忆体在处理器所配发的每个位址上加入了“转译”,如图7所示。软体会在“虚拟位址空间”执行,还有一个名为记忆体管理单元的区块会将其转译为实体位址空间。
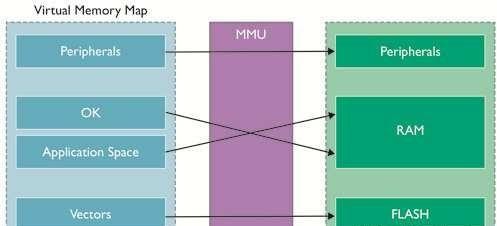
图7 虚拟记忆体
为了使作业系统完整控制存取权限等内容,以针对系统内的各项使用者工作及作业系统本身建立新的虚拟记忆体配置图。每项工作可当作系统内唯一的工作,在自己的虚拟记忆体空间内执行。只有作业系统知道工作程式码及资料区在外部实体记忆体内的实体位置。
在切换工作时,作业系统的其中一项任务就是重新设定记忆体管理单元,以启用传入工作所用的程式码及资料,同时让传出工作的记忆体暂时无法存取。如此可强制区分工作,为安全且弹性的系统的必要元素。
此处不会提供完整说明,ARM处理器内的记忆体管理单元使用保留在外部记忆体中的“分页表”所含的资料来带动及控制转译。系统整合多项最佳化作业(例如,包含Translation Lookaside Buffers,或简称为TLB,能为最近使用过的转译建立快取,以减少读取分页表的工作量),可尽量缩小转译处理程序的工作量。
从ARMv7-M到ARMv7-A的软体转移
多数的高阶软体皆须要简单的重新编译。下列区域的软体则须详加注意:
.重置程式码及其他例外处理常式
如果使用作业系统,这部分的工作将由作业系统所提供的工具来处理。多数情况下,常见作业系统的连接埠将透过公开网域散布或装置供应商提供。
因异常模式差异较大,因此须重新写入中断处理常式。作业系统同样会提供基础架构来完成这部分工作,藉以简单地重新编译多数中断处理常式的主体。
.周边驱动程式
从RTOS转移到Linux这类的多功能平台作业系统时,应用程式码及周边驱动程式须更明确地加以区隔。
.系统组态功能
采用Cortex-M与Cortex-A的装置在提供系统组态与控制功能存取方面有较大的差异。Cortex-M处理器通常透过具名或记忆体对映的暂存器来设定,可直接读取及写入,以达成所要的功能。Cortex-A处理器(为Cortex-A32所支援的AArch32执行状态)则是透过“系统控制协同处理器”来支援设定。概念性的“协同处理器15”包含大量的设定暂存器集,使用专属的指令进行读取及写入。非由作业系统执行的系统组态功能则须重新写入,以完成这部分的工作。也就是说,作业系统通常会提供应用程式介面(API),以用于须要由使用者介面存取的功能。
.汇编程式码
很明显地,汇编程式码也须特别注意。因为写入汇编程式码的其中一个主要原因,便是为了获得最高的效能,因此必须详加检验这些功能,确定重新写入能在存取NEON等某些延伸指令集功能时提供好处。若旧型的汇编程式码已使用“Uniform Assembler Language(UAL)”语法写入,则多数程式码将简单地重新汇编为ARM或Thumb指令。
 0
0









