
恩智浦的i.MX RT系列跨界处理器,为在设备端实现智能运算提供了更高性价比的方案,解锁了在嵌入式应用中部署人工智能算法的新途径。
恩智浦的工程师们从多种角度,做了很多有创新的尝试和工作,为客户提供了丰富的选项,也很好地展示了i.MX RT产品的高性能和高扩展适应性。
本文及随后的一些小文将分别介绍这些精彩的成果。

引 言
多目标检测是机器学习重要的研究领域之一,可以广泛应用于机器人,安防和工业监控等领域。
针对多目标检测任务,目前比较流行的是基于卷积神经网络(Conventional Neural Network,CNN)的算法,例如Yolo,SSD和RetinaNet等。
然而,目前已有CNN方法均不适用于嵌入式平台的部署,这是因为目标检测是一个比较繁重的任务,而现有的检测模型过于复杂,对平台的算力和内存的需求很高,因此无法将其部署在嵌入式平台。
本文基于开源算法,提出了一种轻量化的目标检测网络,大量运用深度可分离卷积以及全新的尺度变换结构,使得模型计算复杂度和结构得到极大简化,进而使多目标检测在MCU上的实现成为可能。
提出的检测算法在NXP微控制器i.MX RT1170上的部署实验结果表明:该算法极大降低了对于ROM和RAM的消耗,运行时间得到大幅度优化,检测速度最高可达10FPS,并且模型精度可以媲美开源的YoloV3-tiny,YoloV4-tiny等模型。
实时多人体检测算法
1. 网络结构设计
本文采用的网络结构设计主要分为两部分,第一部分为网络主体结构,用来逐层提取样本的有效特征。该主体结构借鉴了MobileNetV2的轻量特性,并充分考虑了模型在部署方面对于ROM和RAM的优化。
网络主要特点概括如下:
(1)大量运用深度可分离卷积来减少参数量,进而减少ROM的消耗。深度可分离卷积相对于传统的卷积可以大大较少参数规模。例如对于一个输入有8个通道,输出有16个通道的传统3*3卷积, 其参数量为16*8*3*3=1152;而深度可分离卷积参数量仅有8*3*3+1*1*8*16=200。
(2)模型结构设计上遵循的是加大网络模型深度,缩小每层的宽度,这样带来的好处是减少每层推理所需要的内存占用。这是因为在嵌入式设备中,运行内存极为紧张,而优化过的模型可以减少RAM的使用。
(3)考虑到模型部署需要用到8位整型量化,这里我们采用Relu激活函数。这是因为目前还没有任何研究表明哪种激活函数具有更高的精度,但对于量化来说,显然Relu会比pRelu(图1),leakyRelu或者sigmoid等函数具有更快的推理时间和更低的量化损失。
