
对于自动驾驶汽车来说,传感器有很多种,而视觉传感器“摄像头”就属于传感器中价格相对便宜且功能很重要的一种,被称为“智能汽车之眼”。今天小编先带大家对摄像头作一个基础介绍。
视觉技术其实是仿生理学的解决方案,因为现实世界中司机驾驶车辆就是依靠视觉去做行车过程中的决策。在本文会介绍下车载摄像头的基础知识以及视觉算法的基本原理,另外还会对自动驾驶视觉技术的几大经典场景做一个介绍。
02 车载摄像头介绍
从硬件成本分析,车载摄像头是技术相对成熟而成本最低的的一种方案。使用车载摄像头的缺点主要是后续数据的分析,需要依赖大量的标注数据和模型训练资源去训练成熟的用于自动驾驶的各种机器学习相关模型。
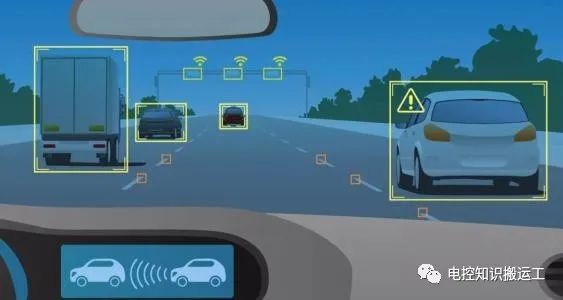
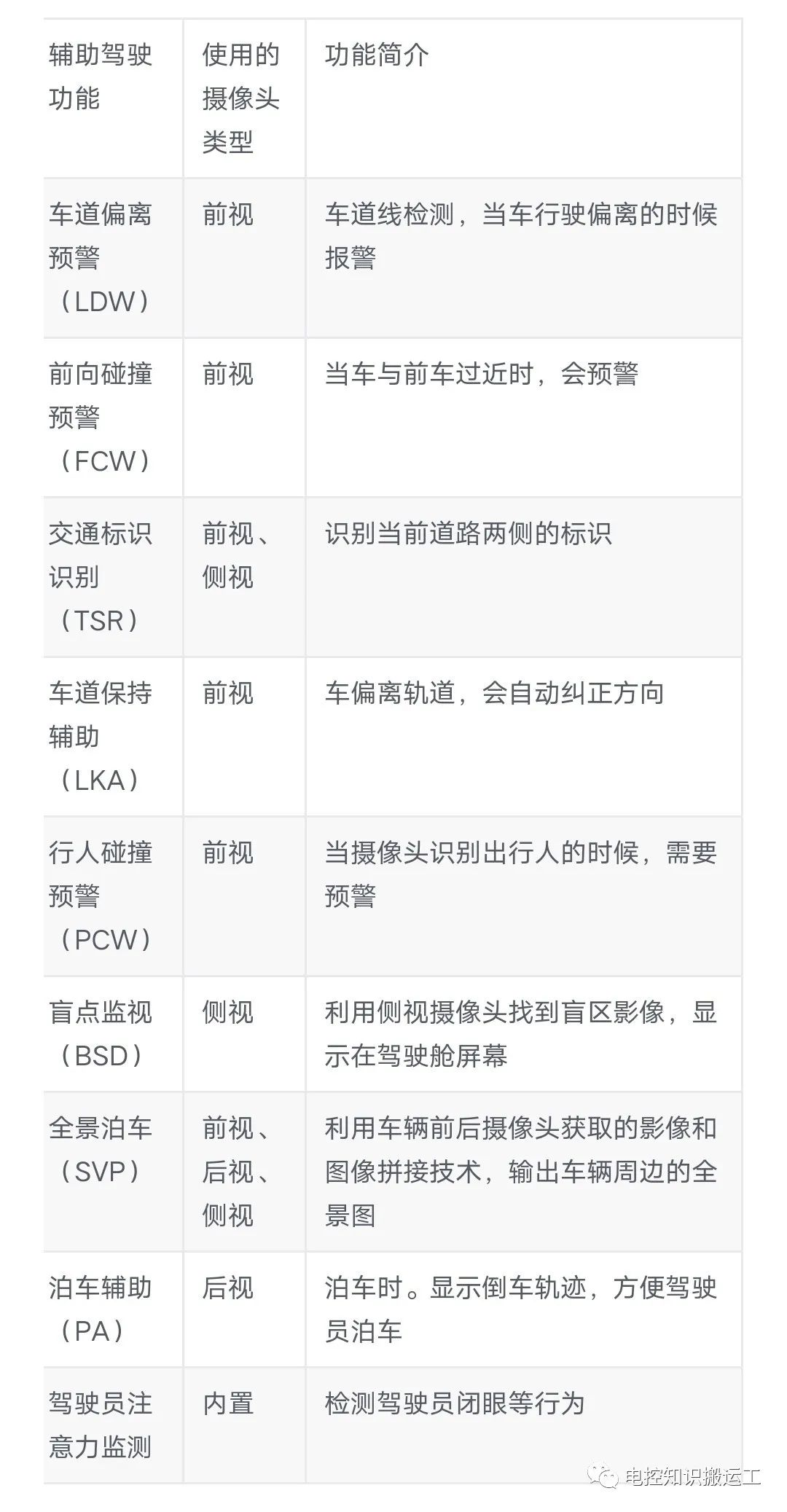
常见的车载摄像头功能如下表所示:

