
导 读
HMC混合内存立方体,HBM高带宽内存,都曾以取代DDRx为己任,两者名称接近,结构类似,并且都有3D TSV 加持,性能均超过同时期DDRx的数倍。
在AI大潮的驱动下,HBM如日中天,HMC却已悄然隐退,是何原因造成了如此大的差异?这篇文章就和大家一起分析其中的缘由。
DRAM Technology
1
HMC
HMC (Hybrid Memory Cube) 混合内存立方体,曾被视为一项革命性的技术而寄予厚望。
HMC由美光和英特尔合作开发,最初设计的目的是为了彻底解决DDR3所面临的带宽问题。
HMC于2011年推出,对于美光来说,其意义非凡,这将是击败三星、海力士两大韩厂的独门武器。
HMC 标准中,4 个 DRAM Die通过3D TSV连接到堆栈底层的逻辑控制芯片Logic Die,其示意图如下所示:
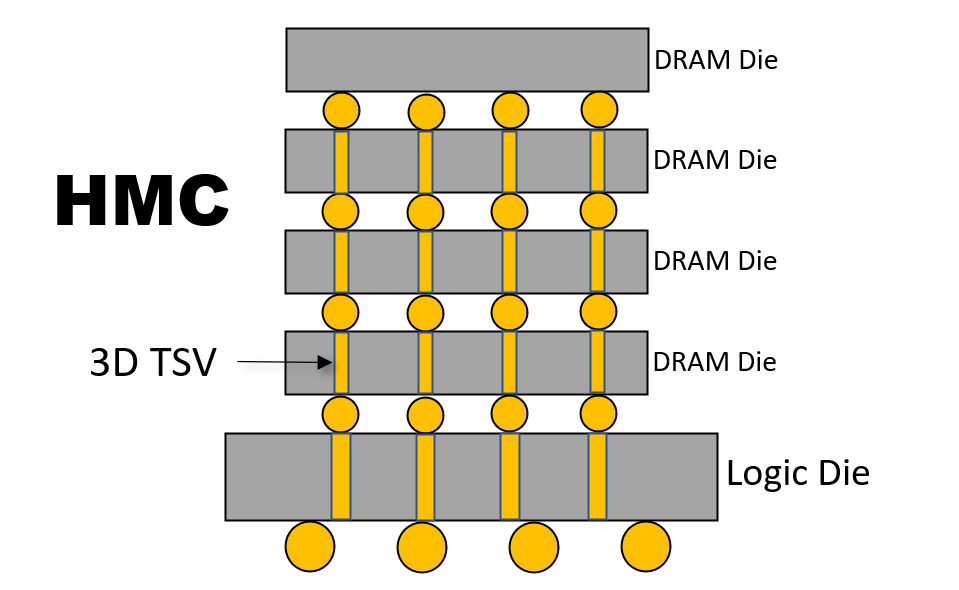
TSV 技术诞生于1999年,最早在内存行业实现商用,是先进封装领域中最为重要的技术,没有之一。
2011年,HMC正是借着TSV技术的东风,获得该年《微处理器报告》最佳新技术奖,一时风头无两。
HMC设计中,从CPU处理器到存储器堆栈的通信是通过高速 SERDES 数据链路进行的,该链路会连接到 DRAM 堆栈底部的逻辑控制器芯片。处理器没有集成到堆栈中,从而避免了芯片尺寸不匹配和散热问题,却带来了一个新的问题,就是处理器离存储器堆栈比较远,这日后也将成为HMC的重要短板。
