
一、 ftrace基本原理
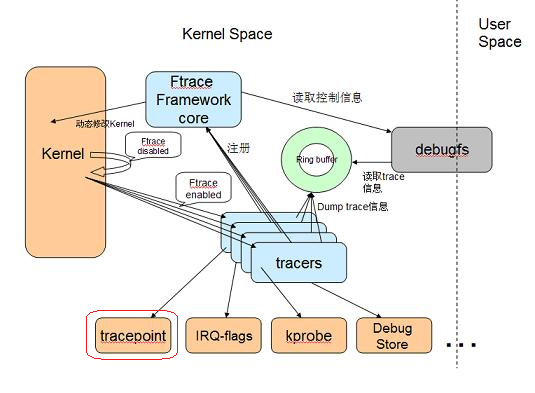 图1-1 ftrace框架
图1-1 ftrace框架 一句话总结:各类tracer往ftrace主框架注册,不同的trace则在不同的probe点把信息通过probe函数给送到ring buffer中,再由暴露在用户态debufs实现相关控制。
对不同tracer来说
1)需要实现probe点(需要跟踪的代码侦测点),有的probe点需要静态代码实现,有的probe点借助编译器在运行时动态替换,event tracing属于前者;
2)还要实现具体的probe函数,把需要记录的信息送到ring buffer中;
3)增加debugfs 相关的文件,实现信息的解析和控制。
二、ftrace event tracing原理介绍
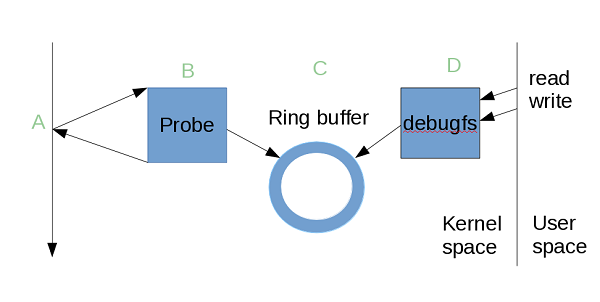 图2-1 ftrace event tracing原理 其它一些 trace 工具也具有相似的工作流程,需要一个 probe 点,一个 probe 函数,一种保存 log 信息的机制,还有用于户进行交互的接口(分别对应图中 A、B、C、D 点)。它们发现可以利用 function trace 的后两部分,也就是环形缓存的管理和用户交互接口部分的代码,只需要实现自己的 probe 点和 probe 函数就可以了。于是在 function trace 进入内核 mainline 后,kprobe 也借用了该机制。
图2-1 ftrace event tracing原理 其它一些 trace 工具也具有相似的工作流程,需要一个 probe 点,一个 probe 函数,一种保存 log 信息的机制,还有用于户进行交互的接口(分别对应图中 A、B、C、D 点)。它们发现可以利用 function trace 的后两部分,也就是环形缓存的管理和用户交互接口部分的代码,只需要实现自己的 probe 点和 probe 函数就可以了。于是在 function trace 进入内核 mainline 后,kprobe 也借用了该机制。 1. tracepoint 的实现原理
