
1.问题描述
对于RHEL发行版以及Ubuntu服务器版本,客户都报告了这样的问题。在一台至强服务器(使用x86_64处理器)上发现好几个正在运行的虚拟机发生了死锁,即虚拟机没有响应。这台服务器是基于NUMA架构的服务器,内建多个CPU节点和内存节点。在主机的Linux中开启了KSM机制和numad监控程序。虚拟机是基于KVM和QEMU构建的。
主机的Linux发行版是Ubuntu 16.04。主机的Linux内核版本是4.4.0-47-generic。
在虚拟机的Linux内核中发现softlockup的如下日志信息。
CPU: 3 PID: 22468 Comm: kworker/u32:2 Not tainted 4.4.0-47-generic #68-Ubuntu Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS Ubuntu-1.8.2-1ubuntu1 04/01/2014 Workqueue: writeback wb_workfn (flush-252:0) [<ffffffff81104388>] smp_call_function_many+0x1f8/0x260 [<ffffffff810727d5>] native_flush_tlb_others+0x65/0x150 [<ffffffff81072b35>] flush_tlb_page+0x55/0x90
2.问题分析
从虚拟机的Linux内核日志信息可知,虚拟机的vCPU3正在运行kworker内核线程,这个线程调用flush_tlb_page()函数刷新TLB,并调用smp_call_function_many()函数给其他vCPU发送IPI广播,最后一直在等待其他vCPU回应。smp_call_function_many()函数实现在kernel/smp.c中,其代码片段如下。
<kernel/smp.c> void smp_call_function_many(const struct cpumask *mask, smp_call_func_t func, void *info, bool wait) { ... for_each_cpu(cpu, cfd->cpumask) { csd_lock(csd); csd->func = func; csd->info = info; if (llist_add(&csd->llist, &per_cpu(call_single_queue, cpu))) __cpumask_set_cpu(cpu, cfd->cpumask_ipi); } /* 给所有vCPU发送IPI广播*/ arch_send_call_function_ipi_mask(cfd->cpumask_ipi); /* 等待其他vCPU返回*/ if (wait) for_each_cpu(cpu, cfd->cpumask) csd_lock_wait(csd); }
我们在虚拟机的Linux内核中找不到特别多的有用信息,但是为什么vCPU会一直在等待TLB刷新呢?我们需要结合主机的Linux内核日志信息一起分析。
接下来分析主机Linux内核中的日志信息。我们可以使用kdump工具来抓取主机Linux发生的死锁或者softlockup中的内存快照(vmcore)。从主机的vmcore里,我们发现有几个线程一直在等待一个读写信号量。
下面是ksmd内核线程的函数调用栈,从第2个栈帧可以发现ksmd内核线程尝试申请一个读者类型的信号量,但是一直没有成功。对照其源代码,我们发现它在scan_get_next_rmap_item()函数中尝试申请一个读者类型的mm→mmap_sem锁。调用路径为kthread()→ksm_scan_thread() →scan_get_next_rmap_item()→down_read()。
<ksmd内核线程的函数调用栈> crash> bt 615 PID: 615 TASK: ffff881fa174a940 CPU: 15 COMMAND: "ksmd" 0 [ffff881fa1087cc0] __schedule at ffffffff818207ee 1 [ffff881fa1087d10] schedule at ffffffff81820ee5 2 [ffff881fa1087d28] rwsem_down_read_failed at ffffffff81823d60 3 [ffff881fa1087d98] call_rwsem_down_read_failed at ffffffff813f8324 4 [ffff881fa1087df8] ksm_scan_thread at ffffffff811e613d 5 [ffff881fa1087ec8] kthread at ffffffff810a0528 6 [ffff881fa1087f50] ret_from_fork at ffffffff8182538f