HMC本质上其实是一个完整的 DRAM 模块,可以安装在多芯片模块 (MCM) 或 2.5D 无源插接器上,从而更加贴近 CPU,实际上却没有人这么做。除此之外,美光还推出了一个"远存储器"的配置,在这一配置中,一部分 HMC 连接到主机,而另一部分 HMC 则通过串行连接到其他 HMC,以此来形成存储器立方体网络。在许多人担心的延迟问题上,美光表示,虽然HMC的串行链路会略微增加系统延迟,但整体的延迟反而是显著降低的,HMC 比 DDR4 提高了约 3 倍的能效(以 pj/bit 为单位)。
DRAM Technology
2
HBM
HBM (High Bandwidth Memory ) 高带宽内存,将很多个DRAM芯片堆叠在一起后和GPU封装在一起,实现大容量,高位宽的DRAM组合阵列。
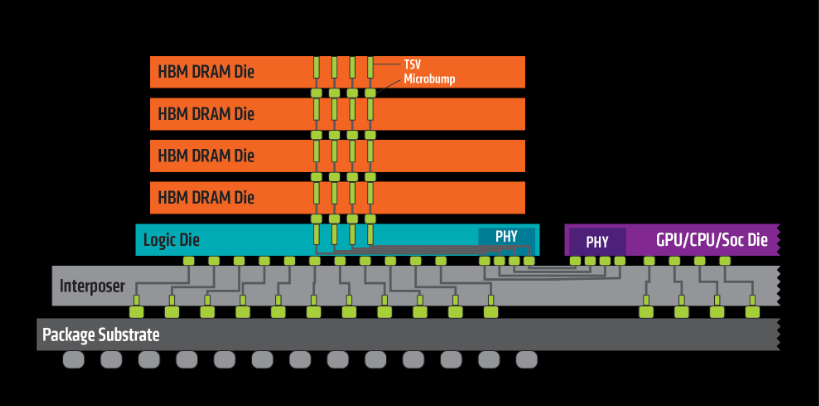
首先,HBM垂直堆叠内存芯片,4 个 DRAM Die通过3D TSV连接到堆栈底层的逻辑控制芯片Logic Die,这点和HMC是相同的。然后,这些DRAM堆栈通过Interposer中介层连接到 CPU 或 GPU。
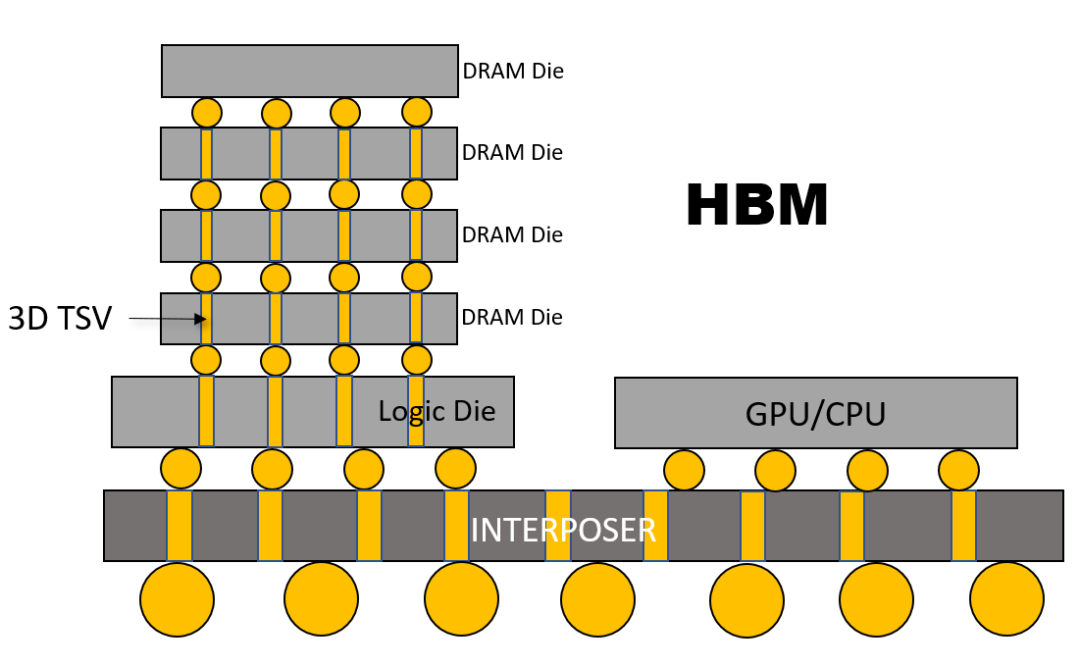
虽然这些 HBM 堆栈没有与 CPU 或 GPU 进行3D集成,但它们通过中介层紧密而快速地连接在一起,以至于 HBM 的特性与片上集成 RAM 几乎没有区别。
HBM由和海力士和AMD共同研发,其推出时间为2013年,被HMC晚了两年。
HBM使用了 128 位宽通道,最多可堆叠 8 个通道,形成 1024 位接口,总带宽在 128GB/s 至 256GB/s 之间。
DRAM Technology
3
HMC vs HBM
今天HBM如日中天,HMC却已经淡出江湖,是何缘由呢?