(1) DECLARE_TRACE
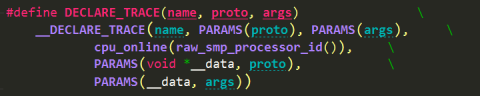
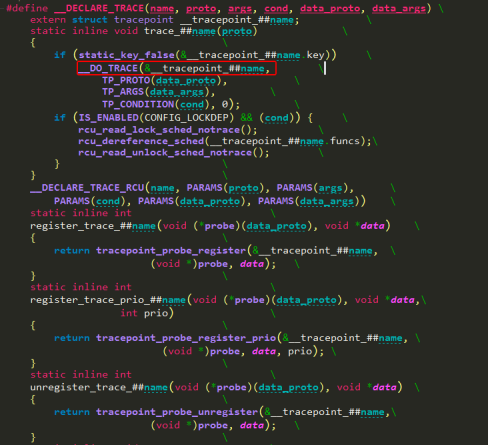
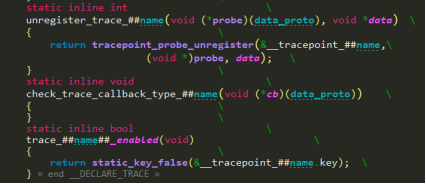
trace_##name最终调用__DO_TRACE宏将信息送到ring buffer中。
reg/unregister_trace_subsys_event 负责注册或注销 probe 函数,probe 函数的原型由 TP_PROTO 宏给出。例如:wakeup相关tracer则是调用了register_trace_sched_wakeup。
使用 tracepoint 需要自己实现 probe 函数, event tracing通过一套通用的机制省去了内核模块/驱动自己实现probe函数的麻烦 。
-
__DO_TRACE
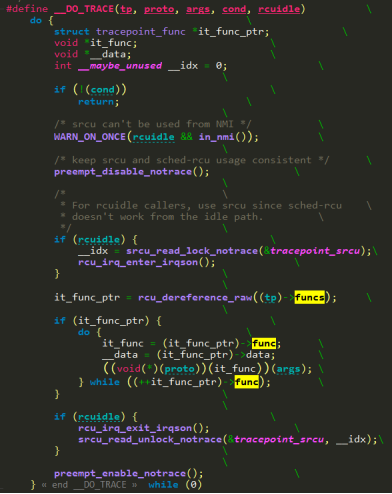
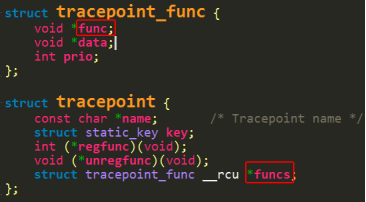
该(it_func_ptr)->func和(tp)->funcs在enable event的时候会被赋值,下文会有展开描述。
(2) DEFINE_TRACE
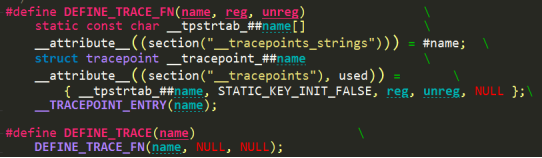
定义了__tpstrtab_##name字符串变量和struct tracepoint __tracepoint_##name。当然二者都放在了链接脚本专门的section里(详见include/asm-generic/vmlinux.lds.h)。编译后可查看system.map去查看具体的变量位置。
2. event tracing的实现原理
(1)TRACE_EVENT
第1次通过包含include/linux/tracepoint.h,将其展开成DECLARE_TRACE。
第2次通过include/trace/trace_events.h,将其展开成DECLARE_EVENT_CLASS,而在该头文件中DECLARE_EVENT_CLASS会被多次展开。