下面是khugepaged内核线程的函数调用栈。从第2个栈帧可以发现khugepaged内核线程尝试申请一个写者类型的信号量,但是一直没有成功。对照其源代码,我们发现它在collapse_huge_page()函数中尝试申请一个写者类型的mm->mmap_sem锁。调用路径为,khugepaged()→khugepaged_do_scan()→khugepaged_scan_mm_slot()→khugepaged_scan_pmd()→collapse_huge_page()→down_write()。
<khugepaged内核线程的函数调用栈> crash> bt 616 PID: 616 TASK: ffff881fa1749b80 CPU: 11 COMMAND: "khugepaged" #0 [ffff881fa108bc60] __schedule at ffffffff818207ee #1 [ffff881fa108bcb0] schedule at ffffffff81820ee5 #2 [ffff881fa108bcc8] rwsem_down_write_failed at ffffffff81823b32 #3 [ffff881fa108bd50] call_rwsem_down_write_failed at ffffffff813f8353 #4 [ffff881fa108bda8] khugepaged at ffffffff811f58ef #5 [ffff881fa108bec8] kthread at ffffffff810a0528 #6 [ffff881fa108bf50] ret_from_fork at ffffffff8182538f
下面是qemu-system-x86_64进程的函数调用栈。从调用栈可知,qemu-system-x86_64进程也在等待一个读者类型的信号量。通过查阅kvm_host_page_size()源代码,我们发现它也在等待mm->mmap_sem锁。
<qemu-system-x86_64进程> crash> bt 12555 PID: 12555 TASK: ffff885fa1af6040 CPU: 55 COMMAND: "qemu-system-x86" #0 [ffff885f9a043a50] __schedule at ffffffff818207ee #1 [ffff885f9a043aa0] schedule at ffffffff81820ee5 #2 [ffff885f9a043ab8] rwsem_down_read_failed at ffffffff81823d60 #3 [ffff885f9a043b28] call_rwsem_down_read_failed at ffffffff813f8324 #4 [ffff885f9a043b88] kvm_host_page_size at ffffffffc02cfbae [kvm] #5 [ffff885f9a043ba8] mapping_level at ffffffffc02ead1f [kvm] #6 [ffff885f9a043bd8] tdp_page_fault at ffffffffc02f0b8a [kvm] #7 [ffff885f9a043c50] kvm_mmu_page_fault at ffffffffc02ea794 [kvm] #8 [ffff885f9a043c80] handle_ept_violation at ffffffffc01acda3 [kvm_intel] #9 [ffff885f9a043cb8] vmx_handle_exit at ffffffffc01afdab [kvm_intel] #10 [ffff885f9a043d48] vcpu_enter_guest at ffffffffc02e026d [kvm] #11 [ffff885f9a043dc0] kvm_arch_vcpu_ioctl_run at ffffffffc02e698f [kvm] #12 [ffff885f9a043e08] kvm_vcpu_ioctl at ffffffffc02ce09d [kvm] #13 [ffff885f9a043ea0] do_vfs_ioctl at ffffffff81220bef #14 [ffff885f9a043f10] sys_ioctl at ffffffff81220e59 #15 [ffff885f9a043f50] entry_SYSCALL_64_fastpath at ffffffff81824ff2
