
一、 Crash?
当linux系统内核发生崩溃的时候,可以通过KEXEC+KDUMP等方式收集内核崩溃之前的内存,生成一个转储elf文件vmcore或者其他dump形式。内核开发者通过分析该elf dump文件就可以诊断出内核崩溃的原因,从而进行操作系统的代码问题修复。那么Crash就是一个被广泛使用内核崩溃转储文件分析工具。 对调试来讲,gdb/trace32是非常适合的,但gdb始终是调试native的工具,不支持kernel信息显示,比如task信息之类的。crash补足了这个短板,由Dave Anderson开发和维护的一个内存转储分析工具,是基于GDB开发的,GDB适用于用户进程的coredump,而Crash扩展了GDB,使其适用于linux kernel coredump,目前它的最新版本是7.3。在没有统一标准的内存转储文件的格式的情况下,Crash工具支持众多的内存转储文件格式,包括:
-
Live linux系统
-
kdump产生的正常的和压缩的内存转储文件
-
由makedumpfile命令生成的压缩的内存转储文件
-
由Netdump生成的内存转储文件
-
由Diskdump生成的内存转储文件
-
由Kdump生成的Xen的内存转储文件
-
IBM的390/390x的内存转储文件
-
LKCD生成的内存转储文件
-
Mcore生成的内存转储文件
二、安装
crash是redhat开源工具,因此需要自己下载代码编译成linux可执行文件。
1)从官方网站下载crash源代码; git clone git://github.com/crash-utility/crash.git