第3次通过包含include/trace/define_trace.h,将其展开成DEFINE_TRACE 其中,include/linux/和include/trace/define_trace.h必须显示被使用者显式包含。
总结下:
- trace_##name,是放置probe点的函数实现,如果该event enable则调用注册进来的trace_event_raw_event_##call
- trace_raw_output_##call,是输出信息的函数实现(cat trace时输出)
-
trace_event_raw_event_##call,是probe函数
(2)trace_##name
细节参见上文宏展开结果。
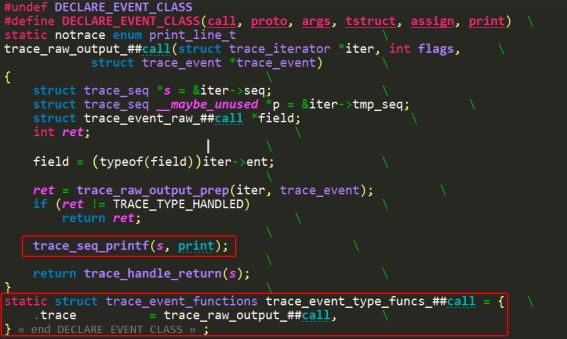
(3)trace_raw_output_##call
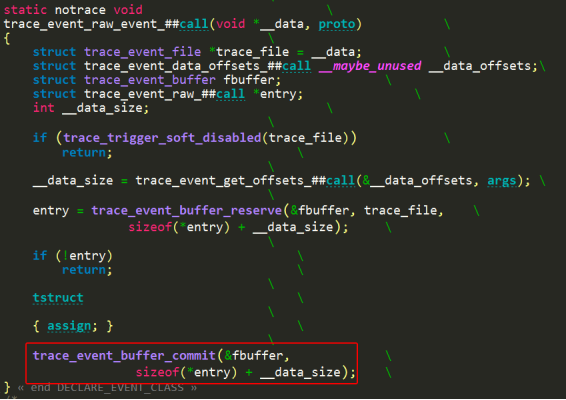
(4)trace_event_raw_event_##call
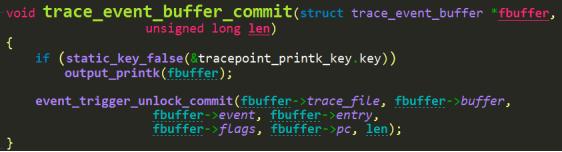
综上,通过上述宏展开,得到:
3. 关键流程梳理
(1)定义event
(2)记录event
(3)使能event
tracefs /sys/kernel/debug/tracing tracefs rw,seclabel,relatime 0 0
对应命令: echo 1 > /sys/kernel/debug/tracing/events/<one_trace_event>/enable
对应关键代码流程:

将上文描述的展开后的宏里面的trace_event_raw_event_##call注册到struct tracepoint_func中进去
(4)输出event

对应关键代码流程:

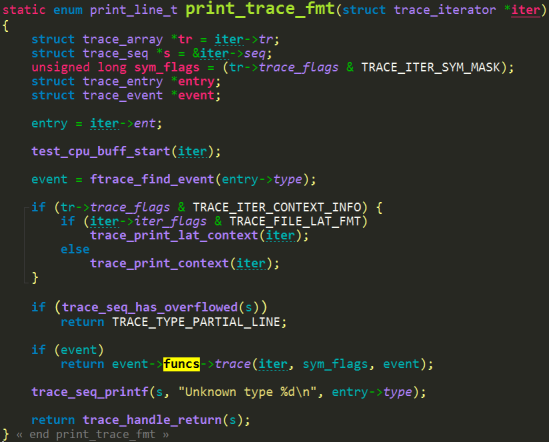
funcs->trace,参见上文被赋值成trace_raw_output_##call了。
三、使用ftrace event tracing跟踪特定进程调度原理
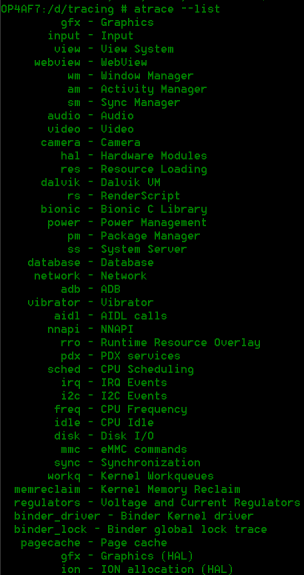