笔者分析大致有以下两个原因:1.结构差异,2.行业标准。

结构差异
虽然HMC和HBM结构相似,都是将DRAM堆叠在逻辑控制器之上,并且都采用了3D TSV技术,但是,HBM却多了一层Interposer,通过Interposer将DRAM堆栈和GPU紧密集成在一起。可以说有GPU的地方,必有HBM。
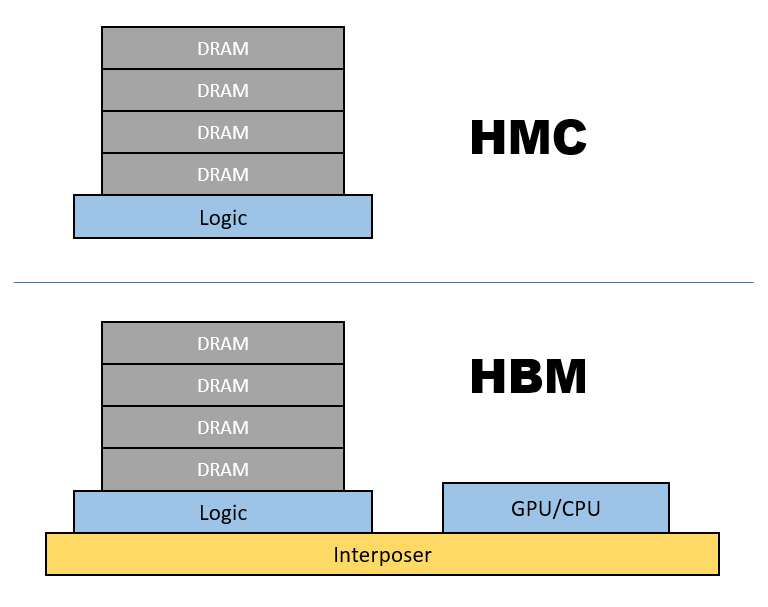
HMC将内存堆栈放置在距离CPU/GPU 很远的位置的方法意味着3D芯片堆叠和固有的低延迟的大部分优势都会丧失,毕竟物理定律是谁也无法逃脱的,信号的传输速度只能那么快。远,就意味着更大的延迟。
假设分别包含HBM和HMC的系统,我们来绘制最小的立方体,并检查其功能密度,即单位体积内包含的功能单位的数量,可以简单理解为单位体积内包含的晶体管数量。可以看出HBM要明显大于HMC,即HBM的功能密度更高,因此,作为先进封装的重要指标来说,HBM的先进程度更高。在热量能够散出的前提下,紧凑紧凑再紧凑就是先进封装的设计原则,为此,我提出了功能密度定律,作为描述系统集成度的重要依据。详见拙著《基于SiP技术的微系统》。通过3D TSV 集成,垂直堆叠芯片,解决了芯片上晶体管等微小组件的一个重要问题:距离。通过将器件垂直堆叠在一起,可以最大限度缩短它们之间的距离,从而减少延迟和功耗。这一点上,HMC和HBM都做到了。然而,HMC没有 Interposer,无法和CPU/GPU进行紧密的集成,因而影响其功能密度, 而HBM却通过Interposer将内存堆栈和CPU/GPU进行紧密集成,有效地提升其功能密度,从而在竞争中胜出。HMC是典型的3D集成技术,而HBM则更高一筹,被称为3.5D集成技术,别小看这0.5个维度,它能带来更紧密的集成度,从而提高系统的功能密度。
从结构上来说,HBM真正击败HMC的原因是什么呢?距离。
有人问,HMC败北HBM是因为它是3D封装而HBM是3.5D吗?是的,确实可以这么理解。
行业标准
结构上的短板,使得HMC必然在功能密度上比不上HBM,在HBM推出后,HMC颓势已显。而给HMC致命一击的是,HBM推出没多久,就被定为了JEDEC行业标准,而HMC虽然比HBM早两年推出,却只有一个HMCC在苦苦支撑。一个是行业内主要科技公司都认可的大组织,一个是美光自己拉起来的小圈子,比赛还没正式开始,胜负就已经分出。拥有数百家会员公司的JEDEC奉行一公司一票与三分之二多数的制度,从而降低了标准制定被任何一家或一批公司所把控的风险。也就是说,JEDEC标准的话语权并不由巨头所掌握,只有大家真正认可,才会最终被推行为正式标准。2018年,人工智能开始兴起,高带宽成为了内存行业的重心,和GPU紧密绑定的HBM赢得了最大的市场,主推该标准的海力士与三星成了大赢家,HBM的大客户英伟达和AMD也因此而赚的盆满钵满。HMC早就没有了2011年刚推出时的风光,门可罗雀,美光也不再执迷不悟,于2018年8月宣布正式放弃HMC,转向HBM。美光毕竟晚了一步,市场份额明显落后于两家韩厂,根据最新数据,SK 海力士占据全球 HBM 市场 50% 的份额,位居第一;三星紧随其后,占据 40% 的份额;而美光屈居第三,仅占据 10% 的市场份额。人工智能的兴起,或许是压倒HMC的最后一根稻草。事到如今,美光也不由地感慨:既生瑜何生亮?
在半导体江湖,新技术层出不穷,波浪荡漾的湖面,星星点点,闪耀着科技的光芒。有些技术曾经光芒四溢,最终却黯然退出,有些却能长时间屹立不倒,并推动人类科技的伟大进步。成王败寇,半导体江湖也是如此。
声明:本文由半导体材料与工艺转载,仅为了传达一种观点,并不代表对该观点的赞同或支持,若有侵权请联系小编,我们将及时处理,谢谢。
 0
0