2)编译前确保必要的组件(ncurese和zlib); sudo apt-get install libncurses5-dev sudo apt-get install zlib1g-dev
3)解压后编译ARM 32bit的crash: cd crash-7.2.8 make target=ARM64
4)如果是ARM 64bit的,则是: cd crash-7.2.8 make target=ARM64
5)编译后会在当前目录下生成crash,可以将多余的符号去除: strip -s crash
6)当发生kernel crash时,会有db生成;
7)然后可以使用crash的各种命令了,详情请看: http://people.redhat.com/anderson/crash_whitepaper/
三、调试
使用crash来调试vmcore,至少需要两个参数:
-
NAMELIST:带symbol的内核映像文件vmlinux,由内核调试信息包提供;
-
MEMORY-IMAGE:内存转储elf dump文件。
Eg:./crash ../dump/vmlinux ../dump/DDRCS0_0.BIN@0x80000000,../dump/DDRCS0_1.BIN@0x100000000,../dump/DDRCS1_0.BIN@0x180000000,../dump/DDRCS1_1.BIN@0x200000000 --kaslr <kaslr_offset> -m kimage_voffset=0xffffffe5d6200000 -m vabits_actual=39
注:vabits_actual=39 是VB_bits: CONFIG_ARM64_VA_BITS配置

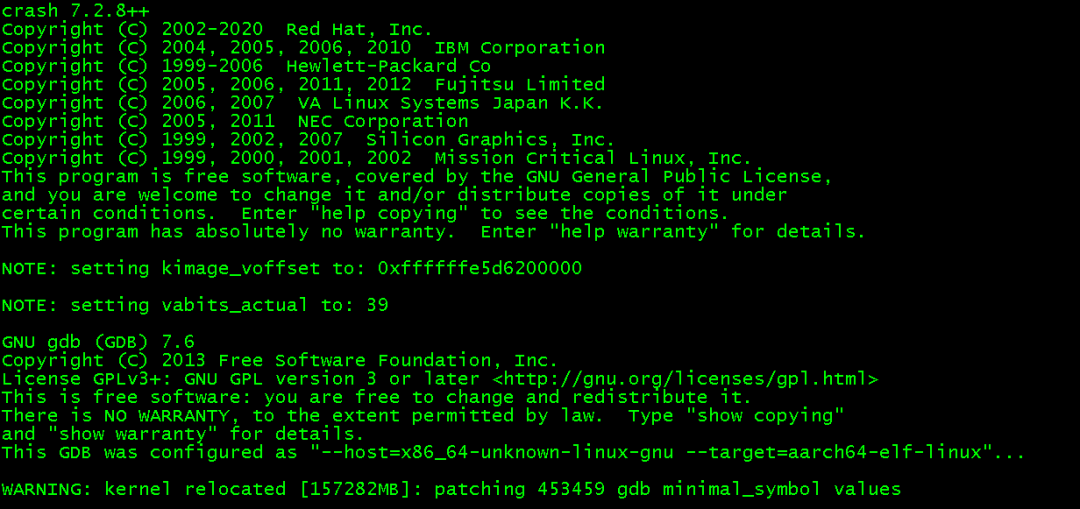