1. Android systrace tag list
2. 用户态如何使用ftrace
(1)使用trace_marker
- Java层:Trace.traceBegin(tag, name)/Trace.traceEnd(tag)
- Native层 :ATRACE_BEGIN(name)/ATRACE_END()
当然,也可以根据特定需求,直接利用systrace现成的tag(即还可以使用systrace 设置tag和手动设置sched调度的event filfter搭配起来用)。如果想关闭用户态的信息打印也是可以的。
(2)开关trace_marker
查看:
cat options/markers
打开:
echo 1 > options/markers
关闭:
echo 0 > options/markers
3. Android Linux状态
(1)Android状态转移
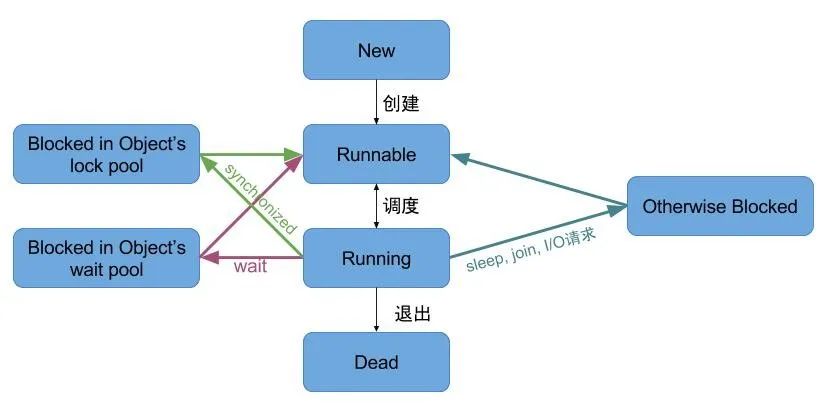 图3-1 Android进程状态转移
图3-1 Android进程状态转移 1)Runnable -> Running:就绪态的进程获得了CPU的时间片,进入运行态; 2)Running -> Runnable: 运行态的进程在时间片用完后,必须出让CPU,进入就绪态; 3)Running -> Blocked:当进程请求资源的使用权(如外设)或等待事件发生(如I/O完成)时,由运行态转换为阻塞态; 4)Blocked -> Runnable:当进程已经获取所需资源的使用权或者等待事件已完成时,中断处理程序必须把相应进程的状态由阻塞态转为就绪态。
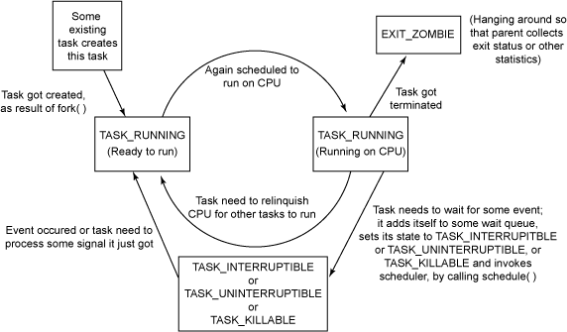
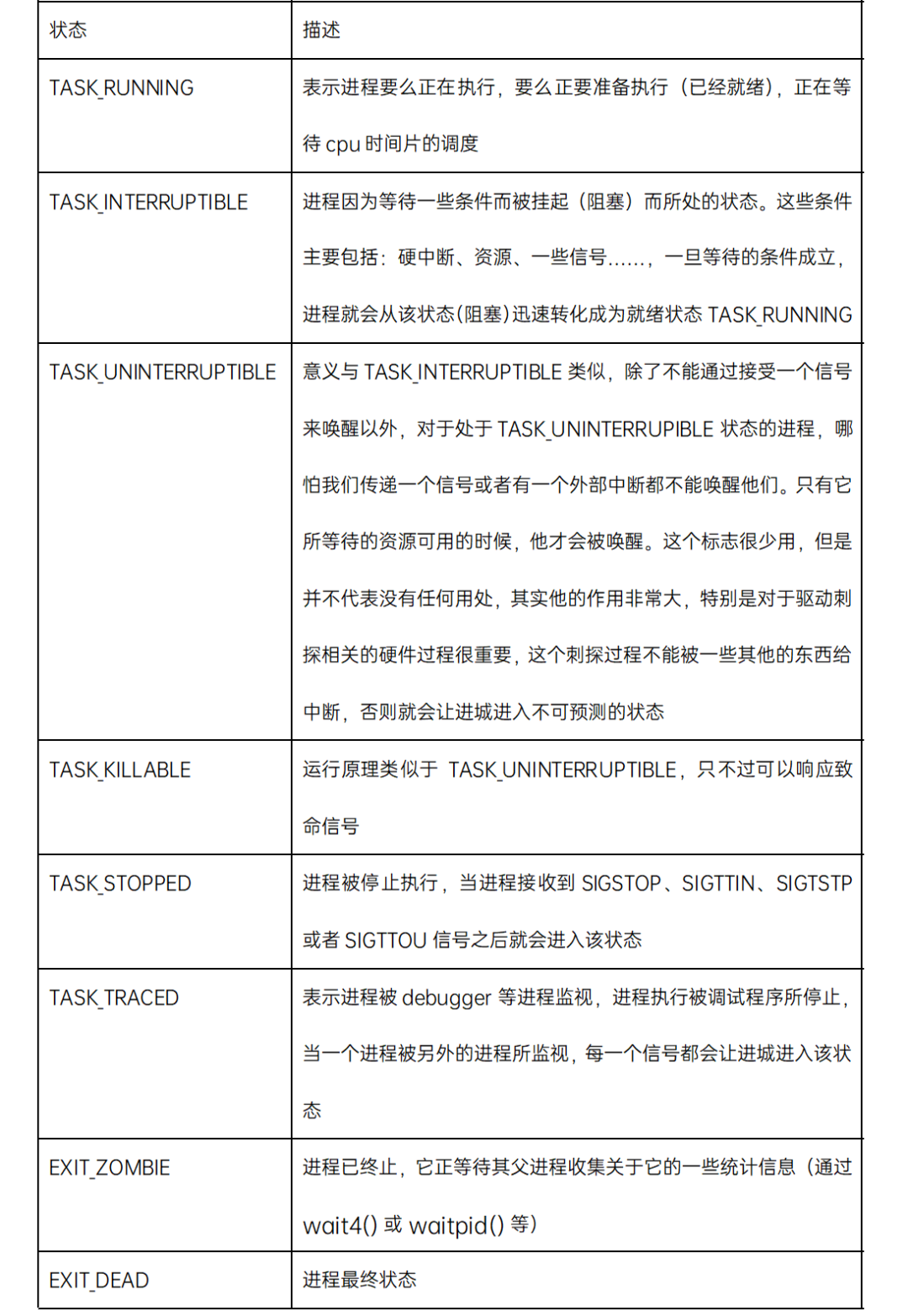
(2)Linux原生状态信息
4. 调度相关events分析
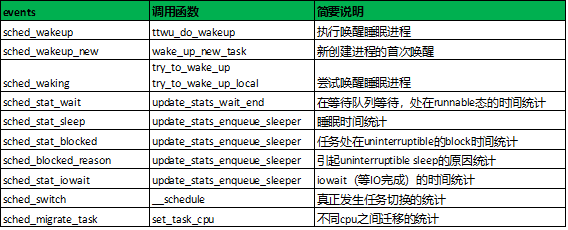
这些trace events足够我们分析线程级别的调度信息。
5. event的filter功能