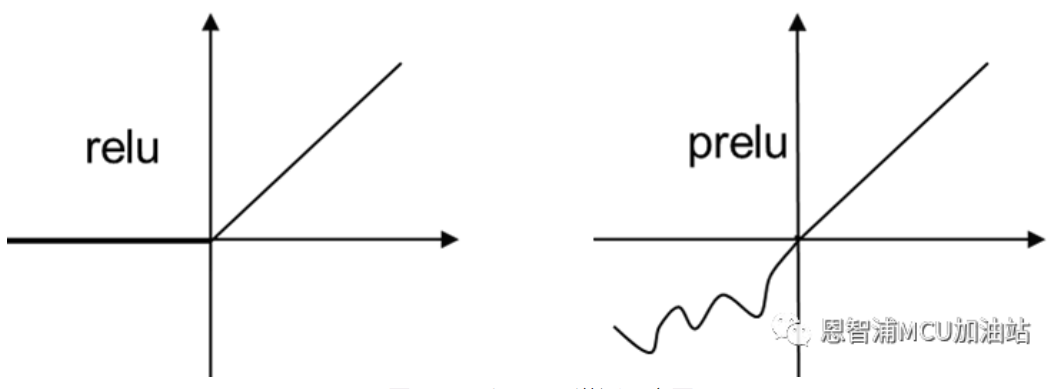 图1 Relu和pRelu激活示意图
图1 Relu和pRelu激活示意图
(4)网络设计中尺度变换结构采用了1*1,3*3和5*5三种卷积核尺寸,进而同时兼顾不同大小目标的定位精度;同时,我们提出的尺度预测结构更为简单,减少了网络模型部署的难度。
2. 网络模型融合压缩与量化
对于训练后的网络模型,可以通过网络模型的融合压缩以及量化技术,加快其在嵌入式设备上的推理时间。
因为本文设计网络中为了使每层数据分布更加均匀(有助于减少整型量化中的损失),采用了Batchnorm对数据进行约束。此外,Batchnorm还可以将输入分布更多的分散在非饱和区,进而减小梯度弥散,加快收敛过程。模型训练结束后,Batchnorm中参数就固化了,可以将其参数融合进卷积层中,最终避免Batchnorm层在实际模型推理中的时间消耗。
模型量化的目的是为了加快模型在MCU上的推理时间,这是因为大多数MCU内核采用Arm Cortex-M 架构,其对定点乘法运算的速度要比浮点运算快得多。此外,模型量化还可以节省模型对于ROM和RAM的需求。
本文采用全8位整型量化的方式对模型进行推理加速。
3. 实验结果分析
本文提出的模型针对目前较为流行的开源公版模型YoloV3-Tiny和YoloV4-Tiny进行对比,实验结果如下:
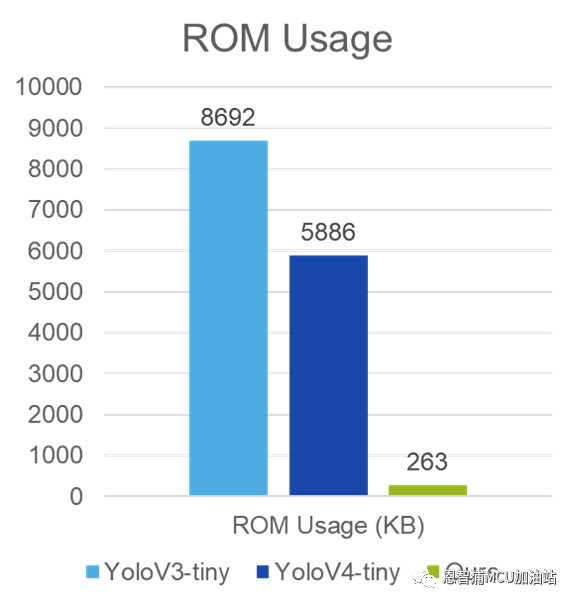
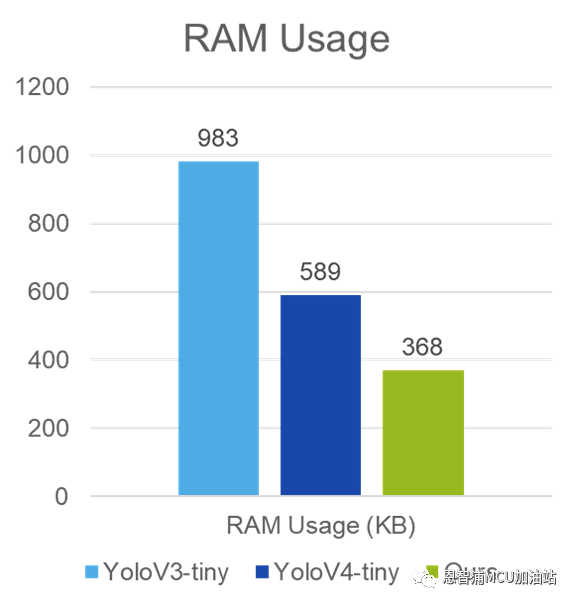
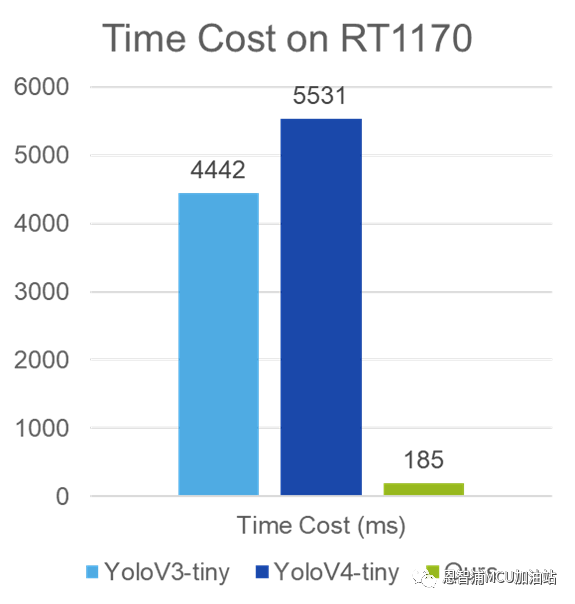 图2 模型对比实验图
图2 模型对比实验图
如图2所示,该模型极大地降低了ROM和RAM的占用,这对于内存大小较为紧张的嵌入式设备来说意义重大。
而在推理时间上,本文提出的模型具有更为突出的优势。作者在NXP微控制器i.MX RT1170(ARM Cortex-M7,1GHz)上的实验结果表明,相比开源模型动辄几秒钟的推理时间,我们提出的网络模型将时间消耗控制在200ms以内,使其部署在微控制器上更加高效。
注意,图2中的时间消耗对比是假设YoloV3-Tiny和YoloV4-Tiny均进行8位整型量化,并且直接使用未经修改的开源算法得到的推理时间。实际上,直接使用开源的、未经修改的YoloV3-Tiny和YoloV4-Tiny等网络结构,由于其复杂结构,部署难度较高。而本文提出网络模型在结构上进行了极大优化,可以利用现有开源工具进行量化部署。
对于模型预测精度,作者进行了如图3的测试对比实验。在多个样本集上,本文提出模型的预测精度可以媲美开源的YoloV3-Tiny和YoloV4-Tiny等模型。