基本输出:
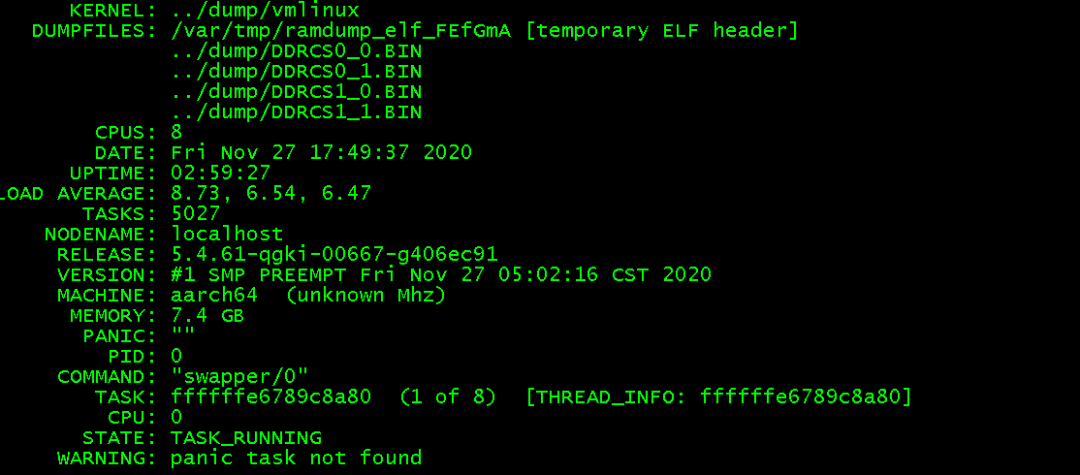
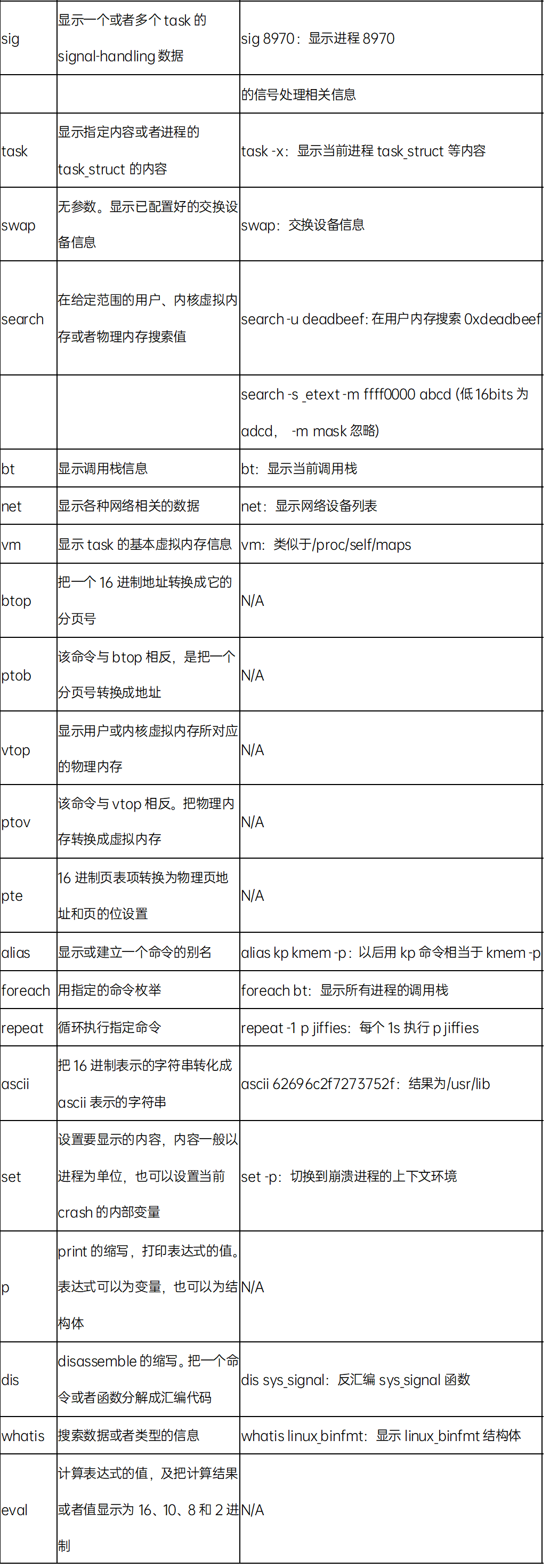
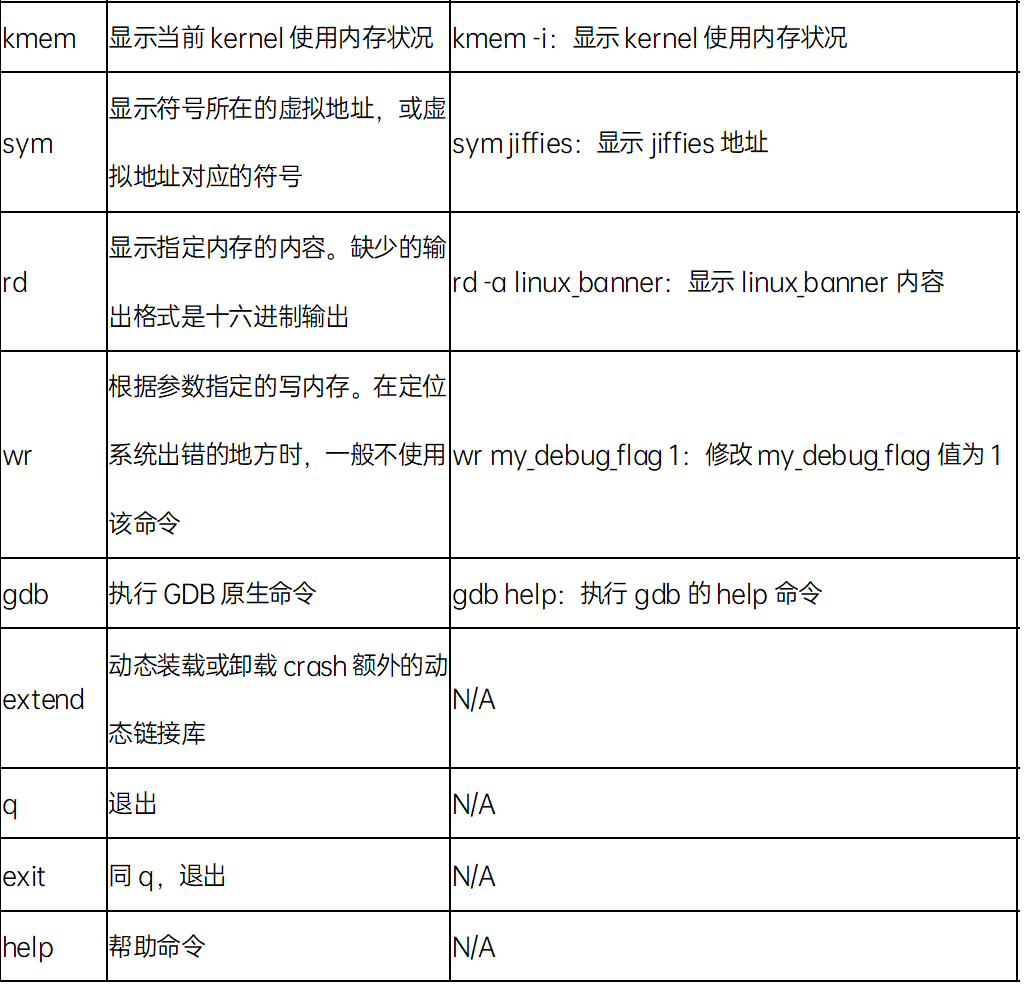
四、常用命令
crash使用gdb7.6作为它的内部引擎,crash中的很多命令和语法都与gdb相同。常用命令如下:如果想获得crash更多的命令和相关命令的详细说明,可以使用crash的内部命令help来获取: log | tail -n 100 查看log cpu watdog bark触发dump
struct msm_watchdog_data wdog_data查看wdog_data 状态:

Non-secure Watchdog data
Pet time: 9.36s
Bark time: 20.0s
Watchdog last pet: 10741.000
Watchdog task running on core 2 from 10750.686741
CPUs responded to pet(alive_mask): 00000001
CPU which didn't respond to pet: 1
CPU#0 : ping_start: 10750.686769 : ping_end: 10750.686779
CPU#1 : ping_start: 10750.686780 : ping_end: 0.000000
ps | grep RU 查看cpu1上活跃进程状态: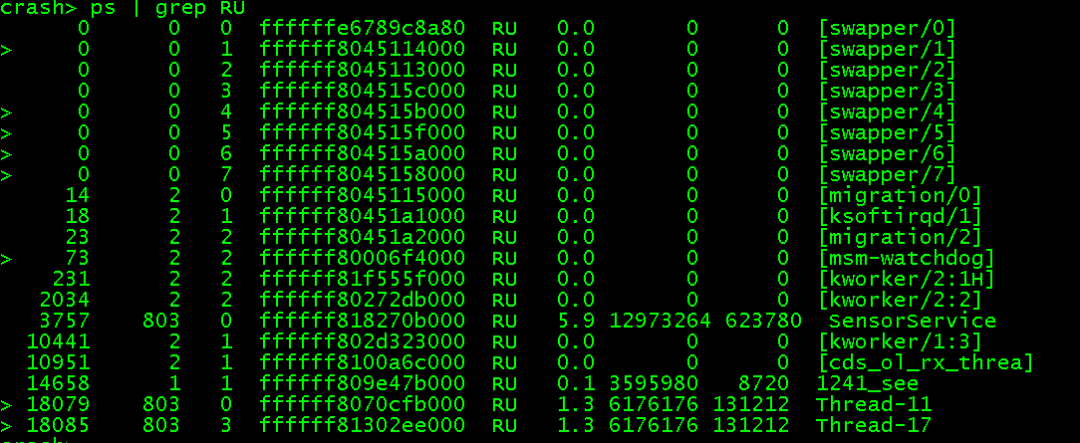