03 视觉算法基本原理
既然摄像头识别对象是依赖深度学习算法,那么视觉相关算法的基本原理也需要大致介绍下。目前各种车载自动驾驶摄像头里面用的图像识别类算法基本上都是CNN的结构,就是卷积神经网络。
卷积神经网络在认知图像的过程其实跟人大脑认知图像的原理类似。大脑识别图像的过程其实是将图片在人脑的各级神经元抽象成各种小的元素,比如棱角、直线等等,然后将这些元素所在的神经突触激活,最终信息传导下去形成认知。卷积神经网络模仿了这种图像识别的流程,通过卷积的各层将图像全部细节元素识别出来,形成最终的认知。

一个标准的CNN的网络结构如图所示:
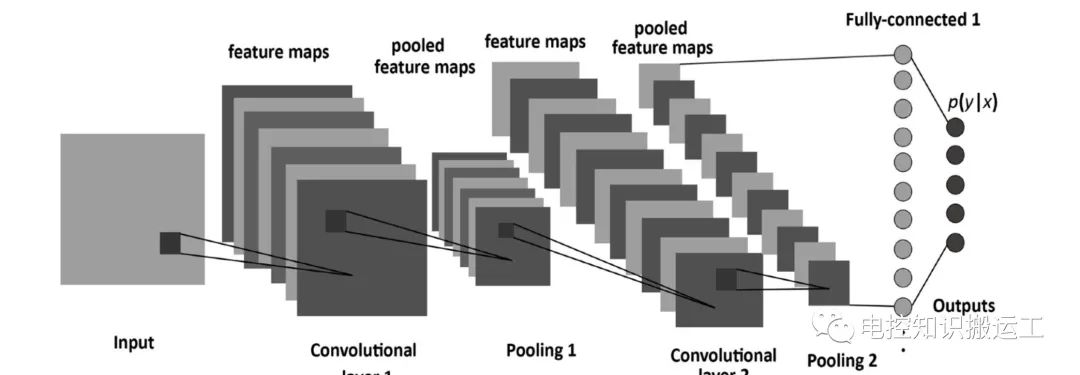
是由很多的层组成的,有卷积层、池化层、全连接层组成。每一层对应很多小的feature maps,feature maps有宽度和高度,可以对应到图像的宽和高。
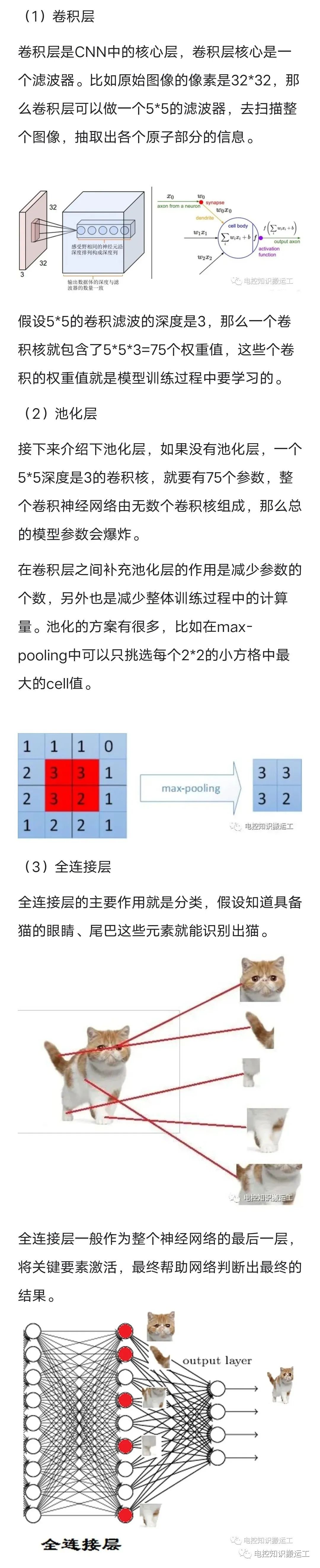
在卷积神经网络中各个层都有不同的功能。
04 视觉技术的基本场景
目前视觉技术在自动驾驶领域的识别主要分以下几个核心场景,分别是雷达云图的识别、行驶途中障碍物的识别、行驶区域的识别、交通标识的识别以及光流识别。
(1)雷达云图识别
上一篇文章介绍过,激光雷达会通过雷达波将行驶过程中道路信息的云图绘制出来。