为实现问题进程的跟踪,我们需要使用event的filter功能。
(1)event filter语法简单介绍
- 对于数字域,可以使用操作符==, !=, <, <=, >, >=, &
- 对于字符串域,可以使用==, !=, ~。目前字符串只支持完全匹配,且最多可以组合16个条件。”~”支持通配符(*,?)。
例子:
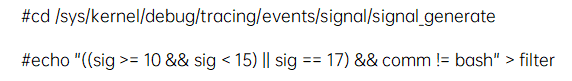
(2)event filter format
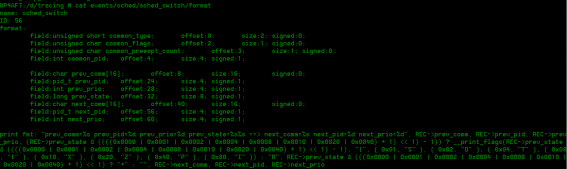
我们依次分析根据上文所有需要跟踪的events,可以根据comm(包括pre_comm,next_comm)和PID等设置过滤条件。
剩下就是把相关events enable就可以了,细节本文就不展开了。
四、实际例子
1. 实际问题
1)问题低概率出现,复现一次不容易,需要一次复现就抓到问题现场;
2)抓取log量还是过大(即使只用“sched”和“camera”),问题场景对负载敏感;
3)问题复现后,需要手动停止,这块手动操作要到10几秒到1分钟不等,需要抓取log量尽可能短,以便抓到出问题时的现场,不然ring buffer被覆盖会导致前功尽弃。
2. 问题分析
虽然该问题概率低,但好消息是只要压测时间足够久,还是能复现出来。通过分析规律,我们发现每次相机切换时,都有AlgoInterface::init出现,重点怀疑该对应的进程调度异常,经确认该方法会对应“APSRoutine”的进程异常。
所以解决问题的关键就变成: 1)利用ftrace event tracing的过滤功能,跟踪“APSRoutine”进程,具体的events的filter设置参见上一章内容; 2)要知道对应的用户态操作,所以必须要打开trace_marker开关(但trace_marker不支持过滤功能,这点比较遗憾,不然可以让记录的内容更少); 3)在Java层crash的地方加hook,crash时抓取ftrace。
所以做了这样满足上述条件的小工具。后续我们还可以将其完善,做成支持抓取任意Java/Native层特定进程调度相关log的功能。
 0
0