从上述的日志信息可知,ksmd内核线程、khugepaged内核线程以及qemu-system-x86_64进程都在等待同一个锁(mm->mmap_sem),那么谁是锁的持有者呢?我们可以通过分析内核的vmcore来推导出哪个进程或者线程是锁的持有者。分析和推导的方法见卷2第4~5章。
通过分析和推导,我们发现该锁的持有者为numad进程。numad进程是运行在用户空间自动做NUMA内存节点平衡管理的进程,它会监控NUMA拓扑和资源使用情况,然后调用migrate_pages系统调用来迁移页面,即将页面从一个内存节点迁移到另外一个内存节点中。该进程持有锁的路径如下。
migrate_pages系统调用-> kernel_migrate_pages()->do_migrate_pages()->down_read() crash> bt 2950 #1 [ffff885f8fb4fb78] smp_call_function_many #2 [ffff885f8fb4fbc0] native_flush_tlb_others #3 [ffff885f8fb4fc08] flush_tlb_page #4 [ffff885f8fb4fc30] ptep_clear_flush #5 [ffff885f8fb4fc60] try_to_unmap_one #6 [ffff885f8fb4fcd0] rmap_walk_ksm #7 [ffff885f8fb4fd28] rmap_walk #8 [ffff885f8fb4fd80] try_to_unmap #9 [ffff885f8fb4fdc8] migrate_pages #10 [ffff885f8fb4fe80] do_migrate_pages
图6.8所示展示了死锁发生的流程。
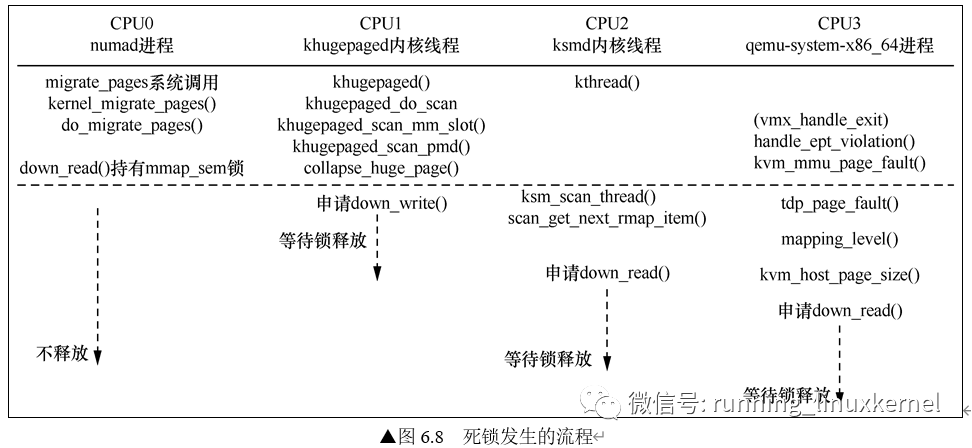
具体操作如下。
(1)假设用户态的numad进程运行在CPU0上,它发现NUMA系统内存节点有不平衡的情况,调用migrate_pages系统调用进行页面迁移。我们假设numad进程现在想把进程A的内存迁移到另外一个内存节点上,通过内核态的do_migrate_pages()函数,它会首先持有进程A的读者类型的锁(mm->mmap_sem)。那这个进程A可能是谁呢?
(2)khugepaged内核线程运行在CPU1上,它会定期扫描系统内存,尝试合并多个连续的页面,使其成为巨页。恰巧的是,khugepaged内核线程正好也扫描到了进程A,因此khugepaged内核线程也想持有进程A的mm->mmap_sem写者类型的锁。但是,因为numad进程已经率先持有了该锁。虽然该线程是读者类型,但是khugepaged内核线程想申请写者类型的锁,根据读写信号量的语义,只能等待该锁被释放后才有机会持有这个锁。
(3)ksmd内核线程运行在CPU2上。ksmd线程也会定期扫描进程尝试发现和合并页面内容相同的页面,从而释放出内存。“无巧不成书”,ksmd内核线程也扫描到了进程A,申请读者类型的mm->mmap_sem锁,但是因为已经有一个写者类型的申请者在等待队列前面,根据读写信号量的语义,写者类型的申请者会优先持有该锁,等写者类型的申请者释放了该锁后,ksmd内核线程才有机会持有这个锁。
(4)虚拟机的qemu-system-x86_64进程运行在CPU3上,它由于在虚拟机里发生了缺页异常,因此退回到主机端处理虚拟机的缺页情况。在处理虚拟机缺页异常的函数中,qemu- system-x86_64进程也需要申请读者类型的锁mm->mmap_sem,这回是申请自己进程的锁。可是,这个锁已经被CPU0上的numad进程先持有了,而且numad进程不仅持有了锁,还长时间不释放。因此,虚拟机被卡在主机端的缺页异常处理里,这就是我们看到的现象,虚拟机没有了响应。
因此,我们需要重点去分析,为什么numad进程持有锁并且一直不释放?
从numad进程的函数调用栈来看,它在迁移页面时遇到了一个KSM页面,调用rmap_walk_ksm()函数把所有映射到这个页面的PTE都销毁(这里指的是所有用户态的进程地址空间的虚拟地址映射到的这个页面的PTE,我们简称为用户PTE),也就是沿着RMAP机制来把KSM页面所有的用户PTE都取消映射关系。每当销毁一个用户PTE的映射关系之后需要调用flush_tlb_page()函数广播和通知所有的CPU:这个用户PTE映射已经取消了,正在刷新TLB,调用smp_call_function_many()发送IPI广播并且等待所有CPU的回应。
那为什么numad进程会一直等待IPI广播的回应呢?可能有两个原因。
-
CPU硬件问题。
-
是不是我们有大量的用户PTE需要做取消映射处理,然后发送大量的IPI广播呢?