图像识别技术可以基于这种云图找出道路轨迹、车辆等信息,从而做驾驶决策。
(2)障碍物识别

通过摄像头捕获实时视频流,然后通过CNN模型可以实时对视频流图像进行识别,然后指导驾驶决策。
(3)行驶区域识别
形势区域识别主要解决的问题是对车道线进行识别,并且标记出继续前行的方向。

(4)交通牌识别
如果说车道线识别和障碍物识别还可以通过雷达做补强,那么交通牌识别是只有视觉技术配合摄像头可以解决的问题。自动驾驶过程中需要配合摄像头找到每个标识牌的内容,比如限速、红绿灯识别、禁行标识等。

交通牌识别的技术问题是交通标识物通常并不出现在视频的主要方位,一般只在视频的边缘位置占据很小的一块区域,所以要通过特殊的图像分割技术解决。
(5)光流识别
光流指的是图像中每个像素点的二维瞬时速度,通常来讲就是图像中每个像素点在图中的移动速度。通过光流识别可以清楚的判断道路中的人、车辆的行驶速度。
光流是可以通过图像可视化的,如下图:

左边是输入的移动的图像,右边是转化为光流的表视图,可以通过不同的颜色标识不同的运动方向,通过深浅标识局部的速度。
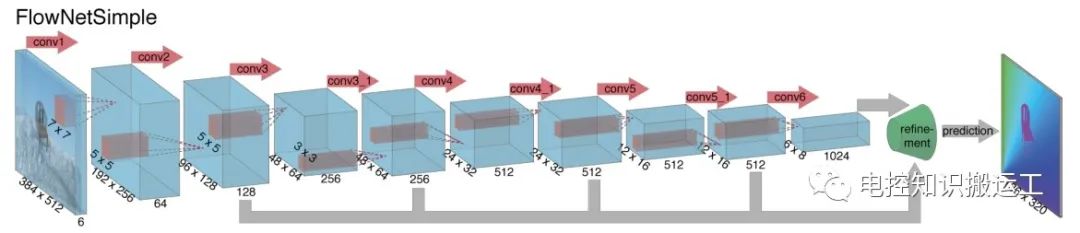
基于光流场景有专业的FlowNet网络,也是一种基于卷积神经网络的变种。
 0
0