当前dump为cpu1 watchdog bark触发 , 需要查看percpu变量irq_stat在cpu1 状态, 使用per_cpu__ 加变量查看percpu 地址,新版本crash per_cpu已经能自动识别:
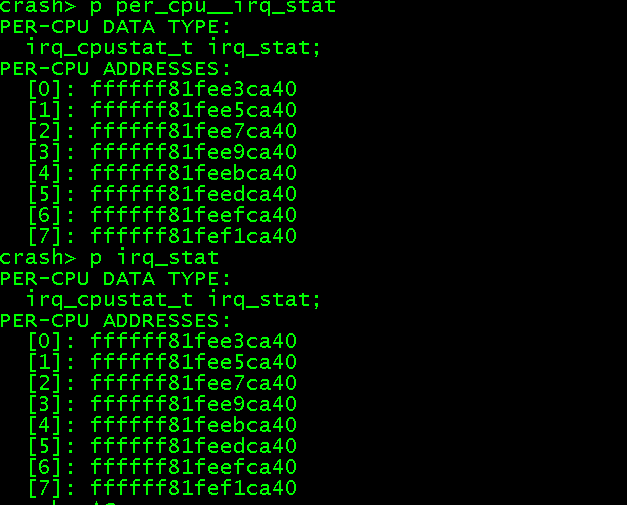
通过地址查看变量:__softirq_pending = 8 对应softirq 为 NET_RX



五、扩展命令
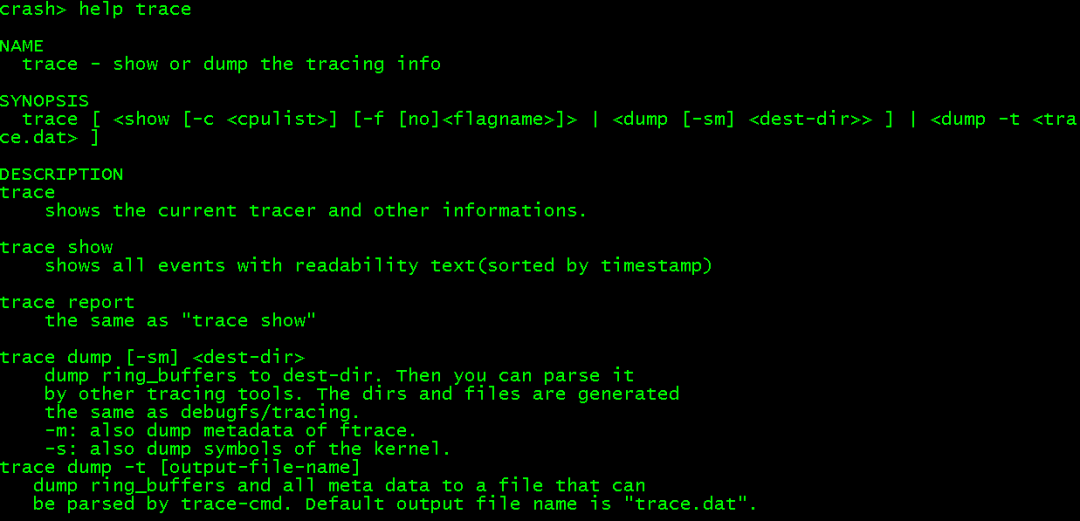
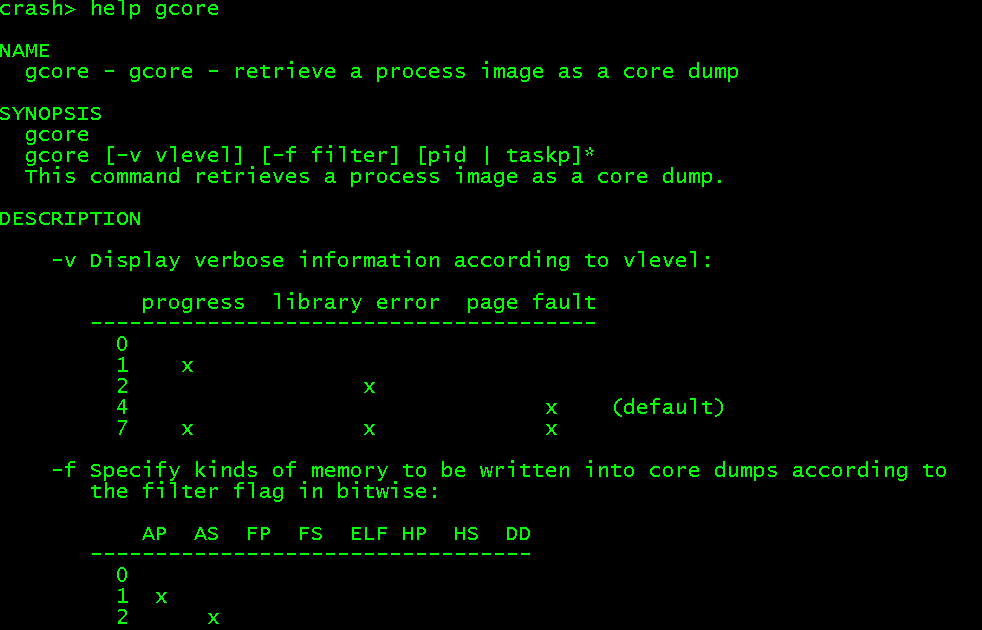
crash支持扩展命令,其中trace/gcore这2个命令对分析问题非常方便,其他具体请看crash扩展命令说明。
trace导出ftrace到FTRACE文件: trace show > FTRACE
gcore导出init进程coredump [kernel中如有打开zram等类似功能,需要crash中添加对应解压缩函数实现]: gcore -f 255 1
使用扩展命令前,需要先编译好对应的so库,下面介绍如何编译扩展命令的库,以trace为例。
六、 ftrace
ftrace对分析kernel性能和死机等问题非常重要,有些异常类问题需要借助mrdump查看ftrace。crash和T32都可以做到,这里讲crash如何利用扩展命令支持查看ftrace。
1. 编译扩展命令库
1)trace扩展命令需要trace-cmd支持,先编译trace-cmd
$git clone git://git.kernel.org/pub/scm/linux/kernel/git/rostedt/trace-cmd.git