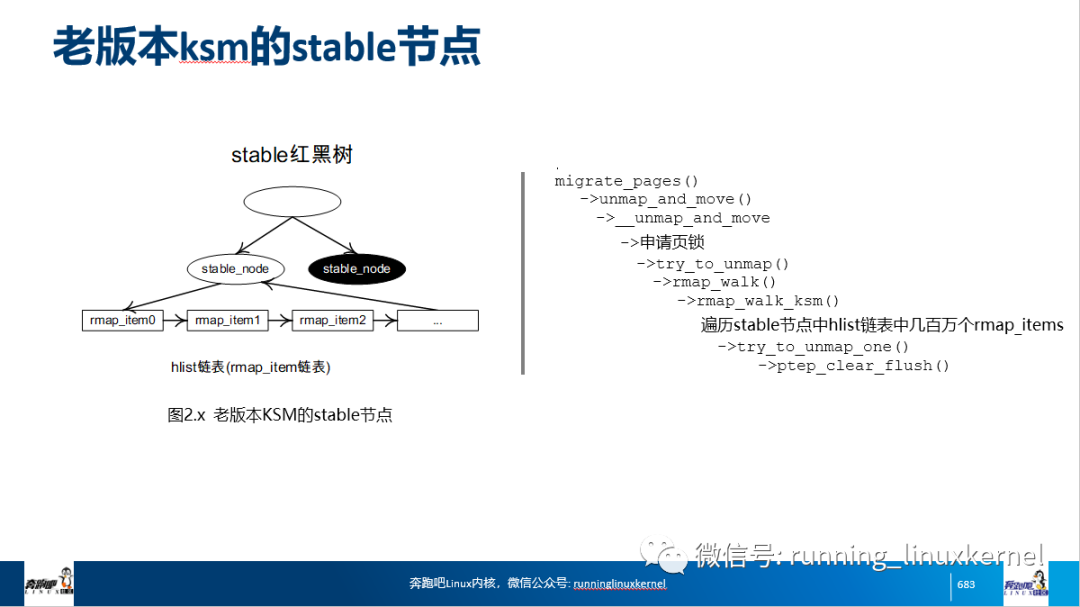
对于第一个原因,可能涉及芯片设计和硬件设计问题了。对于第二个原因,我们可以使用crash工具来分析函数调用栈的内容,推导stable_node节点的hlist链表中有多少个rmap_item成员。下面是rmap_walk_ksm()函数的代码片段,每个KSM页面对应一个stable_node节点,这个stable_node节点里包含了一个hlist链表,链表的成员(rmap_item)代表一个一个被合并的用户PTE。rmap_walk_ksm()函数的作用就是遍历这个hlist链表找出当时被合并的用户PTE,然后调用rmap_one()函数解除这个用户PTE的映射关系。这里调用anon_vma_interval_ tree_foreach()遍历RMAP的AV红黑树是为了检查和保证rmap_item对应的虚拟地址(rmap_item->address)是正确和有效的,具体请看5.7节的内容。
<mm/ksm.c> void rmap_walk_ksm(struct page *page, struct rmap_walk_control *rwc) { stable_node = page_stable_node(page); ... //遍历stable_node中hlist链表的每个成员 hlist_for_each_entry(rmap_item, &stable_node->hlist, hlist) { struct anon_vma *anon_vma = rmap_item->anon_vma; anon_vma_interval_tree_foreach(vmac, &anon_vma->rb_root, 0, ULONG_MAX) { //调用rmap_one()回调函数来解除这个用户PTE的映射关系 rwc->rmap_one(page, vma, addr, rwc->arg)) } ... }