 图3 模型预测效果对比图
图3 模型预测效果对比图
基于i.MX RT1170的实时多人体检测系统
神经网络模型在边缘设备上的部署,是深度学习技术落地的一大关键部分。本文以多人体检测模型为例,分享如何将现有的神经网络模型,部署到NXP的微控制器i.MX RT1170EVK开发板上,并实现实时多人体检测系统。
部署流程如图4所示,首先需要将训练的模型进行模型框架转换,这是因为开源的量化工具仅支持少量的模型框架。
第二步需要对模型进行融合优化,然后利用量化工具将模型进行量化,并转换为MCU可以执行的代码;最后对模型的预处理和后处理进行编程实现,这样摄像头抓取的图像数据就可以进行预处理后送入量化模型,然后根据模型输出特征图进行后处理,提取出有效的候选框作为预测框。
 图4 神经网络边缘设备部署流程图
图4 神经网络边缘设备部署流程图
本文采用NXP i.MX RT1170EVK开发板进行多人体检测系统的实现。
i.MX RT1170是NXP的一款跨界MCU,采用主频达1GHz的Cortex®-M7内核和主频达400MHz的Cortex-M4,这里我们仅使用M7内核。
此外,RT1170EVK上搭载了MIPI接口的OV5640摄像头,分辨率达到720*1280,同时配有5.5寸高清显示屏,分辨率同样达到720*1280。
这里我们采用FreeRTOS系统进行摄像头的实时读取和LCD的实时显示,摄像头和LCD的分辨率均设为最高的720*1280,刷新率均设为15FPS。
系统实现流程如图5所示,摄像头抓取的图像经过PXP转换,然后进行预处理送入模型,最后经过后处理将预测框显示在LCD上。
 图5 人体检测系统实现流程
图5 人体检测系统实现流程
最终,基于i.MX RT1170的人体检测系统可以实现快速精准的多人体位置预测,测试视频如下。

视频中算法检测速度接近5FPS,充分验证了提出模型的有效性和轻量性。
此外,本文算法的一大优势在于运行时间可控,并不会因为被检测人体数量的多少而改变。模型的速度决定了最远检测距离。以下测试结果分别是算法在10FPS,5FPS和3FPS速度下的最远检测距离。


 图6 算法检测距离与速度
图6 算法检测距离与速度
结束语
本文给出的多人体检测算法和系统,为在NXP的MCU上部署多目标检测任务带来了更多的可能性。
结合深度学习模型网络的优化,以及模型融合量化等技术,可以在保证模型精度的同时,实现在嵌入式平台上推理速度的最优化,进而才能将深度学习技术更好的落地。


 0
0