pc端trace-cmd ,将生成的trace-cmd放到crash_master目录 cd trace-cmd make
手机端trace-cmd cd trace-cmd
编译32bit make LDFLAGS=-static CC=<android codebase>/prebuilts/gcc/linux-x86/arm/arm-linux-androideabi-4.9/bin/arm-linux-androideabi-gcc trace-cmd
编译64bit make LDFLAGS=-static CC=~/Android_tool/aarch64-linux-gnu-6.3.1/bin/aarch64-linux-gnu-gcc trace-cmd
2)编译trace.so
将trace.c放入crash源码里的extensions目录,然后在crash源码目录下输入如下命令:make extensions
编译好后,就有so库生成,文件放在extensions目录,比如trace.so。
2. 使用扩展命令
进入crash前,需设定环境变量TRACE_CMD,否则使用时会有异常提示:
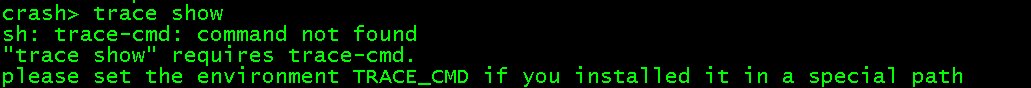
因此在启动crash前,先: exprot trace-cmd 环境变量 export TRACE_CMD=<path-to>/trace-cmd 进入crash后,在crash命令行添加扩展 extend <path-to>/trace.so 至此就可以正确使用trace扩展命令了,比如查看trace有哪些参数可以使用:

执行trace show如下:
 0
0