按照卷2介绍的crash分析技巧,我们很快得到了stable_node节点存放的地址,从而计算出stable_node节点中有多少个成员。
crash> list hlist_node.next 0xffff883f3e5746b0 > rmap_item.lst $ wc -l rmap_item.lst 2306920
stable_node节点一共约有230万个成员,每个成员代表一个被合并的用户PTE,因此一共约有9GB的内存合并到一个KSM页面里(假设一个被合并的页面只有一个用户PTE)。在try_to_unmap_one()函数,解除页表映射关系时需要调用flush_tlb_page()函数做TLB刷新。这个TLB刷新动作在CPU内部会发送IPI中断来通知其他CPU,大概需要10~100s,那么要发送230万个TLB刷新将会持续23~230s。解除页表映射关系和刷新TLB是在持有mm->mmap_sem锁的临界区里进行的,因此numad进程长时间持有锁,导致了其他线程没有办法拿到锁,这也是为什么虚拟机没有响应。
3.解决方案
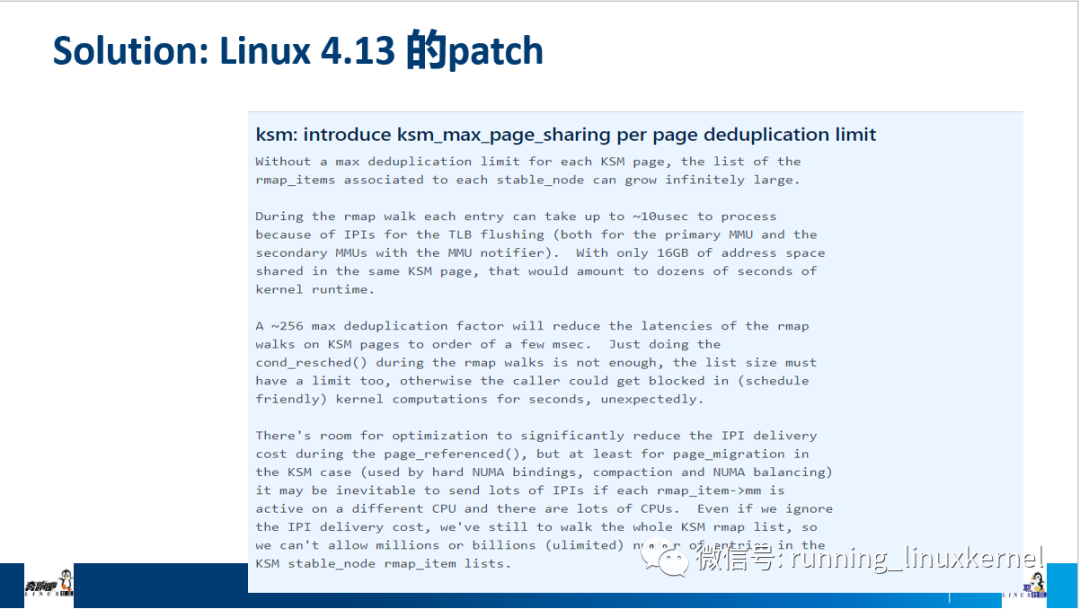
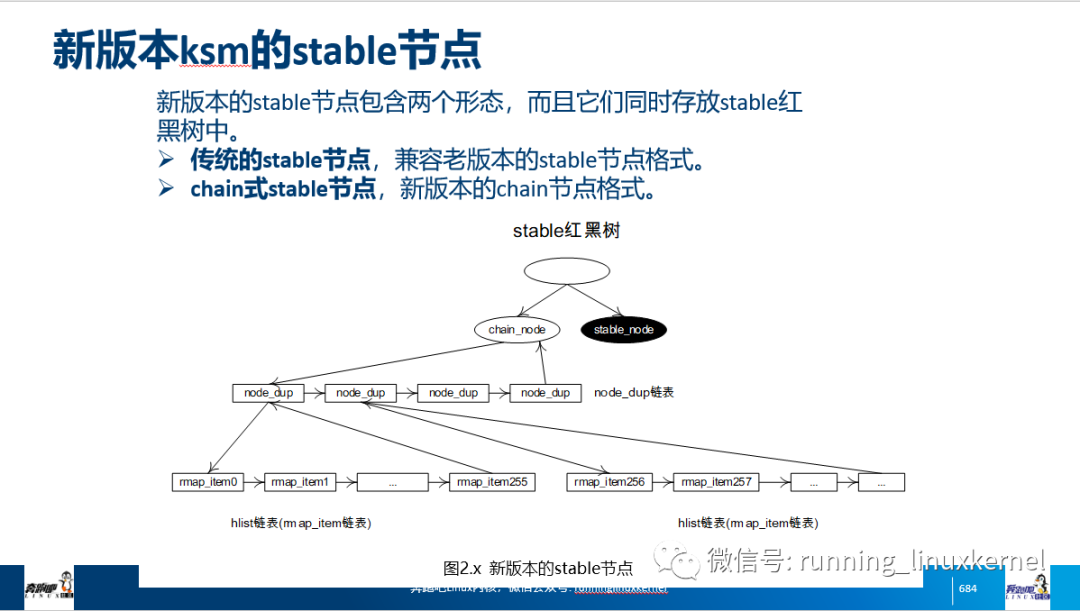
在Linux 4.13内核开发期间, Red Hat的内核工程师Andrea Arcangeli已经修复了这个问题,读者可以参考5.7.4节的内容。
在Ubuntu 16.04中,Linux 4.4.0-96.119内核已经修复了这个问题,读者若使用该版本的Ubuntu发行版,可以将其升级到最新的Linux内核镜像。
补充的slides
下面是补充的slides,仅供参考。
 0
0









